CD网站用户消费数据分析案例
目录
- 一. 项目介绍
- 1.1 背景
- 1.2 数据介绍
- 二. 分析内容
- 2.1 整体分析框架
- 三. 数据处理
- 3.1 导入常用库
- 3.2 导入数据
- 3.3 数据清洗
- 3.3.1 查看数据整体
- 3.3.2 修改字段数据类型
- 3.3.3 添加新列(month)
- 四. 用户整体消费统计
- 4.1 数据整体的描述性统计
- 4.2 用户总体消费趋势
- 五. 用户个体消费行为分析
- 5.1 用户消费金额,购买数量的描述统计
- 5.2 用户消费金额和购买数量的相关分析
- 5.3 用户消费金额、购买数量的分布
- 5.4用户消费金额累计占比(二八法则)
- 5.5 用户消费次数描述统计与分布
- 六. 用户消费周期分析
- 6.1 用户消费时间间隔分析
- 6.1.1 描述统计
- 6.1.2 用户消费时间间隔分布
- 6.2 用户生命周期分析
- 6.2.1 描述统计
- 6.2.2 用户生命周期分布
- 七. 用户价值划分(RFM模型)
- 7.1 RFM模型简介
- 7.2 用户价值划分
- 八、用户活跃程度划分
- 九. 用户质量分析
- 9.1 消费一次用户占比
- 9.2 复购率
- 9.3 回购率
- 9.4 留存率
- 十. 总结
一. 项目介绍
1.1 背景
本项目是针对某CD网站的用户消费记录进行分析,了解用户的整体消费趋势以及用户的消费行为特征,并针对用户的消费特征制定对应的策略,以改善网站的运营效果,提高网站的销售额。
1.2 数据介绍
本次分析的数据集来源于某CD网站,这份数据集涵盖了该网站在1997年1月1日至1998年6月30日期间内用户的消费记录。数据集的每一行表示一个用户的购买记录,由用户ID(user_id)、用户消费时间(order_dt)、用户购买数量(order_products)、用户消费金额(order_amount)组成,并以空格隔开。
链接:CD数据集 提取码:ydqa
二. 分析内容
2.1 整体分析框架
本次分析主要从以下6个角度进行分析,分析的内容见以下框架:

三. 数据处理
3.1 导入常用库
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
%matplotlib inline # 可以将matplotlib的图表直接嵌入到Notebook之中
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号
3.2 导入数据
col_name = ['user_id','order_dt','order_products','order_amount'] # 设置字段名
data = pd.read_table('./CDNOW_master.txt',names=col_name,sep='\s+')
data.head() # 显示前5行
各个字段的含义如下:
- user_id:用户id
- order_dt:每笔订单成交的时间日期
- order_products:每笔订单用户的购买数量
- order_amount:每笔订单的消费金额
3.3 数据清洗
3.3.1 查看数据整体
data.info() #查看数据整体情况
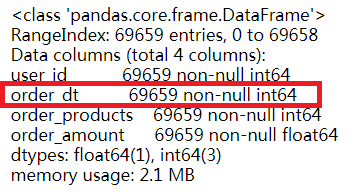
- 该数据集总共有69659条消费记录,每个字段也是69659条记录,说明每个字段没有存在空值,后续不需要做缺失值的处理;
- 订单成交时间order_dt字段的数据类型有误,需要转换为时间类型
3.3.2 修改字段数据类型
data['order_dt'] = pd.to_datetime(data['order_dt'],format='%Y%m%d')
3.3.3 添加新列(month)
为了后续分析的展开,在这里根据order_dt的值新添加月份的字段
data['month'] = data['order_dt'].values.astype('datetime64[M]')
data.head()
四. 用户整体消费统计
4.1 数据整体的描述性统计
data.describe()
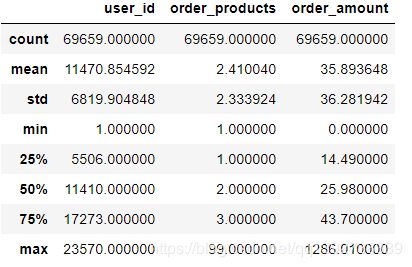
- 从用户购买数量: 用户每个订单平均购买2.4张CD,有75%以上的订单购买数量在3张以内;中位数为2.0,略小于平均水平,说明整体呈右偏分布,存在一些极大值,即一次性购买很多张CD的用户。
- 从用户消费金额: 用户的每个订单消费金额平均为35.9元,超过75%的订单量消费金额在43.7元左右,比较低;中位数为26.0元左右,低于平均水平,同样也说明了消费金额的总体呈右偏分布,存在一些消费金额很高的用户。
综合以上,该批用户中,大部分用户的消费金额不是很高,小部分用户贡献了销售额的绝大部分,需要再进一步挖掘和维持这部分用户。
4.2 用户总体消费趋势
grouped_month = data.groupby("month") # 按月分组
# 设置画布的大小,添加子图
plt.figure(figsize=(20,15))
# 每月的消费总金额,按月分组,对order_amount求和
plt.subplot(231)
grouped_month.order_amount.sum().plot(fontsize=20)
plt.title('总销售额',fontsize=24)
# 每月的消费次数,按月分组,统计每月的消费记录数
plt.subplot(232)
grouped_month.user_id.count().plot(fontsize=20)
plt.title('总消费次数',fontsize=24)
# 每月的销量,按月分组,对order_products求和
plt.subplot(233)
grouped_month.order_products.sum().plot(fontsize=20)
plt.title('总销量',fontsize=24)
# 每月的消费用户数量
plt.subplot(234)
grouped_month["user_id"].nunique().plot(fontsize=20)
