Apache Jena入门

其中, ModelFactory 类是一个Model 工厂,用于创建model 对象。我们可以使用 Model 的createResource 方法在model 中创建一个资源,并可以使用资源的 addProperty 方法添加属性。也可以直接使用createStatement方法在model中创建一个声明,并用model的add方法添加该声明。
Iterator有三种:NodeIterator,StmtIterator,ResIterator
练习:
RDF数据集:
1.
import com.hp.hpl.jena.rdf.model.Model;
import com.hp.hpl.jena.rdf.model.ModelFactory;
import com.hp.hpl.jena.rdf.model.Property;
import com.hp.hpl.jena.rdf.model.RDFNode;
import com.hp.hpl.jena.rdf.model.Resource;
import com.hp.hpl.jena.rdf.model.Statement;
import com.hp.hpl.jena.rdf.model.StmtIterator;
import com.hp.hpl.jena.vocabulary.VCARD;
public class StatementDemo {
public static void main(String[] args){
//声明主语的URI并建立模型
String personURI = "http://somewhere/JohnSmith";
Model model = ModelFactory.createDefaultModel();
//创立主谓宾关系,谓语是jena.vocabulary.VCARD自带的
Resource johnSmith = model.createResource(personURI);
johnSmith.addProperty(VCARD.FN,"John Smith");
johnSmith.addProperty(VCARD.N,model.createResource().addProperty(VCARD.Given,"John").addProperty(VCARD.Family,"Smith"));
//建立声明迭代器
StmtIterator iter = model.listStatements();
while(iter.hasNext()){
//取出每一个声明,每一个声明的主语、谓语、宾语
Statement stmt = iter.nextStatement();
Resource subject = stmt.getSubject();
Property predicate = stmt.getPredicate();
RDFNode object = stmt.getObject();
//用toString方法输出主谓宾
System.out.print(subject.toString()+" -->");
System.out.print(" "+predicate.toString()+" -->");
//判断宾语是资源还是文字(literal),如果是资源(的实例),则直接输出,如果是文字,加引号输出
if(object instanceof Resource){
System.out.print(" "+object.toString());
}else{
System.out.print(" "+"\"" + object.toString() + "\"");
}
System.out.println(" .");
}
}
}
Result:
http://somewhere/JohnSmith --> http://www.w3.org/2001/vcard-rdf/3.0#N --> 203f5bb:15884c765d0:-7fff .
http://somewhere/JohnSmith--> http://www.w3.org/2001/vcard-rdf/3.0#FN--> "John Smith" .
203f5bb:15884c765d0:-7fff --> http://www.w3.org/2001/vcard-rdf/3.0#Family --> "Smith" .
203f5bb:15884c765d0:-7fff --> http://www.w3.org/2001/vcard-rdf/3.0#Given --> "John" .
Model 类的listStatements 将返回一个 Statement 的Iterator。Statement 有的主语、谓语、客体分别用 getSubject、getPredicate、getObject 来返回。其类型分别是 Resource、Property和RDFNode。其中客体 object 类型可以是Resource 或者文本(literal)
2.
import com.hp.hpl.jena.rdf.model.Model;
import com.hp.hpl.jena.rdf.model.ModelFactory;
import com.hp.hpl.jena.rdf.model.Resource;
import com.hp.hpl.jena.vocabulary.VCARD;
public class RDFWriting {
public static void main(String[] args){
String personURI = "http://somewhere/JohnSmith";
Model model = ModelFactory.createDefaultModel();
Resource johnSmith = model.createResource(personURI);
johnSmith.addProperty(VCARD.FN,"John Smith");
johnSmith.addProperty(VCARD.N,model.createResource().addProperty(VCARD.Given,"John").addProperty(VCARD.Family,"Smith"));
//以不同格式输出RDF
System.out.println("RDF/XML:");
model.write(System.out,null);
System.out.println("\n"+"RDF/XML-ABBREV:");
model.write(System.out, "RDF/XML-ABBREV");
System.out.println("\n"+"N-TRIPLE:");
model.write(System.out,"N-TRIPLE");
System.out.println("\n"+"TURTLE:");
model.write(System.out,"TURTLE");
}
}
Result:
RDF/XML:
Smith
John
John Smith
RDF/XML-ABBREV:
Smith
John
John Smith
N-TRIPLE:
_:BX2D335bbeeX3A15884deb340X3AX2D7fff .
"John Smith" .
_:BX2D335bbeeX3A15884deb340X3AX2D7fff "Smith" .
_:BX2D335bbeeX3A15884deb340X3AX2D7fff "John" .
TURTLE:
"John Smith" ;
[
"Smith" ;
"John"
] .
