膨胀卷积——《MULTI-SCALE CONTEXT AGGREGATION BY DILATED CONVOLUTIONS》
看这篇论文主要是想了解膨胀卷积,搜出这篇,看起来貌似比deeplab简单一些,于是以此入手。这篇论文把膨胀卷积的计算原理讲的很清楚,但是作用和产生的缘由的话还是deeplab的论文更容易懂,deeplab里面叫"hole algorithm"。
1. dense prediction
在谈膨胀卷积之前想先说一下dense prediction,一开始对这个概念不太理解,看了看别人的解释后说说自己的理解吧。
在做分类时,我们输入一整张图片(假如是(n,n,3)尺寸的),输出只需要一个class label(尺寸为1);
做目标检测时,给出物体所在边框(方框)的4个顶点(尺寸为(1,4));
做物体边缘检测时,给出物体的边缘像素点,这时候上升到像素级别,预测实际上是基于每个像素了(尺寸为(n, n,1));
做语义分割时,实际上是对输入图像的每个像素点做类别预测,假如有m类,输出实际上是每个像素点被分为各类别的概率(尺寸为(n,n,m));实例分割的话类别就更多了,输出也更稠密。
按照输入和输出的size对比,越往下,输出相对于输入的密度越大。从笨妞做过的实验来看,迭代需要的时间也越长。
作者认为dense prediction有两个关键点多尺度上下文推理和全分辨率输出。“最近的工作研究了两种处理多尺度推理和全分辨率密集预测的冲突需求的方法.一种方法是重复向上卷积,目的是恢复丢失的分辨率,同时从下采样层进行全局透视。另一种方法包括将图像的多个重新缩放版本作为输入到网络,并结合为这些多个输入获得的预测。” 个人理解就是既要通过前面的多尺度卷积抽取图像的特征,卷积抽取特征的一大特点就是特征的尺寸会变小;同时,由于前面说了dense prediction需要对每个像素进行预测,输出需要保存和原分辨率。像FCN就是前面抽特征的时候先缩,特征抽完了再放。
膨胀卷积就是为了保持泛化的抽特征,同时图像的尺寸不缩减。
2. 膨胀卷积
本篇论文中的膨胀卷积平面计算层是这样的:

deeplab论文里面的计算细节是这样的:

当然,为了保持尺寸,通常需要先对图像做padding. padding的数量和膨胀率相关。
一般卷积和膨胀卷积的计算差别:

“膨胀卷积算子在过去被称为“带扩张滤波器的卷积”,它在小波分解算法a trous中起着关键的作用。我们用“扩张卷积”一词代替了“膨胀滤波器卷积”来说明没有构造或表示“扩张滤波器”,而是对卷积算子本身进行了修改,使其能够以不同的方式使用滤波器参数。扩张卷积算子可以使用不同的扩张因子在不同的范围内应用相同的滤波器,我们的定义反映了扩张卷积算子的适当实现,它不涉及扩张滤波器的构造。”
原理:扩展的卷积支持指数扩展的接受域,从而不丢失分辨率或覆盖范围。

论文这个公式笨妞不太能理解,自己算了一下,扩展的接受域大概是这样的:
![]()
从膨胀卷积的计算过程可以看到,它既带有conv卷积滤波功能,同时具有pool层的泛化作用,但与pool层不同,pool只要stride>1,特征图的尺寸就会大幅减小,而dilate不会。
3. 多尺度的膨胀卷积
论文中提到的膨胀卷积网络有7层,其中,每一层的核size都是(3,3)每层的膨胀率率分别是(1,1,2,4,8,16,1),但是作者提供的程序中网络更加复杂,在论文讲到的膨胀卷积网络前面添加了VGG16。同时,vgg16前4个模块之外维持不变,第5个卷积模块改为膨胀率为2,第一个全连接层改为核尺寸为(7,7),膨胀率为4的卷积。可能这就是作者后面提到的更大的网络吧。
论文的网络结构是这样的:
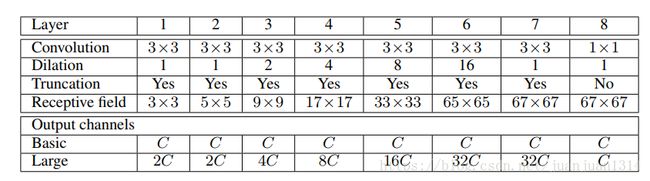
上面网络的初始化方法:
![]()
后面提到的更复杂网络的初始化方法:

4.keras版本的程序解析
作者额源程序是基于caffe。多年不用caffe,实在不习惯,从github上找了个keras版本的,地址在这里
程序是加载预训练模型做预测的,预训练模型只有theano的,没有我需要的tensorflow模型。另外,作者采用4个数据集,分别是
cityscapes、pascol voc2012、kitti、camvid,每个数据集的图像尺寸不同,网络略有不同,但主要基本一样,就以cityscapes对应的网络来看吧。
def get_dilation_model_cityscapes(input_shape, apply_softmax, input_tensor, classes):
if input_tensor is None:
model_in = Input(shape=input_shape)
else:
if not K.is_keras_tensor(input_tensor):
model_in = Input(tensor=input_tensor, shape=input_shape)
else:
model_in = input_tensor
"""""""""""""""""""vgg16""""""""""""""""""""
h = Convolution2D(64, 3, 3, activation='relu', name='conv1_1')(model_in)
h = Convolution2D(64, 3, 3, activation='relu', name='conv1_2')(h)
h = MaxPooling2D(pool_size=(2, 2), strides=(2, 2), name='pool1')(h)
h = Convolution2D(128, 3, 3, activation='relu', name='conv2_1')(h)
h = Convolution2D(128, 3, 3, activation='relu', name='conv2_2')(h)
h = MaxPooling2D(pool_size=(2, 2), strides=(2, 2), name='pool2')(h)
h = Convolution2D(256, 3, 3, activation='relu', name='conv3_1')(h)