plt.title('消费的用户数量',fontsize=24)
# 每月用户平均消费金额的趋势
plt.subplot(235)
(order_amount_month/unique_user_id_month).plot(fontsize=20)
plt.title('人均消费金额',fontsize=24)
# 每月用户平均消费次数的趋势(每月总的消费次数/每月的消费人数)
plt.subplot(236)
((grouped_month.user_id.count())/(grouped_month["user_id"].nunique())).plot(fontsize=20)
plt.title('人均消费次数',fontsize=24)
plt.tight_layout() # 自动调整子图参数,使之填充整个图像区域
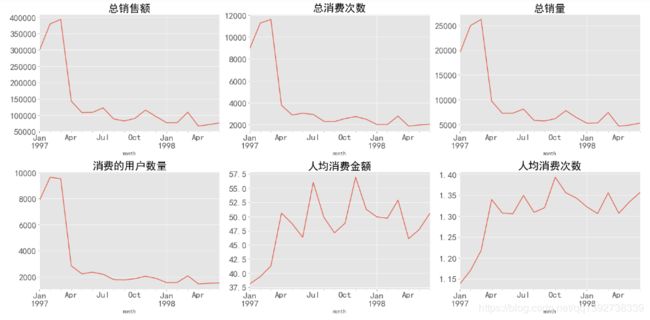
1. 从总销售额/总消费次数/总销量/消费的用户数量趋势图分析:
- 在前3个月,四项指标都相对较高,用户流量较高,消费的总商品数也较多,总体的消费金额也是相对较高,但在3月份之后出现了大幅度下降,下降了63.7%。
- 在1997年3月份之后,这四项指标都趋于平稳,没有太大的波动,但随着时间的推移,这四项指标都是在缓慢下降的,用户在逐渐的流失。
大幅下降原因分析:
从以上前四幅趋势图可以看出,四个指标的大幅下降归根到底是用户流量的波动,分析用户流量波动可以从以下几个方面入手:
1.活动影响: 该网站前3个月可能采用了一定的促销手段拉新,后续营销力度或吸引力度做的不到位;
2.产品变化: 该网站后期是否有变动,造成曝光率下降,客户购买难度增加;
3.数据异常: 如:底层系统故障,造成数据传输有误;前期数据大涨有刷单作弊行为等;
4.外部事件: 如:该网站后期是否有负面的社会新闻;或者前3个月可能恰好出现了与CD相关的热点事件(如:某歌星逝世),引发大量用户购买CD;
5.竞品数据: 可以对应分析竞品的数据,如果竞品数据上涨,则极可能是用户流向竞品;
6.节假日: 对比1998年的1~3月份数据,可知道该因素不是影响数据巨大波动的原因,可以暂时排除。
备注: 因为这里只有一段时间的消费记录,因此无法做出准确判断,具体的原因得结合历史数据以及当时的业务场景做出判断。
2. 从人均消费金额/人均消费次数趋势图分析:
- 由图,人均消费金额和人均消费次数在前4个月是迅速攀升的趋势,从1997年4月之后,人均消费金额在51元上下波动,人均消费次数在1.3~1.4区间内稳定的震荡。
- 结合每月总销售额以及每月消费总人数的趋势分析可知:在前3个月,虽然总销售额和总消费人数都很高,但是平均下来却很低,说明了前3个月存在大量只消费了一次并且消费金额也不高的用户。
五. 用户个体消费行为分析
前面的分析主要是根据时间维度,按月分析用户整体的消费情况,接下来从用户的个体角度出发,分析用户个体的消费金额、购买数量以及消费次数特征。主要分析以下几个内容:
- 用户消费金额,购买数量的描述统计
- 用户消费金额和购买数量的相关分析
- 用户消费金额的分布
- 用户购买数量的分布
- 用户消费金额累计占比(二八法则)
- 用户消费次数的分布
5.1 用户消费金额,购买数量的描述统计
# 根据用户ID进行分组
grouped_user_id = data.groupby("user_id")
grouped_user_id.sum().describe()
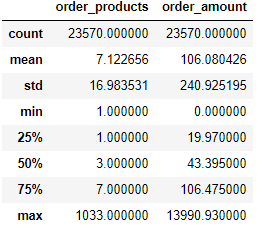
- 由表,一共有23570位用户消费购买了CD,每位用户平均购买7张CD左右,但中位值只有3张,整体呈右偏分布,说明存在小部分客户购买了大量的CD,最大购买数量达到了1033张;
- 用户的平均消费金额为106元,中位值为43元,远小于平均值,也呈右偏分布,存在小部分高消费用户。
5.2 用户消费金额和购买数量的相关分析
绘制用户消费金额和购买数量的散点图,可以了解用户消费金额和购买数量的分布情况。
grouped_user_id.sum().plot.scatter(x="order_products",y="order_amount",fontsize=16)
plt.xlabel("购买数量",fontsize=20)
plt.ylabel("消费金额",fontsize=20)
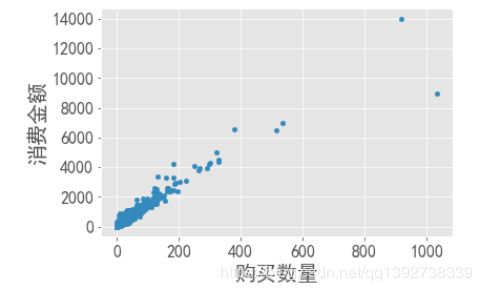
- 如图,整体的离群点个数比较少,绝大部分的用户消费金额在4000元以下。
- 过滤掉离群点,绝大部分的用户消费金额和购买数量的散点图如下:
# 过滤消费金额在4000元以上的离群点
grouped_user_id.sum().query("order_amount<4000").plot.scatter(x="order_products",y="order_amount",fontsize=16)
plt.xlabel("购买数量",fontsize=20)
plt.ylabel("消费金额",fontsize=20)
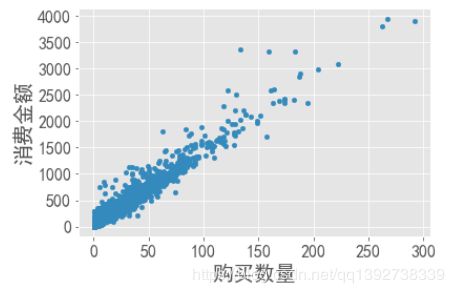
- 如图可以看出,用户的消费金额和购买的数量呈现一定的线性关系,两者的比值是CD的单价,说明网站该价位的CD比较受欢迎或者该网站的CD价位比较单一,用户可选择的价格范围较少,可适当的进货不同的价位CD,来应对不同价位需求的用户。
5.3 用户消费金额、购买数量的分布
# 设置画布的大小,添加子图
plt.figure(figsize=(20,5))
# 用户消费金额分布图绘制
plt.subplot(121)
grouped_user_id.sum().order_amount.plot.hist(bins=20,fontsize=16)
plt.title('用户消费金额分布',fontsize=24)
# 用户购买数量分布图绘制
plt.subplot(122)
grouped_user_id.sum().order_products.plot.hist(bins=20,fontsize=16)
plt.title('用户购买数量分布',fontsize=24)
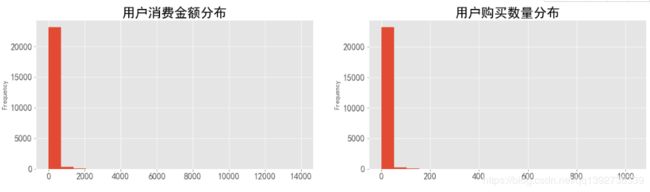
