Python + Selenium 自动发布文章(一):开源中国
Python + Selenium 自动发布文章系列:
Python + Selenium 自动发布文章(一):开源中国
Python + Selenium 自动发布文章(二):简书
Python + Selenium 自动发布文章(三):CSDN
Python + Selenium 自动发布文章(四):加入 bat 脚本
写在开始
还是说说出这个系列的起因吧。之前写完或是修改了Markdown文章,我还分别需要在多个平台进行发布或是更新维护这些内容,这些平台目前包括我的博客、简书、开源中国和CSDN,其实早就想过用比较自动化的形式来解决,无奈有技术、时间、精力等各方面原因的限制。废话不多说吧,直奔今天的主题,本文主要介绍如何用Python和Selenium写(发)开源中国的博客。
准备说明
- 一定的Python基础知识
- 一定的Selenium相关知识
- 开发环境说明:Python v3.6.4,Selenium v3.8.1
PS:Selenium操纵浏览器是依赖于浏览器驱动程序的,下面贴出的是谷歌和火狐浏览器驱动程序的下载地址。
| Chrome ( chromedriver ) | Firefox ( geckodriver ) |
|---|---|
| 官方下载 | 官方下载 |
| 淘宝镜像 | 淘宝镜像 |
| 备用下载 | 备用下载 |
使用说明
下面是示例代码中用到的auto.md文件内容,自动发布文章也还是需要遵循一定的规则,所以以下有几点是必须说明的:
1. [//]: # ()是Markdown注释的一种写法,注释内容写在小括号内;
1.< !-- -->是HTML注释的一种写法,由于Markdown写法的注释有兼容性问题,所以在此调整一下(注意<和!之间实际上是没有空格的,又是为了兼容某些平台的Markdown识别,好想o(╥﹏╥)o);
2. auto.md中间注释部分的内容,用于匹配获得这几个平台的分类和标签等信息;
3. -->\n仅用于划分并匹配获取正文部分内容。
---
title: 自动发布测试文章
date: 2018-05-16
categories:
- 测试
author: Jared Qiu
tags:
- 标签
cover_picture: https://images.unsplash.com/photo-1520095972714-909e91b038e5?ixlib=rb-0.3.5&ixid=eyJhcHBfaWQiOjEyMDd9&s=1110ecf3ce9e4184d4676c54dec0032d&auto=format&fit=crop&w=500&q=60
top: 1
---
### 自动发布
自动发布文章。。
### 参考地址
> [happyJared - 博客](https://blog.mariojd.cn/)
下面的截图是开源中国撰写博客的界面(记得设置默认编辑器为Markdown)。
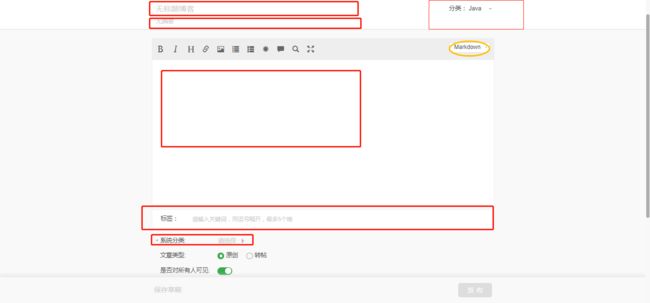
从上图可以看到,在开源中国写一篇博客,需要依次录入标题、摘要(可选)、内容、标签(可选)和选择分类(自定义的)、系统分类等信息。
结合auto.md的内容进行分析,相信用过hexo的朋友都比较清楚,标题一般定义在title处;摘要因为是可选的,所以这里先忽略不处理;正文内容我们通过匹配-->\n就可以获取。剩下标签,自定义分类和系统分类,按规则需要提前定义在注释里,分别对应self_tags,self_category和osChina_sys_category。
代码说明
main.py:程序入口类,主要负责正则匹配解析Markdown和调用post发布文章
import re
import oschina
import linecache
class Main(object):
# init
def __init__(self, file):
self.title = ''
self.content = ''
self.category = ''
self.tags = ''
# OsChina的系统分类, 设个默认值
self.osChina_sys_category = '编程语言'
# CSDN的文章分类, 设个默认值
self.csdn_article_category = '原创'
# CSDN的博客分类, 设个默认值
self.csdn_blog_category = '后端'
self.read_file(file)
# 读取MD中的title, content, self_category, self_tags, osChina_sys_category, csdn_article_category, csdn_blog_category
def read_file(self, markdown_file):
self.title = linecache.getline(markdown_file, 2).split('title: ')[1].strip('\n')
with open(markdown_file, 'r', encoding='UTF-8') as f:
self.content = f.read().split('-->\n')[1]
# 重置文件指针偏移量
f.seek(0)
for line in f.readlines():
if re.search('self_category: ', line) is not None:
self.category = line.split('self_category: ')[1].strip('\n')
elif re.search('self_tags: ', line) is not None:
self.tags = line.split('self_tags: ')[1].strip('\n')
elif re.search('osChina_sys_category: ', line) is not None:
self.osChina_sys_category = line.split('osChina_sys_category: ')[1].strip('\n')
elif re.search('csdn_article_category: ', line) is not None:
self.csdn_article_category = line.split('csdn_article_category: ')[1].strip('\n')
elif re.search('csdn_blog_category: ', line) is not None:
self.csdn_blog_category = line.split('csdn_blog_category: ')[1].strip('\n')
if __name__ == '__main__':
md_file = 'auto.md'
print("Markdown File is ", md_file)
timeout = 10
main = Main(md_file)
