Linux性能优化-网络基础
目录
网络模型
Linux网络栈
Linux网络收发流程
性能指标
套接字信息
协议栈统计信息
网络吞吐和PPS
连通性和延迟
C10K
I/O模型优化
工作模型优化
C1000K
C10M
参考
网络是一种把不同计算机或者网络设备连接到一起的技术,它本质上是一种进程间通讯方式,特别是跨系统的进程间通讯,必须要通过网络才能进行,随着高并发,分布式,云计算,微服务等技术普及,网络的性能也变得越来越重要
多台服务器通过网卡,交换机,路由器等网络设备连接到一起,构成了相互连接的网络
网络模型
OSI网络模型,也就是七层模型,来自国际标准化组织制定的
开放式系统互联通讯参考模型 Open System Interconnection Reference Model,简称OSI网络模型
每个层的功能如下
- 应用层,负责为应用程序提供统一的接口
- 表示层,负责把数据转换成兼容接收系统的格式
- 会话层,负责维护计算机之间的通信连接
- 传输层,负责为数据加上传输头,形成数据包
- 网络层,负责数据的路由和转发
- 数据链路层,负责MAC寻址,错误侦测,改错
- 物理层,负责在物理网络中传输数据帧
OSI模型太复杂了,Linux中使用的是一个更实用的四层模型,即TCP/IP网络模型
- 应用层,负责向用户提供一组应用程序,如HTTP,FTP,DNS等
- 传输层,负责端到端的通讯,如TCP,UDP等
- 网络层,负责网络包的封装,寻址和路由,如IP,ICMP等
- 网络接口层,负责网络包在物理网络中的传输,如MAC寻址,错误侦测,通过网口传输网络帧等
TCP/IP和OSI模型的关系如下
Linux网络栈
有了TCP/IP模型后,在进行网络传输时,数据包就会按照协议栈,对上一层发来的数据进行逐层处理,然后封装上该层的协议头,再发送给下一层
网络包在每一层的处理逻辑,都取决于各层采用的网络协议,比如在应用层,一个提供REST API的应用,可以使用HTTP协议,把它需要传输的JSON数据封装到HTTP协议中,然后向下传递给TCP层
封装是在原来的负载前后,增加固定格式的元数据,原始的负载数据不会被修改
下图是程序数据在每个层的封装格式
各封装层含义
传输层再应用程序数据前面增加TCP头
网络层在TCP数据包前增加了IP头
网络接口层在IP数据包前后分别增加了帧头和帧尾
这些新增的头部和尾部,都按照特定的协议格式填充
这些新增的头部和尾部,增加了网络包的大小,但物理链路中并不能传输任意大小的数据包,网络接口配置的最大传输单元MTU,就规定了最大的IP包大小,常见的以太网中MTU默认值是1500,也是Linux的默认值
一旦网络包超过MTU大小,就会在网络层分片,以保证分片后的IP包不大于MTU值,显然MTU越大,需要的分包也就越少,网络吞吐能力就约好
Linux之中的网络协议栈如下图

通过上图可以发现
最上层的应用程序,需要通过系统调用,来跟套接字接口进行交互
套接字的下面,就是我们前面提到的传输层,网络层和网络接口层
最底层,则是网络驱动程序以及物理网卡设备
网卡是发送和接收网络包的基本设备,在系统启动过程中,网卡通过内核中的网卡驱动程序注册到系统中,而在网络收发过程中,内核通过中断跟网卡进行交互
结合Linux网络栈,可以看出,网络包的处理非常复杂,所以网卡硬件中断只处理最核心的网络数据读取或发送,而协议栈中的大部分逻辑,都会放到软中断中处理
Linux网络收发流程
这里以武力网卡为例,Linux还支持众多的虚拟网络设备,而它们的网络收发流程会有一些差别
网络包的接收流程
当一个网络帧到达网卡后,网卡会通过DMA方式,把这个网络包放到收包队列中,然后通过硬中断,告诉中断处理程序已收到了网络包
接着,网卡中断处理程序会为网络帧分配内核数据结构sk_buff,并将其拷贝到sk_buff缓冲区中,然后再通过软中断,通知内核收到了新的网络帧
