【我的架构师之路】- 说一说go中的sync包
【转载请标明出处】https://blog.csdn.net/qq_25870633/article/details/83448234
好久没写博客了!这段时间一直忙于赶公链项目。今天就不打算将区块链的文章了,因为。。。我承诺过每个月4篇文章的,然鹅,这个10月过去了,我TM还没写一篇文章。如果写链相关的篇幅太长,太耗时(下个月继续以太坊源码分析吧),算了今天就写一写 go的一些源码分析吧。
虽然在golang中主张,“不用内存共享来实现通信,而用通信来实现内存共享”。go推荐用channel的方式来在多个goroutine中传递消息以保证并发安全,用句白话说就是可以用channel来实现锁的功能。比如:
type Mutex struct {
ch chan struct{}
}
func NewMutex() *Mutex {
return &Mutex{make(chan struct{},1)}
}
func (m *Mutex) Lock() {
m.ch <- struct{}{}
}
func (m *Mutex) Unlock() {
<-m.ch
}
func (m *Mutex) TryLock() bool {
select {
case m.ch <- struct{}{}:
return true
default:
}
return false
}
func (m *Mutex) TryLockTimeOut(timeout time.Duration) bool {
timer := time.NewTimer(timeout)
select {
case m.ch <- struct{}{}:
timer.Stop()
return true
case <-time.After(timeout):
}
return false
}
func (m *Mutex) IsLocked() bool {
return len(m.ch) >0
}好了,虽然我们知道go提倡用channel来控制并发锁,但是作为可选方法,go依然提供了很多传统的并发控制api,这些东西基本都在sync包中。下面我们来说说sync包。
sync包提供了基本的同步基元,如互斥锁。除了Once和WaitGroup类型,大部分都是适用于低水平程序线程,高水平的同步使用channel通信更好一些。
本包的类型的值不应被拷贝【即:不应该用值类型去做拷贝,而应该用指针】,那么sync包都有哪一些东西呢?请往下看:
type Locker
type Once
func (o *Once) Do(f func())
type Mutex
func (m *Mutex) Lock()
func (m *Mutex) Unlock()
type RWMutex
func (rw *RWMutex) Lock()
func (rw *RWMutex) Unlock()
func (rw *RWMutex) RLock()
func (rw *RWMutex) RUnlock()
func (rw *RWMutex) RLocker() Locker
type Cond
func NewCond(l Locker) *Cond
func (c *Cond) Broadcast()
func (c *Cond) Signal()
func (c *Cond) Wait()
type WaitGroup
func (wg *WaitGroup) Add(delta int)
func (wg *WaitGroup) Done()
func (wg *WaitGroup) Wait()
type Pool
func (p *Pool) Get() interface{}
func (p *Pool) Put(x interface{})【Mutex】:
我们可以看出其实不多,下面我们都会一一分析源码。说到同步大家第一印象肯定是锁,那么我们下面就先从Mutex 互斥锁说起。互斥锁的代码定义在 src/sync/mutex.go 中。如下:
func throw(string) // 被定义在 runtime 包中,src/runtime/panic.go 的 sync_throw 方法
// mutex 是一个互斥锁
// 零值是没有被上锁的互斥锁。
//
// 首次使用后,不得复制互斥锁。(意思是不能复制值,可以做成引用复制)
type Mutex struct {
// 将一个32位整数拆分为
// 当前阻塞的goroutine数目(29位)|饥饿状态(1位)|唤醒状态(1位)|锁状态(1位) 的形式,来简化字段设计
state int32
// 信号量
sema uint32
}
// 锁接口
type Locker interface {
Lock()
Unlock()
}
const (
// 定义锁的状态
mutexLocked = 1 << iota // 1 表示是否被锁定 0001 含义:用最后一位表示当前对象锁的状态,0-未锁住 1-已锁住
mutexWoken // 2 表示是否被唤醒 0010 含义:用倒数第二位表示当前对象是否被唤醒 0- 未唤醒 1-唤醒 【注意: 未被唤醒并不是指 休眠,而是指为了让所能被设置 被唤醒的一个初始值】
mutexStarving // 4 表示是否饥饿 0100 含义:用倒数第三位表示当前对象是否为饥饿模式,0为正常模式,1为饥饿模式。
mutexWaiterShift = iota // 3 表示 从倒数第四位往前的bit位表示在排队等待的goroutine数目(共对于 32位中占用 29 位)
//
/** 互斥量可分为两种操作模式:正常和饥饿。
【正常模式】,等待的goroutines按照FIFO(先进先出)顺序排队,但是goroutine被唤醒之后并不能立即得到mutex锁,它需要与新到达的goroutine争夺mutex锁。
因为新到达的goroutine已经在CPU上运行了,所以被唤醒的goroutine很大概率是争夺mutex锁是失败的。出现这样的情况时候,被唤醒的goroutine需要排队在队列的前面。
如果被唤醒的goroutine有超过1ms没有获取到mutex锁,那么它就会变为饥饿模式。
在饥饿模式中,mutex锁直接从解锁的goroutine交给队列前面的goroutine。新达到的goroutine也不会去争夺mutex锁(即使没有锁,也不能去自旋),而是到等待队列尾部排队。
【饥饿模式】,锁的所有权将从unlock的gorutine直接交给交给等待队列中的第一个。新来的goroutine将不会尝试去获得锁,即使锁看起来是unlock状态, 也不会去尝试自旋操作,而是放在等待队列的尾部。如果有一个等待的goroutine获取到mutex锁了,如果它满足下条件中的任意一个,mutex将会切换回去正常模式:
1. 是等待队列中的最后一个goroutine
2. 它的等待时间不超过1ms。
正常模式:有更好的性能,因为goroutine可以连续多次获得mutex锁;
饥饿模式:能阻止尾部延迟的现象,对于预防队列尾部goroutine一致无法获取mutex锁的问题。
*/
starvationThresholdNs = 1e6 // 1ms
)
// 如果锁已经在使用中,则调用goroutine 直到互斥锁可用为止。
/**
在此之前我们必须先说下 四个重要的方法;
【runtime_canSpin】,【runtime_doSpin】,【runtime_SemacquireMutex】,【runtime_Semrelease】
【runtime_canSpin】: 在 src/runtime/proc.go 中被实现 sync_runtime_canSpin; 表示 比较保守的自旋,
golang中自旋锁并不会一直自旋下去,在runtime包中runtime_canSpin方法做了一些限制,
传递过来的iter大等于4或者cpu核数小等于1,最大逻辑处理器大于1,至少有个本地的P队列,
并且本地的P队列可运行G队列为空。
【runtime_doSpin】: 在src/runtime/proc.go 中被实现 sync_runtime_doSpin;表示 会调用procyield函数,
该函数也是汇编语言实现。函数内部循环调用PAUSE指令。PAUSE指令什么都不做,
但是会消耗CPU时间,在执行PAUSE指令时,CPU不会对它做不必要的优化。
【runtime_SemacquireMutex】:在 src/runtime/sema.go 中被实现 sync_runtime_SemacquireMutex;表示通过信号量 阻塞当前协程
【runtime_Semrelease】: 在src/runtime/sema.go 中被实现 sync_runtime_Semrelease
*/
func (m *Mutex) Lock() {
// 如果m.state为 0,说明当前的对象还没有被锁住,进行原子性赋值操作设置为mutexLocked状态,CompareAnSwapInt32返回true
// 否则说明对象已被其他goroutine锁住,不会进行原子赋值操作设置,CopareAndSwapInt32返回false
/**
如果mutext的state没有被锁,也没有等待/唤醒的goroutine, 锁处于正常状态,那么获得锁,返回.
比如锁第一次被goroutine请求时,就是这种状态。或者锁处于空闲的时候,也是这种状态
*/
if atomic.CompareAndSwapInt32(&m.state, 0, mutexLocked) {
if race.Enabled {
race.Acquire(unsafe.Pointer(m))
}
return
}
/** 在 锁定没有成功的时候,才会往下面走 */
// 首先判断是否已经加锁并处于 正常模式,
// 将原先锁的state & (1 和 4 | 的结果,目的就是为了检验 state 是处于 1 还是 4 状态, 还是两者都是.
// 如果与1相等,则说明此时处于 正常模式并且已经加锁,而后判断当前协程是否可以自旋。
// 如果可以自旋,则通过右移三位判断是否还有协程正在等待这个锁,
// 如果有,并通过 低2位 判断是否该所处于被唤醒状态,
// 如果并没有,则将其状态量设为被唤醒的状态,之后进行自旋,直到该协程自旋数量达到上限,
// 或者当前锁被解锁,
// 或者当前锁已经处于 饥饿模式
// 标记本goroutine的等待时间
// 开始等待时间戳
var waitStartTime int64
// 本goroutine是否已经处于饥饿状态
// 饥饿模式标识 true: 饥饿 false: 未饥饿
starving := false
// 本goroutine是否已唤醒
// 被唤醒标识 true: 被唤醒 flase: 未被唤醒
awoke := false
// 自旋次数
iter := 0
// 保存当前对象锁状态,做对比用
old := m.state
// for 来实现 CAS(Compare and Swap) 非阻塞同步算法 (对比交换)
for {
// 不要在饥饿模式下自旋,将锁的控制权交给阻塞任务,否则无论如何 当前goroutine都无法获得互斥锁。
// 相当于xxxx...x0xx & 0101 = 01,当前对象锁被使用
// old & (是否锁定|是否饥饿) == 是否锁定
// runtime_canSpin() 表示 是否可以自旋。runtime_canSpin返回true,可以自旋。即: 判断当前goroutine是否可以进入自旋锁
/**
第一个条件:是state已被锁,但是不是饥饿状态。如果时饥饿状态,自旋时没有用的,锁的拥有权直接交给了等待队列的第一个。
第二个条件:是还可以自旋,多核、压力不大并且在一定次数内可以自旋, 具体的条件可以参考`sync_runtime_canSpin`的实现。
如果满足这两个条件,不断自旋来等待锁被释放、或者进入饥饿状态、或者不能再自旋。
*/
if old&(mutexLocked|mutexStarving) == mutexLocked && runtime_canSpin(iter) {
// 主动旋转是有意义的。试着设置 mutexWoken (锁唤醒)标志,告知解锁,不唤醒其他阻塞的goroutines。
// old&mutexWoken == 0 再次确定是否被唤醒: xxxx...xx0x & 0010 = 0
// old>>mutexWaiterShift != 0 查看是否有goroution在排队
// tomic.CompareAndSwapInt32(&m.state, old, old|mutexWoken) 将对象锁在老状态上追加唤醒状态:xxxx...xx0x | 0010 = xxxx...xx1x
// 如果当前标识位 awoke为 未被唤醒 && (old 也为 未被唤醒) && 有正在等待的 goroutine && 则修改 old 为 被唤醒
// 且修改标识位 awoke 为 true 被唤醒
/**
自旋的过程中如果发现state还没有设置woken标识,则设置它的woken标识, 并标记自己为被唤醒。
*/
if !awoke && old&mutexWoken == 0 && old>>mutexWaiterShift != 0 && atomic.CompareAndSwapInt32(&m.state, old, old|mutexWoken) {
// 更改标识位为 唤醒true
awoke = true
}
// 否则: 进入自旋
// 进入自旋锁后当前goroutine并不挂起,仍然在占用cpu资源,所以重试一定次数后,不会再进入自旋锁逻辑
runtime_doSpin()
// 累加自旋次数
iter++
// 更新中转变量
// 保存mutex对象即将被设置成的状态
old = m.state
continue
}
// 以下代码是不使用**自旋**的情况
/**
到了这一步, state的状态可能是:
1. 锁还没有被释放,锁处于正常状态
2. 锁还没有被释放, 锁处于饥饿状态