h = Convolution2D(256, 3, 3, activation='relu', name='conv3_2')(h)
h = Convolution2D(256, 3, 3, activation='relu', name='conv3_3')(h)
h = MaxPooling2D(pool_size=(2, 2), strides=(2, 2), name='pool3')(h)
h = Convolution2D(512, 3, 3, activation='relu', name='conv4_1')(h)
h = Convolution2D(512, 3, 3, activation='relu', name='conv4_2')(h)
h = Convolution2D(512, 3, 3, activation='relu', name='conv4_3')(h)
h = AtrousConvolution2D(512, 3, 3, atrous_rate=(2, 2), activation='relu', name='conv5_1')(h)
h = AtrousConvolution2D(512, 3, 3, atrous_rate=(2, 2), activation='relu', name='conv5_2')(h)
h = AtrousConvolution2D(512, 3, 3, atrous_rate=(2, 2), activation='relu', name='conv5_3')(h)
h = AtrousConvolution2D(4096, 7, 7, atrous_rate=(4, 4), activation='relu', name='fc6')(h)
h = Dropout(0.5, name='drop6')(h)
h = Convolution2D(4096, 1, 1, activation='relu', name='fc7')(h)
h = Dropout(0.5, name='drop7')(h)
h = Convolution2D(classes, 1, 1, name='final')(h)
"""""""""""""""""""vgg16""""""""""""""""""""
#到上面为止都是vgg16,只是第5个conv模块加入了膨胀, fc6从全连接层变成了conv层,并加入膨胀,fc7和final也变成conv层。
""""""""""""""""""""论文当中的网络模块"""""""""""""""""""""""""
h = ZeroPadding2D(padding=(1, 1))(h) #膨胀卷积之前先padding
h = Convolution2D(classes, 3, 3, activation='relu', name='ctx_conv1_1')(h)
h = ZeroPadding2D(padding=(1, 1))(h)
h = Convolution2D(classes, 3, 3, activation='relu', name='ctx_conv1_2')(h)
h = ZeroPadding2D(padding=(2, 2))(h)
h = AtrousConvolution2D(classes, 3, 3, atrous_rate=(2, 2), activation='relu', name='ctx_conv2_1')(h)
h = ZeroPadding2D(padding=(4, 4))(h)
h = AtrousConvolution2D(classes, 3, 3, atrous_rate=(4, 4), activation='relu', name='ctx_conv3_1')(h)
h = ZeroPadding2D(padding=(8, 8))(h)
h = AtrousConvolution2D(classes, 3, 3, atrous_rate=(8, 8), activation='relu', name='ctx_conv4_1')(h)
h = ZeroPadding2D(padding=(16, 16))(h)
h = AtrousConvolution2D(classes, 3, 3, atrous_rate=(16, 16), activation='relu', name='ctx_conv5_1')(h)
h = ZeroPadding2D(padding=(32, 32))(h)
h = AtrousConvolution2D(classes, 3, 3, atrous_rate=(32, 32), activation='relu', name='ctx_conv6_1')(h)
h = ZeroPadding2D(padding=(64, 64))(h)
h = AtrousConvolution2D(classes, 3, 3, atrous_rate=(64, 64), activation='relu', name='ctx_conv7_1')(h) #论文中有7个卷积层,这里多了一个。
""""""""""""""""""""论文当中的网络模块"""""""""""""""""""""""""
h = ZeroPadding2D(padding=(1, 1))(h)
""""""""""""""""""""类似于全连接层部分"""""""""""""""""""""""""
h = Convolution2D(classes, 3, 3, activation='relu', name='ctx_fc1')(h)
h = Convolution2D(classes, 1, 1, name='ctx_final')(h)
""""""""""""""""""""类似于全连接层部分"""""""""""""""""""""""""
"""""""""""""""""""上采样模块,只有cityscape对应的网络采用"""""""""""""
