WSDM'20 | 如何构建推荐系统中的商品知识图谱
Xu D, Ruan C, Korpeoglu E, et al. Product Knowledge Graph Embedding for E-commerce[C] //Proceedings of the 13th International Conference on Web Search and Data Mining. 2020: 672-680.
阅读更多,欢迎关注公众号:论文收割机(paper_reader)
因为排版问题,很多图片和公式无法直接显示,欢迎关注我们的公众号点击目录来阅读原文。
引言
本文将介绍如何构建推荐系统中商品知识图谱(product knowledge graph, PKG),并如何通过该知识图谱来学习图嵌入(graph embedding)。
本文将商品知识图谱与一般的知识图谱(knowledge graph, KG)进行类比,并阐释为何一般知识图谱中的图嵌入学习方法无法直接使用在商品知识图谱的图嵌入学习中。
同时,基于自注意力机制(self-attention),本文提出了一个学习分布表示学习(distributed representation learning)的模型,该模型能够实现端到端(end-to-end)的商品知识图谱的嵌入学习。
为了学习到实体(entity)间的复杂结构信息,poincare embedding(hyperbolic embedding)也将被使用。该实验模型在大规模的walmart商品推荐系统上测试,并完成了知识补全(knowledge completion),搜索排序(search ranking)以及推荐的任务。
PKG中的商品关系
-
product与product之间的关系包括互补关系(complement/cobuy),同时浏览(co-view),以及相互替代(substitute)关系。这些关系在以前的工作中【1,2】已经被研究过。如图中所示,无线音箱和TV是互补的关系,或者遥控器和电视机也是互补的关系。而两种类似的电视机之间就是相互替代的关系。
-
除了product之间的关系之外,产品和自然语言之间的关系也是非常重要的。一个描述性词汇(description)与产品之间的关系是describe的关系,而通过关键词来搜索出的产品与该关键词之间的关系是search关系。
-
基于描述性词汇的,产品能被分入不同层级的类别中,比如一个电视机是属于TV&Videos这个类,而遥控器则是属于TV accessories类别。因此,这种层级化(hierarchical)的类别关系能够被定义成IsA的关系。
-
产品与产品之间的关系,或者产品与词语(word)之间的关系,其实能够被细分成为更具体的关系。比如,complement关系可以被细分成AddOn,AccessoryTo, PartOf等更加具体的互补关系。而‘’word describe product‘的关系,可以被分解成HasAttribute, Brand, Name等关系。
学习PKG中的embedding
现有的KG中embedding学习的方法主要是通过将entities和relations映射到一个低维的连续向量空间中,并同时保持原有的几何结构特性。
比如通过学习translational distance的TransE, TransH, TransR和TransD等方法。以及学习隐语义相似度(latent semantic similarity)的RESCAL, DistMult, HolE和ComplEx等模型。
KG中embedding的学习是基于其中的事实(facts)具有高度合理性(plausibility)的假设,而PKG却与之不同:
在电子商务(e-commerce)的场景中,除了describe和IsA关系能够直接清晰的定义,complement,co-view,substitute和search的关系都需要从用户历史的数据中提取。
比如,两种coffee的产品可能从标题和品牌上来看都是非常相似的,但是它们却不具有substitute的关系,原因是其中一种是无咖啡因的,另一种是含咖啡因的。因此,用户替代选择的记录就能更好的找到两种产品之间的substitute关系。
同时,在电子商务的场景下,PKG的学习也具有噪声(noise)以及稀疏(sparsity)的问题。如果提取关系不是足够复杂(complicated),那么product category的非常规树结构会导致其就很难被嵌入到欧式空间(Euclidean space)中。而且,产品的描述词有时也会充满与describe关系并不相关的干扰词语(noise words)。
1. 与自然语言处理中的翻译(translation)模型结合
为了解决noise 的问题,最终模型的优化目标本质上是一个离散事件序列学习,与神经机器语言翻译(neural machine language translation)问题相同。
例如:
[. . . ,soap, detergent, toothbrush , towel → toothpaste, . . .].
我们希望从该序列中提取出toothpaste 和toothbrush的complement关系。
也就是说该序列能够被翻译成toothpaste这个product,同时toothbrush是该产品输入序列中与该toothpaste最相关的产品。
产品描述性关系的提取也是类似,比如ice cream被{The strawberry ice cream featured by Haagan-Dazs is the marriage of sweet summer strawberries to cream and . . .}描述。
因此该冰淇淋的flavor和brand应该具有最高的注意力值(attention),也就是说该描述被“翻译”成strawberry Haggan-Dazs ice cream。所以,文中提出了改进版的自注意力网络(self-attention network)来提取有噪声的product描述信息和用户活动数据。
2. 多模态多任务学习(multi-modal and multi-task learning)
为了解决稀疏性的问题,本文使用了multi-task multi-modal learning的思想。customer view, purchase, search, substitute 记录,以及产品描述和分类信息都能够成为数据源。
为了更好的找到产品关系之间的相关性,并且学习多种任务,本文使用了propagation rule(信息传播)来建立多种任务之间的关联性。比如可替换的产品或者相似的产品之间,往往也会具有更相似的complement,co-view,substitute关系,同时也会与相似的word之间具有describe和search等关系。
3. Poincare ball embedding spaces
由于PKG之间的空间结构信息非常丰富,同时由于欧式空间中对树状结构信息(层级结构信息)的嵌入并不能够很好的学习,因为从双曲空间(hyperbolic spaces)来学习流形结构(manifold structure)会成为一个更好的选择。
整体模型方法(Methodology)
1. Distributed representation
Distributed representation是基于这样的假设:在相似的上下文出现的词语之间将会具有更加相似的representation。
Translation模型, 例如TransE就是基于这样的假设,两个词语之间的表示通过其之间的关系表示来等价。
比如king − men ≈ queen − women,而两者间的关系是通过royal来等价的。所以在KG中,只需要学习到royal这个关系的向量表示,那么只需要已知由该关系连接的其中一个node men,那么另外一个node king的表示也能够相应计算出即king=men+royal。
但是,直接学习关系向量对于PKG来说并不合理,比如complement这种关系,如果仅用一个向量来学习是不够的,因为complement关系在实际中语义更加丰富,比如结构上的complement,功能上的complement,或者enhancement也是complement的一种,所以我们将不直接学习一个complement向量,而是通过相似的学习方法(比如同时多次出现在购买记录中表示complement关系)来学习到某种特定的关系。
2. substitute关系的学习
当substitute数据是可以获取的时候,可以直接通过产品的embedding来建立substitute关系,同时由于substitute关系是对称的,因此可以直接通过word2vec模型来学习基于substitute关系的embedding。

