Flink最佳实践(二)Flink流式计算系统
前言
在 Flink最佳实践(一)流式计算系统概述 中,我们详细讨论了流式计算系统中 时域、窗口、时间推理与正确性工具 等概念。
本文将以这些概念为基础,逐一介绍 Flink 的 发展背景、核心概念、时间推理与正确性工具、安装部署、客户端操作、编程API 等内容,让开发人员对 Flink 有较为全面的认识并拥有一些基础操作与编程能力。
一、发展背景
1.1 数据处理架构
在流处理器出现之前,数据处理架构主要由批处理器组成,其是对 无限数据的有限切分,具有 吞吐量大、数据较为准确 的特点。
然而我们知道,批处理器在时间切分点附近 仍然无法保证数据结果的真实性,且数据的时效性往往比较低,延迟大。
除了批处理之外,人们为了达到数据生成的高时效性,在数据处理架构中也常常使用微服务来解决,其特点是 延迟低、无状态、服务与存储分离。
但是微服务无状态的约束很大程度上决定了其并不能很好的应用于现代实时数据处理的需求中,比如准确一次的语义、乱序数据流的处理能力等,它无法满足人们对一个先进的流处理器的想象(在无状态的业务需求中,微服务仍然是最佳选择)。
而要满足人们的这些想象,数据处理架构恰恰需要有 「状态」 的概念和相应的机制支持才行。
由此 有状态的流处理器 开始逐渐完善并大规模使用。
有状态的流处理器依赖 高可用可重放的数据源,通过 State(状态)提供准确一次的语义,通过 时间推理工具能够还原真实世界的数据情况,广泛应用于 事件驱动(实时警报)、数据管道(实时数仓)、数据分析(实时报表) 等业务场景中。
高可用可重放的数据源:
- 持久化的、只添加的
- 写入顺序不可变
- 多个消费者多次消费
- 可信的数据源、可重放
1.2 开源分布式流处理器
开源流处理器在不断地发展,从一开始只关注低延迟指标到现在兼顾延迟、吞吐与结果准确性,在发展过程中解决了很多问题,编程API的易用性也在不断地提高。
第一代
- 关注 毫秒级延迟 的事件处理
- 数据丢失与处理简单,容易造成结果不够精确
- 牺牲了部分的准确性来换取更低的延迟
- 只有底层API接口
第二代
- 更好的容错,确保在发生故障的时候仅仅处理一次
- 提供高级API编程接口
- 可能 牺牲延迟到秒级
- 结果取决于事件到达的顺序
第三代
- 精准一次的语义,批流都可应用计算
- 兼顾延迟、吞吐与结果准确性
- 解决了依赖于时间和事件到达顺序的问题
二、核心概念
了解完流处理器的发展背景后,我们来详细讨论一下 Flink 中的核心概念,这些概念是学习与使用 Flink 十分重要的基础知识,在后续开发 Flink 程序过程中将会帮助开发人员更好地理解 Flink 内部的行为和机制。
本节中相关核心概念摘抄自 Flink最佳实践(一)流式计算系统概述 ,该文中对流处理器核心概念有详细的讨论与说明,这里不再过多累述。
2.1 Time(时间语义)
和其他流处理器一样,Flink 中的 Time 也分为三种:事件时间、达到时间与处理时间。
事件时间
事件时间是 事件真实发生的时间。
由于数据乱序的原因,服务端收到数据时的时间和事件本身的时间可能是相差极大的。
正是因为这种差异,服务端做基于事件时间的计算是 最复杂的,需要对乱序的数据流做处理以 「还原」 真实世界的情况,需要依赖一定的数据缓存。
- 迟到与乱序处理
- 延迟较高
达到时间
达到时间是 系统接收到事件的时间,即服务端接收到事件的时间。
处理时间
处理时间是 系统开始处理到达事件的时间。
在某些场景下,处理时间等于达到时间。
因为处理时间 没有乱序 的问题,所以服务端做基于处理时间的计算是比较简单的,无迟到与乱序数据。
- 不需要考虑迟到和乱序
- 有较低的延迟
Flink 中只需要通过 env环境变量即可设置Time:
//创建环境上下文
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 设置在当前程序中使用 ProcessingTime
env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime);
2.2 Window(窗口)
在时间语义(时域)之上,对数据流的操作分为与时间无关的、与时间有关的两种类型,其中与时间有关的操作都与窗口操作挂钩。
基于各类时间的窗口处理 是流处理器中主要的与时间有关的操作,窗口本质就是将无限数据集 沿着时间的边界切分成有限数据集。
没有窗口,就没法在时间维度上划分数据集,也就没法进行后续的数据操作。
在 Flink 中,当 属于这个窗口的第一个元素到达时就会创建一个窗口。
当时间(事件或处理时间)超过窗口的结束时间戳加上用户指定的最大允许延迟时间时,窗口就会被完全删除。
这就是 Flink 窗口的生命周期。
Flink 中的每个窗口都有一个 触发器和执行函数:
- 触发器定义窗口何时触发
- 执行函数定义触发时的计算逻辑
除此之外,窗口还可以定义一个 回收器,用来在 窗口触发后、计算执行前(后) 排除或者回收指定的元素。
Keyed 与 Non-Keyed Windows
Flink 中有两大类型的窗口:Keyed Windows 和 Non-keyed Windows,两种类型的窗口操作API有细微的差别:

在 Keyed Windows 中,stream 需要通过 keyBy和 window方法生成,而在 Non-Keyed Windows 中,stream 只需要通过 windowAll方法即可生成。
在随后的API中两者并没有差异:
- trigger: 设置窗口触发器,没有设置则使用默认触发器
- evictor: 设置窗口触发后、计算执行前,前置的数据过滤器,没有则无
- allowedLateness: 窗口允许的最大延迟,没有则无
- sideOutputLateData: 获取延迟的数据并可以使用
