Sequential Monte Carlo Methods (SMC) 序列蒙特卡洛/粒子滤波/Bootstrap Filtering
Problem Statement
我们考虑一个具有马尔可夫性质、非线性、非高斯的状态空间模型(State Space Model):对于一个时间序列上的观测结果 { y t , t ∈ N } \{ y_t , t \in N \} {yt,t∈N},我们认为每个观测结果 y t y_t yt的生成依赖于一个无法直接观察的隐变量 x t ∈ { x t , t ∈ N } x_t \in \{x_t , t \in N \} xt∈{xt,t∈N},即: p ( y t ∣ x t ) , t ∈ [ 1 , N ] p(y_t|x_{t}), t \in [1,N] p(yt∣xt),t∈[1,N];我们假设隐变量具有一个先验的状态转移函数 p ( x t ∣ x t − 1 ) , t ∈ [ 1 , N ] p(x_t | x_{t-1}), t \in [1,N] p(xt∣xt−1),t∈[1,N],若给定一个初始分布 p ( x 0 ) p(x_0) p(x0),那么这个模型就能由这三个参数描述: p ( x 0 ) , p ( x t ∣ x t − 1 ) , p ( y t ∣ x t ) p(x_0),p(x_t| x_{t-1}),p(y_t|x_t) p(x0),p(xt∣xt−1),p(yt∣xt)。这里,我们定义到时间 t t t的观察序列: x 0 : t = { x 0 , … , x t } \mathbf{x_{0:t}}=\{ x_0, \dots, x_t\} x0:t={x0,…,xt}和对应的隐变量序列 y 1 : t = { y 1 , … , y t } \mathbf{y_{1:t}}=\{ y_1, \dots, y_t\} y1:t={y1,…,yt}。
我们关心如何根据当前的观测序列来推断(infer)隐变量序列,即估计一个后验概率分布 p ( x 0 : t ∣ y 1 : t ) p(\mathbf{x_{0:t}| y_{1:t}}) p(x0:t∣y1:t),和它的边缘概率分布: p ( x t ∣ y 1 : t ) p(x_{t}| \mathbf{y_{1:t}}) p(xt∣y1:t) (这里通常被称为滤波, filtering) ,以及它对于某个函数 f t f_t ft的期望:
I ( f t ) = E p ( x 0 : t ∣ y 1 : t ) f t ( x 0 ; t ) = ∫ p ( x 0 : t ∣ y 1 : t ) f t ( x 0 ; t ) d x 1 : t I(f_t) = \mathbb{E}_{p(\mathbf{x_{0:t}| y_{1:t}})} f_t(\mathbf{x_{0;t}}) = \int p(\mathbf{x_{0:t}| y_{1:t}}) f_t(\mathbf{x_{0;t}}) d_{\mathbf{x_{1:t}}} I(ft)=Ep(x0:t∣y1:t)ft(x0;t)=∫p(x0:t∣y1:t)ft(x0;t)dx1:t
在任何时间 t t t,我们可以推导 p ( x 0 : t + 1 ∣ y 1 : t + 1 ) p(\mathbf{x_{0:t+1}| y_{1:t+1}}) p(x0:t+1∣y1:t+1)和 p ( x 0 : t ∣ y 1 : t ) p(\mathbf{x_{0:t}| y_{1:t}}) p(x0:t∣y1:t)之间的关系:
p ( x 0 : t + 1 ∣ y 1 : t + 1 ) = p ( x 0 : t + 1 , y 1 : t + 1 ) p ( y 1 : t + 1 ) = p ( x 0 : t + 1 , y t + 1 ∣ y t ) p ( y 1 : t ) p ( y 1 : t + 1 ) = p ( x 0 : t ∣ y 1 : t ) p ( y t + 1 , x t + 1 ∣ x 0 : t , y 1 : t ) p ( y 1 : t ) p ( y 1 : t , y t + 1 ) = p ( x 0 : t ∣ y 1 : t ) p ( x t + 1 ∣ y 1 : t , x 0 : t ) p ( y t + 1 ∣ x 0 : t , y 1 : t , x t + 1 ) p ( y 1 : t ) p ( y t + 1 ∣ y 1 : t ) p ( y 1 : t ) = p ( x 0 : t ∣ y 1 : t ) p ( x t + 1 ∣ x t ) p ( y t + 1 ∣ x t + 1 ) p ( y t + 1 ∣ y 1 : t ) \begin{aligned} {p(\mathbf{x_{0:t+1}| y_{1:t+1}})} &= \frac {p(\mathbf{x_{0:t+1}, y_{1:t+1}})} {p(\mathbf{y_{1:t+1}})} \\ &= \frac{p (\mathbf{x_{0:t+1}},y_{t+1}|\mathbf{y}_t) p(\mathbf{y_{1:t}})}{p(\mathbf{y_{1:t+1}})} \\ &= \frac {p(\mathbf{x_{0:t}}|\mathbf{y_{1:t}})p(y_{t+1},x_{t+1}|\mathbf{x_{0:t}},\mathbf{y_{1:t}}) p(\mathbf{y_{1:t}}) }{p(\mathbf{y_{1:t}},y_{t+1})} \\ &= \frac {p(\mathbf{x_{0:t}}|\mathbf{y_{1:t}})p(x_{t+1}|\mathbf{y_{1:t}},\mathbf{x_{0:t}})p(y_{t+1}|\mathbf{x_{0:t}},\mathbf{y_{1:t}},x_{t+1}) p(\mathbf{y_{1:t}}) }{p(y_{t+1}| \mathbf{y_{1:t}}) p(\mathbf{y_{1:t}})} \\&= p(\mathbf{x_{0:t}}|\mathbf{y_{1:t}}) \frac {p(x_{t+1}|x_t) p(y_{t+1}|x_{t+1}) }{p(y_{t+1}|\mathbf{y_{1:t}})} \end{aligned} p(x0:t+1∣y1:t+1)=p(y1:t+1)p(x0:t+1,y1:t+1)=p(y1:t+1)p(x0:t+1,yt+1∣yt)p(y1:t)=p(y1:t,yt+1)p(x0:t∣y1:t)p(yt+1,xt+1∣x0:t,y1:t)p(y1:t)=p(yt+1∣y1:t)p(y1:t)p(x0:t∣y1:t)p(xt+1∣y1:t,x0:t)p(yt+1∣x0:t,y1:t,xt+1)p(y1:t)=p(x0:t∣y1:t)p(yt+1∣y1:t)p(xt+1∣xt)p(yt+1∣xt+1)
Monte Carlo Sampling
假设我们能够从 p ( x 0 : t ∣ y 0 : t ) p(\mathbf{x_{0:t}}|\mathbf{y_{0:t}}) p(x0:t∣y0:t)生成N个独立同分布的随机样本(也被称为粒子particles),那么 f t f_t ft的期望可以用以下表示:
I N ( f t ) = 1 N ∑ i = 1 N f t ( x 0 : t ( i ) ) I_N(f_t) = \frac{1}{N} \sum_{i=1}^N f_t(\mathbf{x^{(i)}_{0:t}}) IN(ft)=N1i=1∑Nft(x0:t(i))