用model.write(OutputStream out,String lang)方法以不同格式输出了RDF,供选的格式有RDF/XML, RDF/XML-ABBREV(RDF/XML的缩略形式), N-TRIPLE(三元组形式), TURTLE, N3(与TURTLE一样),第二个参数不写或写null(最新3.9版本jena中写null会有空指针异常,不识别这个关键字),代表用默认格式RDF/XML
3.
import java.io.InputStream;
import com.hp.hpl.jena.rdf.model.Model;
import com.hp.hpl.jena.rdf.model.ModelFactory;
import com.hp.hpl.jena.util.FileManager;
public class RDFReading {
public static void main(String[] args) {
String inputFileName = "resource.rdf";
Model model = ModelFactory.createDefaultModel();
InputStream in = FileManager.get().open(inputFileName);
if(in == null)
throw new IllegalArgumentException("File: "+inputFileName+" not found");
model.read(in,null);
model.write(System.out);
}
}
Result:
Becky Smith
Rebecca
Smith
Matt Jones
Sarah Jones
John
Smith
Sarah
Jones
John Smith
Matthew
Jones
用model.read(InputStream in,String base)方法读入一个rdf文件,并用默认的RDF/XML格式输出。第二个参数是让相对地址(URI)转换为绝对地址,当项目里都是绝对地址时,设置为null。这里找寻文件的类用的是jena里的FileManager
4.
import com.hp.hpl.jena.rdf.model.Model;
import com.hp.hpl.jena.rdf.model.ModelFactory;
import com.hp.hpl.jena.rdf.model.Property;
import com.hp.hpl.jena.rdf.model.Resource;
public class NSPrefix {
public static void main(String[] args) {
Model model = ModelFactory.createDefaultModel();
String nsA = "http://somewhere/else#";
String nsB = "http://nowhere/else#";
//create Resources and Properties
Resource root = model.createResource(nsA + "root");
Property P = model.createProperty( nsA + "P" );
Property Q = model.createProperty( nsB + "Q" );
Resource x = model.createResource( nsA + "x" );
Resource y = model.createResource( nsA + "y" );
Resource z = model.createResource( nsA + "z" );
model.add(root, P, x).add(root, P, y).add(y, Q, z);
System.out.println( "# -- no special prefixes defined" );
model.write( System.out );
System.out.println( "\n# -- nsA and nsB defined" );
model.setNsPrefix("nsA",nsA );
model.setNsPrefix("nsB",nsB );
model.write( System.out );
}
}
Result:
# -- no special prefixes defined
# -- nsA and nsB defined
用model.setNsPrefix设置名字空间的前缀,如果没有为RDF指定namespace前缀,jena会自动生成j.0和j.1的名字空间
5.
import com.hp.hpl.jena.rdf.model.Model;
import com.hp.hpl.jena.rdf.model.ModelFactory;
import com.hp.hpl.jena.rdf.model.Resource;
import com.hp.hpl.jena.rdf.model.StmtIterator;
import com.hp.hpl.jena.vocabulary.VCARD;
public class ModelAccess {
public static void main(String[] args) {
String personURI = "http://somewhere/JohnSmith";
String givenName = "John";
String familyName = "Smith";
String fullName = givenName + " " + familyName;
Model model = ModelFactory.createDefaultModel();
Resource johnSmith = model.createResource(personURI);
johnSmith.addProperty(VCARD.FN, fullName);
johnSmith.addProperty(VCARD.N,
model.createResource()
.addProperty(VCARD.Given, givenName)
.addProperty(VCARD.Family, familyName));
/*------假设以上一切已是一个RDF文件中的声明,且我们未知,现在要对一个Model操作(一个Model是一个Description)--------------------------------------*/
//从Model中获得资源,假设我们已经知道这个Description主语的URI
Resource vcard = model.getResource(personURI);
//如果知道该属性(VCARD.N)的值是属性,可以直接使用属性的getResource()方法
//Resource name = vcard.getProperty(VCART.N).getResource();
Resource name = (Resource) vcard.getProperty(VCARD.N).getObject();
//如果知道该属性的值是literal,可以直接使用属性的getString()方法
fullName = vcard.getProperty(VCARD.FN).getString();
//可以为这个主语增加属性
vcard.addProperty(VCARD.NICKNAME,"Smithy").addProperty(VCARD.NICKNAME, "Adman");
//用迭代器查看该属性的值
System.out.println("The nicknames of \""+fullName+"\" are:");
StmtIterator itor = vcard.listProperties(VCARD.NICKNAME);
while(itor.hasNext()){
System.out.println(" "+itor.nextStatement().getObject().toString());
}
System.out.println("----------------------------------------");
//查看加入新属性后的RDF/XML
model.write(System.out);
}
}
Result:
The nicknames of "John Smith" are:
Adman
Smithy
----------------------------------------
Smith
John
Adman
Smithy
John Smith
Model 的 getResource 方法:该方法根据参数返回一个资源对象。
Resource 的 getProperty 方法:根据参数返回一个属性对象。
Property 的 getObject 方法:返回属性值。使用时根据实际类型是 Resource 还是 literal 进行强制转换。
Property 的 getResource 方法:返回属性值的资源。如果属性值不是Resource,则报错。
Property 的 getString 方法:返回属性值的文本内容。如果属性值不是文本,则报错。
Resource 的 listProperties 方法:列出所找到符合条件的属性。
6.