reduce/aggregate/fold/apply进行处理 - getSideOutput: 获取延迟的数据
以上方法都是可选调用。
在定义窗口之前,开发人员必须先定义数据流是否根据key分组,使用 keyBy函数即可将数据流划分为 Keyed Stream,如果 keyBy没有被调用,则数据流为 Non-Keyed。
在 Keyed Stream 中,所有的数据都会根据指定的key分配到并行的流中,所以 Keyed Stream 可以进行高效的并行操作,相同key的数据将会被分配到相同的并行任务中。
在 Non-Keyed Stream 中,数据不会被分割成多个并行的逻辑流,即并行度为1。
2.3 State(状态)与Checkpoint(检查点)
Flink 中,状态用于缓存 用户数据、窗口数据、程序运行时状态、数据源偏移量 等信息,而检查点则是 定期对状态备份并提供恢复能力的机制。
正是因为有状态与检查点的支持,Flink才能做到:
- 备份与恢复、7 * 24小时运行的容错
- 数据不重复不丢失,精准一次
- 数据实时产出不延迟
- 横向扩展
- 数据之间有关联,需要通过状态满足业务逻辑
- 系统状态(窗口缓冲区)、用户自定义状态
2.4 一致性保证
一致性保证通常也被称为一致性语义,是流处理器的能力体现。
至多一次
- 事件可以被简单的丢弃
- 等于「无保证」
- 可以得到近似的结果,尽可能低的延迟
至少一次
- 所有事件都会被处理,但是可能处理了多次
- 数据源可重放即可
- 可以得到近似的结果
仅仅一次
- 数据源需要支持重放
- 处理器需要保持状态一致
三、正确性与时间推理工具
Flink 中保持强正确性的工具是 State 和 Checkpoint,提供时间推理能力的工具是 Watermark 和 Trigger。
接下来我们来详细讨论Flink中,这些工具是如何使用和实现的。
3.1 State
3.1.1 状态类别
Flink 有两种状态提供给开发人员使用:Managed State 和 Raw State。
Managed State
Managed State 是由flink runtime管理来管理的,自动存储、自动恢复,在内存管理上有优化机制。
且 Managed State 支持常见的多种数据结构,如value、list、map等,在大多数业务场景中都有适用之处。
总体来说是对开发人员来说是比较友好的,因此 Managed State 是 Flink 中最常用的状态。
Managed State 又分为 Keyed State 和 Operator State 两种。
Keyed State 只能用在 KeyedStream 上的算子中,每个key对应一个state,可以通过flink runtimecontext访问。
支持的数据结构有:
- ValueState
- MapState
- AppendingState
等,其中 AppendingState 还有不同的子类实现,详细的使用信息可以参考 Flink官网。
而 Operator State 可用于所有算子(常用于Source),一个Operator实例对应一个State,支持的数据结构:List 等。
Raw State
Raw State 由用户自己管理,需要序列化,只能使用字节数组的数据结构。
Raw State 的使用和维度都比 Managed State 要复杂,建议在自定义的Operator场景中酌情使用。
3.1.2 状态存储
Flink中状态的实现有三种:MemoryState、FsState、RocksDBState。
三种状态存储方式与使用场景各不相同,详细介绍如下:
MemoryStateBackend
- 构造函数:MemoryStateBackend(int maxStateSize, boolean asyncSnapshot)
- 存储方式:State存储于各个 TaskManager内存中,Checkpoint存储于 JobManager内存
- 容量限制:单个State最大5M、maxStateSize<=akka.framesize(10M)、总大小不超过JobManager内存
- 使用场景:无状态或者JobManager挂掉不影响的测试环境等,不建议在生产环境使用
FsStateBackend
- 构造函数:FsStateBackend(URI checkpointUri, boolean asyncSnapshot)
- 存储方式:State存储于 TaskManager内存,Checkpoint存储于 外部文件系统(本次磁盘 or HDFS)
- 容量限制:State总量不超过TaskManager内存、Checkpoint总大小不超过外部存储空间
- 使用场景:常规使用状态的作业,分钟级的窗口聚合等,可在生产环境使用
RocksDBStateBackend
- 构造函数:RocksDBStateBackend(URI checkpointUri, boolean enableincrementCheckpoint)
- 存储方式:State存储于 TaskManager上的kv数据库(内存+磁盘),Checkpoint存储于 外部文件系统(本次磁盘 or HDFS)
- 容量限制:State总量不超过TaskManager内存+磁盘、单key最大2g、Checkpoint总大小不超过外部存储空间
- 使用场景:超大状态的作业,天级的窗口聚合等,对读写性能要求不高的场景,可在生产环境使用
根据业务场景需要用户选择最合适的 StateBackend ,代码中只需在相应的 env 环境中设置即可:
// flink 上下文环境变量
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 设置状态后端为 FsStateBackend,数据存储到 hdfs /tmp/flink/checkpoint/test 中