3. 锁已经被释放, 锁处于正常状态
4. 锁已经被释放, 锁处于饥饿状态
并且本gorutine的 awoke可能是true, 也可能是false (其它goutine已经设置了state的woken标识)
new 复制 state的当前状态, 用来设置新的状态
old 是锁当前的状态
*/
new := old
/** 下面的几个 if 分别是并列语句,来判断如给 设置 state 的new 状态 */
/**
如果old state状态不是饥饿状态, new state 设置锁, 尝试通过CAS获取锁,
如果old state状态是饥饿状态, 则不设置new state的锁,因为饥饿状态下锁直接转给等待队列的第一个.
*/
// 不要试图获得饥饿goroutine的互斥锁,新来的goroutines必须排队。
// 对象锁饥饿位被改变 为 1 ,说明处于饥饿模式
// xxxx...x0xx & 0100 = 0xxxx...x0xx
/**【一】如果是正常状态 (如果是正常,则可以竞争到锁) */
if old&mutexStarving == 0 {
// xxxx...x0xx | 0001 = xxxx...x0x1,将标识对象锁被锁住
new |= mutexLocked
}
/** 【二】处于饥饿且锁被占用 状态下 */
// xxxx...x1x1 & (0001 | 0100) => xxxx...x1x1 & 0101 != 0;当前mutex处于饥饿模式并且锁已被占用,新加入进来的goroutine放到队列后面,所以 等待者数目 +1
if old&(mutexLocked|mutexStarving) != 0 {
// 更新阻塞goroutine的数量,表示mutex的等待goroutine数目加1
// 首先,如果此时还是由于别的协程的占用 无法获得锁 或者 处于 饥饿模式,都在其state加8表示有新的协程正在处于等待状态
new += 1 << mutexWaiterShift
}
/**
如果之前由于自旋而将该锁唤醒,那么此时将其低二位的状态量重置为0 (即 未被唤醒)。
之后判断starving是否为true,如果为true说明在上一次的循环中,
锁需要被定义为 饥饿模式,那么在这里就将相应的状态量低3位设置为1表示进入饥饿模式
*/
/***
【三】
如果当前goroutine已经处于饥饿状态 (表示当前 goroutine 的饥饿标识位 starving), 并且old state的已被加锁,
将new state的状态标记为饥饿状态, 将锁转变为饥饿状态.
*/
// 当前的goroutine将互斥锁转换为饥饿模式。但是,如果互斥锁当前没有解锁,就不要打开开关,设置mutex状态为饥饿模式。Unlock预期有饥饿的goroutine
// old&mutexLocked != 0 xxxx...xxx1 & 0001 != 0;锁已经被占用
// 如果 饥饿且已被锁定
if starving && old&mutexLocked != 0 {
// 【追加】饥饿状态
new |= mutexStarving
}
/**
【四】
如果本goroutine已经设置为唤醒状态, 需要清除new state的唤醒标记, 因为本goroutine要么获得了锁,要么进入休眠,
总之state的新状态不再是woken状态.
*/
// 如果 goroutine已经被唤醒,因此需要在两种情况下重设标志
if awoke {
// xxxx...xx0x & 0010 == 0,如果唤醒标志为与awoke的值不相协调就panic
// 即 state 为 未被唤醒
if new&mutexWoken == 0 {
panic("sync: inconsistent mutex state")
}
// new & (^mutexWoken) => xxxx...xxxx & (^0010) => xxxx...xxxx & 1101 = xxxx...xx0x
// 设置唤醒状态位0,被 未唤醒【只是为了, 下次被可被设置为i被唤醒的 初识化标识,而不是指休眠】
new &^= mutexWoken
}
/**
之后尝试通过cas将 new 的state状态量赋值给state,
如果失败,则重新获得其 state在下一步循环重新重复上述的操作。
如果成功,首先判断已经阻塞时间 (通过 标记本goroutine的等待时间 waitStartTime ),如果为零,则从现在开始记录
*/
// 将新的状态赋值给 state
// 注意new的锁标记不一定是true, 也可能只是标记一下锁的state是饥饿状态
if atomic.CompareAndSwapInt32(&m.state, old, new) {
/**
如果old state的状态是未被锁状态,并且锁不处于饥饿状态,
那么当前goroutine已经获取了锁的拥有权,返回
*/
// xxxx...x0x0 & 0101 = 0,表示可以获取对象锁 (即 还是判断之前的状态,锁不是饥饿 也不是被被锁定, 所已经可用了)
if old&(mutexLocked|mutexStarving) == 0 {
break // 结束cas
}
// 以下的操作都是为了判断是否从【饥饿模式】中恢复为【正常模式】
// 判断处于FIFO还是LIFO模式
// 如果等待时间不为0 那么就是 LIFO
// 在正常模式下,等待的goroutines按照FIFO(先进先出)顺序排队
/**
设置/计算本goroutine的等待时间
*/
queueLifo := waitStartTime != 0
if waitStartTime == 0 {
// 更新等待时间
waitStartTime = runtime_nanotime()
}
// 通过runtime_SemacquireMutex()通过信号量将当前协程阻塞
// 函数 runtime_SemacquireMutex 定义在 sema.go
/**
既然未能获取到锁, 那么就使用 [sleep原语] 阻塞本goroutine
如果是新来的goroutine,queueLifo=false, 加入到等待队列的尾部,耐心等待
如果是唤醒的goroutine, queueLifo=true, 加入到等待队列的头部
*/
runtime_SemacquireMutex(&m.sema, queueLifo)
// 当之前调用 runtime_SemacquireMutex 方法将当前新进来争夺锁的协程挂起后,如果协程被唤醒,那么就会继续下面的流程
// 如果当前 饥饿状态标识为 饥饿 || 当前时间 - 开始等待时间 > 1 ms 则 都切换为饥饿状态标识
/**
使用 [sleep原语] 之后,此goroutine被唤醒
计算当前goroutine是否已经处于饥饿状态.
*/
starving = starving || runtime_nanotime()-waitStartTime > starvationThresholdNs
// 刷新下 中转变量
/** 得到当前的锁状态 */
old = m.state
/**
如果当前的state已经是饥饿状态
那么锁应该处于Unlock状态,那么应该是锁被直接交给了本goroutine
*/
// xxxx...x1xx & 0100 != 0 处于 饥饿状态
if old&mutexStarving != 0 {
/**
如果当前的state已被锁,或者已标记为唤醒, 或者等待的队列中为空,
那么state是一个非法状态
*/
// xxxx...xx11 & 0011 != 0 又可能是被锁定,又可能是被唤醒 或者 没有等待的goroutine
if old&(mutexLocked|mutexWoken) != 0 || old>>mutexWaiterShift == 0 {
panic("sync: inconsistent mutex state")
}
// delta 表示当前状态下的等待数
// 否则下一次的循环中将该锁这是为 饥饿模式。
// 如果已经是这个模式,那么就会将 状态量的等待数 减1
/**
当前goroutine用来设置锁,并将等待的goroutine数减1.
lock状态 -一个gorotine数,表示 状态 delta == (lock + (减去一个等待goroutine数))
*/
delta := int32(mutexLocked - 1<>mutexWaiterShift == 1 {
// 退出饥饿模式。
// 在这里做到并考虑等待时间至关重要。
// 饥饿模式是如此低效,一旦将互斥锁切换到饥饿模式,两个goroutine就可以无限锁定。
delta -= mutexStarving
}
// 设置新state, 因为已经获得了锁,退出、返回
atomic.AddInt32(&m.state, delta)
break
}
// 修改为 本goroutine 是否被唤醒标识位
/**
如果当前的锁是正常模式,本goroutine被唤醒,自旋次数清零,从for循环开始处重新开始
*/
awoke = true
// 自旋计数 初始化
iter = 0
} else {
// 如果CAS不成功,重新获取锁的state, 从for循环开始处重新开始 继续上述动作
old = m.state
}
}
if race.Enabled {
race.Acquire(unsafe.Pointer(m))
}
}
// 解锁一个未被锁定的互斥锁时,是会报错
// 锁定的互斥锁与特定的goroutine无关。
// 允许一个goroutine锁定Mutex然后
// 安排另一个goroutine解锁它。
func (m *Mutex) Unlock() {
if race.Enabled {
_ = m.state
race.Release(unsafe.Pointer(m))
}
/** 如果state不是处于锁的状态, 那么就是Unlock根本没有加锁的mutex, panic */
// state -1 标识解锁 (移除锁定标记)
new := atomic.AddInt32(&m.state, -mutexLocked)
/**
释放了锁,还得需要通知其它等待者
被通知的 goroutine 会去做下面的事情
锁如果处于饥饿状态,直接交给等待队列的第一个, 唤醒它,让它去获取锁
锁如果处于正常状态,则需要唤醒对头的 goroutine 让它和新来的goroutine去竞争锁,当然极大几率为失败,
这时候 被唤醒的goroutine需要排队在队列的前面 (然后自旋)。如果被唤醒的goroutine有超过1ms没有获取到mutex锁,那么它就会变为饥饿模式
*/
// 再次校验下 标识,new state如果是正常状态, 验证锁状态是否符合
if (new+mutexLocked)&mutexLocked == 0 {
panic("sync: unlock of unlocked mutex")
}
// xxxx...x0xx & 0100 = 0 ;判断是否处于正常模式
if new&mutexStarving == 0 {
// 记录缓存值
old := new
for {
// 如果没有等待的goroutine或goroutine不处于空闲,则无需唤醒任何人
// 在饥饿模式下,锁的所有权直接从解锁goroutine交给下一个 正在等待的goroutine (等待队列中的第一个)。
// 注意: old&(mutexLocked|mutexWoken|mutexStarving) 中,因为在最上面已经 -mutexLocked 并且进入了 if new&mutexStarving == 0
// 说明目前 只有在还有goroutine 或者 被唤醒的情况下才会 old&(mutexLocked|mutexWoken|mutexStarving) != 0
// 即:当休眠队列内的等待计数为 0 或者 是正常但是 处于被唤醒或者被锁定状态,退出
// old&(mutexLocked|mutexWoken|mutexStarving) != 0 xxxx...x0xx & (0001 | 0010 | 0100) => xxxx...x0xx & 0111 != 0
/**
如果没有等待的goroutine, 或者锁不处于空闲的状态,直接返回.
*/
if old>>mutexWaiterShift == 0 || old&(mutexLocked|mutexWoken|mutexStarving) != 0 {
return
}
// 减少等待goroutine个数,并添加 唤醒标识
new = (old - 1< Mutex锁分为正常模式和饥饿模式。一开始默认处于正常模式。在正常模式中,每个新加入竞争锁行列的协程都会直接参与到锁的竞争当中来,而处于饥饿模式时,所有所有新进入的协程都会直接被放入等待队列中挂起,直到其所在队列之前的协程全部执行完毕。
在正常模式中协程的挂起等待时间如果大于某个值,就会进入饥饿模式。
type Mutex struct {
state int32
sema uint32
}
其中,state用来保存mutex的状态量,低一位表示是否上锁,低二位表示当前锁对象是否被唤醒,低三位表示该锁是否处于饥饿状态,而其余位表示当前正被该锁阻塞的协程数。而sema则是作为信号量来作为阻塞的依据。
上述 32位的整数映射到state 字段上的情景为:
state: |32|31|...| |3|2|1|
\__________/ | | |
| | | |
| | | mutex的占用状态(1被占用,0可用)
| | |
| | mutex的当前goroutine是否被唤醒
| |
| 饥饿位,0正常,1饥饿
|
等待唤醒以尝试锁定的goroutine的计数,0表示没有等待者
上述很的运算都是位运算,原因是:锁在同一时刻可能具备多个状态,还有一个原因就是state字段 只有 低位的三位是用来控制状态的,而其他的位都是用来做计数的,所以不能直接赋值操作,而是用了位运算赋值。
下面我们来详细的分析分析代码:首先在代码里有自定义 throw函数:

那么这个函数时在哪里被实现的呢?答案是在 runtime 包中,src/runtime/panic.go 的 sync_throw 方法:

可以看出在之前的文章中我说过的使用了 go:linkname 本方法 目标方法 的注释技巧。
接下来我们看 Mutex 结构体的定义:

可以看到就是简单的定义了两个成员,一个 int32 的state,一个 uint32的 sema 。其中state使用了29个高位作为记录当前阻塞的goroutine数目,剩下低3位分别作为 是否饥饿 0100、是否被唤醒 0010、是否被锁定 0001 。

其中,互斥量可分为两种操作模式: 正常 和 饥饿。
【正常模式】,等待的goroutines按照 FIFO(先进先出)顺序排队,但是goroutine被唤醒之后并不能立即得到mutex锁,它需要与新到达的goroutine争夺mutex锁。 因为新到达的goroutine已经在CPU上运行了,所以被唤醒的goroutine很大概率是争夺mutex锁是失败的。出现这样的情况时候,被唤醒的goroutine需要排队在队列的前面。 如果被唤醒的goroutine有超过1ms没有获取到mutex锁,那么它就会变为 饥饿模式。 在饥饿模式中,mutex锁直接从解锁的goroutine交给队列前面的goroutine。新达到的goroutine也不会去争夺mutex锁(即使没有锁,也不能去自旋),而是到等待队列尾部排队。
【饥饿模式】,有一个goroutine获取到mutex锁了,如果它满足下条件中的任意一个,mutex将会切换回去正常模式: 1. 是等待队列中的最后一个goroutine 。2. 它的等待时间不超过1ms。 正常模式有更好的性能,因为goroutine可以连续多次获得mutex锁; 饥饿模式需要预防队列尾部goroutine一直无法获取mutex锁的问题。
尝试获取mutex的goroutine也有状态,有可能它是新来的goroutine,也有可能是被唤醒的goroutine, 可能是处于正常状态的goroutine, 也有可能是处于饥饿状态的goroutine
并且实现了 Locker 接口的 Lock () 和 Unlock () 函数。
在说这两个函数之前,我们先来看看几个重要的函数(当然,这几个函数,我这里不打算细讲):
四个重要的方法; 【runtime_canSpin】,【runtime_doSpin】,【runtime_SemacquireMutex】,【runtime_Semrelease】
【runtime_canSpin】: 在 src/runtime/proc.go 中被实现 sync_runtime_canSpin; 表示是否可以保守的自旋,golang中自旋锁并不会一直自旋下去,在runtime包中runtime_canSpin方法做了一些限制, 传递过来的iter大等于4或者cpu核数小等于1,最大逻辑处理器大于1,至少有个本地的P队列,并且本地的P队列可运行G队列为空。
【runtime_doSpin】: 在 src/runtime/proc.go 中被实现 sync_runtime_doSpin;表示 会调用procyield函数, 该函数也是汇编语言实现。函数内部循环调用PAUSE指令。PAUSE指令什么都不做, 但是会消耗CPU时间,在执行PAUSE指令时,CPU不会对它做不必要的优化。
【runtime_SemacquireMutex】:在 src/runtime/sema.go 中被实现 sync_runtime_SemacquireMutex;表示通过信号量 阻塞当前协程 。
【runtime_Semrelease】: 在src/runtime/sema.go 中被实现 sync_runtime_Semrelease。表示通过信号量解除当前协程阻塞。
下面进入主题看看Lock ( ) 函数的逻辑:
首先在函数一进来就去基于 cas 去做上锁动作。

如果操作成功,则获得锁,且返回。如果不成功,则继续往下面走。
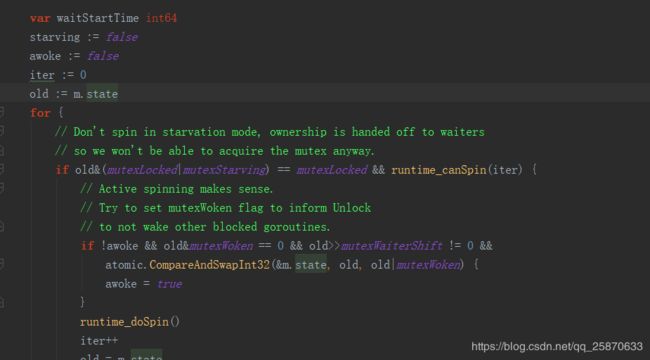
可以看到,先对几个中转变量做好初始化赋值操作,就进入一个死循环。而死循环里面做的事也是十分的简单:
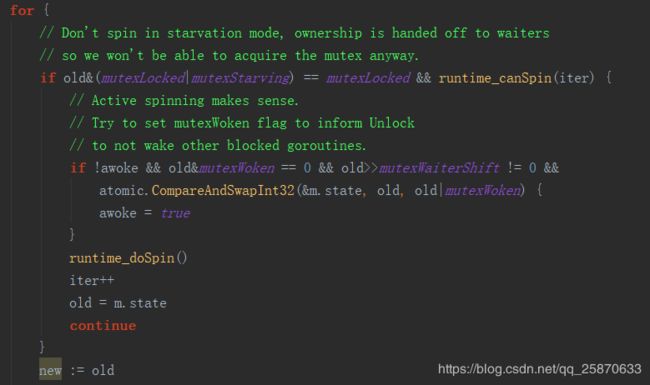
先用 当前状态去 & 锁定和饥饿的状态 看看当前mutex是否为锁定状态,且判断当前当前竞争该mutex的goroutine 是否可以做自旋操作。如果条件满足了,mutex是处于锁定状态,且可以自旋,这时候就再 进一步判断,当前mutex是否有正在等待的的goroutine被唤醒,且 当前有等待的 goroutine ,且给原有的状态(state) 追加goroutine被唤醒状态成功设置的话,则修改中转变量为 唤醒 awoke = true。然后,不管有没有去做唤醒动作,只要是当前mutex 有被锁定且可以有goroutine 可以做自旋,则都回去做自旋且累加自旋计数。继续下轮操作 。否则,往下先获取当前 old的值: new := old 。
再往下走:

第一个 if :表示 判断是否不是饥饿状态,(只要不是饥饿就是正常状态,此时不管是否锁定,是否有goroutine 被唤醒)。如果是饥饿,且因为没哟进去前面的if (不被锁定或者不能再自旋了) 这时候来到这个 if 如果是正常,那么就追加 锁定状态
第二个 if: 表示 只要是 被锁定 或者 饥饿状态,那么由于该mutex不可以被当前调用Lock 函数的 goroutine 锁定,所以,增加等待 goroutine 数目,表示当前 goroutine 等待该mutex
第三个 if: 是饥饿状态,且 mutex处于被锁定状态,那么当前 goroutine 就抢不到锁,则追加为 饥饿状态。
第四个 if :是 如果当前处于 被唤醒状态,那么进一步判断state表示, 如果state没有处于 没有被唤醒,表示有脏数据 (因为 state 的状态值, 和 awoke 和 starving 相呼应的) ,则这时候需要发生恐慌。另外还需要重置被唤醒标识为(消除 被唤醒, 作用是,在下次重新复制 被唤醒时的一个初始状态)
紧接着:

把理后经过处的 新的state的值 (new) 赋值给 state, 如果不OK (有别人过来改掉了 state),则,重新刷新中转变量 old 去再次重复 死循环 for 的操作。OK,就继续往里面走,如果 old 已经不属于 饥饿 或者 被锁定,那么结束 CAS 死循环。否则,记录等待时间,紧接着调用 runtime_SemacquireMutex 阻塞当前新进来的 goroutine (饥饿状态下,后来的 goroutine 会被阻塞),然后,设置 饥饿标识 为 是否饥饿。然后,再次刷新old 中转变量,紧接着判断是否处于饥饿状态。如果处于饥饿状态,紧接着 state可能 又可能是被锁定,又可能是被唤醒 或者 没有等待的goroutine ,那么就是出现了不一致问题,则 panic。
紧接着用 delta 表示当前状态下的等待数,即减少一个锁定状态下的 goroutine。然后判断饥饿标识 不为饥饿 或者 已经正在等待的 goroutine 只有一个了,那么就退出 饥饿模式。重置 state 并退出 cas 死循环。如果不属于饥饿模式,那么设置 唤醒标识位唤醒,且累计自旋计数。ok,这就是我们的 Lock 函数。
下面我们来看看,Unlock 函数:

解锁,一进来就什么都不管,直接去移除锁 标志。然后 做一次校验之前的状态,(很简单,把标识加回去然后 & 锁定状态)去判断之前的状态是否被锁定。如果之前是非锁定状态,那么解锁就会报错;紧接着我们往下看。
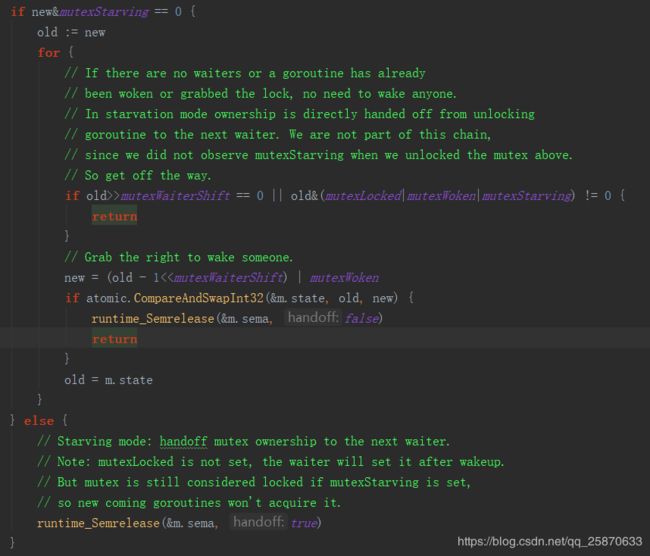
先判断,解了锁之后的状态是否处于 饥饿状态。如果是饥饿状态就直接调用 else 的逻辑去做阻塞解除;否则,就走近 if 里面,先把解锁后的状态记录到中转变量 old 上,然后进入 死循环。进入死循环后第一件事就是,判断 如果没有等待的goroutine,或者 等待的goroutine 有余量且锁的状态为被唤醒,则结束 Unlock (注意 锁的标识已经在 Unlock函数一进来就减掉了);否则 减少 等待 goroutine 的个数 (因为当前调用Unlock 的goroutine 需要被减掉啊,然后持加 唤醒状态) 且重置 state。并释放阻塞,结束调用。如果重置 state 不成功的话就刷新 old 中转变量,进入下一轮 死循环。这就是 Unlock 函数的逻辑。到此为止, mutex的源码已经讲完。
其中具体的流程为:
Lock:

Unlock:

上述就是 sync.Mutex的原理。
【rwmutex】:
既然说了mutex,那下面我们来说一说,sync包的另外一个锁成员 rwmutex:读写锁被定义在 src/sync/rwmutex.go 文件中
线上代码:
type RWMutex struct {
w Mutex // 互斥锁
writerSem uint32 // 写锁信号量
readerSem uint32 // 读锁信号量
readerCount int32 // 读锁计数器
readerWait int32 // 获取写锁时需要等待的读锁释放数量
}
const rwmutexMaxReaders = 1 << 30 // 支持最多2^30个读锁
// 读锁锁定:
//
// 它不应该用于递归读锁定;
func (rw *RWMutex) RLock() {
// 竞态检测
if race.Enabled {
_ = rw.w.state
race.Disable()
}
// 每次goroutine获取读锁时,readerCount+1
// 如果写锁已经被获取,那么readerCount在 - rwmutexMaxReaders与 0 之间,这时挂起获取读锁的goroutine,
// 如果写锁没有被获取,那么readerCount>=0,获取读锁,不阻塞
// 通过readerCount的正负判断读锁与写锁互斥,如果有写锁存在就挂起读锁的goroutine,多个读锁可以并行
if atomic.AddInt32(&rw.readerCount, 1) < 0 {
// 将goroutine排到G队列的后面,挂起goroutine, 监听readerSem信号量
runtime_Semacquire(&rw.readerSem)
}
// 竞态检测
if race.Enabled {
race.Enable()
race.Acquire(unsafe.Pointer(&rw.readerSem))
}
}
// 释放读锁
// 读锁不会影响其他读操作
// 如果在进入RUnlock时没有锁没有被施加读锁的话,则会出现运行时错误。
func (rw *RWMutex) RUnlock() {
// 竞态检测
if race.Enabled {
_ = rw.w.state
race.ReleaseMerge(unsafe.Pointer(&rw.writerSem))
race.Disable()
}
// 读锁计数器 -1
// 有四种情况,其中后面三种都会进这个 if
// 【一】有读锁,单没有写锁被挂起
// 【二】有读锁,且也有写锁被挂起
// 【三】没有读锁且没有写锁被挂起的时候, r+1 == 0
// 【四】没有读锁但是有写锁被挂起,则 r+1 == -(1 << 30)
if r := atomic.AddInt32(&rw.readerCount, -1); r < 0 {
// 读锁早就被没有了,那么在此 -1 是需要抛异常的
// 这里只有当读锁没有的时候才会出现的两种极端情况
// 【一】没有读锁且没有写锁被挂起的时候, r+1 == 0
// 【二】没有读锁但是有写锁被挂起,则 r+1 == -(1 << 30)
if r+1 == 0 || r+1 == -rwmutexMaxReaders {
race.Enable()
throw("sync: RUnlock of unlocked RWMutex")
}
// 否则,就属于 有读锁,且也有写锁被挂起
// 如果获取写锁时的goroutine被阻塞,这时需要获取读锁的goroutine全部都释放,才会被唤醒
// 更新需要释放的 写锁的等待读锁释放数目
// 最后一个读锁解除时,写锁的阻塞才会被解除.
if atomic.AddInt32(&rw.readerWait, -1) == 0 {
// 更新信号量,通知被挂起的写锁去获取锁
runtime_Semrelease(&rw.writerSem, false)
}
}
if race.Enabled {
race.Enable()
}
}
// 对一个已经lock的rw上锁会被阻塞
// 如果锁已经锁定以进行读取或写入,则锁定将被阻塞,直到锁定可用。
func (rw *RWMutex) Lock() {
if race.Enabled {
_ = rw.w.state
race.Disable()
}
// 先获取一把互斥锁
// 首先,获取互斥锁,与其他来获取写锁的goroutine 互斥
rw.w.Lock()
// 告诉其他来获取读锁操作的goroutine,现在有人获取了写锁
// 减去最大的读锁数量,用0 -负数 来表示写锁已经被获取
r := atomic.AddInt32(&rw.readerCount, -rwmutexMaxReaders) + rwmutexMaxReaders
// 设置需要等待释放的读锁数量,如果有,则挂起获取 竞争写锁 goroutine
if r != 0 && atomic.AddInt32(&rw.readerWait, r) != 0 {
// 挂起,监控写锁信号量
runtime_Semacquire(&rw.writerSem)
}
if race.Enabled {
race.Enable()
race.Acquire(unsafe.Pointer(&rw.readerSem))
race.Acquire(unsafe.Pointer(&rw.writerSem))
}
}
// Unlock 已经Unlock的锁会被阻塞.
// 如果在写锁时,rw没有被解锁,则会出现运行时错误。
//
// 与互斥锁一样,锁定的RWMutex与特定的goroutine无关。
// 一个goroutine可以RLock(锁定)RWMutex然后安排另一个goroutine到RUnlock(解锁)它。
func (rw *RWMutex) Unlock() {
if race.Enabled {
_ = rw.w.state
race.Release(unsafe.Pointer(&rw.readerSem))
race.Release(unsafe.Pointer(&rw.writerSem))
race.Disable()
}
// 向 读锁的goroutine发出通知,现在已经没有写锁了
// 还原加锁时减去的那一部分readerCount
r := atomic.AddInt32(&rw.readerCount, rwmutexMaxReaders)
// 读锁数目超过了 最大允许数
if r >= rwmutexMaxReaders {
race.Enable()
throw("sync: Unlock of unlocked RWMutex")
}
// 唤醒获取读锁期间所有被阻塞的goroutine
for i := 0; i < int(r); i++ {
runtime_Semrelease(&rw.readerSem, false)
}
// 释放互斥锁资源
rw.w.Unlock()
if race.Enabled {
race.Enable()
}
}
// RLocker返回一个Locker接口的实现
// 通过调用rw.RLock和rw.RUnlock来锁定和解锁方法。
func (rw *RWMutex) RLocker() Locker {
return (*rlocker)(rw)
}
type rlocker RWMutex
func (r *rlocker) Lock() { (*RWMutex)(r).RLock() }
func (r *rlocker) Unlock() { (*RWMutex)(r).RUnlock() }从上面的代码中我们可以看到,读写锁首先是内置了一个互斥锁,然后再加上维护各种计数器来实现的读写锁,紧接着提供了四个函数支撑着读写锁操作,由 Lock 和Unlock 分别支持写锁的锁定和释放,由RLock 和RUnlock 来支持读锁的的锁定和释放。
读写互斥锁的实现比较有技巧性一些,需要几点
1. 读锁不能阻塞读锁,引入readerCount实现
2. 读锁需要阻塞写锁,直到所以读锁都释放,引入readerSem实现
3. 写锁需要阻塞读锁,直到所以写锁都释放,引入wirterSem实现
4. 写锁需要阻塞写锁,引入Metux实现
首先,我们来讲解 写锁的Lock和Unlock 操作:

首先,一进来就去获取 mutex 用来和其他 写锁互斥。如果获取不成功,说明目前有其他写锁获取到了mutex,那么就会阻塞当前写锁的goroutine。如果获取成功,那么就往下走,然后先对读锁计数器 readerCount 做减去最大允许读锁数 rwmutexMaxReaders ,减完之后用得到的数字加回最大允许读锁数去判断之前还有多少个读锁的 中间变量 r ,如果得知之前读锁的数目 不等于0 (其实只会可能 大于0)则说明之前有读锁存在则叠加 写锁需要等待的读锁释放数量 readerWait ,并且 挂起当前试图获取写锁的 goroutine。
下面说 解写锁:

解写锁的时候,首先我们可以保证一点是(必须是之前获取写锁已成功,且没有读锁持锁),所以一进来就先把之前获取写锁操作时 对读锁减掉 最大允许读锁数目 readerCount 的值,在这里加回来,以此代表写锁已被解除。如果 解除之后的值大于 或等于最大允许读锁数 rwmutexMaxReaders 则表示目前还有读锁或者已经没有读锁但是之前的写锁持锁操作没有成功,导致 r >= rwmutexMaxReaders ,所以都属于 对一个没有上过写锁的锁做 解写锁 操作,则抛 panic。成功,就唤醒所有的之前被挂起的 读锁操作的goroutine (读锁可以有多个)。并且释放掉 mutex。
下面我们来看 读锁的持锁操作和释放锁操作。先来看读锁持锁操作:

首先,读锁持锁操作一进来就叠加 当前读锁计数 readerCount ,如果之前已经有写锁持锁,那么现在就算叠加 读锁计数器也是 小于0 的,所以先挂起当前写锁,否则获取写锁成功。
下面我们看读锁解锁:

也是一进来就自减 读锁计数器 readerCount ,如果减完之后的数 r 小于0 说明对 没有没有上过读锁的锁做了解锁操作,抛 panic。否则对之前 写锁的持锁操作中的 写锁时需要等待的读锁释放数量 readerWait 做自减, 当全部释放了读锁时,则通知释放之前 写锁做持锁操作不成功时被挂起的 写锁。
下面用图来查看流程:
【读锁的】
Rlock:

RUnlock:

【写锁的】
Lock:

Unlock:
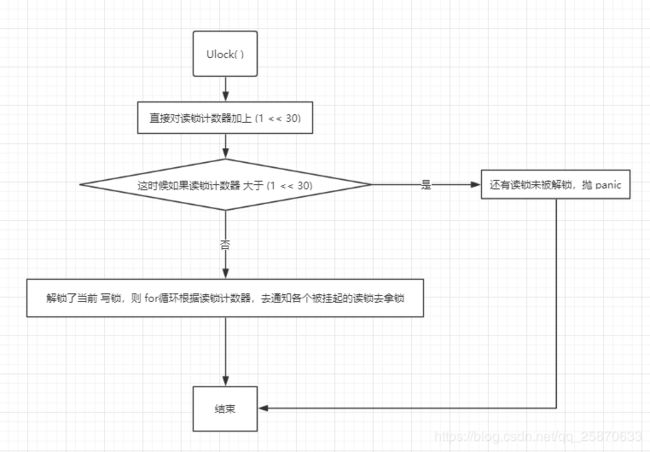
以上就是 rwmutex的实现。
其中,读锁不涉及 内置mutex的使用,写锁用了mutex来排斥其他写锁。
【cond】:
下面我们来看sync包的Cond:代码在 src\sync\cond.go 路径下
可以参考:https://www.jianshu.com/p/7b59d1d92a95
Cond是一个条件锁,就是当满足某些条件下才起作用的锁,有的地方也叫 定期唤醒锁,有的地方叫 条件变量。我们先来看一看cond的使用demo:
var locker = new(sync.Mutex)
var cond = sync.NewCond(locker)
func test(x int) {
cond.L.Lock() //获取锁
cond.Wait()//等待通知 暂时阻塞
fmt.Println(x)
time.Sleep(time.Second * 1)
cond.L.Unlock()//释放锁
}
func main() {
for i := 0; i < 40; i++ {
go test(i)
}
fmt.Println("start all")
time.Sleep(time.Second * 3)
fmt.Println("broadcast")
cond.Signal() // 下发一个通知给已经获取锁的goroutine
time.Sleep(time.Second * 3)
cond.Signal()// 3秒之后 下发一个通知给已经获取锁的goroutine
time.Sleep(time.Second * 3)
cond.Broadcast()//3秒之后 下发广播给所有等待的goroutine
time.Sleep(time.Second * 60)
}下面我们直接来看cond 的源码:
// Cond实现了一个条件变量,一个等待或宣布事件发生的goroutines的集合点。
//
// 每个Cond都有一个相关的Locker L(通常是* Mutex或* RWMutex)。
type Cond struct {
// 不允许复制,一个结构体,有一个Lock()方法,嵌入别的结构体中,表示不允许复制
// noCopy对象,拥有一个Lock方法,使得Cond对象在进行go vet扫描的时候,能够被检测到是否被复制
noCopy noCopy
// 锁的具体实现,通常为 mutex 或者rwmutex
L Locker
// 通知列表,调用Wait()方法的goroutine会被放入list中,每次唤醒,从这里取出
// notifyList对象,维护等待唤醒的goroutine队列,使用链表实现
// 在 sync 包中被实现, src/sync/runtime.go
notify notifyList
// 复制检查,检查cond实例是否被复制
// copyChecker对象,实际上是uintptr对象,保存自身对象地址
checker copyChecker
}
// NewCond方法传入一个实现了Locker接口的对象,返回一个新的Cond对象指针,
// 保证在多goroutine使用cond的时候,持有的是同一个实例
func NewCond(l Locker) *Cond {
return &Cond{L: l}
}
// 等待原子解锁c.L并暂停执行调用goroutine。
// 稍后恢复执行后,Wait会在返回之前锁定c.L.
// 与其他系统不同,除非被广播或信号唤醒,否则等待无法返回。
// 因为等待第一次恢复时c.L没有被锁定,
// 所以当Wait返回时,调用者通常不能认为条件为真。
// 相反,调用者应该循环等待:
// c.L.Lock()
// for !condition() {
// c.Wait()
// }
// ... make use of condition ...
// c.L.Unlock()
//
// 调用此方法会将此routine加入通知列表,并等待获取通知,调用此方法必须先Lock,不然方法里会调用Unlock(),报错
//
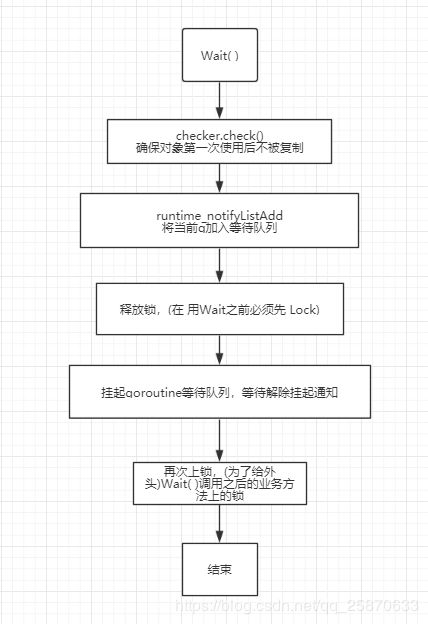
func (c *Cond) Wait() {
// 检查是否被复制; 如果是就panic
// check检查,保证cond在第一次使用后没有被复制
c.checker.check()
// 将当前goroutine加入等待队列, 该方法在 runtime 包的 notifyListAdd 函数中实现
// src/runtime/sema.go
t := runtime_notifyListAdd(&c.notify)
// 释放锁,
// 因此在调用Wait方法前,必须保证获取到了cond的锁,否则会报错
c.L.Unlock()
// 等待队列中的所有的goroutine执行等待唤醒操作
// 将当前goroutine挂起,等待唤醒信号
// 该方法在 runtime 包的 notifyListWait 函数中实现
// src/runtime/sema.go
runtime_notifyListWait(&c.notify, t)
// 被通知了,获取锁,继续运行
c.L.Lock()
}
//
// 唤醒单个 等待的 goroutine
func (c *Cond) Signal() {
// 检查c是否是被复制的,如果是就panic
// 保证cond在第一次使用后没有被复制
c.checker.check()
// 通知等待列表中的一个
// 顺序唤醒一个等待的gorountine
// 在runtime 包的 notifyListNotifyOne 函数中被实现
// src/runtime/sema.go
runtime_notifyListNotifyOne(&c.notify)
}
// 唤醒等待队列中的所有goroutine。
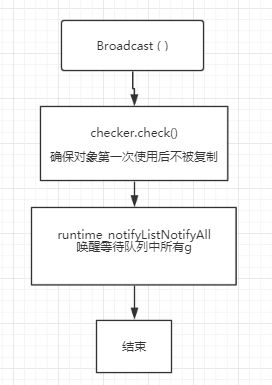
func (c *Cond) Broadcast() {
// 检查c是否是被复制的,如果是就panic
// 保证cond在第一次使用后没有被复制
c.checker.check()
// 唤醒等待队列中所有的goroutine
// 有runtime 包的 notifyListNotifyAll 函数实现
// src\runtime\sema.go
runtime_notifyListNotifyAll(&c.notify)
}
// copyChecker保持指向自身的指针以检测对象复制。
type copyChecker uintptr
// 检查c是否被复制,如果是则panic
/**
check方法在第一次调用的时候,会将checker对象地址赋值给checker,也就是将自身内存地址赋值给自身
*/
func (c *copyChecker) check() {
/**
因为 copyChecker的底层类型为 uintptr
那么 这里的 *c其实就是 copyChecker类型本身,然后强转成uintptr
和拿着 c 也就是copyChecker的指针去求 uintptr,理论上要想等
即:内存地址为一样,则表示没有被复制
*/
// 下述做法是:
// 其实 copyChecker中存储的对象地址就是 copyChecker 对象自身的地址
// 先把 copyChecker 处存储的对象地址和自己通过 unsafe.Pointer求出来的对象地址作比较,
// 如果发现不相等,那么就尝试的替换,由于使用的 old是0,
// 则表示c还没有开辟内存空间,也就是说,只有是首次开辟地址才会替换成功
// 如果替换不成功,则表示 copyChecker出所存储的地址和 unsafe计算出来的不一致
// 则表示对象是被复制了
if uintptr(*c) != uintptr(unsafe.Pointer(c)) &&
!atomic.CompareAndSwapUintptr((*uintptr)(c), 0, uintptr(unsafe.Pointer(c))) &&
uintptr(*c) != uintptr(unsafe.Pointer(c)) {
panic("sync.Cond is copied")
}
}
// noCopy可以嵌入到结构中,在第一次使用后不得复制。
//
// 详细介绍请查看: https://github.com/golang/go/issues/8005#issuecomment-190753527
type noCopy struct{}
// Lock is a no-op used by -copylocks checker from `go vet`.
// Lock 是有 go vet 命令来判断是否有 copy 的检查的
func (*noCopy) Lock() {}
// sync/runtime.go
// 使用链表实现
type notifyList struct {
wait uint32 // 等待数
notify uint32 // 唤醒数
lock uintptr // 信号锁
// 使用链表实现
head unsafe.Pointer // 队列的当前头
tail unsafe.Pointer // 队列的当前尾
}我们可以看出,其中
-
Cond不能被复制:Cond在内部持有一个等待队列,这个队列维护所有等待在这个Cond的goroutine。因此若这个Cond允许值传递,则这个队列在值传递的过程中会进行复制,导致在唤醒goroutine的时候出现错误。
-
顺序唤醒: notifyList对象持有两个无限自增的字段wait和notify,wait字段在有新的goroutine等待的时候加1,notify字段在有新的唤醒信号的时候加1。在有新的goroutine加入队列的时候,会将当前wait赋值给goroutine的ticket,唤醒的时候会唤醒ticket等于notify的gourine。另外,当wait==notify时表示没有goroutine需要被唤醒,wait>notify时表示有goroutine需要被唤醒,waity恒大于等于notify
首先,在使用Cond时,需要由外部传一个锁实例进来。调用 NewCond 方法:
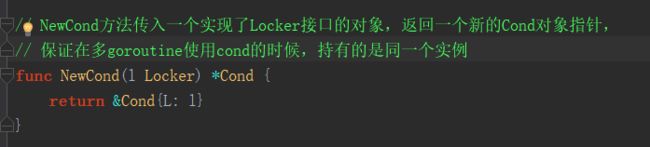
然后就可以在业务中【注意,是必须】先由外部锁,去竞争拿锁:

可以看出来在使用Wait 方法之前,我们必须先获取外部锁,原因是:先当前协程占有着锁,并挂起当前协程等待,其他协程的 通知唤醒,好走后续的业务逻辑,(占有着锁,是不想别人拿到锁,而自己走不到Wait这一步,而Wait是挂起了当前协程,等待别人通知,这样做,就知道只要通知一来,肯定是当前协程可以继续往下走了),这里自己通过对比 Wait的使用及Wait的源码自己就明白了。

接着,Wait中被挂起的goroutine 会一直等待者通知唤醒。
通知有两种形式:
【一】:单个通知
【二】:广播
《单个通知》

《广播》

其中,三个主要方法的流程如下:
Wait:
Signal:

Broadcast:
以上就是Cond的实现。
【Once】:
下面我们来看看 Once 的实现,Once 被定义在 src/sync/once.go 中。其代码非常简单:
// Once 是一个只执行一个动作的对象。
type Once struct {
m Mutex
done uint32 // 初始值为0表示还未执行过,1表示已经执行过
}
// Once 的实现超级简单
// 用 互斥锁做线程安全控制
// 用uint32的done字段标识是否执行过
func (o *Once) Do(f func()) {
// 每次一进来先读标识位 0 标识没有被执行过,1 标识已经被执行过
if atomic.LoadUint32(&o.done) == 1 {
return
}
// 施加互斥锁
o.m.Lock()
defer o.m.Unlock()
// 如果之前未被执行过,则执行
if o.done == 0 {
// 先调用目标函数, 然后标识位更该去为 1
defer atomic.StoreUint32(&o.done, 1)
f()
}
}从上面我们可以看出,once只有一个 Do 方法;once的结构体中只定义了两个字段:一个mutex的m,一个代表标识位的done。
下面我们来看看Do方法的流程:
Do:

好了 once 不需要过多的讲解,实现十分的简单;
【WaitGroup】:
下面我们来看看 一个并发时使用的比较多的 WaitGroup:(其在 src\sync\cond.go 文件中)
// 首次使用后不得复制池。
type WaitGroup struct {
// noCopy可以嵌入到结构中,在第一次使用后不可复制,使用go vet作为检测使用
noCopy noCopy
// 64 bit:高32 bit是计数器,低32位是 阻塞的goroutine计数。
// 64位的原子操作需要64位的对齐,但是32位。
// 编译器不能确保它,所以分配了12个byte对齐的8个byte作为状态。
// 共12个字节,低4字节用于记录wait等待次数,
// 高8字节是计数器(64位机器是高8字节,32机器是中间4个字节,
// 因为64位机器的原子操作需要64位的对齐,但是32位的编译器不能确保。)
// 所以分配了12个byte对齐的8个byte作为状态
// (即:在高低位上 总共用了12byte 代表8byte,为了完全覆盖 64位和32位机器)
// 其实就是为了表达 高8byte,也即 高32位,仅此而已
// byte=uint8范围:0~255,只取前8个元素。转为2进制:0000 0000,0000 0000... ...0000 0000
state1 [12]byte
// 信号量,用于唤醒goroution
sema uint32
}
// uintptr和unsafe.Pointer的区别就是:unsafe.Pointer只是单纯的通用指针类型,用于转换不同类型指针,它不可以参与指针运算;
// 而uintptr是用于指针运算的,GC 不把 uintptr 当指针,也就是说 uintptr 无法持有对象,uintptr类型的目标会被回收。
// state()函数可以获取到wg.state1数组中元素组成的二进制对应的十进制的值
// 根据编译器位数,获得标志位和等待次数的数据域
func (wg *WaitGroup) state() *uint64 {
// 是否是 64位机器:因为64位机器站高8位
if uintptr(unsafe.Pointer(&wg.state1))%8 == 0 {
return (*uint64)(unsafe.Pointer(&wg.state1))
} else {
// 如果是 32位机器, 则首元素从第 4 位开始:因为32 位机器占中间4位
return (*uint64)(unsafe.Pointer(&wg.state1[4]))
}
}
func (wg *WaitGroup) Add(delta int) {
// 获取到wg.state1数组中元素组成的二进制对应的十进制的值的指针
statep := wg.state()
if race.Enabled {
_ = *statep
if delta < 0 {
race.ReleaseMerge(unsafe.Pointer(wg))
}
race.Disable()
defer race.Enable()
}
// 将标记为加delta
// 因为高32位是计数器
// 所以把 delta的值左移32位,并从数组的首元素处开始赋值
// statep 对于 [12]byte 来说:
// 如果是64位的机器,那么首元素地址就是 0 下标处开始
// 如果是32位机器,那么首元素地址是 4 下标处开始
state := atomic.AddUint64(statep, uint64(delta)<<32)
// 获取计数器的值: 转了 int32
v := int32(state >> 32)
//获得调用 wait()等待次数:转了 uint32
w := uint32(state)
if race.Enabled {
if delta > 0 && v == int32(delta) {
race.Read(unsafe.Pointer(&wg.sema))
}
}
// 计数器为负数,报panic
//标记位不能小于0(done过多或者Add()负值太多)
if v < 0 {
panic("sync: negative WaitGroup counter")
}
// 不能Add 与Wait 同时调用
if w != 0 && delta > 0 && v == int32(delta) {
panic("sync: WaitGroup misuse: Add called concurrently with Wait")
}
// Add 完毕
if v > 0 || w == 0 {
return
}
// 当等待计数器> 0时,而goroutine将设置为0。
// 此时不可能有同时发生的状态突变:
// - Add()不能与 Wait() 同时发生,
// - 如果计数器counter == 0,不再增加等待计数器
// 不能Add 与Wait 同时调用
if *statep != state {
panic("sync: WaitGroup misuse: Add called concurrently with Wait")
}
// 所有状态位清零
*statep = 0
//唤醒等待的 goroutine
for ; w != 0; w-- {
// 目的是作为一个简单的wakeup原语,以供同步使用。true为唤醒排在等待队列的第一个goroutine
runtime_Semrelease(&wg.sema, false)
}
}
// Done方法其实就是Add(-1)
func (wg *WaitGroup) Done() {
wg.Add(-1)
}
// Wait 会一直阻塞到 计数器值为0为止
func (wg *WaitGroup) Wait() {
// 获取到wg.state1数组中元素组成的二进制对应的十进制的值的指针
statep := wg.state()
if race.Enabled {
_ = *statep
race.Disable()
}
// cas算法
//循环检查计数器V啥时候等于0
for {
// 获取 计数值
state := atomic.LoadUint64(statep)
// 高32位是计数器
v := int32(state >> 32)
// 计数值
w := uint32(state)
// v == 0 说明 goroutine 执行结束
if v == 0 {
if race.Enabled {
race.Enable()
race.Acquire(unsafe.Pointer(wg))
}
return
}
// 尚有未执行完的go程,等待标志位+1(直接在低位处理,无需移位)
// 增加等待goroution计数,对低32位加1,不需要移位
if atomic.CompareAndSwapUint64(statep, state, state+1) {
if race.Enabled && w == 0 {
race.Write(unsafe.Pointer(&wg.sema))
}
// 目的是作为一个简单的sleep原语,以供同步使用
runtime_Semacquire(&wg.sema)
// 在上一次Wait返回之前重新使用WaitGroup,即在之前的Done 中没有清空 计数量就会有问题
if *statep != 0 {
panic("sync: WaitGroup is reused before previous Wait has returned")
}
if race.Enabled {
race.Enable()
race.Acquire(unsafe.Pointer(wg))
}
return
}
}
}在WaitGroup中,首先定义了以下结构体:

在WaitGroup 结构体中,只有三个字段,表示 首次使用后不可以复制的 noCopy类型的 noCopy;表示计数的 [12]byte类型的 state1;表示 信号量的uint32类型的sema。其中表示计数的 [12]byte类型的 state1十分有讲究,其中原本是打算用 64bit来表示计数,高32 bit是Add()计数器,低32位是 阻塞的goroutine计数,也就是只要分配8个byte就可以表示。但由于 因为64位机器的原子操作需要64位的对齐,但是32位的编译器不能确保,特别是64位机器是高8字节,32机器是中间4个字节,所以这里使用了12位来代替8位,即高8位是为了完全覆盖64和32机器,而低4位是用来做 阻塞的goroutine计数。
我们下面再来看一个核心的方法:state(),该方法实现如下所示:
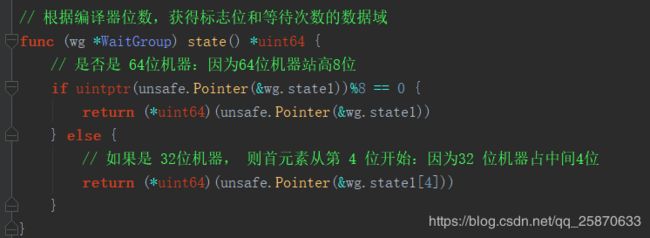
图中我们可以看出,首先是根据不同的机器对数组首位置地址的模上8来判断是多少位的机器,如果是64位的则直接拿数组0下标地址为起始位,如果是32位机器,则拿数组4下标的地址为起始位置。
我们再来看看主要对外的三个方法的流程:
Add:
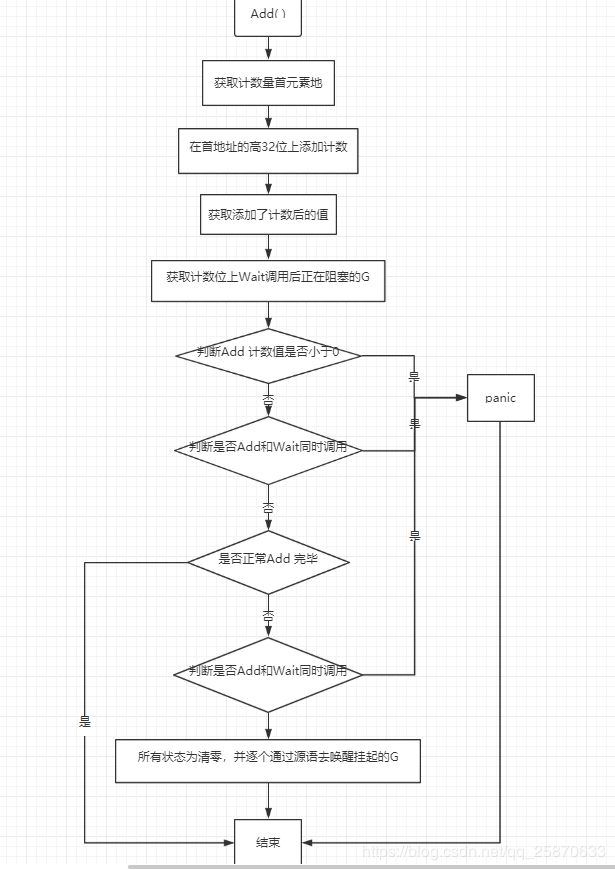
Done:

Wait:

以上就是WaitGroup的具体流程。
【Pool】:
下面我们来看看最后一个成员Pool,其被定义在 src\sync\pool.go 文件中。
一下是Pool的源代码:
// 池是一组可以单独保存和检索的临时对象。
//
//
// 存储在池中的任何项目都可以随时自动删除,
// 并且不会被通知。如果池在发生这种情况时保留唯一引用,
// 则该项可能会被释放。
//
// Pool可以安全地同时使用多个goroutine。
//
// 池的目的是缓存已分配但未使用的 对象 以供以后重用,
// 从而减轻对 gc 的压力。也就是说,
// 它可以轻松构建高效,线程安全的 free 列表。
// 但是,它不适用于所有 free 列表。
//
// 池的适当使用是管理一组默认共享的临时项,
// 并且可能由包的并发独立客户端重用。
// 池提供了一种在许多客户端上分摊分配开销的方法。
//
//
// 很好地使用池的一个例子是fmt包,
// 它维护一个动态大小的临时输出缓冲区存储。
// 底层存储队列 在负载下(当许多goroutine正在积极打印时)
// 进行缩放,并在静止时收缩。
//
// 另一方面,作为短期对象的一部分维护的空闲列表不适合用于池,
// 因为在该场景中开销不能很好地摊销。
// 使这些对象实现自己的空闲列表更有效。
//
//
// 首次使用后不得复制池。
//
/**
pool 的两个特点
1、在本地私有池和本地共享池均获取 obj 失败时,
则会从其他 p 偷一个 obj 返回给调用方。
2、obj 在池中的生命周期取决于垃圾回收任务的下一次执行时间,
并且从池中获取到的值可能是 put 进去的其中一个值,
也可能是 new fun 处 新生成的一个值,在应用时很容易入坑。
在多个goroutine之间使用同一个pool做到高效,是因为sync.pool为每个P都分配了一个子池,
当执行一个pool的get或者put操作的时候都会先把当前的goroutine固定到某个P的子池上面,
然后再对该子池进行操作。每个子池里面有一个私有对象和共享列表对象,
私有对象是只有对应的P能够访问,因为一个P同一时间只能执行一个goroutine,
【因此对私有对象存取操作是不需要加锁的】。
共享列表是和其他P分享的,因此操作共享列表是需要加锁的。
*/
type Pool struct {
// 不允许复制,一个结构体,有一个Lock()方法,嵌入别的结构体中,表示不允许复制
// noCopy对象,拥有一个Lock方法,使得Cond对象在进行go vet扫描的时候,能够被检测到是否被复制
noCopy noCopy
/** local 和 localSize 维护一个动态 poolLocal 数组 */
// 每个固定大小的池, 真实类型是 [P]poolLocal
// 其实就是一个[P]poolLocal 的指针地址
local unsafe.Pointer
// local 数组的大小
// typedef uint64 uintptr
localSize uintptr
// New 是一个回调函数指针
// 即:当Get 获取到目标对象为 nil 时,需要调用 此处的回调函数
// 用于生成 新的对象
New func() interface{}
}
// 本地池的附录
// 也就是一些包装
type poolLocalInternal struct {
// 只能由相应的P 使用
// 私有缓冲区
private interface{}
// 可以由任意的P 使用
// 公共缓冲区
shared []interface{}
// 保护共享的互斥锁
Mutex
}
/**
【注意】
因为poolLocal中的对象可能会被其他P偷走,
private域保证这个P不会被偷光,至少保留一个对象供自己用。
否则,如果这个P只剩一个对象,被偷走了,
那么当它本身需要对象时又要从别的P偷回来,造成了不必要的开销。
*/
type poolLocal struct {
poolLocalInternal
/**
cache使用中常见的一个问题是false sharing。
当不同的线程同时读写同一cache line上不同数据时就可能发生false sharing。
false sharing会导致多核处理器上严重的系统性能下降。
*/
// 字节对齐,避免 false sharing (伪共享)
pad [128 - unsafe.Sizeof(poolLocalInternal{})%128]byte
}
// 在 runtime 包中实现 /src/runtime/stubs.go 的 sync_fastrand()
func fastrand() uint32
var poolRaceHash [128]uint64
// poolRaceAddr returns an address to use as the synchronization point
// for race detector logic. We don't use the actual pointer stored in x
// directly, for fear of conflicting with other synchronization on that address.
// Instead, we hash the pointer to get an index into poolRaceHash.
// See discussion on golang.org/cl/31589.
func poolRaceAddr(x interface{}) unsafe.Pointer {
ptr := uintptr((*[2]unsafe.Pointer)(unsafe.Pointer(&x))[1])
h := uint32((uint64(uint32(ptr)) * 0x85ebca6b) >> 16)
return unsafe.Pointer(&poolRaceHash[h%uint32(len(poolRaceHash))])
}
/** 总的来说,sync.Pool的定位不是做类似连接池的东西,它的用途仅仅是增加对象重用的几率,减少gc的负担,而开销方面也不是很便宜的 */
/**
归还对象的过程:
1)固定到某个P,如果私有对象为空则放到私有对象;
2)否则加入到该P子池的共享列表中(需要加锁)。
可以看到一次put操作最少0次加锁,最多1次加锁。
*/
func (p *Pool) Put(x interface{}) {
/**
如果放入的值为空,直接return.
检查当前goroutine的是否设置对象池私有值,
如果没有则将x赋值给其私有成员,并将x设置为nil。
如果当前goroutine私有值已经被设置,那么将该值追加到共享列表。
*/
if x == nil {
return
}
if race.Enabled {
if fastrand()%4 == 0 {
// Randomly drop x on floor.
return
}
race.ReleaseMerge(poolRaceAddr(x))
race.Disable()
}
// 先获得当前P绑定的 localPool
l := p.pin()
// 如果当前 localPool中的 私有 缓冲区为nil
// 则将 obj的值赋给 私有缓冲区,并将 obj 引用设为 nil (入参的 obj是个interface{})
if l.private == nil {
l.private = x
x = nil
}
// 调用方必须在完成取值后调用 runtime_procUnpin() 来取消禁用抢占
runtime_procUnpin()
// 如果上面添加入私有缓冲不成功,则加入公共缓冲区
if x != nil {
l.Lock()
l.shared = append(l.shared, x)
l.Unlock()
}
if race.Enabled {
race.Enable()
}
}
/**
获取对象过程是:
1)固定到某个P,尝试从私有对象获取,如果私有对象非空则返回该对象,并把私有对象置空;
2)如果私有对象是空的时候,就去当前子池的共享列表获取(需要加锁);
3)如果当前子池的共享列表也是空的,那么就尝试去其他P的子池的共享列表偷取一个(需要加锁),并删除其他P的共享池中的该值(p.getSlow());
4)如果其他子池都是空的,最后就用用户指定的New函数产生一个新的对象返回。注意这个分配的值不会被放入池中。
可以看到一次get操作最少0次加锁,最大N(N等于MAXPROCS)次加锁。
*/
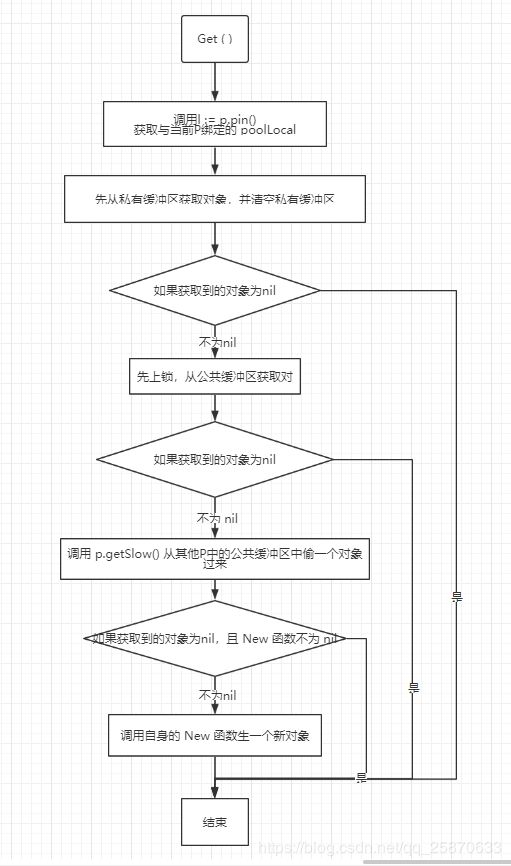
func (p *Pool) Get() interface{} {
/**
尝试从本地P对应的那个本地池中获取一个对象值, 并从本地池冲删除该值。
如果获取失败,那么从共享池中获取, 并从共享队列中删除该值。
如果获取失败,那么从其他P的共享池中偷一个过来,并删除共享池中的该值(p.getSlow())。
如果仍然失败,那么直接通过New()分配一个返回值,注意这个分配的值不会被放入池中。
New()返回用户注册的New函数的值,如果用户未注册New,那么返回nil。
*/
if race.Enabled {
race.Disable()
}
// l : *poolLocal
// 即:与当前P绑定的 poolLocal
l := p.pin()
// 这里不需要加锁,因为 p.pin() 中将 goroutine 设为了不可抢占。
x := l.private
l.private = nil
// 先取消禁用抢占
runtime_procUnpin()
// 如果私有缓冲取不到则,从公共缓冲区尾部拿
if x == nil {
l.Lock()
last := len(l.shared) - 1
if last >= 0 {
x = l.shared[last]
l.shared = l.shared[:last]
}
l.Unlock()
// 如果还取不到,则去其他P的公共缓冲区,偷一个
if x == nil {
x = p.getSlow()
}
}
if race.Enabled {
race.Enable()
if x != nil {
race.Acquire(poolRaceAddr(x))
}
}
// 如果 还是空,则 new一个
if x == nil && p.New != nil {
x = p.New()
}
return x
}
/**
在我们获取到了 poolLocal。
就回到了我们从中取值的过程。
在取对象的过程中,我们仍然会面临:
既不能从 private 取、也不能从 shared 中取得尴尬境地。
这时候就来到了 getSlow()。
*/
// 从其他P的共享缓冲区偷取 obj
func (p *Pool) getSlow() (x interface{}) {
size := atomic.LoadUintptr(&p.localSize) // 获取当前 poolLocal 的大小
local := p.local // 获取当前 poolLocal
// 先固定 当前P,并取得当前的 P.id 来从其他 P 中偷值 (obj),
// 那么我们需要先获取到其他 P 对应的 poolLocal。
// 假设 size 为数组的大小,local 为 p.local,那么尝试遍历其他所有 P:
// 获取 P.id
// 从其他 proc (poolLocal) 偷 一个对象
pid := runtime_procPin()
runtime_procUnpin()
for i := 0; i < int(size); i++ {
// 获取目标 poolLocal, 引入 pid 保证不是自身
l := indexLocal(local, (pid+i+1)%int(size))
// 对目标 poolLocal 加锁,用于访问 share 区域
l.Lock()
// steal 一个缓存对象
last := len(l.shared) - 1
if last >= 0 {
x = l.shared[last]
l.shared = l.shared[:last]
l.Unlock()
break
}
l.Unlock()
}
return x
}
// pin 会将当前 goroutine 订到 P 上, 禁止抢占(preemption) 并从 poolLocal 池中返回 P 对应的 poolLocal
// 调用方必须在完成取值后调用 runtime_procUnpin() 来取消禁止抢占。
func (p *Pool) pin() *poolLocal {
/***
pin() 首先会调用运行时实现获得当前 P 的 id,
将 P 设置为禁止抢占。然后检查 pid 与 p.localSize 的值
来确保从 p.local 中取值不会发生越界。如果不会发生,
则调用 indexLocal() 完成取值。否则还需要继续调用 pinSlow() 。
*/
// 返回当前 P.id PID
// 并将 P设置为 禁止抢占
pid := runtime_procPin()
// 在 pinSlow 中会存储 localSize 后再存储 local,因此这里反过来读取
// 因为我们已经禁用了抢占,这时不会发生 GC
// 因此,我们必须观察 local 和 localSize 是否对应
// 观察到一个全新或很大的的 local 是正常行为
s := atomic.LoadUintptr(&p.localSize) // 获取当前 poolLocal 的大小
l := p.local // 获取当前 poolLocal
// 因为可能存在动态的 P(运行时调整 P 的个数)procresize/GOMAXPROCS
// 如果 P.id 没有越界,则直接返回 PID
/**
具体的逻辑就是首先拿到当前的pid,
然后以pid作为index找到local中的poolLocal,
但是如果pid大于了localsize,
说明当前线程的poollocal不存在,就会新创建一个poolLocal
*/
if uintptr(pid) < s {
// 说明空间已分配好,直接返回
return indexLocal(l, pid)
}
// 没有结果时,涉及全局加锁
// 例如重新分配数组内存,添加到全局列表
return p.pinSlow()
}
func (p *Pool) pinSlow() *poolLocal {
/**
因为需要对全局进行加锁,pinSlow() 会首先取消 P 的不可抢占,然后使用 allPoolsMu 进行加锁
*/
// 在互斥锁下重试。
// 固定时无法锁定互斥锁。
// 这时取消 P 的禁止抢占,因为使用 mutex 时候 P 必须可抢占
runtime_procUnpin()
// 加锁
allPoolsMu.Lock()
defer allPoolsMu.Unlock()
// 当锁住后,再次固定 P 取其 id
pid := runtime_procPin()
// 并再次检查是否符合条件,因为可能中途已被其他线程调用
// 当再次固定 P 时 poolCleanup 不会被调用
s := p.localSize
l := p.local
/**
具体的逻辑就是首先拿到当前的pid,
然后以pid作为index找到local中的poolLocal,
但是如果pid大于了localsize,
说明当前线程的poollocal不存在,就会新创建一个poolLocal
*/
if uintptr(pid) < s {
return indexLocal(l, pid)
}
// 如果数组为空,新建
// 将其添加到 allPools,垃圾回收器从这里获取所有 Pool 实例
if p.local == nil {
allPools = append(allPools, p)
}
// 根据 P 数量创建 slice,如果 GOMAXPROCS 在 GC 间发生变化
// 我们重新分配此数组并丢弃旧的
size := runtime.GOMAXPROCS(0)
local := make([]poolLocal, size)
// 将底层数组起始指针保存到 p.local,并设置 p.localSize
atomic.StorePointer(&p.local, unsafe.Pointer(&local[0])) // store-release
atomic.StoreUintptr(&p.localSize, uintptr(size)) // store-release
// 返回所需的 pollLocal
return &local[pid]
}
// 实现缓存清理
// 当 stop the world (STW) 来临,在 GC 之前会调用该函数
func poolCleanup() {
// 该函数会注册到运行时 GC 阶段(前),此时为 STW 状态,不需要加锁
// 它必须不处理分配且不调用任何运行时函数,防御性的将一切归零,有以下两点原因:
// 1. 防止整个 Pool 的 false retention
// 2. 如果 GC 发生在当有 goroutine 与 l.shared 进行 Put/Get 时,它会保留整个 Pool.
// 那么下个 GC 周期的内存消耗将会翻倍。
// 遍历所有 Pool 实例,接触相关引用,交由 GC 进行回收
for i, p := range allPools {
// 解除引用
allPools[i] = nil
// 遍历 p.localSize 数组
for i := 0; i < int(p.localSize); i++ {
// 获取 poolLocal
l := indexLocal(p.local, i)
// 清理 private 和 shared 区域
l.private = nil
for j := range l.shared {
l.shared[j] = nil
}
l.shared = nil
}
// 设置 p.local = nil 除解引用之外的数组空间
// 同时 p.pinSlow 方法会将其重新添加到 allPool
p.local = nil
p.localSize = 0
}
// 重置 allPools,需要所有 p.pinSlow 重新添加
allPools = []*Pool{}
}
var (
// allPools 的锁?
allPoolsMu Mutex
// 所有P的 pool 队列?
allPools []*Pool
)
/**
pool创建的时候是不能指定大小的,
所有sync.Pool的缓存对象数量是没有限制的(只受限于内存),
因此使用sync.pool是没办法做到控制缓存对象数量的个数的。
另外sync.pool缓存对象的期限是很诡异的,
先看一下src/pkg/sync/pool.go里面的一段实现代码。
*/
func init() {
/***
可以看到pool包在init的时候注册了一个poolCleanup函数,
它会清除所有的pool里面的所有缓存的对象,
该函数注册进去之后会在每次gc之前都会调用,
因此sync.Pool缓存的期限只是两次gc之间这段时间。
例如我们把上面的例子改成下面这样之后,输出的结果将是0 0。
a := p.Get().(int)
p.Put(1)
runtime.GC()
b := p.Get().(int)
fmt.Println(a, b)
正因gc的时候会清掉缓存对象,也不用担心pool会无限增大的问题。
*/
runtime_registerPoolCleanup(poolCleanup)
/**
可以看到在init的时候注册了一个PoolCleanup函数,
他会清除掉sync.Pool中的所有的缓存的对象,
这个注册函数会在每次GC的时候运行,
所以【sync.Pool中的值只在两次GC中间的时段有效】。
通过以上的解读,我们可以看到,Get方法并不会对获取到的对象值做任何的保证,
因为放入本地池中的值有可能会在任何时候被删除,
但是不通知调用者。放入共享池中的值也有可能被其他的goroutine偷走。
所以对象池比较适合用来存储一些临时切状态无关的数据,
但是不适合用来存储数据库连接的实例,以及 net conn 等,
因为存入对象池重的值有可能会在垃圾回收时被删除掉,
这违反了数据库连接池建立的初衷。
*/
}
/** 根据当前 pid 作为索引,和localPool的头指针,去load localPool */
func indexLocal(l unsafe.Pointer, i int) *poolLocal {
/**
在这个过程中我们可以看到在运行时调整 P 的大小的代价。
如果此时 P 被调大,而没有对应的 poolLocal 时,
必须在取之前创建好,从而必须依赖全局加锁,
这对于以性能著称的池化概念是比较致命的,因此这也是 pinSlow 的由来。
*/
// 简单的通过 p.local 的头指针与索引来第 i 个 pooLocal
lp := unsafe.Pointer(uintptr(l) + uintptr(i)*unsafe.Sizeof(poolLocal{}))
return (*poolLocal)(lp)
}
// Implemented in runtime.
// 定义在 runtime 包中, src/runtime/mgc.go 的 sync_runtime_registerPoolCleanup()
func runtime_registerPoolCleanup(cleanup func())
// 定义在 runtime 包中, src/runtime/proc.go 的 sync_runtime_procPin()
func runtime_procPin() int
// 定义在 runtime包中, src/runtime/proc.go 的 sync_runtime_procUnpin()
func runtime_procUnpin()
首先,我们来说下 Pool的结构:

可以看出来,里头只有三个主要的字段一个代表 底层存储队列的首指针;一个代表底层队列的大小;一个代表存储了new一个新的对象的函数实现。而真正存储对象的底层其实是 poolLocalInternal:
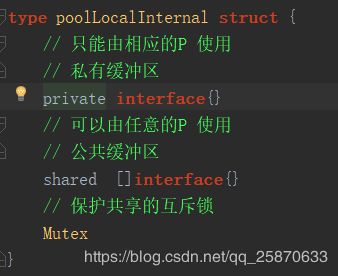
可以看到在 poolLocalInternal 中其实分了两块存储,一块为私有的,一块为共有的,私有的里头的对象只能有当前G访问,共有的是可以被其他G偷走的。
先看下Pool的使用:
func main() {
defer debug.SetGCPercent(debug.SetGCPercent(-1))
var count int32
newfun := func() interface{} {
return atomic.AddInt32(&count, 1)
}
pool := sync.Pool{New: newfun}
v1 := pool.Get()
fmt.Printf("v1 :%v\n", v1)
pool.Put(9)
pool.Put(10)
pool.Put(11)
pool.Put(12)
v2 := pool.Get()
fmt.Printf("v2 :%v\n", v2)
debug.SetGCPercent(100)
runtime.GC()
v3 := pool.Get()
fmt.Printf("v3 :%v\n", v3)
pool.New = nil
v4 := pool.Get()
fmt.Printf("v4 :%v\n", v4)
}
过多的原理都写在了注释里了,下面我们只来看一看流程即可。
Put:

Get:
以上,就是 sync 包中所有的库的源码讲解,主要func的讲解部分全部在代码的注释中,所以不做过多的赘述了!欢迎各路大神的批评和鞭策~