使用model.listSubjectsWithProperyty()方法查询
import java.io.InputStream;
import com.hp.hpl.jena.rdf.model.Model;
import com.hp.hpl.jena.rdf.model.ModelFactory;
import com.hp.hpl.jena.rdf.model.ResIterator;
import com.hp.hpl.jena.util.FileManager;
import com.hp.hpl.jena.vocabulary.VCARD;
public class RDFQuery {
public static String fileName = "resource.rdf";
public static void main(String[] args) {
Model model = ModelFactory.createDefaultModel();
InputStream in = FileManager.get().open(fileName);
if(in == null)
throw new IllegalArgumentException("file: "+fileName+" not found");
model.read(in,null);
ResIterator itor = model.listSubjectsWithProperty(VCARD.FN);
if(itor.hasNext())
{
System.out.println("The database contains vcard for: ");
while(itor.hasNext())
System.out.println(" "+itor.nextResource().getProperty(VCARD.FN).getString());
}
else
System.out.println("No vcards were found in the database");
}
}
Result:
The database contains vcard for:
Becky Smith
Matt Jones
Sarah Jones
John Smith
也可以使用Seletor查询
StmtIterator itor = model.listStatements(new SimpleSelector(null,VCARD.FN,(RDFNode)null));
if(itor.hasNext())
{
System.out.println("The database contains vcard for: ");
while(itor.hasNext())
System.out.println(" "+itor.nextStatement().getString());
}
else
System.out.println("No vcards were found in the database");
结果同上
7.
import com.hp.hpl.jena.rdf.model.Model;
import com.hp.hpl.jena.rdf.model.ModelFactory;
import com.hp.hpl.jena.rdf.model.RDFNode;
import com.hp.hpl.jena.rdf.model.Resource;
import com.hp.hpl.jena.vocabulary.VCARD;
public class ControlRDF {
public static void main(String[] args) {
String personURI = "http://somewhere/JohnSmith";
String givenName = "John";
String familyName = "Smith";
String fullName = givenName + " " + familyName;
Model model = ModelFactory.createDefaultModel();
Resource johnSmith = model.createResource(personURI);
johnSmith.addProperty(VCARD.FN, fullName);
johnSmith.addProperty(VCARD.N,
model.createResource()
.addProperty(VCARD.Given, givenName)
.addProperty(VCARD.Family, familyName));
System.out.println("原始内容:");
model.write(System.out);
//删除Statement
model.removeAll(null, VCARD.N, (RDFNode)null);
//也可以用model.remove(StmtIterator itor)方法
// model.remove(model.listStatements(null, VCARD.N,(RDFNode)null )); 下面两句也可以相对替换
model.removeAll(null,VCARD.Given,(RDFNode)null);
model.removeAll(null,VCARD.Family,(RDFNode)null);
System.out.println("\n删除后的内容:");
model.write(System.out);
//增加Statement
//用model.add(Resource arg1, Property arg2, RDFNode arg3)方法
model.add(johnSmith,VCARD.N,model.createResource().addProperty(VCARD.Given, givenName).addProperty(VCARD.Family, familyName));
System.out.println("\n重新增加后的内容:");
model.write(System.out);
}
}
Result:
原始内容:
John Smith
Smith
John
删除后的内容:
John Smith
重新增加后的内容:
Smith
John
John Smith
除了直接使用 Model 的方法外,对Model 中的Resource(资源)或Property(属性,实际上也继承自Resource)进行增删操作也可以达到更改 Model 的目的。
Model 的合并主要分为 交、并、补三种操作。
如下图所示:
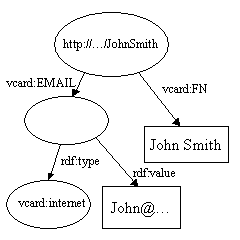
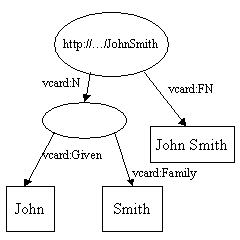
这两个图分别代表一个Model。它们的名字相同,且具有相同的属性 vcard:FN ,值为John Smith。因此,我们对这两个Model 进行“并”(union)操作。所得到的Model 的图形表示如下:

其中重复的 vcard:FN 值只出现一个。
这三种操作的方法分别为:
- Model.intersection(Model model): 交操作。创建一个新Model ,内容是前两个Model的共有部分。(交集)
- Model.union(Model model): 并操作。创建一个新Model,内容是前两个Model内容的叠加,重复的去掉。(并集)
- Model1.difference(Model model2): 补操作。创建一个新Model,内容是Model1去掉与Model2共有的,和Model2独有的部分。(差集)
8.
import com.hp.hpl.jena.rdf.model.Model;
import com.hp.hpl.jena.rdf.model.ModelFactory;
import com.hp.hpl.jena.rdf.model.Resource;
import com.hp.hpl.jena.vocabulary.RDF;
import com.hp.hpl.jena.vocabulary.VCARD;
public class ModelOperation {
public static void main(String[] args) {
String personURI = "http://somewhere/JohnSmith";
String givenName = "John";
String familyName = "Smith";
String fullName = givenName + " " + familyName;
Model model1 = ModelFactory.createDefaultModel();
Resource johnSmith1 = model1.createResource(personURI);
johnSmith1.addProperty(VCARD.FN,fullName);
johnSmith1.addProperty(VCARD.N,model1.createResource()
.addProperty(VCARD.Given, givenName)
.addProperty(VCARD.Family, familyName));
System.out.println("Model1的内容是:");
model1.write(System.out);
Model model2 = ModelFactory.createDefaultModel();
Resource johnSmith2 = model2.createResource(personURI);
johnSmith2.addProperty(VCARD.FN, fullName);
johnSmith2.addProperty(VCARD.EMAIL, model2.createResource()
.addProperty(RDF.type, "vcard.internet")
.addProperty(RDF.value, "John@qq.com"));
System.out.println("\nModel2的内容是:");
model2.write(System.out);
//Union
Model model3 = model1.union(model2);
System.out.println("\nUnion后的新Model");
model3.write(System.out);
//Intersection
Model model4 = model1.intersection(model2);
System.out.println("\nIntersection后的新Model");
model4.write(System.out);
//Difference
Model model5 = model1.difference(model2);
System.out.println("\n从model1中Difference掉model2后的新Model");
model5.write(System.out);
//Difference
Model model6 = model2.difference(model1);
System.out.println("\n从model2中Difference掉model1后的新Model");
model6.write(System.out);
}
}
Result:
Model1的内容是:
John Smith
Smith
John
Model2的内容是:
John@qq.com
vcard.internet
John Smith
Union后的新Model
vcard.internet
John@qq.com
John Smith
John
Smith
Intersection后的新Model
John Smith
从model1中Difference掉model2后的新Model
John
Smith
从model2中Difference掉model1后的新Model
vcard.internet
John@qq.com
使用Jena进行SPARQL查询
Requirement: 查询谓语是vcard.FN,宾语是John Smith的所有主语
import java.io.InputStream;
import com.hp.hpl.jena.query.Query;
import com.hp.hpl.jena.query.QueryExecution;
import com.hp.hpl.jena.query.QueryExecutionFactory;
import com.hp.hpl.jena.query.QueryFactory;
import com.hp.hpl.jena.query.ResultSet;
import com.hp.hpl.jena.query.ResultSetFormatter;
import com.hp.hpl.jena.rdf.model.Model;
import com.hp.hpl.jena.rdf.model.ModelFactory;
import com.hp.hpl.jena.util.FileManager;
public class RDFQuery {
public static void main(String[] args) {
String inputFileName = "resource.rdf";
Model model = ModelFactory.createDefaultModel();
InputStream in = FileManager.get().open(inputFileName);
if(in == null)
throw new IllegalArgumentException("File: "+inputFileName+" not found");
model.read(in,null);
//创建一个查询语句
String queryString = "SELECT ?subject"+" WHERE "+"{ ?subject \"John Smith\"}" ;
//创建一个查询
Query query = QueryFactory.create(queryString);
//执行查询,获得结果
QueryExecution qe = QueryExecutionFactory.create(query, model);
ResultSet results = qe.execSelect();
//向控制台输出结果
//用这句一样ResultSetFormatter.out(results);
ResultSetFormatter.out(System.out, results, query);
//释放资源
qe.close();
}
}
首先程序要先读入该本体(这里是RDF文件)
使用QueryFactory.create创建一个Query,然后用使用QueryExecutionFactory.create将Query和Model都传入执行工厂进行执行,用ResultSet收集结果,最后用ResultSetFormatter.out向控制台输出结果