env.setStateBackend(new FsStateBackend("hdfs://ns1/tmp/flink/checkpoint/test", false))
3.1.3 状态保存与迁移
Flink 中将会按照用户的设置,定时执行 Checkpoint 对状态进行备份,这是 Flink 的自动保存机制。
除了自动保存之外,Flink 还提供了 Savepoint 的手动保存方式:
# flink命令行工具中手动触发savepoint
bin/flink savepoint -m 127.0.0.1:8081 任务id /tmp/savepoint
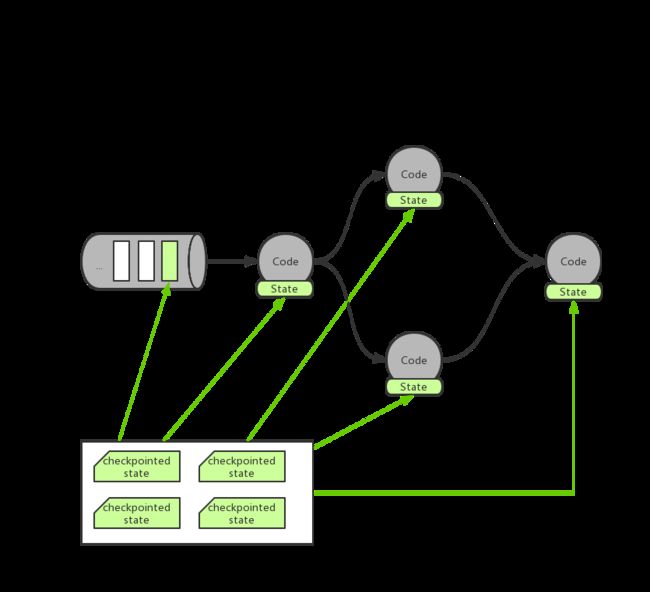
Savepoint 是一种手动触发执行的 全量Checkpoint,其会立即在当前数据中插入checkpoint barrier,立即生产快照备份。
只要 Checkpoint 的快照备份信息存在,则 Flink 程序就可以根据这份数据进行迁移改造等操作。
3.2 Checkpoint
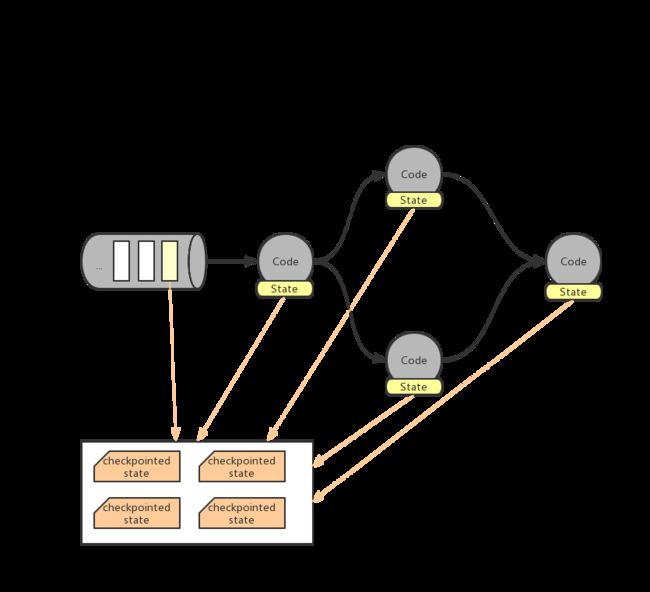
Checkpoint 是分布式全域一致的,数据会被写入hdfs等共享存储中。且其产生是 异步的,在 不中断、不影响运算 的前提下产生。
首先,Flink 会在数据源设置一系列的 checkpoint barrier,默认间隔n毫秒在数据流中插入一个 barrier 点。
ck barrier n 与 ck barrier n-1 之间的数据都属于当前的checkpoint。
ck barrier n经过第一个op(算子操作)时向ck后端保存 source offset 的信息。
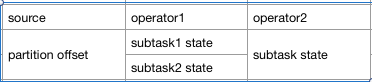
此时,ck后端中的 Checkpoint 信息可以简化为下表:

随着数据在程序算子中流动,ck barrier n 会慢慢传播到每个op中。
经过后续每个op时:
- ck barrier n到达之前,会用input buffer缓存之前的数据集
- ck barrier n到达之后表示当前所属的所有数据已经处理完成并更新状态
- 将当前op的状态保存至ck后端
此时ck后端中的 Checkpoint 信息如下:

ck barrier n经过最后的sink op时向ck后端确认ck完整性,所有节点将「数据读取的位置」与「当前状态快照」写入共享的dfs。
此时ck后端中的 Checkpoint 信息如下:
当任务失败时,所有节点从dfs中读取「上次的数据位置」来重置消息队列,并从「上次的状态」开始重新计算即可。
同 State 一样,用户只需在相应的 env 环境中设置即可:
// 1000毫秒进行一次 Checkpoint 操作
env.enableCheckpointing(1000)
// 模式为准确一次
env.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE)
// 两次 Checkpoint 之间最少间隔 500毫秒
env.getCheckpointConfig.setMinPauseBetweenCheckpoints(500)
// Checkpoint 过程超时时间为 60000毫秒,即1分钟视为超时失败
env.getCheckpointConfig.setCheckpointTimeout(60000)
// 同一时间只允许1个Checkpoint的操作在执行
env.getCheckpointConfig.setMaxConcurrentCheckpoints(1)
3.3 Watermark
Flink 程序并 不能自动提取数据源中哪个字段/标识为数据的事件时间,从而也就无法自己定义 Watermark 。
开发人员需要通过 Flink 提供的 API 来 提取和定义 Timestamp/Watermark,可以在 数据源或者数据流中 定义。
3.3.1 自定义数据源设置 Timestamp/Watermark
自定义的数据源类需要继承并实现 SourceFunction[T]接口,其中 run方法是定义数据生产的地方:
//自定义的数据源为自定义类型MyType
class MySource extends SourceFunction[MyType]{
//重写run方法,定义数据生产的逻辑
override def run(ctx: SourceContext[MyType]): Unit = {
while (/* condition */) {
val next: MyType = getNext()
//设置timestamp从MyType的哪个字段获取(eventTimestamp)
ctx.collectWithTimestamp(next, next.eventTimestamp)
if (next.hasWatermarkTime) {
//设置watermark从MyType的那个方法获取(getWatermarkTime)
ctx.emitWatermark(new Watermark(next.getWatermarkTime))
}
}
}
}
3.3.2 在数据流中设置 Timestamp/Watermark
在数据流中,可以设置 stream 的 Timestamp Assigner ,该 Assigner 将会接收一个 stream,并生产一个带 Timestamp和Watermark 的新 stream。
Timestamp Assigner 通过 DataStream 的 assignTimestampsAndWatermarks方法设置:
val withTimestampsAndWatermarks: DataStream[MyEvent] = stream
.assignTimestampsAndWatermarks(new MyTimestampsAndWatermarks())
assignTimestampsAndWatermarks的参数可以接收两种接口类型的子类:
AssignerWithPeriodicWatermarks
- 周期性生成watermark(可能根据流中的元素,也可能根据处理时间)
- 该实现的
getCurrentWatermark方法会被每隔一段时间调用一次,由ExecutionConfig.setAutoWatermarkInterval来定义 - 当返回的watermark不为空且比当前watermark大的话,该watermark会被使用
class BoundedOutOfOrdernessGenerator extends AssignerWithPeriodicWatermarks[MyEvent] {
//最大允许的乱序范围
val maxOutOfOrderness = 3500L // 3.5 seconds
//当前最大时间戳
var currentMaxTimestamp: Long = _
//提取数据源中的timestamp
override def extractTimestamp(element: MyEvent, previousElementTimestamp: Long): Long = {
val timestamp = element.getCreationTime()
//设置当前最大时间
currentMaxTimestamp = max(timestamp, currentMaxTimestamp)
timestamp
}
//获取当前watermark,将会被 ExecutionConfig.setAutoWatermarkInterval 定义的时间定时调用
override def getCurrentWatermark(): Watermark = {
//设置watermark为当前最大时间戳-最大允许的乱序范围
new Watermark(currentMaxTimestamp - maxOutOfOrderness)
}
}
AssignerWithPunctuatedWatermarks
- 先调用
extractTimestamp提取数据源中的timestamp - 然后马上调用
checkAndGetNextWatermark,每一次分配timestamp都会调用此方法 checkAndGetNextWatermark中可以访问到extractTimestamp设置的时间戳,然后决定是否生成一个watermark- 当
checkAndGetNextWatermark放回一个不为空且比当前watermark大的值,该watermark会被使用
class PunctuatedAssigner extends AssignerWithPunctuatedWatermarks[MyEvent] {
//提取数据源中的timestamp
override def extractTimestamp(element: MyEvent, previousElementTimestamp: Long): Long = {
element.getCreationTime
}
override def checkAndGetNextWatermark(lastElement: MyEvent, extractedTimestamp: Long): Watermark = {
//根据上一条数据和当前的timestamp判断是否生成以及如何生成watermark
if (lastElement.hasWatermarkMarker()) new Watermark(extractedTimestamp) else null
}
}
需要注意的是,使用 AssignerWithPunctuatedWatermarks虽然可以做到每条数据都生成watermark并使用,但是因为watermark会产生相应的计算处理,数量巨大的watermark将会影响到系统的性能,所以应该尽量避免出现大量的watermark。
3.3.3 预定义的 Assigner
AscendingTimestampExtractor
Flink中内置了集中预定义的 Assigner ,可以直接在特定场景中直接使用。
例如,在时间戳只会一直增加的场景中,任意事件的时间都可以被当做watermark,因为不会有更早的时间戳出现,比如在多分区的kafka队列中,不要求所有分区全局都是升序,只要各个分区中的时间戳是升序的即可。
在这种场景中,Flink 的watermark合并机制将会正确的生成watermark,无论多个分区的数据流是在进行shuffle或者合并、连接等其他操作。
DataStream stream = ...
DataStream withTimestampsAndWatermarks =
//使用预定义的升序时间戳 Assigner
stream.assignTimestampsAndWatermarks(new AscendingTimestampExtractor() {
@Override
public long extractAscendingTimestamp(MyEvent element) {
//直接指定数据源中的时间戳字段即可
return element.getCreationTime();
}
});
BoundedOutOfOrdernessTimestampExtractor
在另外一种场景中,可以设置 允许固定最大时间范围内的延迟,比如固定时间间隔中周期性发送数据的数据源,因为数据发送的间隔是固定的,所以可以设置一个固定的最大允许延迟时间。
DataStream stream = ...