接下来,内核协议栈从缓冲区中取出网络帧,并通过网络协议栈,从下到上逐层处理这个网络帧。比如
链路层检查报文的合法性,找出上层协议的类型,IPv4还是IPv6,再去掉帧头,帧尾,然后交给网络层
网络层取出IP头,判断网络包下一步的走向,是交给上层处理还是转发,当网络层确认这个包是要发送到本机后,就会取出上层协议类型TCP或UDP,去掉IP头,再交给传输层处理
传输层取出TCP头的或者UDP头后,根据<源IP,源端口,目的IP,目的端口>四元组作为标识,找出对应的Socket,并把数据拷贝到Socket的接收缓存中
最后,应用程序就可以使用Socket,读取到新接收到的数据了
下图是网络的收发流程
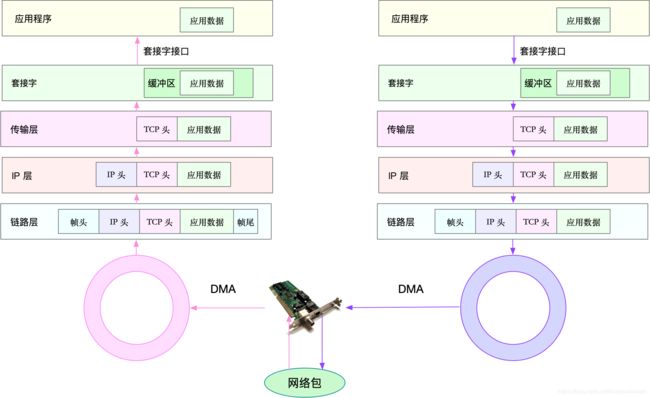
网络包的发送流程
网络包的发送流程就是上图的右半部分,发送的方向,正好跟接收方向相反
首先,应用程序调用Sockeet API,比如sendmsg发送网络包
由于这是一个系统调用,所以会陷入到内核态的套接字层中,套接字层会把数据包放到Socket发送缓冲区中
之后,网络协议栈从Socket发送缓冲区中,取出数据包,再按照TCP/IP栈,从上层到下面处理,如传输层和网络层,分别为其增加TCP头和IP头,执行路由查找确认下一跳的IP,并按照MUT大小分片
分片后的网络包,再送到网络接口层,进行物理地址寻址,以找到下一跳的MAC地址,然后添加帧头和帧尾,放到发送包队列中,这一切完成后,会有软中断通知驱动程序,发包队列中有新的网络帧需要发送
最后,驱动程序通过DMA,从发包队列中读取网络帧,并通过物理网络把它发送出去
性能指标
通常有带宽,吞吐量,延迟,PPS(Packet Per Second)等指标衡量网络的性能
- 带宽,表示链路的最大传输速率,单位通常是b/s(比特/秒)
- 吞吐量,表示没丢包时的最大数据传输速率,单位通常为b/s(比特/秒),或者B/s(字节/秒),吞吐量受带宽限制,而吞吐量/带宽,就是该网络的使用率
- 延迟,表示从网络请求发出后,一直到收到远端响应,所需要的时间延迟,在不同场景中,这一指标可能会有不同含义,如可以表示建立连接需要的时间(TCP握手延迟),或一个数据包往返所需时间(如RTT)
- PPS,是Packet Per Second(包/秒),表示网络包围单位的传输速度,PPS通常用来评估网络的转发能力,如硬件交换机,通常可以达到线性转发(即PPS可以达到或接近理论最大值),而Linux服务器的转发则容易受到网络包大小的影响
除了这些指标
- 网络的可用性(网络能否正常通讯),
- 并发连接数(TCP连接数量),
- 丢包率(丢包百分比),
- 重传吕(重新传输的网络包比例)
等也是常用的性能指标
套接字信息
ifconfig和ip只显示了网络接口收发数据包的统计信息,但在实际的性能问题中,网络协议栈中的统计信息,我们也必须关注,可以使用netstat和ss来查看套接字,网络栈,网络接口以及路由表的信息
命令如下
# -l 表示只显示监听套接字
# -n 表示显示数字地址和端口而不是名字
# -p 表示显示进程信息
netstat -nlp | head -n 3
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 2149/sshd
# -l 表示只显示监听套接字
# -t 表示只显示TCP套接字
# -n 表示显示数字地址和端口而不是名字
# -p 表示显示进程信息
ss -ltnp | head -n 3
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 0 128 *:22 *:* users:(("sshd",pid=2149,fd=3))
