DFSMN-SAN WITH PERSISTENT MEMORY MODEL FOR AUTOMATIC SPEECH RECOGNITION翻译
摘要
self-attention网络(SAN)已被引入自动语音识别(ASR)中,并由于其捕获长期依赖的优秀能力而获得了最先进的性能。关键要素之一是可以在整个话语水平上有效执行的self-attention机制。在本文中,我们尝试调查是否可以利用超出整体话语水平的更多信息并从中受益。我们提出将具有增强记忆能力的self-attention层应用到ASR。具体而言,我们首先提出一种变体模型体系结构,该结构将深度前馈序列记忆网络(Deep Feed-Forward Sequential Memory Network,DFSMN)与self-attention层相结合,形成了比单独self-attention网络更好的baseline模型。然后,我们提出并比较了添加到self-attention层中的两种附加记忆结构。在大规模LVCSR任务上进行的实验表明,在四个单独的测试集上,DFSMN-SAN体系结构的字符错误率(CER)相对于普通SAN编码器减少了5%。更重要的是,额外的记忆结构可进一步将CER减少5%至11%的相对水平。
1.介绍
在多个NLP任务中,transformer模型已被成功应用,并被证明比循环神经网络(例如LSTM)更有效。其中包含两个关键要素:正弦位置编码和self-attention机制,这可在输入单词嵌入时编码上下文。最近,还积极研究了transformer模型及其变体以进行语音识别。为了更好地用于ASR建模,transformer架构需要进行一些修改。先前的工作总结了一些关键点:
首先,由于语音发声通常持续几秒钟,而语音帧是使用几毫秒的窗口提取的,因此对声音输入帧进行下采样以扩大时间范围始终是有益的。一些模型体系结构的变体使用TDNN或BiLstm作为后处理模块以提取self-attention的高级特征。
其次,同时使用CTC损失以及在聆听,参加和拼写(LAS)框架的transformer编码器是有效的。在[7]中,CTC损失用于优化ASR的transformer编码器结构。在[8,5]中,在普通话语音识别任务的背景下检查了原始transformer的整个编码器-解码器结构。
最后,对于self-attention网络,一个普遍的观察是,选择上下文的时间越长,可以获得的性能越好。在[9]中,为了支持在线语音识别,提出了一种跳块机制。实验结果表明,与整个话语环境相比,跳块总是导致性能下降。在这项工作中,优先考虑探索所有可能的信息以提高语音识别的准确性,而在线语音识别(其中延迟是需要考虑的重要因素)将不在研究范围内。
为了基于self-attention层进行进一步的改进,自然的想法是在整个话语上下文长度之外探索更多信息。最近,在[10]中,作者提出通过引入一个新的层来增强持久性记忆,从而将self-attention和前馈子层合并为一个统一的注意力层。已经表明,键值向量形式的附加持久性记忆块存储了一些不依赖于上下文的全局信息。这项工作为实现上述动机提供了启示。
在本文中,我们首先探索了模型体系结构的变体,它结合了DFSMN和self-attention层。实验表明,该模型架构优于标准的transformer编码器。然后,我们在其self-attention层上应用记忆增强方法。我们进一步提出了一种改进的记忆块结构并进行了比较实验。我们的贡献如下。 首先,我们作进一步的验证,对于低层来说,不需要self-attention层,只需几个添加到高层的self-attention层即可以实现较好性能。 其次,我们将增强持久记忆应用于ASR模型,并提出了一种改进的记忆块结构变体,该变体在识别性能上更紧凑且更具竞争力。 所有实验都是在大规模训练数据上进行的,即超过10,000小时。
2.模型结构
深度前馈序列记忆网络提供了一种非循环架构来对长期依赖性进行建模。与self-attention网络相比,FSMN的层结构更简单,并且更专注于相邻帧的局部范围,而忽略了序列不同位置的相对依赖性。多头self-attention层可以通过从整个序列的上下文中收集信息来对相对依赖性进行建模。有鉴于此,我们探索了FSMN层和多头self-attention层的结合。我们相信,所提出的体系结构可以在建模效率和捕获长期相对依赖性之间取得更好的折衷。
2.1 DFSMN
DFSMN从概念上可以看作是标准前馈完全连接的神经网络,并带有一些类似于FIR的滤波器。类似于FIR的滤波器的公式采用以下形式:
h t = ∑ i = 0 N 1 a i ⋅ h t − i + ∑ j = 1 N 2 b j ⋅ h t + j (1) h_t=\sum^{N_1}_{i=0}a_i\cdot h_{t-i}+\sum^{N_2}_{j=1}b_j\cdot h_{t+j}\tag{1} ht=i=0∑N1ai⋅ht−i+j=1∑N2bj⋅ht+j(1)
其中 N 1 N_1 N1和 N 2 N_2 N2分别表示反向顺序和前向顺序。从等式1我们可以观察到DFSMN中可学习的类似于FIR的滤波器可用于将长上下文信息编码为固定大小的表示形式( h t h_t ht),这使DFSMN捕获了长期依赖性。但是,在此体系结构中忽略了不同位置的相对依赖性。
2.2 SAN
self-attention网络具有两个子模块,包括一个多头注意力层和一个位置前馈层。此外,在self-attention和前馈层之后都应用了dropout,残差连接和层归一化。self-attention的计算过程公式如下:
S e l f A t t n ( Q , K , V ) = s o f r m a x ( Q K d k ) V (2) SelfAttn(Q,K,V)=sofrmax(\frac{QK}{\sqrt{d_k}})V\tag{2} SelfAttn(Q,K,V)=sofrmax(dkQK)V(2)
M u l t i H e a d ( Q , K , V ) = C o n c a t ( h e a d 1 , h e a d 2 , … , h e a d h ) W O (3) MultiHead(Q,K,V)=Concat(head_1,head_2,\dots,head_h)W^O\tag{3} MultiHead(Q,K,V)=Concat(head1,head2,…,headh)WO(3)
h e a d i = S e l f A t t n ( Q W i Q , K W i K , V W i V ) (4) head_i=SelfAttn(QW^Q_i,KW^K_i,VW^V_i)\tag{4} headi=SelfAttn(QWiQ,KWiK,VWiV)(4)
其中 W k W_k Wk, W v W_v Wv和 W q W_q Wq是大小为 d k × d d_k\times d dk×d的键,值和查询矩阵。 d k = d / h d_k=d/h dk=d/h, h h h是self-attention层中的头数。通过关注来自 W i Q W_i^Q WiQ, W i K W_i^K WiK和 W i V W_i^V WiV映射的不同子空间的信息来执行多头注意力。 W O W^O WO是输出权重矩阵。很明显,self-attention可以从不同位置的不同表示中探索信息。换句话说,该体系结构能够对相对依赖性进行建模。
2.3 DFSMN-SAN
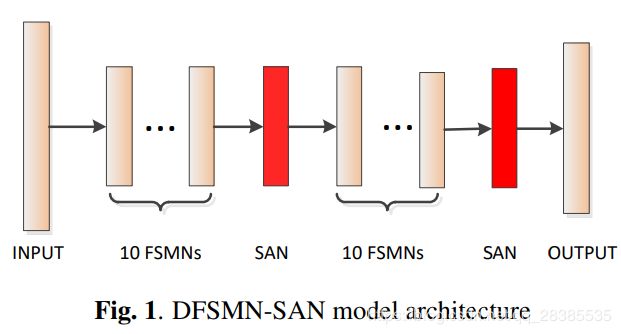
我们提出了一种DFSMN-SAN模型,其中多头self-attention层(图1中的红色块)与DFSMN模型相结合。 与[2]中TDNN和SAN的组合类似,我们认为DFSMN和SAN的组合可以在建模效率和捕获长期相对依赖关系之间实现更好的折衷。根据经验评估了两种类型的组合。第一种是在DFSMN模型的末尾简单地堆叠所有的self-attention层,第二种是使用嵌入方式将self-attention层插入DFSMN。在我们的试验性实验中,我们发现后者始终表现更好。因此,如图1所示,在本文中使用了嵌入类型的组合。在每10个连续的FSMN层之后,插入一个self-attention层。
3.具有持久记忆的增强self-attention层
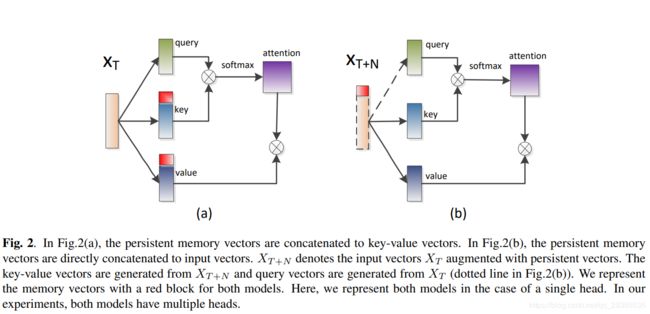
在本节中,我们进一步提出将具有持久记忆的增强self-attention层应用于DFSMN-SAN模型。其背后的动机是研究是否可以利用超出整个话语水平的更多信息并从中受益。这些记忆向量从训练开始就被随机初始化,并以整个训练语料库进行更新。我们相信这些记忆向量可以学习和存储一些对ASR任务有用的全局信息。在这里,我们提出了一种不同于[12]的新的记忆块结构。两种不同类型的记忆块结构描述如下。
3.1 key-value记忆结构
图2(a)展示了由[12]提出的具有持久记忆向量的增强self-attention层。更确切地说,这些持久记忆向量是一组 N N N对key-value向量,它们堆叠在两个 d k × N d_k\times N dk×N维矩阵 M k M_k Mk和 M v M_v Mv中。
这些持久记忆向量只是简单地连接到键值向量池中:
K m = C o n c a t ( [ W k x 1 , … , W k x T ] , M k ) (5) K_m=Concat([W_kx_1,\dots,W_kx_T],M_k)\tag{5} Km=Concat([Wkx1,…,WkxT],Mk)(5)
V m = C o n c a t ( [ W v x 1 , … , W v x T ] , M v ) (6) V_m=Concat([W_vx_1,\dots,W_vx_T],M_v)\tag{6} Vm=Concat([Wvx1,…,WvxT],Mv)(6)
S e l f A t t n ( Q , K m , V m ) = s o f t m a x ( Q K m d k ) V m (7) SelfAttn(Q,K_m,V_m)=softmax(\frac{QK_m}{\sqrt{d_k}})V_m\tag{7} SelfAttn(Q,Km,Vm)=softmax(dkQKm)Vm(7)
其中对应于记忆向量的位置编码等于零。 X T = [ x 1 , . . . , x T ] X_T=[x_1,...,x_T] XT=[x1,...,xT]。 K m K_m Km表示key向量与对应的 N N N个记忆向量的串联。与一般的多头self-attention层相似,持久记忆向量被拆分为多个头,并且在头之间不共享参数。
3.2 输入嵌入记忆结构
在本文中,我们提出了一种新型的记忆结构,如图2(b)所示。 与key-value记忆结构不同,这些持久记忆向量直接连接到输入向量:
K m = C o n c a t ( [ W k x 1 , … , W k x T ] , [ W k M 1 , … , W v M N ] ) (8) K_m=Concat([W_kx_1,\dots,W_kx_T],[W_kM_1,\dots,W_vM_N])\tag{8} Km=Concat([Wkx1,…,WkxT],[WkM1,…,WvMN])(8)
V m = C o n c a t ( [ W v x 1 , … , W v x T ] , [ W v M 1 , … , W v M N ] ) (9) V_m=Concat([W_vx_1,\dots,W_vx_T],[W_vM_1,\dots,W_vM_N])\tag{9} Vm=Concat([Wvx1,…,WvxT],[WvM1,…,WvMN])(9)
其中 [ M 1 , . . . , M N ] [M_1,...,M_N] [M1,...,MN]表示持久记忆向量。显然, K m K_m Km和 V m V_m Vm共享相同的持久记忆向量。也就是说,与key-value记忆结构相比,我们的参数更少。
4.实验设置
4.1 训练环境
在所有实验中使用的特征向量是40维log-Mel滤波器组能量特征,并附加了一阶和二阶导数。Log-mel滤波器组的能量特征以25ms的窗口进行计算,并每10ms移动一次。我们堆叠8个连续的帧,并输每隔3个输入入帧进行二次采样。对每个帧应用全局均值和方差归一化。所有实验均基于CTC学习框架。 我们使用基于CI音节的声学建模方法进行CTC学习。CTC学习的目标标签定义为包括1394个普通话音节,39个英文音素和一个空白字符。字符错误率结果在测试集上进行测量。我们使用经过修剪的5-gram语言模型。所有系统都使用包含数百万个单词的词汇表。通过使用加权有限状态换器(WFST),以集束搜索算法执行解码。
4.2 数据集
4.3 声学模型
对于第一个实验,我们展示了DFSMN,self-attention和DFSMN-SAN模型的工作。DFSMN系统使用1024个隐藏单元的30个DFSMN组件,每个组件具有512个单元的映射层。self-attention包含10个多头self-attention子层,其大小与30个DFSMN模型相当。我们将模型维数设置为 d = 512 d=512 d=512,头数 h = 8 h=8 h=8。DFSMN-SAN模型由30个DFSMN组件和3个多头self-attention子层组成。
对于第二个实验,我们通过使用持久性记忆增强self-attention子层来改进DFSMN-SAN。我们将键值记忆向量的头数设置为8。位置嵌入在所有头之间共享。
为了稳定地进行CTC学习,我们将梯度剪裁为 [ − 1.0 , 1.0 ] [-1.0,1.0] [−1.0,1.0]。我们使用Kaldi工具包来训练模型,并且使用BMUF优化和8个Tesla P40 GPU以分布式方式训练所有模型。