DataStream withTimestampsAndWatermarks =
//使用预定义的时间戳 Assigner 并设置最大允许的延迟时间范围
stream.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor(Time.seconds(10)) {
@Override
public long extractTimestamp(MyEvent element) {
return element.getCreationTime();
}
});
Flink 中内置的 Assigner 是 用户自定义实现 Assigner 的绝佳参考,建议参阅自定义 Assigner 的实现源代码,可帮助开发人员对自定义 Assigner 的理解,相关代码位于 org.apache.flink.streaming.api.functions.timestamps包下。
3.4 Trigger
3.4.1 自定义触发器
触发器决定了窗口何时会被触发计算,Flink 中开发人员需要在 window类型的操作之后才能调用 trigger方法传入触发器定义。
Flink 中的触发器定义需要继承并实现 Trigger接口,该接口有以下方法:
- onElement(): 每个被添加到窗口中的元素都会被调用
- onEventTime(): 当事件时间定时器触发时会被调用,比如watermark到达
- onProcessingTime(): 当处理时间定时器触发时会被调用,比如时间周期触发
- onMerge(): 当两个窗口合并时两个窗口的触发器状态将会被调动并合并
- clear(): 执行需要清除相关窗口的事件
以上方法会返回决定如何触发执行的 TriggerResult:
- CONTINUE: 什么都不做
- FIRE: 触发计算
- PURGE: 清除窗口中的数据
- FIRE_AND_PURGE: 触发计算后清除窗口中的数据
3.4.2 预定义触发器
如果开发人员未指定触发器,则 Flink 会自动根据场景使用默认的预定义好的触发器。
在基于事件时间的窗口中使用 EventTimeTrigger,该触发器会在watermark通过窗口边界后立即触发(即watermark出现关闭改窗口时)。
在全局窗口(GlobalWindow)中使用 NeverTrigger,该触发器永远不会触发,所以在使用全局窗口时用户需要自定义触发器。
其他预定义触发器还有如下:
- ProcessingTimeTrigger: 基于处理时间的触发器
- CountTrigger: 根据窗口中元素数量的触发器
- PurgingTrigger: 接收一个触发器,并将其转为带Purge类型的触发器
同样,预定义的触发器也是开发人员学习触发器如何定义与使用的最佳案例,相关源代码位于 org.apache.flink.streaming.api.windowing.triggers包下。
四、安装部署
目前为止,我们掌握了 Flink 中的一些基本的理论概念。接下来,在动手开发之前拥有一个 Flink 集群是第一步。
本章将介绍 Flink 集群几种不同的部署模式供开发人员参考使用。
4.1 集群架构
在介绍部署方式之前,我们有必要先了解一下 Flink 集群的部署架构和节点组成。
Flink 集群也是采用 Master-Slaves 式的结构,由一个(或者多个)Master管理多个Slaves。
集群中的角色主要有三个:JobManager、TaskManager以及Client。

Client
开发人员编写的代码会被 Client 打包处理并提交到 JobManager 中。
Client 可以控制集群中提交的作业,如查看信息、结束作业等操作。
Client 可以是任意拥有 Flink 环境的节点,只要其能够连上 JobManager 服务即可。
JobManager
Flink 中的 Master 节点称为 JobManager,具有以下功能:
- 接收 Client 发出的作业操作请求
- 根据用户代码生成优化后的执行计划(Execution Graph)
- 调度执行计划到各个子节点执行
- 协调子节点做 Checkpoint 等任务
TaskManager
Flink 中的 Slave 节点称为 TaskManager,具有以下功能:
- 子节点上 Memory & IO & Network 等资源管理
- 定期向 JobManager 汇报节点状态、任务与资源等情况
- 接收 JobManager 分配的执行计划并执行具体计算任务
4.2 本地单节点模式
这是最简单的 Flink 安装部署方式。
在官网 下载 指定版本的 Flink 发型包到本地并解压。
进入 Flink 解压缩目录中执行:
./bin/start-cluster.sh
即可启动一个最简单的 Flink 进程,可以通过 http://127.0.0.1:8081/ 访问 JobManager 界面。
4.3 Standalone HA 模式
建议线上使用的 Flink 集群至少是 Standalone HA 模式的,能够保证 JobManager 是高可用的,避免 JobManager 宕机导致整个集群失效。
Flink 集群的 HA 需要 Zookeeper 的支持,Flink 的发型包中自带了 Zookeeper,可以通过以下命令启动:
./bin/start-zookeeper-quorum.sh
在 conf/zoo.cfg 文件中默认配置好了本地启动的 Zookeeper
# The port at which the clients will connect
clientPort=2181
# ZooKeeper quorum peers
server.1=localhost:2888:3888
# server.2=host:peer-port:leader-port
Zookeeper 设置完毕后,需要编辑以下文件并同步到所有要安装的节点中:
- masters: 记录master节点的文件
- slaves: 记录slave节点的文件
- flink-conf.yaml: 使用外部zk需要修改以下两个配置为对应zk信息
- high-availability: zookeeper
- high-availability.zookeeper.quorum: localhost:2181
强烈建议使用外部 Zookeeper。
最后,检查 JAVA_HOME 环境变量是否已经正确设置。
配置完毕后将 Flink 发型包中的文件同步到各个节点中,启动集群即可:
./bin/start-cluster.sh
4.4 Yarn 模式
Yarn 模式是生产环境中 Flink 最常应用的模式之一,其可以直接 复用现有 Yarn 集群的资源与调度能力,做到无缝集成,不用再单独部署 Flink 集群,直接向 Yarn 集群提交 Flink 任务即可。
Flink 集成 Yarn 集群的方式很简单,只需要在 Flink 节点上配置环境变量使 Flink 程序可以读取 Yarn 的相关配置即可:
- YARN_CONF_DIR
- HADOOP_CONF_DIR
Flink 提交任务时将会根据执行模式自动匹配并寻找 Yarn 集群的信息并提交任务。
Yarn Session
Yarn Session 模式会先在 Yarn 集群上提交一个 Flink 任务信息,这个 Flink 任务可以看做是一个简单的 Flink 集群,里面运行了 JobManager、TaskManager 等节点,称之为 Yarn Session。
Yarn Session 是以长驻的形式 长期运行在 Yarn 集群中,它和普通的 Flink 集群一样,可以接受客户端提交的 Flink 任务并运行,一个 Yarn Session 可以执行多个 Flink 任务。
简单来说就是运行在 Yarn 集群中的 Flink 集群。
启动一个 Yarn Session :
# 启动4个container(运行TaskManager,内存4096m)、1个appmaster(运行JobManager,内存1024m)
./bin/yarn-session.sh -n 4 -jm 1024m -tm 4096m