# 开源中国
osChina = oschina.OsChina()
osChina.post(main, timeout)
authorize.py:目前仅实现了用qq进行授权登录的方法
from selenium.webdriver.support.wait import WebDriverWait
# QQ授权登录, 使用前提是QQ客户端在线
def qq(driver, timeout):
# 切换到最新打开的窗口
window_handles = driver.window_handles
driver.switch_to.window(window_handles[-1])
print('qq authorize title is ', driver.title)
# 切换iframe
iframe = WebDriverWait(driver, timeout).until(lambda d: d.find_element_by_id('ptlogin_iframe'))
driver.switch_to.frame(iframe)
# 点击头像进行授权登录
login = WebDriverWait(driver, timeout).until(lambda d: d.find_element_by_xpath('//*[@id="qlogin_list"]/a[1]'))
login.click()
oschina.py:这个是开源中国自动写(发)博客的核心类
import authorize
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.common.action_chains import ActionChains
# 开源中国
class OsChina(object):
@staticmethod
def post(main, timeout):
# 1.账号密码
account = 'xxx'
password = 'xxx'
# 2.跳转登陆
login = 'https://www.oschina.net/home/login'
driver = webdriver.Chrome()
driver.get(login)
# 3.窗口最大化
driver.maximize_window()
# 4.使用QQ授权登录
driver.find_element_by_xpath('/html/body/section/div/div[2]/div[2]/div/div[2]/a[4]').click()
authorize.qq(driver, timeout)
# 4.使用账号密码登陆
# driver.find_element_by_id('userMail').send_keys(account)
# driver.find_element_by_id('userPassword').send_keys(password)
# driver.find_element_by_xpath('//*[@id="account_login"]/form/div/div[5]/button').click()
# 5.移到"我的空间", 点击"我的博客"
my_space = WebDriverWait(driver, timeout).until(lambda d: d.find_element_by_xpath('//*[@id="MySpace"]'))
ActionChains(driver).move_to_element(my_space).perform()
driver.find_element_by_xpath('/html/body/header/div/div[2]/div/div[2]/div/ul/li[4]/a').click()
# 6.点击"写博客"
write_blog = WebDriverWait(driver, timeout).until(
lambda d: d.find_element_by_xpath('/html/body/div/div/div/div/div[1]/div[1]/div[4]/a'))
write_blog.click()
# 7.选择自定义分类, 系统分类
classify = WebDriverWait(driver, timeout).until(lambda d: d.find_elements_by_class_name('select-opt'))
for c in classify:
html = c.get_attribute('innerHTML')
if main.category in html:
if 'span' in html:
# 自定义分类
data_value = c.get_attribute('data-value')
js = 'document.getElementById("self_sort").value=' + data_value
driver.execute_script(js)
else:
if main.osChina_sys_category == html:
# 系统分类
data_value = c.get_attribute('data-value')
js = 'document.getElementById("sys_sort").value=' + data_value
driver.execute_script(js)
# 8.填写标题, 内容和标签
title = driver.find_element_by_xpath('//*[@id="title"]')
title.clear()
title.send_keys(main.title)
content = driver.find_element_by_id('mdeditor')
content.clear()
content.send_keys(main.content)
tags = driver.find_element_by_xpath('//*[@id="blog-form"]/div[2]/div/div[3]/div[1]/div[2]/div[2]/input')
tags.clear()
tags.send_keys(main.tags)
# 9.保存草稿
driver.find_element_by_xpath('//*[@id="blog-form"]/div[3]/div/button[1]').click()
# 9.发布文章
# driver.find_element_by_xpath('//*[@id="blog-form"]/div[3]/div/button[2]').click()
从代码注释可以看到,目前支持账号密码和QQ授权两种方式登录,支持保存草稿或发布文章操作。
运行效果
多说无益,来看看运行效果图吧,测试一下保存草稿。
写在最后
总之,在开源中国自动写文章的思路大概就这样,不过这也绝对不是唯一的办法,大家完全可以根据代码自己做调整,而且网页的结构可能会发生改变,这里也不敢保证程序可以一直正常运行下去。好了,下一篇介绍如何在简书自动写(发)文章。