深度理解计算机内存对齐
内存对齐是任何一个学习底层语言的程序员都要遇到的很关键的问题,尤其是计算
struct这种复合数据类型大小时,就不再是简单的成员大小相加。这是因为计算机需要内存对齐导致的。本篇博文将对内存对齐进行深度解释,从根源上解决疑问。
数组和结构体
数组
数组属于复合结构类型,它是相同类型元素的结合,所以一旦数组定义完成,其成员类型都是同种类型,可以想象成线性紧密排列。所以计算一个数组大小时,它总是跟我们预期的大小一致。结构体
结构体不同于数组,为了解决实际中遇到的问题,它可以将多种类型聚合在一起,但是因为每个成员大小比如int,char,double等等。(每个类型的大小不一,所以它不能够通过下标或者成员指针类型加减的方式访问每个成员,它通过成员名字访问),当用sizeof计算对应结构体大小时,绝大多数情况它总是跟我们预期的大小有出入,且永远是偶数。
为什么会这样?这就涉及到了计算机内存对齐。在寻找答案的过程中,一般解释都是仅仅对内存对齐的规则,地址分配规定再加上高深莫测术语上进行阐释(在此就不再赘述),并未对内存对齐的种种疑问做出很好的解释,所以我决定自己钻研解决。
在经过对CPU和DRAM的发展、框架、构造、连接等原理上的了解和思考后
大致明白了cpu寻址过程、内存中的数据的存放规则、片选信号、分时传输机制等等。对编译器对内存地址分配的规则,实际数据在内存中的布局有了知其所以然的快感。
现在通过我的问题主线,一步一个脚印还原主要问题出现和解决。
1.未对齐地址的数据对读取的影响
当前认知:
- 此cpu有32位数据总线,32位地址总线
- 数据总线每次访问可以直接提取32 bits的数据也就是4个字节
- 地址总线可以寻址2^32(4G)个地址单位,一个字节对应一个地址。
源:在访问未按4倍数对齐的地址读取四字节数据时,cpu的读取过程如下
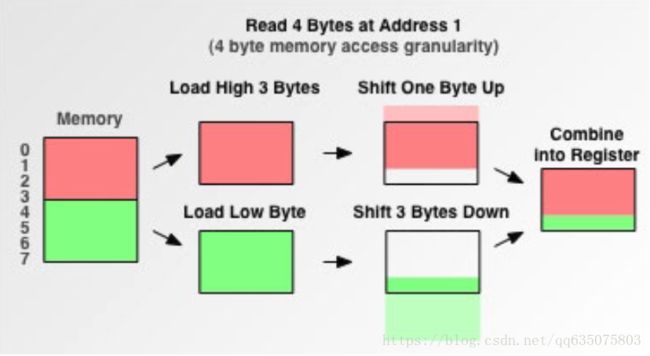
假设要从地址1处访问四个字节,解释是cpu将在第一个总线周期先获得0~3地址的内容RED,然后再第二个总线周期获取4~7地址处的内容GREEN。然后移出RED的第一个字节,再移出GREEN的后三个字节,然后将数据整合到寄存器中,所以这样再未对齐的地址处访问4字节的数据就有了两次的总线周期。导致时间加长。
但一个简单的例子显得说服力微乎其微。
那么现在通过以下代码对应测试16位,32位CPU在不同地址上处理size个字节数据的耗时。
16位cpu操作
void CPU16( void *data, int32_t size ) //size表示要操作的字节数
{
int *data16 = (int*) data;
int *data16End = data16 + (size >> 1); //2字节跨度
char *data8 = (char*) data1End;
char *data8End = data8 + (size & 0x00000001); //用char*处理剩下的字节
while( data16 != data16End ) {
*data16++ = -*data16;
}
while( data8 != data8End ) {
*data8++ = -*data8;
}
} 32位cpu操作