Yarn Session 启动后,AppId 会被写入 /tmp/.yarn-properties-${user}中。
向 Yarn Session 提交 Flink 任务:
./bin/flink run examples/streaming/WordCount.jar --input hdfs:///test_dir/input_dir/story --output hdfs:///test_dir/output_dir/output
flink 命令将会自动寻找 /tmp 路径下 Yarn Session 的 AppId,用户也可以通过 -yid选项手动指定 AppId 信息。
Yarn Session 在分组提交测试 Flink 任务的场景下十分方便,不同的小组使用不同的 Yarn Session 互不影响,且统一管理与限制资源的使用,对于每个用户来说,其面对的都是一个完整的 Flink 集群。
Single Job
除了 Yarn Session 之外,Flink 还可以直接向 Yarn 集群提交单独的任务,运行完成即刻销毁并释放资源(就像 Spark 一样)。
向 Yarn 集群提交单独的任务:
./bin/flink run -m yarn-cluster -yn 2 examples/streaming/WordCount.jar --input hdfs:///test_dir/input_dir/story --output hdfs:///test_dir/output_dir/output
任务提交成功之后,可以在 Yarn 集群中通过 App 列表查看任务详细信息,也可以通过 AppId 管理任务。
Single Job 比较适合正式上线后的生产任务,独占运行资源保证运行的稳定。
除了 Yarn 之外,Flink 还支持 Mesos、Docker、K8S、AWS 等不同环境的安装部署,可以参考 官方文档-deployment。
五、客户端操作
拥有 Flink 集群后,我们可以马上进行上手实践。
Flink 提供了丰富的客户端操作来提交任务、与任务进行交互,下面将简单介绍 Flink 中两种最常用的客户端应用。
5.1 CommandLine
Flink 命令行执行程序为 bin/flink。
该程序中 Flink 任务操作的所有功能,如前文中用到任务提交命令:
./bin/flink run examples/streaming/WordCount.jar --input hdfs:///test_dir/input_dir/story --output hdfs:///test_dir/output_dir/output
任务提交之后可以继续查看集群上的任务情况:
# 查看任务列表
bin/flink list -m 127.0.0.1:8081
# 停止某个任务,安全关闭source与task
bin/flink stop -m 127.0.0.1:8081 任务id
# 立即取消某个任务并设置savepoint,暴力中断
bin/flink stop -m 127.0.0.1:8081 -s /tmp/savepoint 任务id
# 手动触发savepoint
bin/flink savepoint -m 127.0.0.1:8081 任务id /tmp/savepoint
# 从指定的savepoint中恢复
bin/flink run -d -s /tmp/savepoint/savepoint-xxx ./e
xamples/streaming/TopSpeedWindowing.jar
更多参数与功能可以通过 bin/flink -h来查看使用的帮助信息。
5.2 Scala Shell
Scala Shell 提供了一个 REPL 环境给用户,即时执行代码,所见即所得,对于实验类的验证测试过程十分有用。
Scala Shell 启动需要连接到一个远程集群或者本地环境,这里以远程集群为例:
# 远程集群可以是独立的 flink 集群,也可以是 yarn session 模式的集群
bin/start-scala-shell.sh remote jm的ip地址 jm的ip端口
除了连接到远程集群外,Scala Shell 还可以直接向 Yarn 集群申请资源提交执行任务:
bin/start-scala-shell.sh yarn -n 2 -jm 1024 -s 2 -tm 1024 -nm flink-yarn
打开 Scala Shell 之后,这个所见即所得的世界就是你的了,Just Do It.
除了最常用的命令行与REPL环境,Flink 还提供了诸如 SQL Client、Restful Api、Web界面等客户端应用,开发人员可以通过 SQL Client 进行sql测试,使用 Restful Api 进行提交与管理任务等操作。
六、编程API
6.1 API 概述
Flink 提供了几种不同层次的 API 给开发人员使用,分别是:SQL API、Table API、Datastream 与 ProcessFunction。
如下图所示:
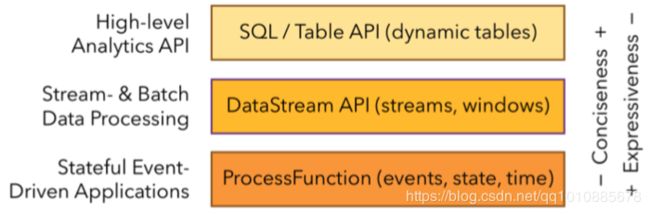
越上层的API易用性与简洁性越强,但是表达能力越弱。反之,越下层的API表达能力越强,但是易用性与简洁性越弱。
SQL/Table API 是 Flink 中最高级的 API,通常用于数据分析的场景,表达能力能与 SQL 或者 Python的DataFrame 相媲美。
具有以下特点:
- 声明式:用户只关心做什么,不用关心怎么做
- 高性能:支持查询优化,可以获取更好的执行性能
- 流批统一:相同的统计逻辑,既可以流模式运行,也可以批模式运行
- 标准稳定:语义遵循SQL标准,不易变动
- 易理解:语义明确,所见即所得
Table API 和 SQL API 的区别在于后者是前者的子集,也就是说 SQL API 能够实现的功能 Table API 都能实现反之则不行,但是正如前面所说的,Table API 的易用性并不如 SQL API。
而 Datastream API 是能够直接操作数据流的API,在 Datastream 中可以对 时间和窗口 进行操作。
ProcessFunction 是 Flink 中最底层的 API,能够直接操作 事件、状态与时间。
简而言之,无论是 Flink 还是 Spark 编程,其都可以看成是在画一个任务执行的DAG图,图中有并行有串行,有一对一的Task,也有多对多的 Shuffle Task。
和 Spark 不同的是,Flink 中的数据交换策略比较多样:
- global: 全部发往第一个task
- broadcast: 所有task广播
- forward: 上下游并行度一样时一对一发送
- shuffle: 随机均匀分配
- rebalance: 全部task轮流分配
- recale: 本地task轮流分配
- partitionCustom: 自定义单播
6.2 Window API
在 Flink 中使用窗口的步骤为:
- 定义是否为 Keyed Stream
- 定义 Window Assigners
- 定义 Window Functions
- 定义可选调用的API
6.2.1 Window Assigners
在确认你的流是是 Keyed 还是 Non-Keyed 之后,开发人员需要通过 window(Keyed) 或者 windowAll(Non-Keyed) 来为窗口指定 Assigners,Assigners 定义了 如何将元素分配给窗口。
Flink 中内置了多种 Window Assigners 如创建 tumbling windows, sliding windows, session windows 和 global windows 等窗口的 Assigner。
基于不同的时间类型,这些 Assigner 有不同的实现,并 根据指定时间将元素分配给窗口。
开发人员可以参考以上的内置实现来定义自己的 Assigner,源码包位于 org.apache.flink.streaming.api.windowing.assigners。
以下 Assigners 使用 Demo 来自 Flink官网。
Tumbling Windows:
val input: DataStream[T] = ...
