全栈项目iCCUT之服务端开发(一)
全栈项目iCCUT之数据篇(一)
(一)项目简介
由于博主是一个二流大学的码农,所以想为二流大学量身定做一款APP(当然啦,我只做iOS端的),一来方便学校生活,二来也锻炼一下自己的全栈能力。这个项目的主要功能嘛,无非就是搞个校园新闻首页,偷看学校的免费影视资源,还有就是自动登录上网账号什么的。OK,废话不多说,开始上手。
(二)开发准备
在本篇中,博主的主要目的是用简单的爬虫把校园网上的影视资源爬取下来并且存储到MySQL中去,以供以后APP服务端使用。为此,我们即将用到的是以下的一些工具:
- MySQL
- Python
- PyCharm
- Navicat for MySQL
(三)环境配置
由于我们需要通过Python连接数据库,因此我们少不了使用MySQLdb模块。唉…Mac装这玩意还真没我想象中轻松啊。
1.安装MySQLdb
在max os x下安装mysql,我们需要使用python访问mysql数据库,需要安装MySQLdb模块,方法如下:
在下面的网址下载mysqldb模块:
http://sourceforge.net/projects/mysql-python/
解压以后,在解压文件中找到setup_posix.py
找到:
mysql_config.path = “mysql_config”
改为:
mysql_config.path = “/usr/local/mysql/bin/mysql_config”
然后执行:
sudo python setup.py install
安装成功后,在命令行输入python进入python环境,输入import MySQLdb,我的环境中报下面的错误:
import MySQLdb
Traceback (most recent call last):
File “”, line 1, in
File “/Library/Python/2.7/site-packages/MySQL_python-1.2.4b4-py2.7-macosx-10.11-intel.egg/MySQLdb/init.py”, line 19, in
import _mysql
ImportError: dlopen(/Library/Python/2.7/site-packages/MySQL_python-1.2.4b4-py2.7-macosx-10.11-intel.egg/_mysql.so, 2): Library not loaded: libmysqlclient.18.dylib
Referenced from: /Library/Python/2.7/site-packages/MySQL_python-1.2.4b4-py2.7-macosx-10.11-intel.egg/_mysql.so
Reason: unsafe use of relative rpath libmysqlclient.18.dylib in /Library/Python/2.7/site-packages/MySQL_python-1.2.4b4-py2.7-macosx-10.11-intel.egg/_mysql.so with restricted binary
在10.10的系统环境下只需要:
sudo ln -s /usr/local/mysql/lib/libmysqlclient.18.dylib /usr/lib/libmysqlclient.18.dylib
然而,我的系统已经升级到了10.11,输入上述的指令以后报错:
n: /usr/lib/libmysqlclient.18.dylib: Operation not permitted
出现如下提示的原因是:
OS X 10.11 中System Integrity Protection 的功能,阻止了写入的操作的,默认是开启的,需要关闭。
关闭方式:
重启电脑,开机时按住 cmd + R,进入 Recovery 模式。然后打开终端工具 ,输入命令:csrutil diable,然后再次重启电脑即可。
但是关闭以后,10.11安全性方面的特性就不复存在了,假如既不想关闭 System Intergrity Protection 功能,又想解决Python-MysqlDB的问题,经过Google的帮助,找到了一个解决方法:
sudo install_name_tool -change libmysqlclient.18.dylib \
/usr/local/mysql/lib/libmysqlclient.18.dylib \
/Library/Python/2.7/site-packages/MySQL_python-1.2.4b4-py2.7-macosx-10.9-intel.egg/_mysql.so
在Python环境下再次import MySQLdb,OK!大功告成,模块已经安装成功了。
(四)数据库
在创建数据库之前我们先来看一看校园网视频的下载界面。

好吧,果然丑的那么的理所当然。由于我很懒,所以在构建表的时候我只用上了它的ID,视频名字,视频地址,一级分类和二级分类这些必须的字段。如图:
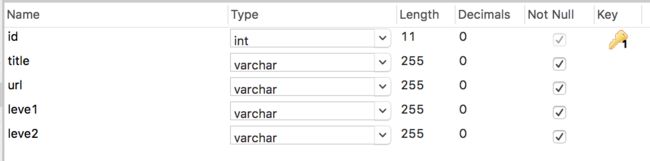
这样的话数据库端的告一段落,很简单吧(我还在纠结新闻的数据要不要也用这种方式存储,如果后续添加功能我会更新的)。
(五)Python
Python大法好啊!