当N足够大时,蒙特卡洛采样能够无偏估计 f t f_t ft的期望,然而我们通常是不知道先验分布 p ( x 0 : t ∣ y 0 : t ) p(\mathbf{x_{0:t}}|\mathbf{y_{0:t}}) p(x0:t∣y0:t)的,因此采样的样本是随机采样的,这就会导致这种方法效率不会很高,尤其是当随机采样的分布与 p ( x 0 : t ∣ y 0 : t ) p(\mathbf{x_{0:t}}|\mathbf{y_{0:t}}) p(x0:t∣y0:t)的分布相差较大时。
Importance Sampling (IS)
为了解决采样效率问题,我们引用一个重要性分布 π ( x 0 : t ∣ y 0 : t ) \pi(\mathbf{x_{0:t}}|\mathbf{y_{0:t}}) π(x0:t∣y0:t)来代替之前蒙特卡洛方法里的随机采样,那么采样权重(importance weight)可以表示为:
w ( x 0 : t ) = p ( x 0 : t ∣ y 0 : t ) π ( x 0 : t ∣ y 0 : t ) w(\mathbf{x_{0:t}})= \frac { p(\mathbf{x_{0:t}}|\mathbf{y_{0:t}})} {\pi(\mathbf{x_{0:t}}|\mathbf{y_{0:t}})} w(x0:t)=π(x0:t∣y0:t)p(x0:t∣y0:t)
则 f t f_t ft的期望可以被写成:
I ( f t ) = ∫ f t ( x 0 : t ) p ( x 0 : t ∣ y 0 : t ) d x 0 : t = ∫ π ( x 0 : t ∣ y 0 : t ) p ( x 0 : t ∣ y 0 : t ) π ( x 0 : t ∣ y 0 : t ) f t ( x 0 : t ) d x 0 : t = E π ( x 0 : t ∣ y 0 : t ) [ w ( x 0 : t ) f t ( x 0 : t ) ] = 1 N ∑ i = 1 N [ w ( x 0 : t ( i ) ) f t ( x 0 : t ( i ) ) ] \begin{aligned} I(f_t) &= \int f_t(\mathbf{x_{0:t}}) p(\mathbf{x_{0:t}}|\mathbf{y_{0:t}}) d_{\mathbf{x_{0:t}}} \\ &= \int \pi(\mathbf{x_{0:t}}|\mathbf{y_{0:t}}) \frac { p(\mathbf{x_{0:t}}|\mathbf{y_{0:t}})} {\pi(\mathbf{x_{0:t}}|\mathbf{y_{0:t}})} f_t(\mathbf{x_{0:t}}) d_{\mathbf{x_{0:t}}} \\&= \mathbb{E}_{\pi(\mathbf{x_{0:t}}|\mathbf{y_{0:t}})} [w(\mathbf{x_{0:t}})f_t(\mathbf{x_{0:t}})] \\ &= \frac{1}{N} \sum_{i=1}^N [w(\mathbf{x^{(i)}_{0:t}}) f_t(\mathbf{x^{(i)}_{0:t}})] \end{aligned} I(ft)=∫ft(x0:t)p(x0:t∣y0:t)dx0:t=∫π(x0:t∣y0:t)π(x0:t∣y0:t)p(x0:t∣y0:t)ft(x0:t)dx0:t=Eπ(x0:t∣y0:t)[w(x0:t)ft(x0:t)]=N1i=1∑N[w(x0:t(i))ft(x0:t(i))]
我们还可以推导另外一种写法:由于 ∫ p ( x ) d x = 1 \int p(x)dx=1 ∫p(x)dx=1,有 ∫ π ( x ) w ( x ) d x = 1 \int \pi(x)w(x)dx=1 ∫π(x)w(x)dx=1,因此 E π ( x ) w ( x ) = 1 \mathbb{E}_{\pi(x)}w(x)=1 Eπ(x)w(x)=1,然后得到 1 N w ( x ) = 1 \frac{1}{N}w(x)=1 N1w(x)=1,即 w ( x ) = N w(x)=N w(x)=N,则上面的式子可以被这么写:
I ( f t ) = 1 N ∑ i = 1 N [ w t ( i ) f t ( x 0 : t ( i ) ) ] = ∑ i = 1 N [ w t ( i ) N f t ( x 0 : t ( i ) ) ] = ∑ i = 1 N [ w t ( i ) ∑ w t ( i ) f t ( x 0 : t ( i ) ) ] = ∑ i = 1 N w t ~ f t ( x 0 : t ( i ) ) \begin{aligned} I(f_t) &= \frac{1}{N} \sum_{i=1}^N [w_t^{(i)} f_t(\mathbf{x^{(i)}_{0:t}})] \\ & = \sum_{i=1}^N [\frac{w_t^{(i)}}{N} f_t(\mathbf{x^{(i)}_{0:t}})] \\ & = \sum_{i=1}^N [\frac{w_t^{(i)}}{\sum w_t^{(i)}} f_t(\mathbf{x^{(i)}_{0:t}})] \\ &= \sum_{i=1}^N \tilde{w_t}f_t(\mathbf{x^{(i)}_{0:t}}) \end{aligned} I(ft)=N1i=1∑N[wt(i)ft(x0:t(i))]=i=1∑N[Nwt(i)ft(x0:t(i))]=i=1∑N[∑wt(i)wt(i)ft(x0:t(i))]=i=1∑Nwt~ft(x0:t(i))
这里的 w t ~ = w t ( x ) ∑ w t ( x ) \tilde{w_t}=\frac{w_t(x)}{\sum w_t(x)} wt~=∑wt(x)wt(x)是一个归一化后的采样权重(normalized importance weight),重要性采样IS是一个通用的蒙特卡洛方法,但是由于它的表现形式,它在时间序列上并不能进行递归估计,比如:为了计算 p ( x 0 : t ∣ y 0 : t ) p(\mathbf{x_{0:t}}|\mathbf{y_{0:t}}) p(x0:t∣y0:t),IS需要获得所有的 y 0 : t \mathbf{y_{0:t}} y0:t然后才能进行计算,然后当新的 y t + 1 y_{t+1} yt+1到来时,IS需要重新在整个观测序列 y 0 : t + 1 \mathbf{y_{0:t+1}} y0:t+1上来计算,时间复杂度高,因此我们接下来介绍在时间序列上的重要性采样。
Sequential Importance Sampling (SIS)
我们能够扩展IS方法,使它在 t + 1 t+1 t+1时刻的计算能够使用 t t t时刻的计算结果。我们先将重要性函数 π ( x 0 : t ∣ y 1 : t ) \pi(\mathbf{x_{0:t}|y_{1:t}}) π(x0:t∣y1:t)用 t − 1 t-1 t−1时刻描述:
π ( x 0 : t ∣ y 1 : t ) = π ( x 0 : t − 1 ∣ y 1 : t ) π ( x t ∣ x 0 : t − 1 , y 1 : t ) = π ( x 0 : t − 1 ∣ y 1 : t − 1 ) π ( x t ∣ x 0 : t − 1 , y 1 : t ) \begin{aligned} \pi(\mathbf{x_{0:t}|y_{1:t}}) &= \pi(\mathbf{x_{0:t-1}|y_{1:t}})\pi(x_t| \mathbf{x_{0:t-1},y_{1:t}}) \\ &= \pi(\mathbf{x_{0:t-1}|y_{1:t-1}})\pi(x_t| \mathbf{x_{0:t-1},y_{1:t}}) \\ \end{aligned} π(x0:t∣y1:t)=π(x0:t−1∣y1:t)π(xt∣x0:t−1,y1:t)=π(x0:t−1∣y1:t−1)π(xt∣x0:t−1,y1:t)