// tumbling event-time windows
input
.keyBy()
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.()
// tumbling processing-time windows
input
.keyBy()
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.()
// daily tumbling event-time windows offset by -8 hours.
input
.keyBy()
.window(TumblingEventTimeWindows.of(Time.days(1), Time.hours(-8)))
.()
Sliding Windows:
val input: DataStream[T] = ...
// sliding event-time windows
input
.keyBy()
.window(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(5)))
.()
// sliding processing-time windows
input
.keyBy()
.window(SlidingProcessingTimeWindows.of(Time.seconds(10), Time.seconds(5)))
.()
// sliding processing-time windows offset by -8 hours
input
.keyBy()
.window(SlidingProcessingTimeWindows.of(Time.hours(12), Time.hours(1), Time.hours(-8)))
.()
Session Windows:
val input: DataStream[T] = ...
// event-time session windows with static gap
input
.keyBy()
.window(EventTimeSessionWindows.withGap(Time.minutes(10)))
.()
// event-time session windows with dynamic gap
input
.keyBy()
.window(EventTimeSessionWindows.withDynamicGap(new SessionWindowTimeGapExtractor[String] {
override def extract(element: String): Long = {
// determine and return session gap
}
}))
.()
// processing-time session windows with static gap
input
.keyBy()
.window(ProcessingTimeSessionWindows.withGap(Time.minutes(10)))
.()
// processing-time session windows with dynamic gap
input
.keyBy()
.window(DynamicProcessingTimeSessionWindows.withDynamicGap(new SessionWindowTimeGapExtractor[String] {
override def extract(element: String): Long = {
// determine and return session gap
}
}))
.()
Global Windows:
val input: DataStream[T] = ...
input
.keyBy()
.window(GlobalWindows.create())
.()
6.2.2 Window Functions
定义好 Window Assigners 之后,开发人员需要在窗口和数据之上定义执行计算的 Window Functions。
ReduceFunction
可以递增地聚合窗口的元素,是个高效的操作:
val input: DataStream[(String, Long)] = ...
input
.keyBy()
.window()
.reduce { (v1, v2) => (v1._1, v1._2 + v2._2) }
AggregateFunction
AggregateFunction 是 ReduceFunction 的底层版本,也可以递增地聚合窗口的元素,但是其可以让开发人员更加灵活的定义计算,同时也意味着其实用比较复杂。
AggregateFunction 有三个泛型参数:输入类型、累加器类型和输出结果类型,Demo 如下:
/**
* The accumulator is used to keep a running sum and a count. The [getResult] method
* computes the average.
*/
//输入类型为(String, Long),累加器类型为(String, Long),输出类型为Double
class AverageAggregate extends AggregateFunction[(String, Long), (Long, Long), Double] {
//初始化累加器
override def createAccumulator() = (0L, 0L)
//累加器计算
override def add(value: (String, Long), accumulator: (Long, Long)) =
(accumulator._1 + value._2, accumulator._2 + 1L)
//获取结果,从累加器中计算,不需要缓存所有数据
override def getResult(accumulator: (Long, Long)) = accumulator._1 / accumulator._2
//合并两个累加器的结果
override def merge(a: (Long, Long), b: (Long, Long)) =
(a._1 + b._1, a._2 + b._2)
}
val input: DataStream[(String, Long)] = ...
input
.keyBy()
.window()
.aggregate(new AverageAggregate)
FoldFunction:
fold()方法指定 输入的数据如何和之前的输出结果相计算,该方法会在每个数据进入窗口之后马上进行计算。
第一个进入窗口的元素(没有上一个输出结果的情况下),将会与一个用户指定的初始值相计算。
val input: DataStream[(String, Long)] = ...
input
.keyBy()
.window()
.fold("") { (acc, v) => acc + v._2 }
需要注意的是,fold()方法不能在 Session Window 等可合并的窗口中使用。
ProcessWindowFunction
获取一个包含窗口的所有元素的Iterable,以及一个可以访问时间和状态信息的上下文对象,这使得它比其他窗口函数提供了更大的灵活性。这是以性能和资源消耗为代价的,因为元素不能增量地聚合,而是需要在内部进行缓冲,直到窗口准备好处理为止。
ProcessWindowFunction 接口的定义类似:
abstract class ProcessWindowFunction[IN, OUT, KEY, W <: Window] extends Function {
/**
* Evaluates the window and outputs none or several elements.