netstat和ss的输出也是类似的,都展示了套接字的状态,接收队列,发送队列,本地地址,远端地址,进程PID和进程名称等
其中,接收队列(Recv-Q)和发送队列(Send-Q)需要特别关注,他们通常都应该是0,当不是0时,说明有网络包的堆积发生,还需要注意在不同套接字状态下他们的含义不同
当套接字处于连接状态Established时
- Recv-Q,表示套接字缓冲还没有被应用程序取走的字节数(即接收队列长度)
- Send-Q,表示还没有被远端主机确认的字节数(即发送队列长度)
当套接字处于监听状态Listening时
- Recv-Q,表示sync backlog的当前值
- Send-Q,表示最大的sync backlog
而syn backlog是TCP协议栈中的半连接队列长度,想应的也有一个全连接队列(accept queue),它们都维护TCP状态的重要机制
顾名思义,所谓半连接,就是还没有完成TCP三次握手的连接,连接只进行了一半,而服务器收到了客户端的SYN包后,就会把这个连接放到半连接队列中,然后再向客户端发送SYN+ACK包
而全连接,则是指服务器收到了客户端的ACK,完成了TCP三次握手,然后就会把这个连接挪到全连接队列中,这些全连接中的套接字,还需要再被accept()系统调用取走,这样服务器就会开始真正处理客户端的请求了
协议栈统计信息
使用netstat,ss也可以查看协议栈的信息
netstat -s
Ip:
1553776 total packets received
1 with invalid addresses
43881 forwarded
0 incoming packets discarded
1509894 incoming packets delivered
1131547 requests sent out
216 dropped because of missing route
Icmp:
1876 ICMP messages received
228 input ICMP message failed.
ICMP input histogram:
destination unreachable: 248
timeout in transit: 1
echo requests: 1605
echo replies: 13
timestamp request: 9
1627 ICMP messages sent
0 ICMP messages failed
ICMP output histogram:
destination unreachable: 7
echo request: 8
echo replies: 1605
timestamp replies: 7
IcmpMsg:
InType0: 13
InType3: 248
InType8: 1605
InType11: 1
InType13: 9
OutType0: 1605
OutType3: 7
OutType8: 8
OutType14: 7
Tcp:
5004 active connections openings
748 passive connection openings
183125 failed connection attempts
379 connection resets received
2 connections established
1481840 segments received
1035374 segments send out
57038 segments retransmited
16 bad segments received.
29082 resets sent
InCsumErrors: 14
Udp:
26171 packets received
3 packets to unknown port received.
