开源监控系统 Prometheus 入门
点击上方蓝色“程序猿DD”,选择“设为星标”
回复“资源”获取独家整理的学习资料!


来源 | 公众号「yangyidba」
一 简介
Prometheus 是一套开源的监控系统。设计思路来自于Google的borgmon 监控系统(由工作在 SoundCloud的Google 前员工在2012年创建)。
提供多维数据模型和灵活的查询方式,通过将监控指标关联多个tag,来将监控数据进行任意维度的组合。
提供PromSQL可以利用多维数据完成复杂的查询。
在不依赖分布式存储的情况下,支持单个服务器节点可以本地存储。通过Prometheus自带的时序数据库支持每秒千万级别的数据存储。
制定了数据标准,以基于HTTP的pull方式采集时间序列数据,只要满足Prometheus监控数据格式的监控数据都可以被Prometheus采集,汇总。
通过PushGateway组件 支持以push方式推送时间序列数据。
支持静态配置和通过服务发现的机制发现监控对象,自动完成数据采集。目前已经支持Kubernets,etcd,Consul 等多种服务发现,减少运维人员手动配置操作。
多种图形模式及仪表盘支持(grafana)
易于维护,可以通过二进制文件直接启动,并且提供了容器化部署镜像。
支持数据分区采样和联邦集群部署,支持大规模集群监控。
二 架构
一图胜千言 (图片来自官方的架构图)

我们从上面的架构图可以看出 Prometheus 的主要模块包含:Server, Exporters, Pushgateway, PromQL, Alertmanager, WebUI 等。我们逐一认识一下各个模块的功能作用。
2.1 模块
Retrieval是负责定时去暴露的目标页面上去抓取采样指标数据。
Storage 是负责将采样数据写入指定的时序数据库存储。
PromQL 是Prometheus提供的查询语言模块。可以和一些webui比如grfana集成。
Jobs / Exporters:Prometheus 可以从 Jobs 或 Exporters 中拉取监控数据。Exporter 以 Web API 的形式对外暴露数据采集接口。
Prometheus Server:Prometheus 还可以从其他的 Prometheus Server 中拉取数据。
Pushgateway:对于一些以临时性 Job 运行的组件,Prometheus 可能还没有来得及从中 pull 监控数据的情况下,这些 Job 已经结束了,Job 运行时可以在运行时将监控数据推送到 Pushgateway 中,Prometheus 从 Pushgateway 中拉取数据,防止监控数据丢失。
Service discovery:是指 Prometheus 可以动态的发现一些服务,拉取数据进行监控,如从DNS,Kubernetes,Consul 中发现, file_sd 是静态配置的文件。
AlertManager:是一个独立于 Prometheus 的外部组件,用于监控系统的告警,通过配置文件可以配置一些告警规则,Prometheus 会把告警推送到 AlertManager。
2.2 Prometheus的工作原理逻辑:
Prometheus server 定期从静态配置或者服务发现的 targets 拉取要监控的目标数据metrics。
Prometheus server 在本地存储收集到的 metrics,并运行已定义好的 alert.rules,记录新的时间序列或者向 Alertmanager 推送警报。
Alertmanager 收到警告的时候,可以根据配置,聚合,去重,降噪,最后发送警告。
可以使用 API, Prometheus Console 或者 Grafana 查询和聚合数据。
三 Prometheus的数据模型和类型
3.1 数据模型
Prometheus 存储的所有数据都是时间序列数据(Time Serie Data,简称时序数据)。时序数据是具有时间戳的数据流,该数据流属于某个度量指标(Metric)和该度量指标下的多个标签(Label)。