*
* @param key The key for which this window is evaluated.
* @param context The context in which the window is being evaluated.
* @param elements The elements in the window being evaluated.
* @param out A collector for emitting elements.
* @throws Exception The function may throw exceptions to fail the program and trigger recovery.
*/
def process(
key: KEY,
context: Context,
elements: Iterable[IN],
out: Collector[OUT])
/**
* The context holding window metadata
*/
abstract class Context {
/**
* Returns the window that is being evaluated.
*/
def window: W
/**
* Returns the current processing time.
*/
def currentProcessingTime: Long
/**
* Returns the current event-time watermark.
*/
def currentWatermark: Long
/**
* State accessor for per-key and per-window state.
*/
def windowState: KeyedStateStore
/**
* State accessor for per-key global state.
*/
def globalState: KeyedStateStore
}
}
使用Demo如下:
val input: DataStream[(String, Long)] = ...
input
.keyBy(_._1)
.timeWindow(Time.minutes(5))
.process(new MyProcessWindowFunction())
/* ... */
class MyProcessWindowFunction extends ProcessWindowFunction[(String, Long), String, String, TimeWindow] {
def process(key: String, context: Context, input: Iterable[(String, Long)], out: Collector[String]): () = {
var count = 0L
for (in <- input) {
count = count + 1
}
out.collect(s"Window ${context.window} count: $count")
}
}
注意,使用ProcessWindowFunction进行简单的累加计算效率是十分低下的,可以通过将ProcessWindowFunction与ReduceFunction、AggregateFunction或FoldFunction相结合来缓解这种情况,可以参考 Flink官网。
6.2.3 Evictors
Evictors 可翻译为驱逐者,但是称之为回收器或者过滤器可能更加合适。
Flink 的窗口模型允许指定除 WindowAssigner 和触发器之外的可选回收器。这可以使用 evictor(…)方法实现定义。
其能够在触发器触发之后以及在应用窗口函数之前 and/or 之后从窗口中删除元素。
为此,Evictor 接口有两个方法:
/**
* 窗口函数计算之前调用
*
* @param elements The elements currently in the pane.
* @param size The current number of elements in the pane.
* @param window The {@link Window}
* @param evictorContext The context for the Evictor
*/
void evictBefore(Iterable> elements, int size, W window, EvictorContext evictorContext);
/**
* 窗口函数计算之后调用
*
* @param elements The elements currently in the pane.
* @param size The current number of elements in the pane.
* @param window The {@link Window}
* @param evictorContext The context for the Evictor
*/
void evictAfter(Iterable> elements, int size, W window, EvictorContext evictorContext);
同样的,Flink 中也内置了几个预定义的 Evictor:
- CountEvictor: 根据用户指定的数量保留元素,如果超出指定数量则依次删除窗口中的元素。
- DeltaEvictor: 用户需要指定一个
DeltaFunction和threshold,Evictor 将会把当前元素和窗口中的所有元素一一调用DeltaFunction并计算结果值,大于threshold的数据将会被丢弃。 - TimeEvictor: 根据用户定义的窗口大小interval,它会找到它的元素中的最大时间戳max_ts,并删除所有时间戳小于max_ts - interval的元素。
源代码包位于 org.apache.flink.streaming.api.windowing.evictors
6.3 广播变量
和 Spark 中的广播变量一样,Flink 也支持在各个节点中各存一份小数据集,所在的计算节点实例可在本地内存中直接读取被⼴播的数据,可以避免 Shuffle 提高并行效率。
可在 DataStream 上使用 withBroadcastSet方法将数据集以指定id广播,并在 RichMapFunction中通过 getRuntimeContext().getBroadcastVariable方法获得广播数据集:
val env = ExecutionEnvironment.getExecutionEnvironment
// 创建需要⼴播的数据集
val dataSet1: DataSet[Int] = env.fromElements(1, 2, 3, 4)
//创建输⼊数据集
val dataSet2: DataSet[String] = env.fromElements("flink", "dddd")
dataSet2.map(
//使用RichFunction 读取广播变量
new RichMapFunction[String, String]() {
var broadcastSet: Traversable[Int] = null
override def open(config: Configuration): Unit = {
// 获取广播变量数据集,并且转换成Collection对象
broadcastSet = getRuntimeContext().getBroadcastVariable[Int]("broadcastSet-1")
}
def map(input: String): String = { input + broadcastSet.toList }
}
)
//广播DataSet数据集,指定广播变量量名称为broadcastSet-1
.withBroadcastSet(dataSet1, "broadcastSet-1")
6.4 TaskChain
Flink作业中,可以指定相关的链条将相关性⾮常强的转换操作绑定在一起,使得上下游的Task在同⼀个Pipeline中执行,避免因为数据在⽹网络或者线程之间传输导致的开销。
一般情况下Flink在Map类型的操作中默认开启 TaskChain 以提高整体性能,开发人员也可以根据⾃己需要创建或者禁⽌ TaskChain 对任务进⾏细粒度的链条控制。

//创建 chain
dataStream.filter(...).map(...).startNewChain().map(...)
//禁止 chain
dataStream.map(...).disableChaining()
创建的链条只对当前的操作符和之后的操作符有效,不不影响其他操作,如上demo只针对两 个map操作进⾏链条绑定,对前面的filter操作无效,如果需要可以在filter和map之间使用 startNewChain⽅法即可。