- 由图,由于有个别的极大值的干扰,导致数据过于集中,但是可以看出,大部分用户消费金额集中在1000元以下,购买的CD数量集中在100张以内,下面绘制消费金额在1000以内、购买数量在100以内的用户消费分布情况。
# 设置画布的大小,添加子图
plt.figure(figsize=(20,5))
# 用户消费金额分布图绘制
plt.subplot(121)
grouped_user_id.sum().query("order_amount<1000").order_amount.plot.hist(bins=20,fontsize=16)
plt.title('用户消费金额分布',fontsize=24)
# 用户购买数量分布图绘制
plt.subplot(122)
grouped_user_id.sum().query("order_products<100").order_products.plot.hist(bins=20,fontsize=16)
plt.title('用户购买数量分布',fontsize=24)
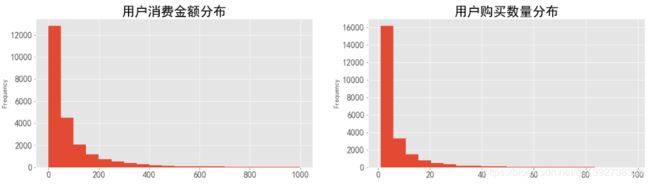
- 由图,大部分用户的消费能力都不高,处在比较低的消费档次;超过一半用户的消费金额在50元以下;高消费的用户数量极少,符合消费行为的行业规律。
- 接近70%的用户购买CD的数量在5张以内,超过一半的用户购买不超过3张(调节"order_products"<60),购买大量CD的用户占比很小。
5.4用户消费金额累计占比(二八法则)
- 创建的思路:根据用户ID分组,根据用户的消费金额的进行降序排列,计算累加值与总消费金额的比值来计算占比,再绘制曲线。
# 新建DataFrame,包含用户消费金额、用户消费金额的累加、累加值的占比
# 用户的消费金额按照降序方式排列
df_amount_cumsum = grouped_user_id.sum().sort_values(by="order_amount",ascending=False)
# 新添加用户消费金额的累加值
df_amount_cumsum["amount_cumsum"] = df_amount_cumsum.cumsum()["order_amount"]
# 把原来多余的列删除,方便查看
df_amount_cumsum.drop("order_products",axis = 1,inplace = True)
# 计算累加值占比
df_amount_cumsum["persent"] = df_amount_cumsum.amount_cumsum.apply(lambda x : x/df_amount_cumsum.amount_cumsum.max())
# 将user_id从索引转化为列
df_amount_cumsum.reset_index(inplace = True)
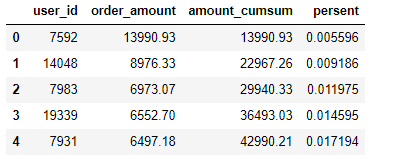
df_amount_cumsum.head()
绘制曲线:
plt.figure(figsize=(8,4),dpi=80)
df_amount_cumsum.persent.plot(fontsize=16)
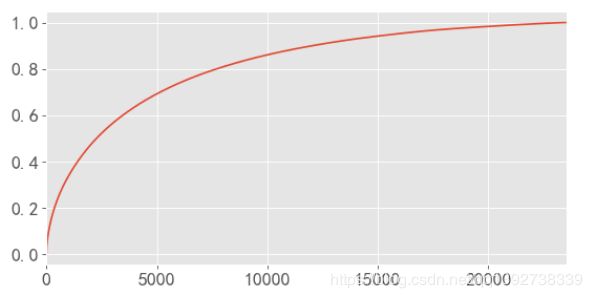
- 由描述统计表知道,一共有23570位用户,结合上图可知,有21.2%的用户贡献了70%的销售额;有31.8%的用户贡献了80%的销售额。因此这一部分的用户需要重点维护。
5.5 用户消费次数描述统计与分布
- 1.描述统计:
# 用户消费次数的描述统计
grouped_user_id.order_amount.count().describe()

- 由上,一共有23570名用户,每位用户平均消费3.0次,50%以上的只消费了1次,75%以下的人都消费不足3.0次, 说明有少部分用户的消费次数很高,最高的达到了217次。
- 2.分布
- 分析思路:对用户进行分组后,通过计算每个用户order_amount的数量来确认该用户的的消费次数。
- 同理,由于极值的影响并且绝大部分用户的消费次数都在20次以内,所以筛选了这个范围内的分布情况。
grouped_user_id.order_amount.count().reset_index().query("order_amount<=20").order_amount.plot.hist(bins=20)
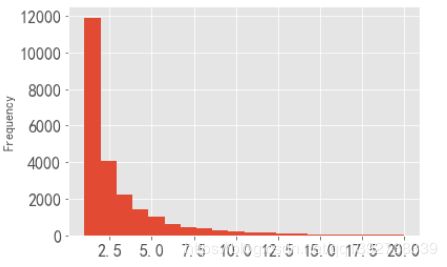
- 由图,超过一半的用户只消费了1次,大约有68%的用户消费了1~2次,说明该网站的用户粘度比较低。
六. 用户消费周期分析
6.1 用户消费时间间隔分析
用户消费时间间隔是指每一位用户前后两次消费的时间间隔;通过分析用户订单的时间间隔,了解用户的消费习惯,可以更好的决定营销方案的实施周期。
#每个用户的每次购买时间间隔
# shift()方法是将数据错位输出,即整列数据下拉一行,第一行用NaT填充
order_diff = grouped_user_id.apply(lambda x:x["order_dt"]-x["order_dt"].shift())
order_diff .head(5)
6.1.1 描述统计
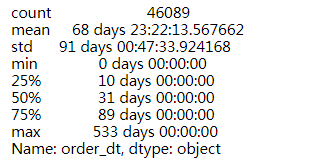
order_diff.describe()
6.1.2 用户消费时间间隔分布
# 用户两次购买时间间隔的分布图
plt.figure(figsize=(10,4))
# 删除空值,消除单位days转化为数值型,绘制直方图
(order_diff.dropna() / np.timedelta64(1, 'D')).plot.hist(bins = 50,fontsize=16)
plt.xlabel("消费间隔时间/天",fontsize=20)
plt.ylabel("频数",fontsize=20)
plt.title('用户消费间隔分布图',fontsize=20)
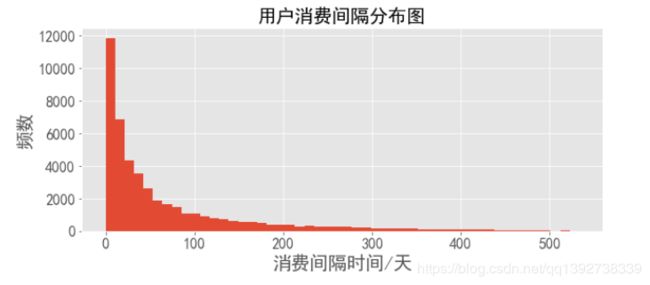