# the following two layers pretend to be a Deconvolution with grouping layer.
# never managed to implement it in Keras
# since it's just a gaussian upsampling trainable=False is recommended
h = UpSampling2D(size=(8, 8))(h)
logits = Convolution2D(classes, 16, 16, bias=False, trainable=False, name='ctx_upsample')(h)
"""""""""""""""""""上采样模块,只有cityscape对应的网络采用"""""""""""""
if apply_softmax:
model_out = softmax(logits) #2维softmax
else:
model_out = logits
model = Model(input=model_in, output=model_out, name='dilation_cityscapes')
return model
预测程序:
#没有细看这个方法的算法,大致看来是把反射填充的部分重新算回去,并做zoom
#做zoom的原因在于,除了sityscape对应的网络有最后两层upsample,部分还原了图像尺寸,其他数据集对应的网络都没有upsample,需要通过zoom来放大输出。
def interp_map(prob, zoom, width, height):
zoom_prob = np.zeros((prob.shape[0], height, width), dtype=np.float32)
for c in range(prob.shape[0]):
for h in range(height):
for w in range(width):
r0 = h // zoom
r1 = r0 + 1
c0 = w // zoom
c1 = c0 + 1
rt = float(h) / zoom - r0
ct = float(w) / zoom - c0
v0 = rt * prob[c, r1, c0] + (1 - rt) * prob[c, r0, c0]
v1 = rt * prob[c, r1, c1] + (1 - rt) * prob[c, r0, c1]
zoom_prob[c, h, w] = (1 - ct) * v0 + ct * v1
return zoom_prob
def predict(image, model, ds):
image = image.astype(np.float32) - CONFIG[ds]['mean_pixel']
#输入图像大多是(500,500)以内的图片,作者采用的是填充而不是resize同一图像尺寸,
#先对整张图做同一尺寸的填充,然后再根据每个图像本身的尺寸做图像分割和填充。
conv_margin = CONFIG[ds]['conv_margin']
input_dims = (1,) + CONFIG[ds]['input_shape']
batch_size, num_channels, input_height, input_width = input_dims
model_in = np.zeros(input_dims, dtype=np.float32)
image_size = image.shape
output_height = input_height - 2 * conv_margin
output_width = input_width - 2 * conv_margin
#整体填充
image = cv2.copyMakeBorder(image, conv_margin, conv_margin,
conv_margin, conv_margin,
cv2.BORDER_REFLECT_101) #填充方式为“反射填充”
#计算图像分割数量
num_tiles_h = image_size[0] // output_height + (1 if image_size[0] % output_height else 0)
num_tiles_w = image_size[1] // output_width + (1 if image_size[1] % output_width else 0)
row_prediction = []
for h in range(num_tiles_h):
col_prediction = []
for w in range(num_tiles_w):
offset = [output_height * h,
output_width * w]
#有重叠的分割,并填充到input_size
tile = image[offset[0]:offset[0] + input_height,
offset[1]:offset[1] + input_width, :]
margin = [0, input_height - tile.shape[0],
0, input_width - tile.shape[1]]
tile = cv2.copyMakeBorder(tile, margin[0], margin[1],
margin[2], margin[3],
cv2.BORDER_REFLECT_101)
model_in[0] = tile.transpose([2, 0, 1])
#每张分割图做一次预测
prob = model.predict(model_in)[0]
col_prediction.append(prob)
col_prediction = np.concatenate(col_prediction, axis=2)
row_prediction.append(col_prediction) #预测图合并成大图
prob = np.concatenate(row_prediction, axis=1)
if CONFIG[ds]['zoom'] > 1:
#做zoom,还原图像。
prob = interp_map(prob, CONFIG[ds]['zoom'], image_size[1], image_size[0])
prediction = np.argmax(prob, axis=0)
