关于hadoop-ha联邦制集群搭建的注意事项
在学习大数据的过程中避免不了要搭建各种分布式集群,能不能准确快速地搭好集群将关系到我们学习大数据效率的高低。由于之前没有一定的经验,所以在学习的过程中经常遇到各种问题。网上虽然有一些解决方案,但有时不完全有用,得结合自己的实际情况做出判断。今天就自己的学习心得分享给大家:
说明:本集群是在虚拟机linux的CentOS-6.7 64位版本上搭建的(当然不局限于该版本,但建议选择版本6.0以上的)。由于hadoop是用java写的,所以必须安装jdk(建议采用1.7版本)。这里默认您已经安装好了jdk,并配置好了环境变量。本次集群中的主机数量为5台,各台的关系如下图:

hadoop2.0官方提供了两种HDFS HA的解决方案,一种是NFS,另一种是QJM。这里我们使用简单的QJM。在该方案中,主备NameNode之间通过一组JournalNode同步元数据信息,一条数据只要成功写入多数JournalNode即认为写入成功。通常配置奇数个JournalNode
这里还配置了一个zookeeper集群,用于ZKFC(DFSZKFailoverController)故障转移,当Active NameNode挂掉了,会自动切换Standby NameNode为standby状态。有关zookeeper集群的搭建将不在这里介绍了,想知道的同学可以去网上搜一下。
一、安装Hadoop
说明:这里采用hadoop-2.7.2(稳定版),由于之前的1.0版本中是没有yarn体系的,所以需要选择2.0版本以上的。
1.1解压
将安装包hadoop-2.7.2.tar.gz上传到linux系统。可以采用Alt+p的方式直接拖动上传,也可以采用支持SSH协议的SecureFX进行文件上传.上传好后解压到相应的目录下:
tar -zxvf hadoop-2.7.2.tar.gz -C /root/apps/
1.2 配置环境变量
vim /etc/profile
export JAVA_HOME=/usr/java/jdk1.7.0_55
export HADOOP_HOME=/root/apps/hadoop-2.7.2
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin
配置好后记得更新:source /etc/profile
并关闭防火墙:services iptables stop
1.3修改配置文件
进入到配置文件目录:cd /root/apps/hadoop-2.7.2/etc/hadoop

以上标记的文件都是需要配置的,具体的配置如下:
====================
hadoop-env.sh
====================
export JAVA_HOME=/root/apps/jdk1.7.0_45
export HADOOP_HOME=/root/apps/hadoop-2.7.2
====================
core-site.xml
====================
=====================
hdfs-site.xml
=====================
sshfence
shell(/bin/true)
===================
yarn-site.xml
===================
==============
mapred-site.xml
==============
==============
slaves
==============
shizhan02
shizhan03
shizhan04
说明:在集群中各台主机之间是随时要通信的,如果每次通信都需要手动登录会显得很麻烦,那么我们就得配置各主机之间的免钥登录.
首先要配置shizhan01到shizhan02、shizhan03、shizhan04、shizhan05的免钥登录.
在shizhan01上生成一对密钥: ssh-keygen -t rsa
然后将密钥拷贝到其他机器上,包括自己:
ssh-copy-id -i ~/.ssh/id_rsa.pub root@shizhan01
ssh-copy-id -i ~/.ssh/id_rsa.pub root@shizhan02
ssh-copy-id -i ~/.ssh/id_rsa.pub root@shizhan03
ssh-copy-id -i ~/.ssh/id_rsa.pub root@shizhan04
ssh-copy-id -i ~/.ssh/id_rsa.pub root@shizhan05
两个namenode之间要配置ssh免密码登陆,在shizhan05上生成密钥,并将其拷贝到shizhan01:ssh-keygen -t rsa
ssh-copy-id -i ~/.ssh/id_rsa.pub root@shizhan01
注意:由于密钥登录是基于ssh协议的,但有些Linux版本中没有安装ssh协议,所以在执行免钥登陆时检查一下:
rpm -qa | grep openssh
如果出现如下信息:
openssh-askpass-5.3p1-123.el6_9.x86_64
openssh-5.3p1-123.el6_9.x86_64
openssh-clients-5.3p1-123.el6_9.x86_64