- 由上,用户前后两次消费的平均时间间隔是68天,在90天内的占比75%以上,间隔最长的是533天;因此,在用户消费之后的60天左右,可以采取适当的营销手段刺激用户再次消费。
- 此外,从分布图上,有超过41%的用户消费间隔在20天内,这部分用户可以在消费30天左右进行引导消费。
6.2 用户生命周期分析
这里定义的用户生命周期是指用户的最后一次消费与第一次消费的时间间隔。
6.2.1 描述统计
user_life = grouped_user_id.order_dt.agg(["min","max"])
(user_life["max"]-user_life["min"]).describe()
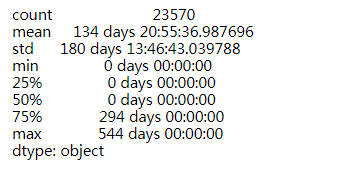
6.2.2 用户生命周期分布
# 用户生命周期分布图
plt.figure(figsize=(10,4))
((user_life["max"]-user_life["min"])/np.timedelta64(1,"D")).plot.hist(bins=25,fontsize=16)
plt.xlabel("生命周期/天",fontsize=20)
plt.ylabel("频数",fontsize=20)
plt.title('用户生命周期分布图',fontsize=20)
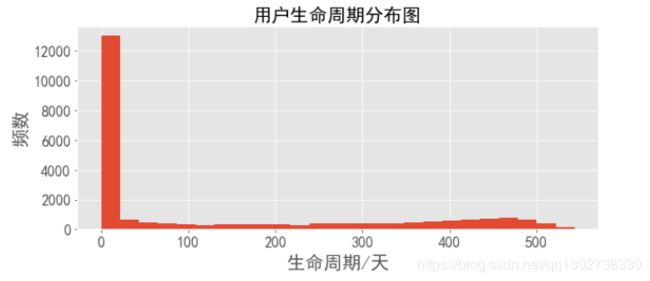
- 由图,用户的生命周期集中在了0天,大部分用户只在一天之内有过消费(次数不定)。下面滤除这部分用户,进一步细化分布。
user_dt = (user_life["max"]-user_life["min"])/np.timedelta64(1,"D")
user_dt[user_dt.values>0].plot.hist(bins=50,figsize = (10,4),fontsize=16)
plt.xlabel("生命周期/天",fontsize=20)
plt.ylabel("频数",fontsize=20)
plt.title('用户生命周期分布图',fontsize=20)
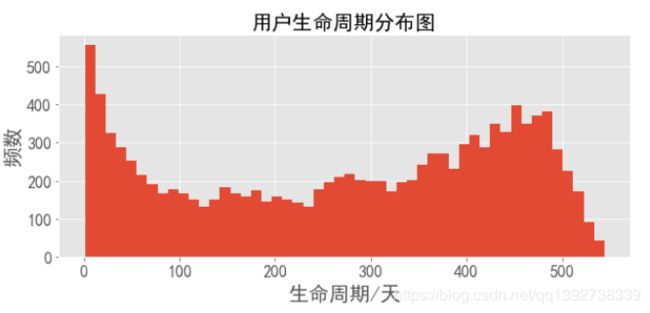
- 所有用户的生命周期平均是134天,但是有50%以上的用户生命周期为0天,即超过一半的用户只在一天内有过消费。因此,从策略上看,应该在新用户消费之后,花费更多的精力去引导他们再次消费,提高他们的消费体验。
- 从分布上分析,用户的生命周期呈现双峰的趋势,一部分集中在30天内,这部分用户粘性不高的,也是需要在30天左右引导消费的用户群;另一部分集中在400~470天之内的用户,可以看出这部分用户的粘性很高,需要继续维持。
七. 用户价值划分(RFM模型)
7.1 RFM模型简介
RFM模型是衡量客户价值和客户创利能力的重要工具和手段。该模型通过一个客户的近期购买行为、购买的总体频率以及消费的金额三项指标来描述该客户的价值状况。
- R(Recency)——最近一次交易时间间隔。基于最近一次交易日期计算的得分,距离当前日期越近,得分越高。
- F(Frequency)——客户在最近一段时间内交易次数。基于交易频率计算的得分,交易频率越高,得分越高。
- M(Monetary)——客户最近一段时间内交易金额。基于交易金额计算的得分,交易金额越高,得分越高。
根据上述三个维度,判断用户的创利能力,并将用户划分为以下8个层次:
- 重要价值客户(111):消费时间近,消费频次和消费金额都很高;
- 重要发展客户(101):消费时间较近,消费金额高,但频次不高,忠诚度不高,很有潜力的用户,需重点发展;
- 重要保持客户(011):最近消费比较远,消费金额和频次都很高;
- 重要挽留客户(001):最近消费时间远,消费频次不高,但消费金额高的用户,可能是将要流失的客户,应当给予措施挽留;
- 一般价值客户(110):最近消费时间比较近,频率高,但消费金额低,需要提高其客单价;
- 一般发展客户(100):最近消费时间近,消费金额和频次不高;
- 一般保持客户(010):最近消费时间比较远,消费频次高,金额不高;
- 一般挽留客户(000):三者都不理想;
7.2 用户价值划分
备注说明:1.由于数据集的日期比较久远,就以最大的日期作为时间的基准,离最大日期越远,则表示消费时间距"今"越久;2.三项指标的高低评判标准是与平均值作比较的,其中消费次数和消费金额大于平均值则为1,低于平均值则为0,而消费时间相反。
# 用透视表新建DataFrame,这里不用包括order_products字段
rfm_demo = data.pivot_table(index="user_id",
values=["order_dt","order_amount"],
aggfunc={"order_dt":"max","order_amount":"sum"})
# 用分组统计每一个用户的消费次数,后续需要合并到新的DataFrame表中
con_times = grouped_user_id.order_products.count()
# 合并
rfm = rfm_demo.join(con_times,how="inner")
# 修改字段名,order_amount对应“M”,这里的order_products是消费次数的统计字段,对应“F”
rfm.rename(columns={"order_amount":"M","order_products":"F"},inplace=True)
# 新添加列,“R”对应距“今”的天数
rfm['R'] = (rfm_demo.order_dt.max()-rfm.order_dt)/ np.timedelta64(1,'D')
# 删除多余的order_dt字段
rfm.drop("order_dt",axis=1,inplace=True)
rfm.head()
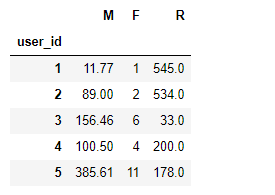
三项指标各自与基准值对比,正值说明指标优于基准值,负值则相反,代码如下:
# 由于最近消费取1,R的处理与F,M相反,分开单独处理
# R值为负值时,说明该值要大于平均值,即最近一次购买在很久之前
df_r = rfm[["R"]].apply(lambda x:x.mean()-x)