于是我们有:
π ( x 0 : t ∣ y 1 : t ) = π ( x 0 ) ∏ k t π ( x k ∣ x 0 : k − 1 , y 1 : k ) \begin{aligned} \pi(\mathbf{x_{0:t}|y_{1:t}}) &= \pi(x_0) \prod_k^t \pi(x_k|\mathbf{x_{0:k-1},y_{1:k}}) \end{aligned} π(x0:t∣y1:t)=π(x0)k∏tπ(xk∣x0:k−1,y1:k)
到这里,由于我们可以推导出 p ( x 0 : t ∣ y 1 : t ) p(\mathbf{x_{0:t}}|\mathbf{y_{1:t}}) p(x0:t∣y1:t)和 π ( x 0 : t ∣ y 1 : t ) \pi(\mathbf{x_{0:t}}|\mathbf{y_{1:t}}) π(x0:t∣y1:t)关于 t − 1 t-1 t−1时刻的计算,则对于重要性权重 w t w_t wt我们同样有:
w t ( i ) ( x 0 : t ) = p ( x 0 : t ( i ) ∣ y 1 : t ( i ) ) π ( x 0 : t ( i ) ∣ y 1 : t ( i ) ) = p ( x 0 : t − 1 ( i ) ∣ y 1 : t − 1 ( i ) ) π ( x 0 : t − 1 ( i ) ∣ y 1 : t − 1 ( i ) ) p ( x t ( i ) ∣ x t − 1 ( i ) ) p ( y t ∣ x t ( i ) ) p ( y t ∣ y 1 : t − 1 ) π ( x t ∣ x 0 : t − 1 ( i ) , y 1 : t ) = w t − 1 ( i ) ( x 0 : t − 1 ( i ) ) p ( x t ( i ) ∣ x t − 1 ( i ) ) p ( y t ∣ x t ( i ) ) p ( y t ∣ y 1 : t − 1 ) π ( x t ( i ) ∣ x 0 : t − 1 ( i ) , y 1 : t ) \begin{aligned} w^{(i)}_t(\mathbf{x_{0:t}}) &= \frac { p(\mathbf{x_{0:t}}^{(i)}|\mathbf{y_{1:t}}^{(i)})} {\pi(\mathbf{x_{0:t}}^{(i)}|\mathbf{y_{1:t}}^{(i)})} \\ &= \frac { p(\mathbf{x_{0:t-1}}^{(i)}|\mathbf{y_{1:t-1}}^{(i)})} {\pi(\mathbf{x_{0:t-1}}^{(i)}|\mathbf{y_{1:t-1}}^{(i)})} \frac {p(x_{t}^{(i)}|x_{t-1}^{(i)}) p(y_{t}|x_{t}^{(i)}) }{p(y_{t}| \mathbf{y_{1:{t-1}}}) \pi(x_t|\mathbf{x_{0:t-1}}^{(i)}, \mathbf{y_{1:t}}) } \\ &= w^{(i)}_{t-1}(\mathbf{x_{0:t-1}}^{(i)}) \frac {p(x_{t}^{(i)}|x_{t-1}^{(i)}) p(y_{t}|x_{t}^{(i)}) }{p(y_{t}|\mathbf{y_{1:t-1}}) \pi(x_t^{(i)}|\mathbf{x_{0:t-1}}^{(i)},\mathbf{y_{1:t}}) } \end{aligned} wt(i)(x0:t)=π(x0:t(i)∣y1:t(i))p(x0:t(i)∣y1:t(i))=π(x0:t−1(i)∣y1:t−1(i))p(x0:t−1(i)∣y1:t−1(i))p(yt∣y1:t−1)π(xt∣x0:t−1(i),y1:t)p(xt(i)∣xt−1(i))p(yt∣xt(i))=wt−1(i)(x0:t−1(i))p(yt∣y1:t−1)π(xt(i)∣x0:t−1(i),y1:t)p(xt(i)∣xt−1(i))p(yt∣xt(i))