0 packet receive errors
75603 packets sent
0 receive buffer errors
0 send buffer errors
UdpLite:
TcpExt:
6815 invalid SYN cookies received
183110 resets received for embryonic SYN_RECV sockets
2929 TCP sockets finished time wait in fast timer
24142 delayed acks sent
16 delayed acks further delayed because of locked socket
Quick ack mode was activated 575 times
127933 packet headers predicted
222188 acknowledgments not containing data payload received
109477 predicted acknowledgments
1007 times recovered from packet loss by selective acknowledgements
Detected reordering 409 times using SACK
67 congestion windows recovered without slow start by DSACK
28 congestion windows recovered without slow start after partial ack
TCPLostRetransmit: 831
2 timeouts in loss state
2087 fast retransmits
483 retransmits in slow start
75902 other TCP timeouts
TCPLossProbes: 984
TCPLossProbeRecovery: 39
196 SACK retransmits failed
693 DSACKs sent for old packets
1 DSACKs sent for out of order packets
742 DSACKs received
2 DSACKs for out of order packets received
12 connections reset due to unexpected data
296 connections reset due to early user close
58 connections aborted due to timeout
TCPDSACKIgnoredNoUndo: 268
TCPSpuriousRTOs: 3
TCPSackShifted: 6
TCPSackMerged: 122
TCPSackShiftFallback: 1960
TCPRcvCoalesce: 75111
TCPOFOQueue: 40947
TCPOFOMerge: 1
TCPChallengeACK: 3
TCPSYNChallenge: 3
TCPSynRetrans: 53302
TCPOrigDataSent: 570082
TCPHystartTrainDetect: 4
TCPHystartTrainCwnd: 117
TCPHystartDelayDetect: 5
TCPHystartDelayCwnd: 163
TCPKeepAlive: 399
TCPDelivered: 575112
TCPAckCompressed: 32868
IpExt:
InOctets: 865682906
OutOctets: 351744826
InNoECTPkts: 1924805
InECT0Pkts: 1941
ss -s
Total: 89 (kernel 312)
TCP: 3 (estab 2, closed 0, orphaned 0, synrecv 0, timewait 0/0), ports 0
Transport Total IP IPv6
* 312 - -
RAW 0 0 0
UDP 5 4 1
TCP 3 3 0
INET 8 7 1
FRAG 0 0 0 这些协议栈的统计信息都很直观,ss只显示已经连接,关闭,孤儿套接字等简单统计
netstat则提供更详细的网络协议栈信息
上面的netstat的输出示例,就展示了TCP协议的主动连接,被动连接,失败重试,发送和接收的分段数量等各种信息
网络吞吐和PPS
接下来,我们再来看看,如何查看系统当前的网络吞吐量和PPS,在这里,推荐使用sar,在前面CPU,内存和I/O模块中,已经多次使用到
给sar增加-n参数就可以查看网络的统计信息,如网络接口DEV,网络接口错误EDEV,TCP,UDP,ICMP等
执行下面就可以得到网络接口统计信息
sar -n DEV 1
Linux 4.20.0-1.el7.elrepo.x86_64 (iz2zege42v3jtvyj2oecuzz) 02/12/2019 _x86_64_ (1 CPU)
09:58:06 PM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s
09:58:07 PM docker0 0.00 0.00 0.00 0.00 0.00 0.00 0.00
09:58:07 PM lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00
09:58:07 PM eth0 0.99 0.99 0.05 0.51 0.00 0.00 0.00
09:58:07 PM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s
09:58:08 PM docker0 0.00 0.00 0.00 0.00 0.00 0.00 0.00
09:58:08 PM lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00
09:58:08 PM eth0 1.01 2.02 0.05 0.65 0.00 0.00 0.00
^C
比较重要的指标含义
- rxpck/s和txpck/s,分别是接收和发送的PPS,单位是包/秒
- rxkB/s和txkB/s,分别是接收和发送的吞吐量,单位是KB/秒
- rxcmp/s和txcmp/s,分别是接收和发送的压缩数据包数,单位是包/秒
- %ifutil是网络接口的使用率,即半双工模式下(rxkBs+txkB/s)/Bandwidth,而全双攻模式下为max(rxkB/s,txkB/s)/Bandwidth
其中,Bandwidth可以用ethtool来查询,它的单位通常是Gb或者Mb/是,不过注意这里是小写字母b,表示比特而不是字节,通常的网络千兆网卡,万兆网卡等,单位也都是比特,查询方式如下
ethtool eth0 | grep Speed
Speed: Unknown!