df_fm = rfm[["F","M"]].apply(lambda x:x-x.mean())
# 组成一个新的DataFram,供后续判断使用
df_rfm = df_r.join(df_fm)
df_rfm.head()
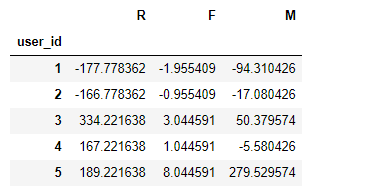
根据比较值,给用户划分价值标签,代码如下:
# 定义一个标签函数,使得df_rfm生成一个标签列,例如:“111“→“对应重要价值客户“
def rfm_func(x):
level = x.apply(lambda x : "1" if x >=0 else "0")
label = level.R + level.F + level.M
d = {"111":"重要价值客户","101":"重要发展客户","011":"重要保持客户",
"001":"重要挽留客户","100":"一般发展客户","110":"一般价值客户",
"010":"一般保持客户","000":"一般挽留客户"}
result = d[label]
return result
rfm["label"] = df_rfm[["R","F","M"]].apply(rfm_func,axis=1)
rfm.head(10)
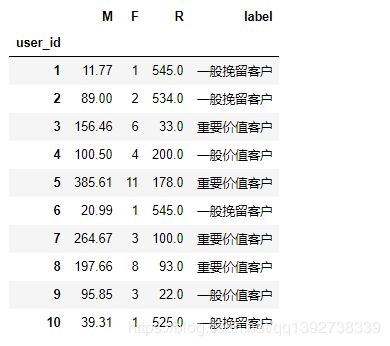
统计各消费层次用户的消费金额和人数占比情况,代码如下:
# 分析不同层次用户消费金额和人数占比情况
# 生成一个只关于M值的DF,直接用sum()函数,生成的是Series格式的
rfm1 = rfm.groupby("label").M.agg([sum]).sort_values(by='sum',ascending=False)
# 修改列名:将生成的sum列修改成M列
rfm1.rename(columns={"sum":"M"},inplace=True)
# 计算不同层次的用户的M和人数占比,以百分比的形式表示
rfm1["M占比"] = (rfm1["M"]/rfm1.M.sum()).apply(lambda x: format(x,'.2%'))
rfm1["人数"] = rfm.groupby("label").M.count()
rfm1["人数占比"] = (rfm1["人数"]/rfm1["人数"].sum()).apply(lambda x: format(x,".2%"))
rfm1
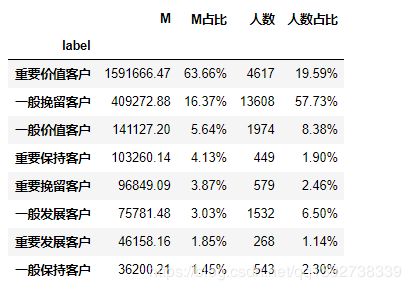
- 从不同层次用户的消费总金额M分析,重要价值客户的消费金额最多,占总消费额63.7%;一般挽留客户消费金额占比16.4%,位列第二。
- 从不同层次用户的人数分析,重要价值客户占比19.6%,排名第二,离一般挽留客户(占比57.7%)的差距较大。
- 业务上可以根据上表对用户群进行针对性的分类运营,这样不但可以降低运营成本,也可以提高运营效果。
八、用户活跃程度划分
本次分析用户的活跃程度分为以下四种:
- 新用户(new):第一次消费;
- 活跃用户(active):上个时间窗口有消费,本时间窗口内再次消费,即为本次时间窗口的活跃用户;
- 回流用户(return):之前有过消费,上个时间窗口甚至更久没有消费,本次时间窗口又消费了,即视为本次时间窗口的回流用户;
- 不活跃用户(unactive):之前有过消费,本次时间窗口没有消费的,视为本次时间窗口的不活跃用户。
本次分析的时间窗口采用的长度是一个月,即统计每一个月不同活跃程度的用户占比分布情况。
# 使用数据透视表,统计每一个用户在每一个月的消费次数情况
# 对于没有消费的空值,用0填充
data_pivot = data.pivot_table(index="user_id",
columns="month",
values="order_dt",
aggfunc='count').fillna(0)
user_con=data_pivot.applymap(lambda x: 1 if x>0 else 0)
user_con.head(3)

- 由于在分析中只需要关注用户在该月是否消费过,不需要关注用户消费的次数,因此用0代表用户在该月没有消费,1代表在该月消费了。
# 用户的本月消费状态需要根据上一个月的消费状态确定
# 所以要先判断是否是第一次记录
def status_func(data):
user_status = [] # 设计空列表,存放用户每一个月的活跃状态
for i in range(len(user_con.columns)): # 每一个月都进行一下判断
# 若本月没有消费
if data[i]==0:
# 是否是第一次记录
if len(user_status) > 0: # 不是第一次记录,再判断上一次记录的是否是未注册
if user_status[i-1] == "unreg": # 上一状态是未注册,本月没消费,本次依旧为未注册
user_status.append("unreg")
else:
user_status.append("unactive") # 已注册过,则这一次为不活跃
# 是第一次记录
else:
user_status.append("unreg")
# 本月有消费
else:
if len(user_status) > 0: # 判断是否是第一次记录
if user_status[i-1] == 'unactive': # 上一个状态是不活跃,本月有消费,则为回流用户
user_status.append("return")
elif user_status[i-1] == "unreg": # 上一个状态是未注册,本月有消费,为新客
user_status.append("new")
else:
user_status.append("active") # 上个月为新/活跃/回流,本月有消费,为活跃
else:
user_status.append("new") # 是第一次记录,有消费,为新客
# 用上述判断出来的状态值替代0,1
data.iloc[0:]=user_status
return data
user_status = user_con.apply(statues_func,axis=1)
user_status.tail(5)

# 将未注册的替换成空值,统计其他消费状态,每一个月的人数
statue_grouped_month = user_status.replace('unreg',np.NaN).apply(lambda x:pd.value_counts(x)).fillna(0).T
statue_grouped_month
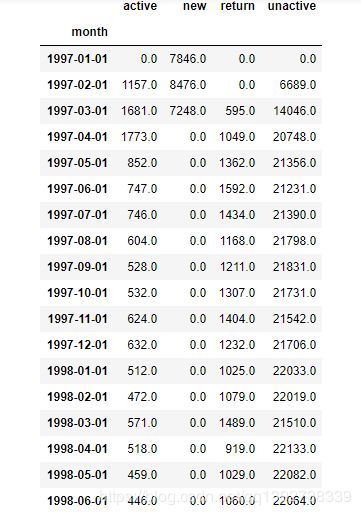
- 由上表可以看出,新客都是集中在前三个月,后续时间里都没有新客消费;每个月活跃用户的数量在逐渐下降,不活跃用户随时间有明显的上升。
接下来绘制每个月不同活跃程度用户的占比。
# 绘制面积图plot.area()
statue_grouped_month.plot.area(figsize = (10,4),fontsize=16)
plt.legend(fontsize=14)
plt.xlabel("month",fontsize=20)
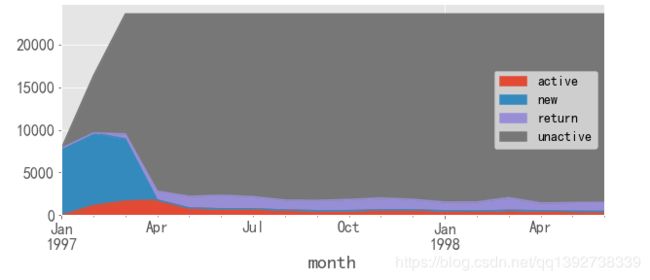
上图为每一个月用户不同活跃程度人数的分布情况,从图可以看出:
- 该网站前个月,新客用户群占比最大从1997年3月开始,不活跃的用户群就达到了最大占比;
- 在每月有消费的用户群中(即新客、活跃用户、回流用户),前3个月新客人数占比很高,活跃用户数在1997年4月占比最大,后续的月份里有消费的用户群占比最大的是回流用户。
status_rate = status_grouped_month.apply(lambda x:x/x.sum(),axis=1)
plt.figure(figsize=(10,5),dpi=80)
ax1 = plt.subplot(221)
status_rate["new"].plot(title="new_rate",fontsize=12)
ax2 = plt.subplot(222)
status_rate["unactive"].plot(title="unactive_rate",fontsize=12)
ax3 = plt.subplot(223)
status_rate["return"].plot(title="return_rate",fontsize=12)
ax3 = plt.subplot(224)
status_rate["active"].plot(title="active_rate",fontsize=12)
plt.tight_layout() # 调整图与图之间的距离
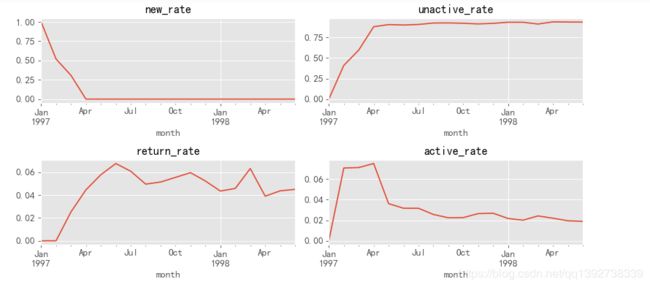
- 上图是不同活跃程度用户每月占比的变化趋势,可以更加明显地看到在后续的时间里,回流用户每月占比后期在4%~6%之间,最后是在4%左右,有下降的趋势;同时活跃用户从最高的8%逐渐下降到2%,说明用户的忠诚程度是有一定的下降的;不活跃用户在逐步上升,用户流失较大。以上都会导致网站的销售额逐渐下降。
九. 用户质量分析
9.1 消费一次用户占比
buy_times = grouped_user_id.order_dt.count().reset_index()
# 统计仅消费一次和消费多次的用户
buy_one = (buy_times["order_dt"]==1).value_counts().values
# 绘制饼图
plt.figure(figsize=(8,4),dpi=80)
plt.pie(x = buy_one,
autopct = '%.1f%%',
shadow = True,
explode = [0.08,0],
textprops = {'fontsize' : 16})
plt.axis('equal')
plt.legend(['仅消费一次','多次消费'],loc="upper right",fontsize=14)
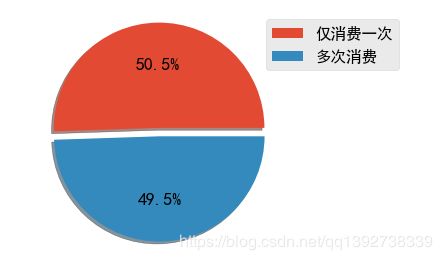
- 如图,有超过一半的用户仅消费了一次,这也说明了运营不利,留存效果不好。
9.2 复购率
复购率是指在一个时间窗口内,购买多次的用户占比(购买多次的用户人数/总的消费人数)。
# 复购率涉及到每一个用户、每一个月的订单情况,所以可以先用user_id做索引,月份做列名来统计一下
re_purchase_demo = data.pivot_table(index="user_id",columns="month",
values="order_dt",
aggfunc="count")
# 转换:消费2次以上记为1,消费1次记为0,消费0次记为NAN
# 转换的目的:这样可以利用sum()计算出2次消费以上的人,用count()计算有过消费的用户
re_purchase = re_purchase_demo.applymap(lambda x: 1 if x>1 else 0 if x==1 else np.NaN)
plt.figure(figsize = (10,4))
plt.xlabel('month', fontsize=16)
plt.ylabel('复购率',fontsize=16)
plt.title('复购率趋势图',fontsize=18)
(re_purchase.sum()/re_purchase.count()).plot(fontsize=14)
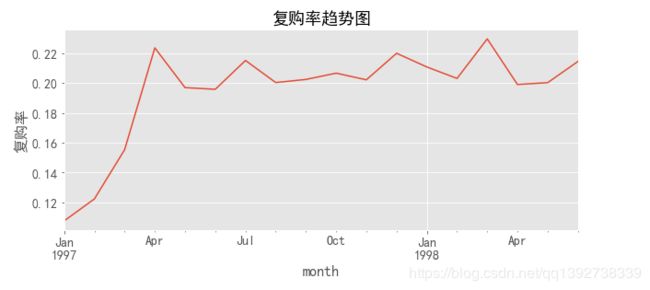
- 由上图,前3个月的复购率不高,是由于大量的新客加入,并且新客的复购率也不高;而在后期,这时的用户都是比较忠诚的用户,复购率比较稳定,在21%左右。
9.3 回购率
记某一个时间窗口内消费的用户数量为A,在下一个时间窗口仍旧消费的用户数量记为B,这里定义B/A为回购率。通过分析回购率,可以大致预测下个时间窗口用户的消费人数。
本次回购率分析以一个月的时间长度作为一个时间窗口。
# 新建数据透视表,统计每一个用户的每月消费次数
back_purchase_demo = data.pivot_table(index="user_id",columns="month",
values="order_dt",
aggfunc="count")
# 区分有消费和没消费的,有消费的记为1,没有消费的记为0.
back_purchase = back_purchase_demo.applymap(lambda x:1 if x>0 else 0 )
#如果本月进行消费,下月也进行消费,则记为1;如果下月没有消费,则记为0,若本月没有记为消费,则记为nan
def purchase_func(data):
status = []
for i in range(len(back_purchase.columns)-1): # 减1是排除最后一个月,最后一个月分析不了
# 本月有消费
if data[i]==1:
if data[i+1]==1:
status.append(1) # 本月消费并且下个月也消费了,则为1
else:
status.append(0) # 本月消费,但下个月没有消费,则为0
else:
status.append(np.NaN) # 本月没有消费的
status.append(np.NaN) # 最后一个月,没有下个月可以作对比,用NaN填充。
data.iloc[0:]=status
return data
back_user = back_purchase.apply( purchase_func,axis=1)
back_user.head()
# 绘制趋势图
plt.figure(figsize=(10,8))
# 绘制回购率趋势图
plt.subplot(211)
plt.ylabel("回购率",fontsize=10)
plt.title("用户回购率趋势图",fontsize=16)
(back_user.sum()/back_user.count()).plot(fontsize=14)
# 绘制每月回购用户数趋势图
plt.subplot(212)
plt.ylabel("回购频次",fontsize=10)
plt.title("回购用户数量趋势图",fontsize=16)
back_user.sum().plot(fontsize=14)
plt.tight_layout() # 调整图与图之间的距离
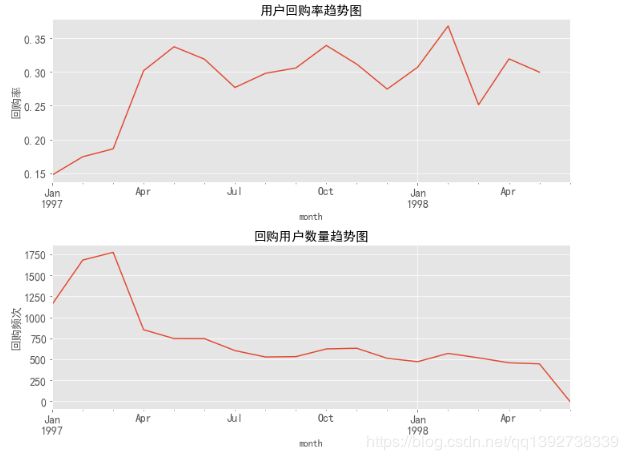
- 上图可以看出,在初期用户的回购率并不高,前3个月的回购率只有15%-18%,4月份起回购率在30%左右震荡。
这也说明了对于新用户,在其第一次消费后的三个月内是一段重要的时期,需要营销策略积极引导其再次消费及持续消费。 - 从用户回购数量趋势图看,回购用户数整体呈下降趋势;因此,对于有持续消费的老客,也要适时推出反馈老客户的优惠活动,以加强老客的忠诚度。
9.4 留存率
留存率分析主要是针对一年以内,用户在首购后,在以下各个周期内的再次购买的分布情况。本次选定的周期为(7天,15天,30天,60天,90天,180天,365天)。
- 计算用户每次消费距离首购的时间间隔date_interval
# 用户第一次消费的时间
order_dt_min = data.groupby("user_id").order_dt.agg(["min"]).reset_index()
# 组建新的DataFrame,并计算用户每次消费距离首次消费的时间间隔
retain_user = pd.merge(data[["user_id","order_dt","order_amount"]],order_dt_min,how="inner")
retain_user["date_interval"] = (retain_user["order_dt"] - retain_user["min"])/np.timedelta64(1,'D')
retain_user.head(10)
- 将时间间隔按照分割区间,进行分割归组
# 将时间间隔进行分组[0,7,15,30,60,90,180,365]
bins=[0,7,15,30,60,90,180,365]
retain_user['date_interval_bins']=pd.cut(retain_user.date_interval,bins=bins)
retain_user.head(10)
- 统计用户在首购后,在每个留存周期内的平均消费金额的分布。
# 用户在不同留存周期的消费金额
retention_demo=retain_user.pivot_table(index='user_id',columns='date_interval_bins',
values='order_amount',aggfunc=sum,dropna=False)
retention_demo.head()
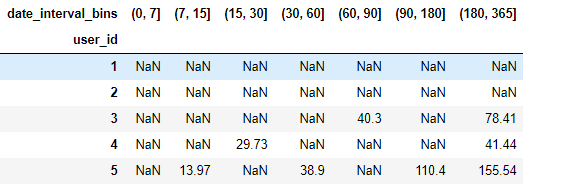
# 绘图
plt.figure(figsize=(8,4),dpi=80)
retention_demo.mean().plot.bar(fontsize=12)
plt.title("留存后平均消费金额")
plt.ylabel("消费金额")
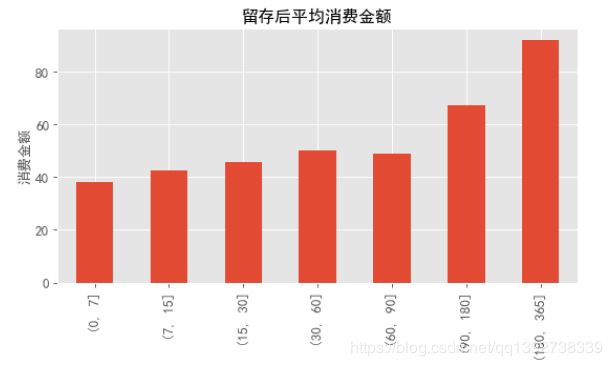
- 如上图在用户首购后的180天~365天内,用户的平均消费金额达到最大。
接下来统计每个留存周期内的留存率。
#1代表有消费,0代表没有
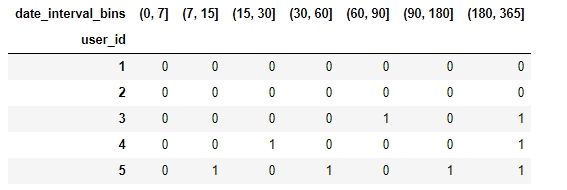
retention=retention_demo.applymap(lambda x:1 if x>0 else 0)
retention.head()
# 每个周期的留存率
# 取X轴,Y轴数据
x1 = (retention.sum()/retention.count()).index.astype(str)