对于当前 t t t时刻来说, p ( y t ∣ y 1 : t − 1 ) p(y_{t}|\mathbf{y_{1:t-1}}) p(yt∣y1:t−1)是确定的,而且对于所有的采样样本 x 0 : t ( i ) , i ∈ N \mathbf{x_{0:t}}^{(i)},i \in N x0:t(i),i∈N都一致,因此还我们可以这么表示 w ~ t ( i ) \tilde w^{(i)}_t w~t(i)的更新:
w ~ t ( i ) ( x 0 : t ) ∝ w ~ t − 1 ( i ) ( x 0 : t − 1 ) p ( x t ∣ x t − 1 ) p ( y t ∣ x t ) π ( x t ∣ x 0 : t − 1 , y 1 : t ) \begin{aligned} \tilde w^{(i)}_t(\mathbf{x_{0:t}}) & \propto \tilde w^{(i)}_{t-1}(\mathbf{x_{0:t-1}}) \frac {p(x_{t}|x_{t-1}) p(y_{t}|x_{t}) }{\pi(x_t|\mathbf{x_{0:t-1},y_{1:t}}) } \end{aligned} w~t(i)(x0:t)∝w~t−1(i)(x0:t−1)π(xt∣x0:t−1,y1:t)p(xt∣xt−1)p(yt∣xt)
当我们采用先验分布作为重要性分布时,我们的重要性函数变成了:
π ( x 0 : t ∣ y 1 : t ) = p ( x 0 : t ) = p ( x 0 ) ∏ k = 1 t π ( x k ∣ x k − 1 ) \begin{aligned} \pi(\mathbf{x_{0:t}|y_{1:t}}) &= p(\mathbf{x_{0:t}}) =p(x_0) \prod_{k=1}^t \pi(x_k|x_{k-1}) \end{aligned} π(x0:t∣y1:t)=p(x0:t)=p(x0)k=1∏tπ(xk∣xk−1)
因此 w w w的更新被简化为: w ~ t ( i ) ( x 0 : t ) ∝ w ~ t − 1 ( i ) ( x 0 : t − 1 ) p ( y t ∣ x t ( i ) ) \tilde w^{(i)}_t(\mathbf{x_{0:t}}) \propto \tilde w^{(i)}_{t-1}(\mathbf{x_{0:t-1}}) p (y_{t}|x_t^{(i)}) w~t(i)(x0:t)∝w~t−1(i)(x0:t−1)p(yt∣xt(i))。SIS是一个不错的方法,但本质上就是一个带约束的重要性采样方法,但是它在高维度空间的计算并不是很有效,比如当 t t t非常大时。
Bootstrap Filtering = Resampling + SIS
SIS的问题是:当t增加时,重要性权重的分布的计算会越来越不准确,尤其是当时间t达到一定量时,通常只有很少的样本(粒子)是有非零权重的,而大部分样本(粒子)的权重都是0,因此会让这个采样分布无法正确描述出先验分布。为了处理这种退化(degeneracy),我们需要加入一个额外的重采样(resampling)步骤。
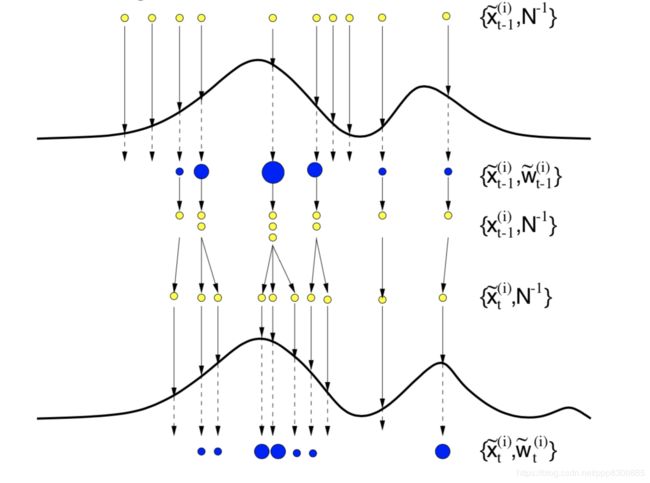
重采样的目的是扩增(multiply)那些权值较高的粒子个数而减少(eliminate)权值低的粒子,具体来说,假设一个粒子具有 w ~ t \tilde w_t w~t权值,重采样会在此粒子附近再采样 N w ~ t N \tilde w_t Nw~t个粒子,若 w ~ t = 0 \tilde w_t=0 w~t=0,那么这个粒子会被淘汰(dead),剩下的(serviving)粒子会进入到下一个时刻,注意重采样完后的每个粒子的权值都变成了: w ~ t ( i ) = 1 N , i ∈ N \tilde w_t^{(i)}=\frac{1}{N}, i \in N w~t(i)=N1,i∈N。