连通性和延迟
最后,通常使用ping,来测试远程主机的连通性和延迟,而这基于ICMP协议,比如下面的命令,可以测试本机到114.114.114.114 这个IP地址的连通性和延迟
ping -c 3 114.114.114.114
PING 114.114.114.114 (114.114.114.114) 56(84) bytes of data.
64 bytes from 114.114.114.114: icmp_seq=1 ttl=65 time=32.8 ms
64 bytes from 114.114.114.114: icmp_seq=2 ttl=65 time=32.8 ms
64 bytes from 114.114.114.114: icmp_seq=3 ttl=94 time=32.8 ms
--- 114.114.114.114 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2003ms
rtt min/avg/max/mdev = 32.809/32.814/32.822/0.209 msping的输出,可以分为两部分
第一部分,是每个ICMP请求的信息,包括ICMP序列号(icmp_seq),TTL(生存时间,或者跳数)以及往返延迟
第二部分,则是三次ICMP请求的汇总
比如上面示例显示,发送了3个网络包,并且接收到了3个响应,没有丢包发生,这说明测试主机到
114.114.114.114是连通的,平均往返延迟是RTT是244ms,也就是从发送ICMP开始,到接收到114.114.114.114回复的确认,总共经历244ms
C10K
最早是Dan Kegel在1999年提出来的,那时候服务器只是32位,系统是Linux2.2,只有很少内存和千兆网卡
从资源上说,对于2G内存和千兆网卡的服务器同时处理1W个请求,只要每个请求处理占用不到200K(2GB/10000)的内存和100Kbit(1000Mbit/10000)的网络带宽就可以,所以物理资源是足够的,接下来就是软件的问题,特别是网络I/O模型问题
文件I/O其实跟网络I/O模型也类似,在C10K以前,Linux中网络处理都用同步阻塞的方式,也就是每个请求都分配一个进程或现场,请求数只有100个时,这种方式没问题,但到1W个请求时,1W个进程或线程的调度,上下文切换和他们占用的内存,都会成为瓶颈
既然每个请求分配一个线程的方式不合适,为了支持1W个并发请求,这里就有两个问题需要解决
1.怎样在一个线程内处理多个请求,也就是要在一个线程内响应多个网络I/O,以前的同步阻塞方式下,一个线程只能处理一个请求,到这里不再适用,可以用费阻塞I/O或者异步I/O来处理多个网络请求
2.怎样更节省资源处理客户其你去,也就是要用更少的线程来服务这些请求
I/O模型优化
异步,费阻塞I/O的解决思路,其实就是网络编程中常用的I/O多路复用(I/O Multiplexing)
首先说下两种I/O事件通知方式,水平和触发和边缘触发,他们常用在套接字接口和文件描述符中