y1 = (retention.sum()/retention.count()).values
# 绘制折线图
plt.figure(figsize=(10,5),dpi=80)
plt.plot(x1,y1, marker='o')
plt.xticks(fontsize=14)
plt.yticks(fontsize=14)
plt.title('留存率',fontsize=16)
# 添加数据标签
for a, b in zip(x1, y1):
plt.text(a, b, round(b,2), ha='left', va='top', fontsize=12)
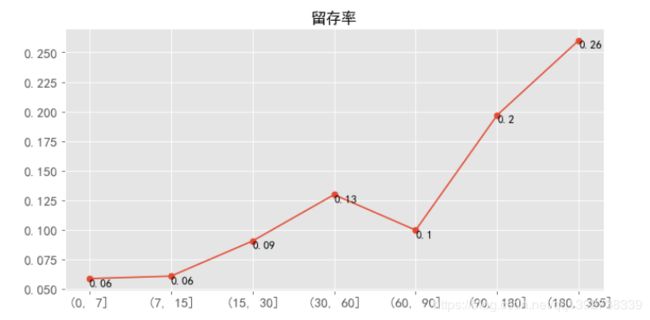
- 如上图,有6%的用户在第一次消费后的1~7天里再次消费,6%的用户在8~15天内再次消费,有20%的用户在第一次消费后的三个月到半年之间有过购买,26%的用户在半年后至1年内有过购买,可以看出购买CD不是高频消费行为。
- 结合不同周期的用户平均消费金额可以看出,用户第一次消费后的180~365天,CD的需求会比较大。
十. 总结
- 1.从整体趋势
- CD的销售金额和销售量在1997年1月~3月相对较高,在4月份大幅度骤降,下降幅度为63.7%,下降原因可以根据流量波动模型以及实际的业务情况进行排除,后续运营中规避相应风险,甚至根据风险找到业绩的突破口。
- 1997年4月份之后,销售金额与销售量趋于平稳,但是有下降的趋势,在后续运营中可以展开营销活动,刺激用户的回流以及获取新客。
- 2.从用户个体消费行为分析
- 消费金额:平均每一位用户的消费金额为106元,但超过50%的用户消费不到44元,处于低消费水平,因此,如何吸引这部分用户提高消费,转化为高消费人群也是一个棘手和有重大意义的问题。
- CD购买量:平均每一位用户购买了7.1张CD,但是有超过50%的用户购买不到3张CD,由销售金额和销售数量的相关性可知,这批用户是消费水平低的用户,对于这批小金额小批量的用户,可以通过丰富产品种类和产品价格来和低价优惠来吸引消费。
- 二八法则:由于有50%的用户是低消费群体,因此对应的会存在一群高消费群体,即对应着二八法则,通过统计发现,有21.2%的用户贡献了70%的销售额,有31.8%的用户贡献了80%的销售额,因此,对于这部分高质量用户,可以对应建立会员制,已实现专门化运营。
- 消费次数:平均每一位用户消费了3次,但是超过50%的用户只消费了1次,大约有68%的用户消费了1~2次;对于购买次数少的用户,可以考虑分析网站的用户体验方面是否存在需要改善的地方。
- 3.用户消费周期
- 用户消费时间间隔: 用户前后两次消费的时间间隔平均是68天,在90天内的占比75%以上,有超过41%的用户消费间隔在20天内;对于用户在这方面的习惯,可以制定对应策略,例如:在用户消费15天后,发送优惠券(需要综合考虑成本、利润),这样可以刺激用户再次消费,在用户购买后的60天左右,提醒用户优惠券的使用。
- 用户生命周期:所有用户的生命周期平均是134天,但是有50%以上的用户只在一天内有过消费;排除这部分用户后,用户的生命周期呈现双峰的趋势,一部分集中在30天内,另一部分集中在400~470天之内的;生命周期在30天以内的用户占比56.2%,因此,上面提到的优惠券方案也可以用于提高用户的生命周期上。
- 4.用户价值划分(RFM模型)
- 基于RFM模型,将用户划分为八个价值程度不同的用户,其中,重要价值客户人数占比19.6%,消费金额占比63.7%,是需要重点维护运营的用户群;此外,实际业务可以根据RFM模型,对用户进行针对性的运营,这样不但可以降低运营成本,还可以提高运营效果。
- 当然实际的用户价值度划分,需要根据实际业务指标的重点程度进行分析,这里展示的是最基本、最简单的划分。
- 5.用户活跃程度划分
- 本次分析根据用户的月消费行为,把用户划分为新用户、活跃用户、回流用户、 不活跃用户。
- 新用户:新用户集中在前三个月,后续时间里都没有新用户消费;
- 活跃用户:前四个月,活跃用户占比在不断地上升,1997年5月份,出现了大幅度的下跌,从最高的8%骤降到4%,后续随着时间推移,在缓慢下降,最后在2%上下波动。
- 回流用户:回流用户的占比前期在不断地上升,中期在4%~6%范围内震荡,最后维持在4%左右,整体也是呈现一个下降趋势;
- 不活跃用户:不活跃用户每月占比都在不断的上升,最后稳定在93.6%。
- 以上各个用户群的占比趋势变化说明了,用户在逐渐的流失,忠诚度也在逐步下降。因此在后续运营中,可以根据用户的活跃程度,决定什么时间展开促销活动,刺激用户消费,这样可以让用户回流以及更加活跃的消费。
- 6.用户质量
- 消费一次用户占比: 有50.5%的用户只消费了一次,留存率不高;
- 复购率:前3个月,用户的复购率不高,是由于大量的新客加入,并且新客的复购率也不高;而在后期,用户的忠诚度比较高,复购率比较稳定,在21%上下震荡。
- 回购率:在初期,用户的回购率并不高,前3个月的回购率只有15%-18%,4月份起回购率在30%左右震荡。这也说明了对于新用户,在其第一次消费后的三个月内是一段重要的时期,需要营销策略积极引导其再次消费及持续消费。
- 留存率:本次留存率划分的周期区间是(7天,15天,30天,60天,90天,180天,365天),有6%的用户在第一次消费后的1~7天内再次消费,6%的用户在8~15天内再次消费,有20%的用户在第一次消费后的三个月到半年之间有过购买,26%的用户在半年后至1年内有过购买,可以看出购买CD不是高频消费行为。
- 结合不同周期的用户平均消费金额可以看出,用户第一次消费后的180~365天,CD的需求会比较大。