度量指标(Metric):描述了被监控的某个测量特征。度量指标名称由ASCII字母、数字、下划线和冒号组成,须匹配正则表达式 [a-zA-Z_:][a-zA-Z0-9_:]*。
标签(Tag):对于同一个度量指标,不同标签值组合会形成特定维度的时序。标签支持Prometheus的多维数据模型。Prometheus 的查询语言可以通过度量指标和标签对时序数据进行过滤和聚合。标签名称可以包含 ASCII 字母、数字和下划线,须匹配正则表达式 [a-zA-Z_][a-zA-Z0-9_]*,带有 _ 下划线的标签名称保留为内部使用。标签值可以包含任意 Unicode 字符,包括中文。
采样值(Sample):时序数据其实就是一系列的采样值。每个采样值包括:一个64位的浮点数据和一个精确到毫秒的时间戳。
时间序列的存储似乎可以设计成key-value存储的方式
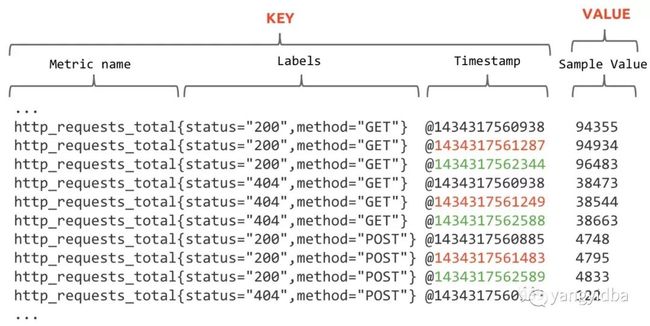
进一步拆分,我们通过PomeSQL查询看到的是类似如下

name是特定的label标签,代表了metric name。
3.2 Metric 的类型
Prometheus 主要提供四种主要的 metric 类型:Counter: 一种累加的 metric,它是一个只能递增的数值。典型的应用如:请求的个数,结束的任务数,出现的错误数等等。重启进程后,会被重置为0,比如MySQL的启动时间。
Gauge:一个既可以增加,又可以减少的度量指标。计量器主要用于测量类似于温度、内存使用量这样的瞬时数据。
Histogram:Histogram 由 prometheus_local_storage_series_chunks_persisted, 表示 Prometheus 中每个时序需要存储的 chunks 数量,我们可以用它计算待持久化的数据的分位数。
Summary:Summary 和 Histogram 类似,由 prometheus_target_interval_length_seconds。
3.3 作业和实例
Prometheus 中,将任意一个独立的数据源(target)称之为实例(instance)。包含相同类型的实例的集合称之为作业(job)。如下是一个从mysql_no_product.yml获取监控对象,每隔1min拉取一次的job 。
-
- job_name: 'qa-mysql'
scrape_timeout: 20s
scrape_interval: 1m
file_sd_configs:
- files:
- mysql_no_product.yml
refresh_interval: 1m
relabel_configs:
- source_labels: ['mysql_host']
target_label: __param_mysql_host
- source_labels: ['mysql_port']
target_label: __param_mysql_port
- source_labels: ['__address__']
target_label: __address__
四 报警
Alertmanager 主要用于接收 Prometheus 发送的告警信息,它支持丰富的告警通知渠道,而且很容易做到告警信息进行去重,降噪,分组,策略路由,是一款前卫的告警通知系统。Alertmanager 可以比较吸引人的特性:
报警分组:将报警分组,当报警大量出现的时候,只会发一条消息告诉你数据库挂了的情况出现了 100 次,而不是用 100 条推送轰炸你;
报警抑制:显然,当数据库出问题的时候,其它的应用可肯定会出问题,这时候你可能不会需要其它的不相干的报警短信,这个功能将真正有用的信息及时通知你;
报警静默:一些不重要的报警,可以完全忽略,因此也就没有必要通知;
五 可视化
Grafana 是一个跨平台的开源的度量分析和可视化工具,可以通过将采集的数据查询然后可视化的展示。比Prometheus 自带的web ui提供更多好看的界面和功能 。
本文通过OpenWrite的Markdown转换工具发布
关注我,回复“加群”加入各种主题讨论群

代码生成器:IDEA 强大的 Live Templates
Spring Boot 2.1之后如何在启动日志中打印请求路径列表
NASA立扫把挑战”?牛顿的棺材板都按不住啦!
如何干掉恶心的 SQL 注入?
Spring Boot 2.x 中使用国产数据库连接池Druid
朕已阅 