水平触发,只要文件描述符可以非阻塞的执行I/O,就会触发通知,应用程序可以随时检查文件描述符状态,再根据状态,进行I/O操作
边缘触发,只有在文件描述符的状态发生改变(I/O请求到达)时,才发送一次通知,这时候应用程序需要尽可能多的执行I/O,直到无法继续读写,才可以停止,如果I/O没执行完,或因为某种原因没来得及处理,这次通知也就丢失了
再看I/O多路复用的方式
1.使用费阻塞I/O和水平触发通知,比如select和poll
根据水平触发的原理,select和poll需要从文件描述符列表中,找出哪些可以执行I/O,然后进行真正的网络I/O读写,由于I/O是非阻塞的,一个县城中就可以同时监控一批套接字的文件描述符,这样就达到了单线程处理多请求的目的
这种方式的最大有限,是对应用程序友好,其API非常简单
但是,应用程序使用select和poll时,需要对这些文件描述符列表进行沦陷,当请求数多的时候就会比较耗时,并且select和poll还有一些其他的限制
select使用固定长度的位相量,表示文件描述符的集合,因此会有最大描述符数量的限制,在32位系统中,默认限制是1024,在select内部,检查套接字状态是用轮询的方式,再加上应用软件使用时的轮询,就变成了一个O(n^2)的关系
而poll改进了select的表示方式,换成了一个没有固定长度的数组,这样就没有了最大描述符数量的限制(但还会受到系统文件描述符限制),但应用程序在使用poll时,同样需要对文件描述符列表进行轮询,这样处理耗时跟描述符数量就是O(N)的关系
除此之外,应用程序每次调用select和poll,还乤把文件描述符的集合,从用户空间传入内核空间,由内核修改后,再传出到用户空间中,这一来一回的内核空间与用户空间切换,也增加了处理成本
2.使用非阻塞I/O和边缘触发,如epoll
epoll可以解决select和poll的问题
epoll使用红黑树,在内核中管理文件描述符,就不需要应用程序每次操作时都传入传出这个集合
epoll使用事件驱动机制,只关注有I/O事件发生的文件描述符,不需要轮询扫描整个集合
epoll在Linux2.6中新增的,由于边缘触发只在文件描述符可读或可写事件发生时才通知,那么应用程序就需要尽可能多的执行I/O,并要处理更多的异常事件
3.使用异步(Asynchronous I/O AIO)
异步I/O允许应用程序同时发起很多I/O操作,而不用等待这些操作完成,在I/O完成后,系统会有事件通知,如信号或者回调函数方式,告诉应用程序,这时应用程序才会去查询I/O操作的结果
异步I/O也是Linux2.6才支持的,并在很长时间内斗处于不完善的状态,如glic提供的异步I/O库一直有被社区诟病,由于异步I/O跟我们直观逻辑不太一样,设计的难度比较高
工作模型优化
1.主进程+多个worker子进程,这是最常用的一种模式
- 主进程执行bind()+listen()后,创建多个子进程
- 在每个子进程中,都通过accept()或epoll_wait()来处理相同的套接字