3 利用自注意力(self-attention)机制来学习complement,co-view,describe以及search关系
关系数据来源:
-
complement:purchase records
-
co-view:view records
-
search:search records
-
describe:产品描述(description)
自注意力中的embedding层
首先每个entity以及其对应的位置信息(position)都能够被表示成一个向量,因为将entity sequence截断成最长为l长的序列之后,输入和输出的embedding表示为:

![]()
Self-attention层原来是基于query,key和value的网络,本文将隐层的信息表示成基于权重的输入embedding和:
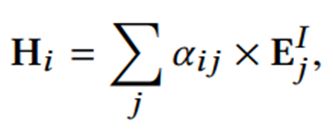
其中的权重$\alpha$是由输入的embedding和输出的embedding共同决定的:
![]()
但是由于$\alpha$是embedding直接内积,所以为了不影响self-attention层的信息表示,在输入和输出层之前加入两层网络来增加参数:

因此,对于purchase和view数据,最终的预测层将是用前l个entities来预测第l+1个entity输出的embedding:
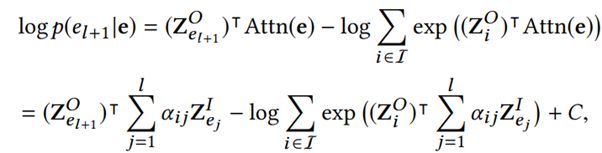
对于description和search数据,其实是希望能够找到前l个entities与第l+1个输入entity的embedding的关系,因此对于该数据的预测层是:

最后的loss function就是将数据中所有出现的序列求和计算。
4. Poincare embedding来学习分类层级信息和IsA关系
两个catogery的词语,c1和c2之间的层级关系,其实在双曲空间中能够更好保持,该度量用
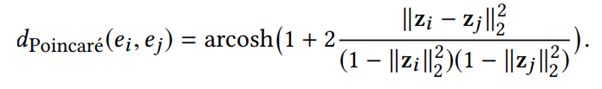
来表示。因此,最终的两个category之间是否有对应关系也是用与word2vec model类似的函数:
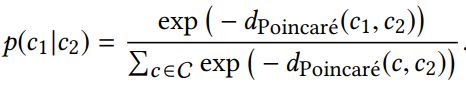
而product与category word之间的IsA关系是用:

函数来学习的。C是表示category word的embedding。
5 Multi-task training

所有的embedding几乎都参与到各个不同任务中,而每个任务之间的网络参数又并不能够直接共享,所以本文通过在【3】中描述的多任务学习框架:1)每次随机选择一个任务来训练,
2)每次训练的数据是所有数据中的一部分,
3)sampling的数据按照其原有数据量的大小成正比。
4)最后训练将以在validation 数据集上不在提高表现为准。
6 整体框架
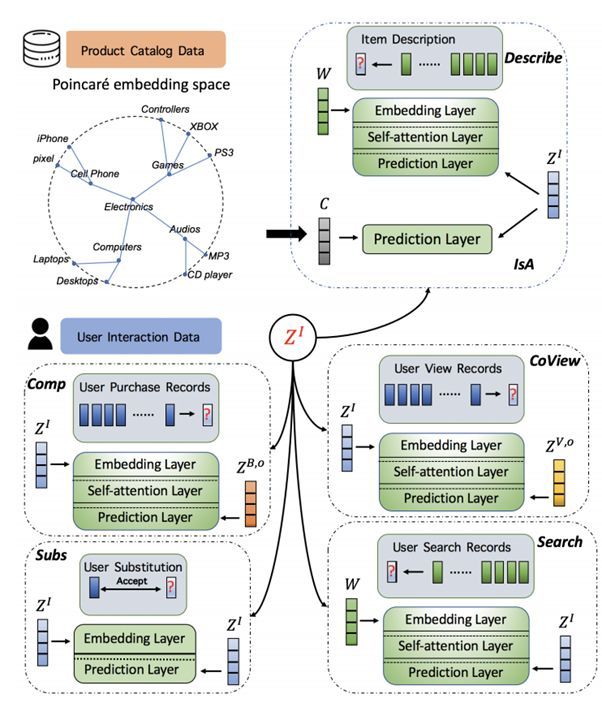
实验
主要的实验就是为了验证设计的PKG是有效的,同时multi-task multi-modal学习的框架是有效的。最终的实验回答了以下几个问题:
-
multi-task学习框架是否合理?
-
除了知识补全(knowledge completion),PKG如何提升在下游(downstream)的任务表现?
-
为什么KG直接应用在e-commerce的数据上是不可行的?
-
本文提出的方法是否比直接用KG的方法来学产品间的关系更好?
1 数据
products:14万的grocery产品
description:每个产品有一段文本描述,通常为20-100词。
category:每个产品都在一个种类分类下,总有有1198个次分类,228个大分类,28个department,9个super-department。
session 数据:约四百万条view,purchase,search和被点击的search结果。
substitute:7万个产品间的可替代信息。
PRG的建立:通过对session数据的统计,首先建立一个初步的有权PKG,之后通过random walk找到top-k的相关邻居,再将其与相关的邻居相连接。
2 对比结果
实验对比了Translation based模型以及latent semantic 模型。No PRG代表不进行random walk来筛选邻居,而直接使用原始数据。
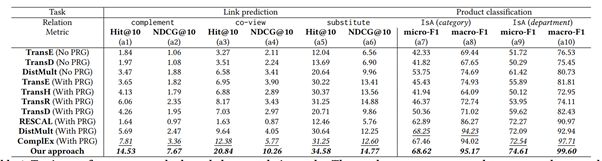
由于篇幅限制,不再详细介绍实验的具体细节,可以自行搜索该文章进行阅读。
总结
本文介绍了如何建立PKG,并且如何在eCommerce的场景下来学习embedding。但是有几个问题本文并没有很好的回答:
-
attention 的系数为什么仅用输入和输出的embedding来得到,而不是像NLP model中的attention weights?
-
通过翻译模型来理解sequence,但是第l个entity与前l-1个entities之间的位置信息关系可能并不是非常相关?
-
在eCommerce场景下非常重要的user信息该如何变成PKG的一部分呢?
相关文章:
-
Slides | 利用知识图网络做常识推理
-
SIGIR‘19 | 图神经网络协同过滤算法-Neural Graph Collaborative Filtering
-
QQ音乐上市,让我们来谈谈音乐播放器中的推荐算法
-
一文读懂自注意力机制:8大步骤图解+代码
References
[1] Julian McAuley, Rahul Pandey, and Jure Leskovec. 2015. Inferring networks of substitutable and complementary products. In Proceedings of the 21th ACM SIGKDD international conference on knowledge discovery and data mining. ACM, 785–794.
[2] Yin Zhang, Haokai Lu, Wei Niu, and James Caverlee. 2018. Quality-aware neural complementary item recommendation. In Proceedings of the 12th ACM Conference on Recommender Systems. ACM, 77–85.
[3] Victor Sanh, Thomas Wolf, and Sebastian Ruder. 2019. A hierarchical multi-task approach for learning embeddings from semantic tasks. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 33. 6949–6956.
[4] Xu, Da, et al. "Product Knowledge Graph Embedding for E-commerce." Proceedings of the 13th International Conference on Web Search and Data Mining. 2020.
阅读原文
阅读更多,欢迎关注公众号:论文收割机(paper_reader)
因为排版问题,很多图片和公式无法直接显示,欢迎关注我们的公众号点击目录来阅读原文。