void CPU32( void *data, int size ) //size表示要操作的字节数
{
int *data32 = (int*) data;
int *data32End = data32 + (size >> 2); //四字节跨度
char *data8 = (char*) data32End;
char *data8End = data8 + (size & 0x00000003); //用char*处理剩下的字节
while( data32 != data32End ) {
*data32++ = -*data32;
}
while( data8 != data8End ) {
*data8++ = -*data8;
}
} 结果图

其中x轴代表起始地址。y轴代表时间,单位微秒。
BLUE->CPU16
GREEN->CPU32
可见,无论是双字节访问粒度(CPU16)还是四字节当问粒度(CPU32)在非按照其粒度倍数对齐的地址读取数据时,都会都会耗费将近一半的时间。在非对齐地址上处理相同字节数据的CPU32比CPU16仍要缩短将近一半时间。
问:我现在知道了它访对非对齐地址读取粒度长度的数据至少需要个周期,但是按照当前的理解,一个地址对应一个字节,一次访问从当前地址向后在内存提取4个字节的数据,对于地址1读取4个字节数据理论而言是合理的,那它为什么非要这般费力从4(CPU32)或者2(CPU16)倍数对齐处读取数据?这就需要了解CPU与内存的设计和连接方式等等。
内存设计与工作原理
为了简化篇幅这里大致介绍DRAM小部分设计、大致工作原理及与CPU的联系,感兴趣可以自行搜索补充。
现代计算机来说,最关键的2个部件就是CPU和内存。内存中存储了要执行的程序指令,而CPU就是用来执行这些指令的。CPU工作需要知道指令或数据的内存地址,那么这样一个地址是如何和内存这样一个硬件联系起来的呢?现在就看看内存到的是怎么工作的。
- DRAM芯片结构

上图是DRAM芯片一个单元的结构图。一个单元被分为了N个超单元(可以叫做cell),每个cell由M个DRAM基本单元(1bit)组成。 所以描述一个DRAM芯片可以存储N*M位数据。上图就是一个有16个超单元,每个cell8位的存储模块,我们可以称为16*8bit 的DRAM芯片。而超单元(2,1)我们可以通过如矩阵的方式访问,比如 data = DRAM[2.1] 。这样每个cell都能有唯一的地址,这也是内存地址的基础。
每个超单元的信息通过地址线和数据线传输查找和传输数据。如上图有2根地址线和8根数据线连接到存储控制器(注意这里的存储控制器和前面讲的北桥的内存控制器不是一回事),存储控制器电路一次可以传送M位数据到DRAM芯片或从DRAM传出M位数据。为了读取或写入【i,j】超单元的数据,存储控制器需要通过地址线传入行地址i 和列地址j。这里我们把行地址称为ROW(Row Access Strobe)请求, 列地址称为(Column Access Strobe)请求。
但是我们发现地址线只有2位,也就是寻址空间是0-3。而确定一个超单元至少需要4位地址线,那么是怎么实现的呢?
- 分时传送地址码

采用分时传送地址码的方法。看上图我们可以发现在DRAM芯片内部有一个行缓冲区,实际上获取一个cell的数据,是传送了2次数据,第一次发送RAS,将一行的数据放入行缓冲区,第二期发送CAS,从行缓冲区中取得数据并通过数据线传出。这些地址线和数据线在芯片上是以管脚(PIN)与控制电路相连的。将DRAM电路设计成二维矩阵而不是一位线性数组是为了降低芯片上的管脚数量。入上图如果使用线性数组,需要4根地址管脚,而采用二维矩阵并使用RAS\CAS两次请求的方式只需要2个地址管脚。但这样的缺点是增加了访问时间,所以在计算机运行时,数量庞大的内存访问会大大降低系统运行速度。由此应运而生了多级缓存的概念,以便提高数据获取效率
为了使CPU能在一次从内存中获取尽可能多的数据,加宽数据总线就显得尤为重要
- 字扩展和位扩展
显然,如果每个DRAM芯片就只有这么一点大,仅仅是将每片单纯连在一起的话, 那光4G内存的占整个卧室那么大吧。所以就有了字扩展和位扩展。 - 字长位数扩展
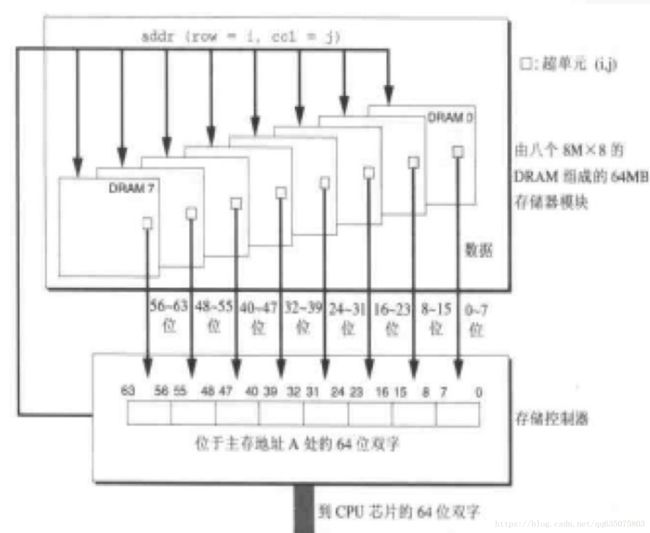
位扩展的方法很简单,只需将多片RAM的相应地址端、读/写控制端 和片选信号CS并接在一起,而各片RAM的I/O端并行输出即可。 如上图,我们采用了8个DRAM芯片分,别编号为0-7,每个超单元中存储8位数据。在获取add(row=i,col=j)地址的数据的时候,从每个DRAM芯片的【i, j】单元取出一个字节的数据,这样传送到CPU的一共是8*8b = 64b的数据。我们通过8个8M*8b的内存颗粒扩展为了8M*64b的内存模块。
但是这样仅仅只是竖向扩展,要实现空间的缩小还要实现横向扩展,这时候就需要字扩展 - 字存储容量扩展
RAM的字扩展是利用译码器输出控制各片RAM的片选信号CS来实现的。RAM进行字扩展时必须增加地址线,而增加的地址线作为高位地址与译码器的输入相连。同时各片RAM的相应地址端、读/写控制端 、相应I/O端应并接在一起使用。下图是对应X86cpu的RAM进行字、位扩展后的内存布局、总线连接
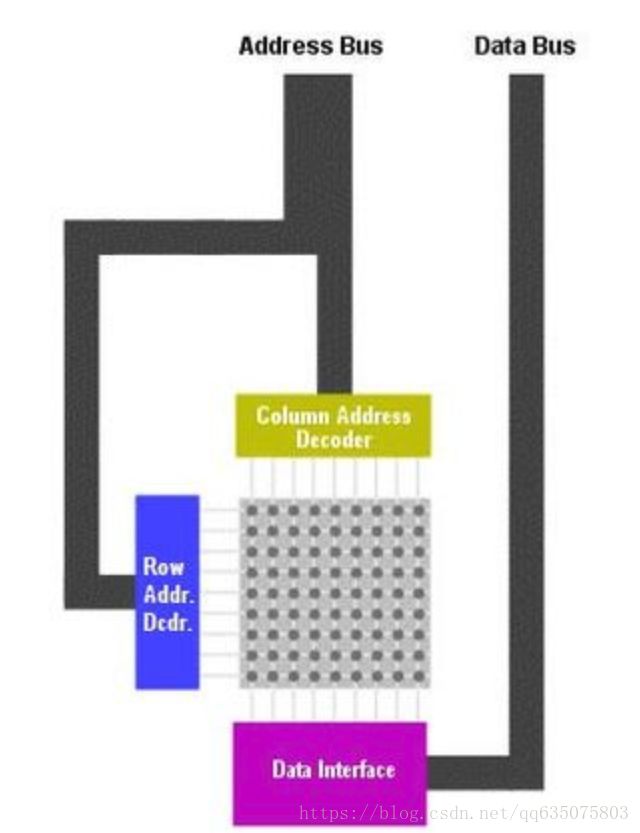
对于X86 处理器,如下图所示它通过地址总线发出一个具有22 位二进制数字的地址编码,其中11 位是行地址,另外11 位是列地址,其通过RAM 地址接口进行分离。行地址解码器(row )会首先确定行地址,然后列地址解码器(col)将确定列地址,这样就能确定唯一的存储数据的位置,然后该数据就会通过RAM 数据接口将数据传到数据总线。

由上图可知,对应X86cpu(32位数据总线)的RAM的每个芯片的超单元位已经被扩展到了32bits,它分别对应32位CPU数据总线,例如要从0地址开始读取四个字节,那么它就可以一次性提取出这四个字节的内容,这样不仅仅提高了提取效率,也大大缩小了访问局限和内存体积。否则读取一个int变量就需要进行4次内存操作(8位处理器)。
如果你从文章开始认真看到了这个地方,那么相信你对 无法从任意地址提取四个字节数据有了一定的答案。
对无法从任意地址上进行数据操作的解释
此处不讨论intel 8086cpu,因为它有16跟地址线和20根数据总线,使用了内存分段的原理进行寻址,有兴趣的盆友可以翻阅《C专家编程》第七章对内存的思考其中对Intel处理器的发展和内存有很好的介绍。
这里以X86CPU进行讨论。我们了解到地址是按照字节编制的,即一个地址对应第一个字节大小的数据。但是在RAM上一个芯片的超单元就将四个字节的数据纵向固化在一起,显然逻辑上就是0~3,4~7……这些单元被“一根一根”被整合在一起。对于内存访问一般有以下两个条件:
CPU进行一次内存访问读取的数据和字长相同。
有些CPU只能对字长倍数的内存地址进行访问。
对于第一个条件一般来说,目前存储器一个cell是8bit,进行位扩展使他和字长还有数据线位数是相同,那么一次就能传送CPU可以处理最多的数据。而前面我们说过目前是按字节编址可能是因为一个cell是8bit,所以一次内存操作读取的数据就是和字长相同。
也正是因为位扩展后每个DRAM位扩展芯片使用相同RAS。对于而言寻址,这里就涉及到了片选信号。
- 片选信号概述
当CPU通过地址线想存储器传送地址时,在字扩展介绍中,存储器通过各个原件其实对该地址进行了解析,如果CPU按照4倍数地址对齐输入,那么地址的最低两位就时00,此时有效地址中就包含了片选信号,告诉存储控制器该选择哪块目标芯片,从而在芯片上通过行列译码器提取对应cell一次性提取32bits。
所以以32位CPU为例,CPU只能对0,4,8,16这样的地址进行寻址。若要对任意地址寻址,若从地址2处访问四个字节,勤奋的处理器就不得不做出一些判断进行多次内存访问和提取移位等操作(如通过中间层“Memory Controller”),(然而早期一些处理器很懒,如68000,它是一个16位的处理器,当你给出一个未按2倍对齐的地址去提取四字节数据时,它会直接报异常)而现有的按4的倍数寻址就不存在这样的问题了。而很多32位CPU禁掉了地址线中的低2位A0,A1,这样他们的地址必须是4的倍数,否则会发送错误。当然intel很早开始就支持对未对齐地址的访问,但是这样会浪费掉很多时间,对于具有更高内存粒度的处理器如果大量地址未对齐效率将更加降低。
如果你想知道CPU地址线和内存的连接方法和计算原理
那么你有没有想过:
- CPU是如何判断每次操作的字节数的?
- CPU如何区分指令长度和操作地址的?
- 每条指令都包含了哪些信息?
- 不同规格、型号的cpu和RAM区别和联系?
- 虚拟地址、逻辑地址、物理地址、之间的区别和存在意义
- 什么时原子指令?内存对齐对于多进程任务的意义
and so on
现在来理解结构体的内存规则
现在可以知道,编译器其实在我们每次定义变量分配内存时总是按照偶地址的规则来进行。对于结构体而言,考虑到世界上品种繁多的CPU 8、16、32、64等等,我们的代码不能只在自己机器上使用吧,对于任何CPU首先不能把变量分配在奇地址上,这一点编译器做到了,每个成员类型按照自己大小的对齐数分配地址,这是为了做到读取的便利,和尽可能的实现跨平台。但是最后为什么要以最大成员数倍数来决定他的大小?
因为如果创建结构体数组,数组成员是紧密排列的,那么就会导致存在成员未在自己的对齐数上,这对CPU执行效率和程序可移植性上都是比较差的。所以还要在后面padding几个字节空间,实现最大化的效率。
通过对CPU、内存的角度来看待内存对齐,耗费了不少精力。但是解决问题的时刻总是快感淋漓,对于内存有了更深刻的认识。
篇幅有限,难免有疏漏。见识甚浅,如果有任何错误的地方请指出。