openssh-server-5.3p1-123.el6_9.x86_64
就说明已经安装有了,如果没有就手动安装:
yum install ssh
yum install rsync
1.4将配置好的hadoop拷贝到其他节点:
scp -r /root/apps/hadoop-2.7.2/ root@shizhan02:/root/apps/
scp -r /root/apps/hadoop-2.7.2/ root@shizhan03:/root/apps/
scp -r /root/apps/hadoop-2.7.2/ root@shizhan04:/root/apps/
scp -r /root/apps/hadoop-2.7.2/ root@shizhan05:/root/apps/
二、启动Hadoop集群
说明:这里启动是严格按照顺序进行的,如果你其中的某一步先做了或者后做了,都会导致很多让人头疼的问题,最终达不到集群的效果。ps:我之前在这里可谓是一波九折,连续弄得好几天啊,集群搭了n遍,删了又装,装了又删,配置文件被我改了无数遍,我都有放弃的意念了。
2.1启动zookeeper集群(在shizhan02、shizhan03、shizhan04上启动)
cd /root/apps/zookeeper/bin
./zkServer.sh start
当3台都启动好后,可以查看到一个leader,两个follower
./zkServer.sh status
2.2启动journalnode(在shizhan02、shizhan03、shizhan04上启动)
cd /root/apps/hadoop-2.7.2
sbin/hadoop-daemon.sh start journalnode
运行jps命令可以看到shizhan02、shizhan03、shizhan04多了journalnode、QuorumPeerMain进程
2.3格式化HDFS(在shizhan01上执行)
hdfs namenode -format
格式化后会在根据hdfs-site.xml中的dfs.namenode.name.dir配置生成个文件,然后将该文件拷贝到shizhan05的/home/hadoop/下。
scp -r namedir/ shizhan05:/home/hadoop/
但建议hdfs namenode -bootstrapStandby
注意:这里是在shizhan05上执行的hdfs namenode -bootstrapStandby命令,由于执行该命令时会监听9000active端口,所以应该先在shizhan01上启动hdfs,然后才能在shizhan05上执行该命令,否则会出现netexception。
2.4格式化ZKFC(在shizhan01上执行一次即可)
hdfs zkfc -formatZK
2.5关闭之前在shizhan01上启动的hdfs,重新启动hdfs
sbin/start-dfs.sh
此时jsp命令查看各个节点的运行状态,会发现shizhan05上多了namenode进程。如果符合上面给出图的节点状态就说明安装成功了
注意:由于在安装的过程中或者以后为了扩展集群的数量会产生多次格式化操作,导致datanode节点启动不了。原因是每次格式化后,集群的clusterId、namespaceID、blockpooLID都会发生改变,而节点上原有的集群信息并没有被覆盖,所以需要手动删除datanode节点上原有的集群信息再格式化。
2.6启动yarn
sbin/start-yarn.sh
到此,hadoop-2.7.2配置完毕,可以统计浏览器访问:
http://shizhan01:50070
NameNode 'shizhan01:9000' (active)
http://shizhan05:50070
NameNode 'shizhan05:9000' (standby)
三、验证HDFS
首先向hdfs上传一个文件
hadoop fs -put /etc/profile /profile
hadoop fs -ls /
然后再kill掉active的NameNode
kill -9
通过浏览器访问:http://shizhan05:50070
NameNode 'shizhan05:9000' (active)这个时候shizhan05上的NameNode变成了active
在执行命令:
hadoop fs -ls /
可以发现上传的文件依然存在.
注意:当尝试手动进行namenode主备切换时,不建议直接通过杀掉进程的方式。如果两台机器上的namenode进程都被杀死的话,可能会出现namenode主备无法启动或者无法切换的问题.
四、验证yarn
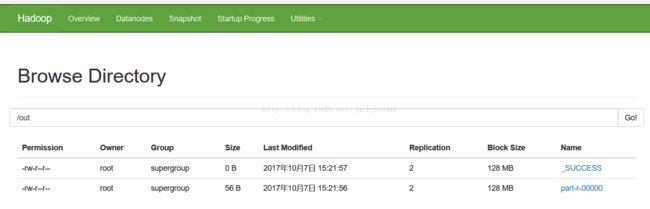
运行一下hadoop提供的demo中的WordCount程序:
hadoop jar apps/hadoop-2.7.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /profile /out
查看后yarn能成功作业:
五、总结
大数据中的集群安装是非常重要的,当然也非常考验一个人的耐心和处理问题的能力。学习的过程是漫长而乏味的,只有坚持下来了才会慢慢成长。希望我的以上心得能对你有所帮助!