如最常用的反向代理服务器Nginx就是这么工作的,它也是由主进程和多个worker进程组成,主进程主要用来初始化套接字,并管理子进程的生命周期
而worker进程,则负责实际的请求处理,整理逻辑如下图
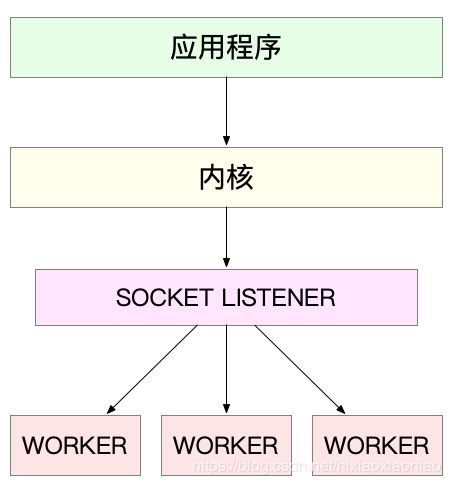
需要注意,accept()和epoll_wait()调用,还存在一个惊群的问题,换句话说,当网络I/O事件发生时,多个进程被同时唤醒,但实际上只有一个进程来响应这个事件,其他被唤醒的进程都会重新休眠
- accept()的惊群问题,在Linux2.6中解决了
- epoll的问题,到Linux4.5,通过EPOLLEXCLUSIVE解决
为了避免惊群问题,Nginx在每个worker进程中,都增加了一个全局锁(accept_mutex),这些worker进程需要首先竞争到锁,只有竞争到锁的进程,才会加入到epoll中,这样就确保只有一个worker子进程被唤醒
根据前面CPU模块的内容,进程的管理,调度,上下文切换的成本非常高,Nginx的多进程模式性能好的原因是
这些进程实际上并不需要经常创建和销毁,而是在没任务时休眠,有任务时唤醒,只有在worker由于某些异常退出时,主进程才需要创建新的进程来替代他
也可以用线程代替进程,主线程负责初始化套接字和子线程状态管理,子线程负责实际的请求处理
由于线程的调度和切换成本都较低,可以进一步把epoll_wait()都放到主线程中,保证每次事件都只唤醒主线程,而子线程只需要负责后续的请求处理
2.监听到相同端口的多进程模型
在这种方式下,所有的进程都监听到相同的端口,并且开启SO_REUSEPORT选项,由内核负责将请求负载均衡到这些监听进程中去,这一过程如下图所示

由内核确保只有一个进程被唤醒,就不会出现惊群问题了,如Nginx在1.9.1中就已经支持这种模式
如下图所示
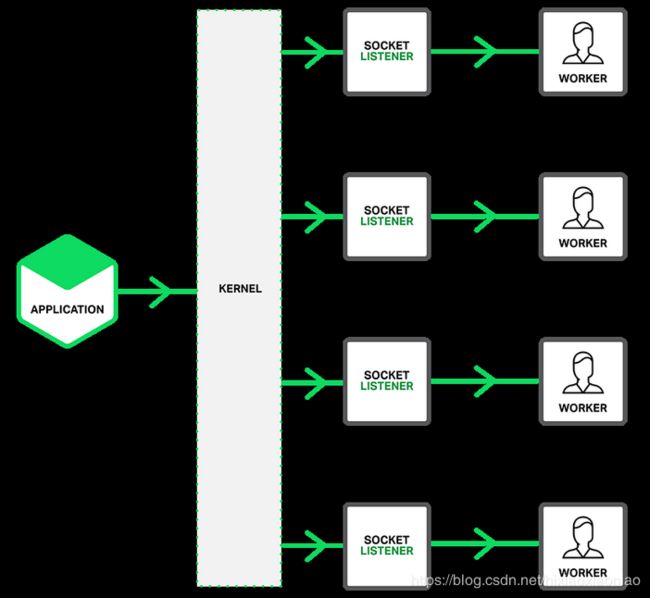
需要注意,使用SO_REUSEPORT选项,需要使用Linux3.9以上的版本才可以
C1000K
基于I/O多路复用和请求处理优化,C10K问题很容易就可以解决
之后又出现了C100K,C1M,也就是是并发从原来的1W增加到10W,100W
从1W到10W其实还是基于C10K的这些理论,epoll配合线程池,再加上CPU,内存,网络接口的性能和容量提升,大部分情况下,C100K很自然可以达到
但再进一步,C1M就很难了
从物理资源使用上来说,100W个请求需要大量的系统资源,如
假设每个请求需要16KB内存,那么总共需要15GB内存
从贷款上来说,假设只有20%的活跃连接,每个连接需要1KB/s吞吐量,总共也需要1.6Gb/s的吞吐量,千兆网卡也满足不了这个吞吐量,所以还需要配置万兆网口,或者基于多网卡Bonding承载更大的吞吐量
从软件资源上来说,大量的连接也会占用大量的软件资源,如文件描述符的数量,连接的状态跟踪CONNTRACK,网络协议栈的缓存大小(如套接字读写缓存,TCP读写缓存)等
