BIRNet: Brain image registration using dual-supervised fully convolutional networks
一、Motivation
缺乏准确的Ground-Truth。
we design a fully convolutional network that is subject to dual-guidance。
1) Ground-truth guidance using deformation fields obtained by an existing registration method;
2) Image dissimilarity guidance using the difference between the images after registration.
(2)可以帮助避免过度依赖于训练变形场的监督,这种监督可能是不准确的。为了进行有效的训练,我们使用gap filling,hierarchical loss, multi-source strategies进一步改善了深度卷积网络。
二、Contribution
1 与传统方法相比,提出了一种端到端的one-shot的无需参数微调的配准方法。
2 与基于深度学习的配准方法相比,我们旨在解决缺少理想的Ground-Truth变形的问题,然后进一步提高配准精度。
3 为了提高效率和准确性,基于基本的UNet架构,我们还建议使用gap filling来学习更多高级功能,并使用多通道输入for better informing the registration network。
三、Method

整体框架上图所示:
一种分层的对偶网络。采用U-Net网络结构,但是在此基础上添加四种策略:1)Hierarchical dual-supervision。2)Gap filling.
3)Multi-channel inputs 4)Data augmentation
1 Dual-supervision
1) loss φ—the difference between the predicted deformation field and the existing (training) ground- truth deformation field;
2) loss M —the difference between the tem-plate and the warped subject image based on the deformation currently estimated via the network.
两种损失的定义如下图所示:

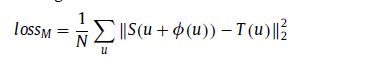
总损失定义如下:如果alpha越大,则表明希望变形场更准确。belta越大,则表明图像差异更小。
![]()

网络的输入是concatenated original image, difference map, and gradient map。如上图所示。
由于输入尺寸和输出尺寸不一致,所以需要进行变换。也就是对Ground-truth中的位置进行映射。

2 Gap Filling
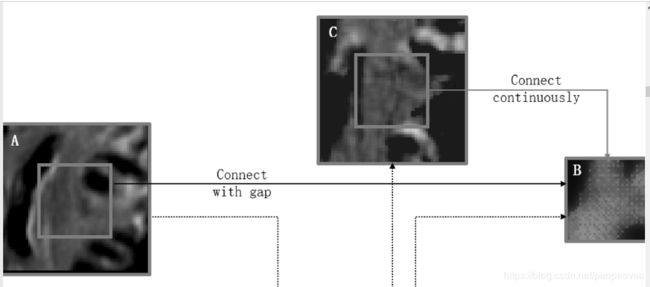

如上图所示,黑色部分是U-Net的基本结构。左侧是下采样而右侧是上采样。为了恢复由于下采样而丢失的细节,我们将左右两侧的对应的部分进行了concatenate。
上图A和原图像相似,而B则是和变形场相似。这两个特征图差别很大,这样对配准效果有影响。值得注意的是,特征图是通过反卷积从低级特征图上采样的中间特征图,因此相邻的体素可能引用不同的信息。因此,特征图B是有点不连续的。
所以作者提出在同一级别中加入额外的卷积层,来使B更连续。如上图绿色部分所示。
以此方式,在间隙填充之后的特征图C将与特征图B更相似,从而提高了配准精度和训练速度。
3 Multi-channel inputs

图像特征图(例如差异图和梯度图)也可以用于提高配准精度。差异图被计算为对象和模板图像之间的强度差异。 梯度图提供边界信息以帮助结构对齐。此外,除了强度图像以外,还使用梯度图来计算等式中(3)中的图像相似度。这确保了边界可以更精确地对齐。 注意,将梯度图缩放到强度图像的相同值范围以进行一致的比较。通常,深度学习网络可以自行学习所需的功能。 但是,损失函数通常仅在最后一层计算,从而导致额叶卷积层的参数不理想。因此,从一开始就输入在传统配准方法中有用的梯度图和差异图,可以大大提高正面卷积层中参数的效果和收敛速度。
4 Data augmentation
LONI LPBA40 ( Shattuck et al., 2008 ) dataset


四、Experiments
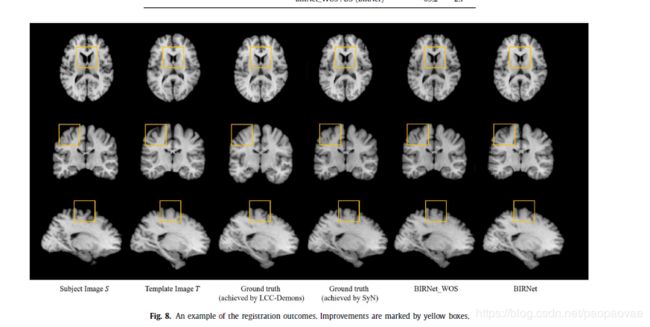
此文章实验比较多,只截取了一部分。

BIRNet_WOS:在该模型中,我们基于U-Net添加了层次监督,间隙填充和多通道输入。
BIRNet :The same setting as BIRNet-WOS but with dual- guidance (our proposed method).