假设我们的重要性采样分布就是先验分布,那么Boostrap Filtering的过程可以被如下归纳:
- 初始化 N N N个粒子: { x 0 ( i ) = p ( x 0 ) , i ∈ N } \{x^{(i)}_0=p(x_0),i\in N\} {x0(i)=p(x0),i∈N},令 t = 1 t=1 t=1。
- 采样 N N N个粒子: { x ^ t ( i ) ∼ p ( x t ∣ x t − 1 ( i ) ) , i ∈ N } \{\hat x_t^{(i)} \sim p(x_t|x_{t-1}^{(i)}),i \in N\} {x^t(i)∼p(xt∣xt−1(i)),i∈N},对于每个粒子,更新其采样轨迹: x ^ 0 : t ( i ) = ( x 0 : t − 1 ( i ) , x ^ t ( i ) ) \mathbf {\hat x_{0:t}}^{(i)} = (\mathbf {x_{0:t-1}}^{(i)},\hat x_t^{(i)}) x^0:t(i)=(x0:t−1(i),x^t(i))。
- 估计每个粒子的权重: w t ( i ) = p ( y t ∣ x ^ t ( i ) ) w_t^{(i)}=p(y_t|\hat x_t^{(i)}) wt(i)=p(yt∣x^t(i)) 并归一化得到 w ~ t ( i ) \tilde w_t^{(i)} w~t(i)(由于上一步的重采样使 w t − 1 ( i ) w_{t-1}^{(i)} wt−1(i)都相同,所以不需要参与权重计算)。
- 根据每个粒子的权重 w ~ t ( i ) \tilde w_t^{(i)} w~t(i),从 { x ^ t ( i ) , i ∈ N } \{\hat x_{t}^{(i)},i \in N\} {x^t(i),i∈N}中重新采样N个粒子: { x t ( i ) , i ∈ N } \{ x_{t}^{(i)},i \in N\} {xt(i),i∈N},更新 x 0 : t ( i ) = ( x 0 : t − 1 ( i ) , x t ( i ) ) \mathbf { x_{0:t}}^{(i)} = (\mathbf {x_{0:t-1}}^{(i)}, x_t^{(i)}) x0:t(i)=(x0:t−1(i),xt(i)),此时 w ~ t ( i ) = 1 N \tilde w_t^{(i)}=\frac{1}{N} w~t(i)=N1。
- 重复2-4步骤,且 t = t + 1 t=t+1 t=t+1
Bootstrap Filtering有几个优点:1. 易实现,计算简单;2. 扩展性好,当迁移至别的问题时,只需要更改重要性采样分布即可;3. 天然支持并行计算,4.重采样过程可以看成是一种黑匣子,输入当前的权值和粒子索引,输出每个粒子要重采样的次数,因此这种黑匣子有很多种实现方法,这样可以支持很多的复杂的模型在时间序列上进行推断(inference)
Conclusion
这种方法其实代表了一种时间序列上的推断框架,它有很多名字:粒子滤波 / Bootstrap Filtering / 序列化蒙特卡洛 / 序列化重要性采样 + 重采样,这种通用的思想可以被用到很多具体的推断问题上,特别是partially observed问题,如机器人定位,partially observed MDP (POMDPs)。借用一张图来表示Bootstrap Filtering:
Reference
https://www.stats.ox.ac.uk/~doucet/doucet_defreitas_gordon_smcbookintro.pdf