最后大量请求带来的中断处理,也会带来非常高的处理成本,这就需要多队列网卡,中断负载均衡,CPU绑定,RPS/RFS(软中断负载均衡到多个CPU核上),以及将网络报的处理卸载Offload到网络设备(如TSO/GSO,LRO/GRO,VXLAN OFFLOAD)等各种硬件和软件的优化
C1M的解决版本,本质上还是构建在epoll非阻塞I/O模型上,但除了I/O模型之外,还需要从应用程序到Linux内核,再到CPU,内存,网络等各个层次的深度优化,特别是需要借助硬件,来卸载原来通过软件处理的大量功能
C10M
再进一步,有没有可能在单机中同时处理1000W的请求呢,这就是C10M问题
在C1M问题中,各种软件,ing见的优化可能已经做到头了,特别是升级完硬件有足够的内存,足够大的网卡,更多的网络卸载功能后,会发现再怎么优化程序和内核中的各种网络参数,想实现C10M请求并发,都是极其困难
其根本原因还是Linux内核协议栈做了太多太繁重的工作,从网卡中断带来的硬件中断处理程序开始,到软件中断中的各层网络协议处理,最后再到应用程序,这个路径实在是太长了,就会导致网络包的处理优化,到了一定程度后,就无法更进一步了
要解决这个问题,最终就是跳过内核协议栈的冗长路径,把网络包直接送到要处理的应用程序那里去,有两种常见的机制,DPDK和XDP
1.DPDK,用户态网络的标准
它跳过内核协议栈,直接由用户态进程通过轮询的方式,来处理网络接收
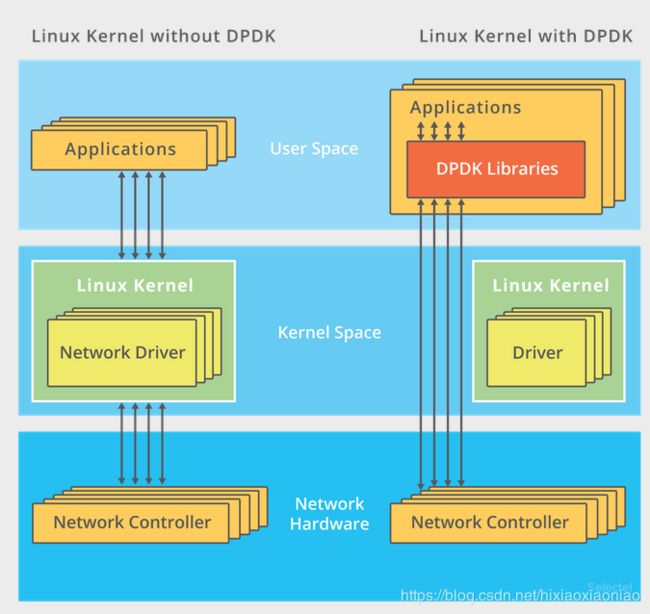
轮询看起来效率很低,但其低效率是体现在查询时间明显多于实际工作时间情况下,如果每时每刻都有新的网络包需要处理,轮询的优势就很明显了,如
在PPS非常高的场景下,查询时间比实际工作时间少了很多,绝大部分时间都在处理网络包
跳过协议栈后,省去了繁杂的硬件中断,软件中断再到Linux网络协议栈的逐层处理过程,应用程序可以针对应用的实际场景,有针对性的优化网络包的处理逻辑,而不需要关注所有的细节
此外DPDK还通过大页,CPU绑定,内存对齐,流水线并发等多种机制,优化网络包的处理效率
2.XDP(eXpress Data Path)
这是基于Linux内核提供的一种高性能网络数据路径,它允许网络包,在进入内核协议栈之前,就进行处理,也可以带来更高的性能,XDP底层跟bcc-tools一样,都是Linux内核的eBPF机制实现的
XDP的原理如下图所示
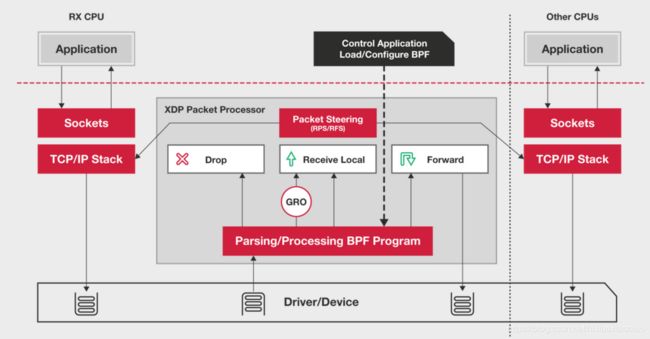
XDP对内核要求比较高,需要Linux4.8以上版本,并且也不提供缓存队列,基于XDP的应用程序通常是专用的网络应用,常见的有IDS(入侵检测系统),DDos防御,cilium容器网络插件等
参考
Socket Sharding in NGINX Release 1.9.1
The C10K problem
C10M
Introduction to DPDK: Architecture and Principles
XDPeXpress Data Path
cilium
The Secret To 10 Million Concurrent Connections