color_image = CONFIG[ds]['palette'][prediction.ravel()].reshape(image_size)
return color_image程序只有theano版本的预训练模型,于是笨妞自己弄了个训练程序,训练pascol voc2012,训练程序如下
import numpy as np
import cv2
from dilation_net import DilationNet
from datasets import CONFIG
from keras.optimizers import SGD
from keras.applications.vgg16 import preprocess_input
from keras.preprocessing import image
from PIL import Image
import random
def binarylab(labels, size, nb_class):
y = np.zeros((size,size,nb_class))
for i in range(size):
for j in range(size):
y[i, j,labels[i][j]] = 1
"""
for k in range(nb_class):
plt.imshow(y[:, :, k])
plt.show()
"""
return y
def load_data(path, size=224, mode=None):
img = Image.open(path)
w,h = img.size
if w < h:
if w < size:
img = img.resize((size, size*h//w))
w, h = img.size
else:
if h < size:
img = img.resize((size*w//h, size))
w, h = img.size
img = img.crop((int((w-size)*0.5), int((h-size)*0.5), int((w+size)*0.5), int((h+size)*0.5)))
if mode=="original":
return img
if mode=="label":
y = np.array(img, dtype=np.int32)
mask = y == 255
y[mask] = 0
y = binarylab(y, size, 21)
#y = np.expand_dims(y, axis=0)
return y
if mode=="data":
X = image.img_to_array(img)
#X = np.expand_dims(X, axis=0)
X = preprocess_input(X)
return X
def generate_arrays_from_file(names, path_to_train, path_to_target, input_size, output_size, batch_size):
while True:
for name in names:
Xpath = path_to_train + "{}.jpg".format(name)
ypath = path_to_target + "{}.png".format(name)
X = []
y = []
for i in range(batch_size):
X.append(load_data(Xpath, input_size, mode="data"))
y.append(load_data(ypath, output_size, mode="label"))
X = np.array(X)
y = np.array(y)
yield (X, y)
if __name__ == '__main__':
ds = 'voc12' # choose between cityscapes, kitti, camvid, voc12
nb_class = 21
# get the model
model = DilationNet(dataset=ds)
sgd = SGD(lr=0.0002)
model.compile(optimizer=sgd, loss='categorical_crossentropy')
model.summary()
input_size = CONFIG[ds]['input_shape'][0]
output_size = 34
nb_class = CONFIG[ds]['classes']
path_to_train = 'VOCtrainval_11-May-2012/VOCdevkit/VOC2012/JPEGImages/'
path_to_target = 'VOCtrainval_11-May-2012/VOCdevkit/VOC2012/SegmentationClass/'
path_to_txt = 'VOCtrainval_11-May-2012/VOCdevkit/VOC2012/ImageSets/Segmentation/train.txt'
with open(path_to_txt, "r") as f:
ls = f.readlines()
names = [l.rstrip('\n') for l in ls]
random.shuffle(names)
nb_data = len(names)
train_gen = generate_arrays_from_file(names, path_to_train, path_to_target, input_size, output_size, batch_size=2)
model.fit_generator(train_gen,
samples_per_epoch=nb_data//2,
nb_epoch=1)
但是发现反向计算梯度的时候内存直接溢出了,笨妞的机子实在太烂,16G内存,没有GPU。没办法,只能阉割网络,先把vgg16第5个conv模块阉割掉,还是报溢出,没有办法,接着把fcn6和fcn7的kernel数量从4096缩减到1024,终于可以正常跑了。1轮训练要花10个小时,龟速啊!
使用默认学习率(0.001),第二个batch,loss就变nan了,降到0.0001,loss稳着不动,到0.0002,勉强慢慢下降,下降也是很慢。
其实还有一个加快速度的办法就是前面的vgg16模型直接载入imagenet预训练权重,并设置为不训练。同时,也可以在阉割一下,直接用论文中的7层网络。