在构建爬虫之前,我们先来分析一下网页。如图:
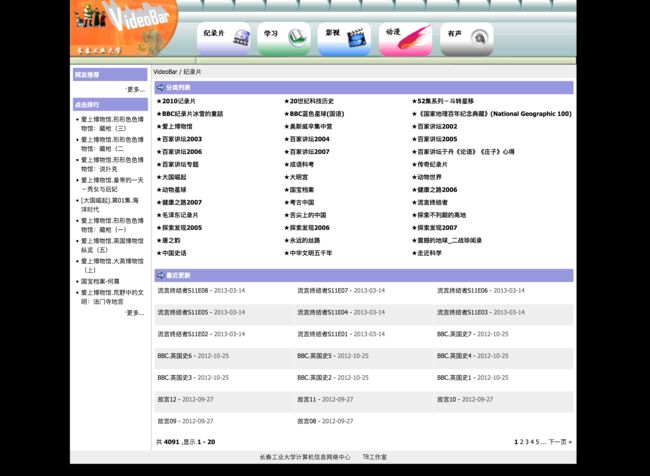
看这个貌似有很多的目录层级需要爬取,但是进去之后我笑了:
所有的资源地址都有相同的规律,即http://v8.ccut.edu.cn/article.php?/XXXXX.有了这样的规律以后,就根本不需要翻进去翻出来的爬取数据了,校园网果然有二流学校的作风,连scrapy模块都可以省略了。
第一步:
新建一个ParserPage.py
既然是要搞爬虫,那么urllib2和re模块肯定是必不可少的了。
先通过urllib2获取页面内容,当然还要经过我们学校隔路的gb2312编码才能看到内容:
html = urllib2.urlopen(url).read().decode(“gb2312”)
然后再定义三个正则表达式,分别从下载界面中获取视频名称、地址和两个分类。
#视频名称
patName = re.compile(r'(.*)')
#视频地址
patURL = re.compile(r'href="(.*\.rmvb|.*\.mp4)"')
#视频分类
patList = re.compile(r'(.*?)')
最后通过findall的方法获取所需要的内容:
resName = re.findall(patName,html)[0]
resURL = re.findall(patURL,html)[0]
resList = re.findall(patList,html)
这是获取一个下载页面的信息,到时候要获取两万多个地址的信息的时候只需要将其抽成一个方法,传入变化的地址参数就可以解析了。
第二步:
新建一个mysql.py
接下来就是连接数据库,并且保存数据了。引入之前搞了蛮久的MySQLdb。
import MySQLdb
定义好host,port,username,pwd。
host = 'localhost'
port = 3306
user = 'root'
pwd = ''
进行连接并且获取游标,对了不要忘记了设置字符集哦!
def __init__(self):
self.conn = MySQLdb.connect(host=self.host,user=self.user,passwd=self.pwd,db='sy_video',port=self.port,charset='gb2312')
self.conn.set_character_set('gb2312')
self.cur = self.conn.cursor()
定义一个插入数据的方法供外界调用,记得不要忘记了commit。
def insertData(self,id,title,url,leve1,leve2):
try:
sql = 'insert into FreeVideo values(%d,"%s","%s","%s","%s")' % (id,title,url,leve1,leve2)
print(sql)
self.cur.execute(sql)
self.conn.commit()
except MySQLdb.Error,e:
print "Mysql Error %d: %s" % (e.args[0], e.args[1])
最后就是把mysql.py和ParserPage.py整和起来使用了。完整的代码如下:
mysql.py
__author__ = 'Maru'
import MySQLdb
class Mysql:
host = 'localhost'
port = 3306
user = 'root'
pwd = ''
def __init__(self):
self.conn = MySQLdb.connect(host=self.host,user=self.user,passwd=self.pwd,db='sy_video',port=self.port,charset='gb2312')
self.conn.set_character_set('gb2312')
self.cur = self.conn.cursor()
def queryAllData(self):
try:
sql = 'select * from FreeVideo'
self.cur.execute(sql)
except MySQLdb.Error,e:
print "Mysql Error %d: %s" % (e.args[0], e.args[1])
def insertData(self,id,title,url,leve1,leve2):
try:
sql = 'insert into FreeVideo values(%d,"%s","%s","%s","%s")' % (id,title,url,leve1,leve2)
print(sql)
self.cur.execute(sql)
self.conn.commit()
except MySQLdb.Error,e:
print "Mysql Error %d: %s" % (e.args[0], e.args[1])
ParserPage.py
__author__ = 'maru'
import urllib2
import re
import mysql
class ParserPage():
def parserPage(self,url):
try:
html = urllib2.urlopen(url).read().decode("gb2312")
except UnicodeDecodeError,e:
print("UnicodeDecodeError:"+e)
return
except urllib2.URLError,e:
print("URLError"+e)
return
#视频名称
patName = re.compile(r'(.*)')
#视频地址
patURL = re.compile(r'href="(.*\.rmvb|.*\.mp4)"')
#视频分类
patList = re.compile(r'(.*?)')
try:
resName = re.findall(patName,html)[0]
resURL = re.findall(patURL,html)[0]
resList = re.findall(patList,html)
except IndexError,e:
return
return {
"name": resName,
"url": resURL,
"leve1": resList[0],
"leve2": resList[1]
}
if __name__ == "__main__":
index = 500
parser = ParserPage()
db = mysql.Mysql()
while index (六)一些需要留意的坑
- 在给MySQL插入中文数据的时候千万记得字符集要统一,否则一定会让你生不如死的,博主由于对数据库的使用也不是很熟练,所以在这里浪费了大量的时间。所以记得,我记得是有三个字符集需要统一,加油吧,骚年们!
- CCUT真的不愧是二流大学,获取数据的时候我都快哭了,要不就是莫名其妙资源消失不见,要么就是rmvb变成rm,所以在异常处理的时候我显得异常烦躁,毕竟二流大学啊!
(七)Finally
晒一晒最终的成果:
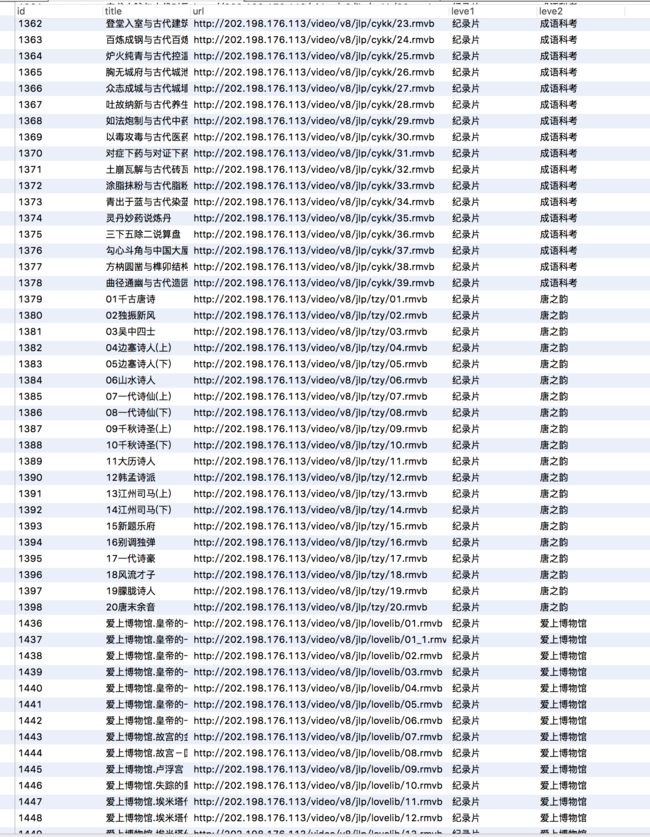
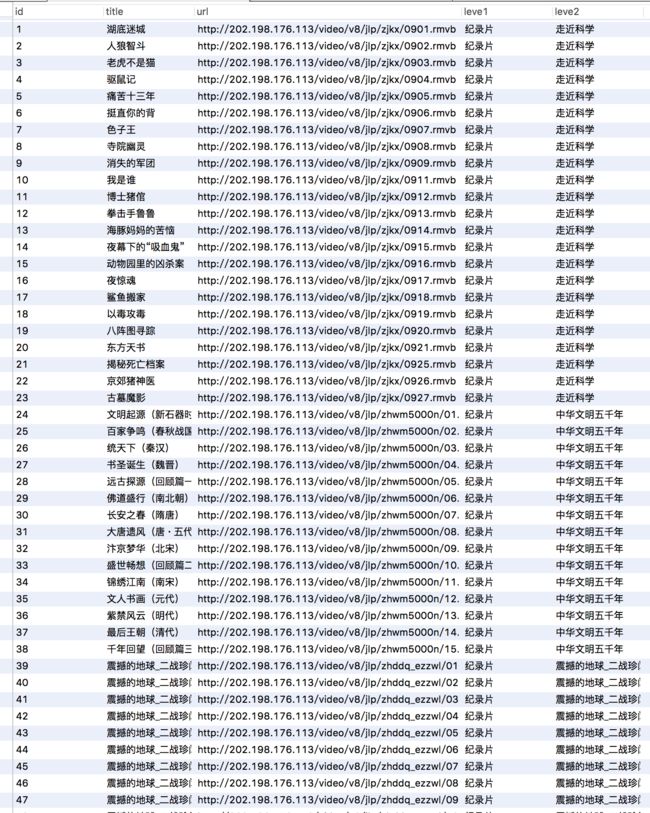
代码实现非常的简陋,但是第一个全栈项目还是比较有纪念价值的。附上github地址: