Python之操作系统
操作系统
1. os函数
(1).返回操作系统类型
import os
# posix: linux系统; nt: windows系统
print(os.name)

(2).操作系统的详细信息
import os
# 系统类型 主机名 内核版本 时间 64位操作系统
info = os.uname()
# 打印操作系统的所有详细信息
print(info)
# 打印操作系统的系统类型
print(info.sysname)
# 打印操作系统的主机名
print(info.nodename)

(3).系统环境变量
import os
print(os.environ)
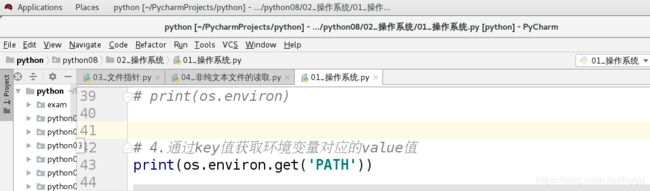
(4).通过key值获取环境变量对应的value值
import os
print(os.environ.get('PATH'))

(5).判断文件是否为绝对路径(不管文件是否真实存在,只是绝对路径就返回Ture)
import os
print(os.path.isabs('tmp/passwd'))
print(os.path.isabs('/tmp/wes'))
(6).生成绝对路径
import os
# 默认在当前路径下生成
print(os.path.abspath('hello.png'))
# 在指定路径下生成
print(os.path.join('/home/kiosk','hello.png'))

(7). 获取文件名/目录名
import os
filename = '/home/kiosk/Desktop/file'
# 获取文件名
print(os.path.basename(filename))
# 获取目录名
print(os.path.dirname(filename))

(8).创建目录/删除目录
import os
# 创建目录
os.mkdir('westos')
# 删除目录
os.rmdir('westos')
# 创建递归目录
os.makedirs('westos/linux')

(9).创建文件/删除文件
import os
# 创建文件
os.mknod('westos.txt')
# 删除文件
# os.remove('westos.txt')
 (10).重命名重命名
(10).重命名重命名
import os
# 创建文件
os.mknod('redhat.txt')
# 重命名文件
os.rename('redhat.txt','date.txt')

(11).判断文件或者目录是否存在
import os
print(os.path.exists('data.txt'))

(12).分离后缀名和文件名
import os
print(os.path.splitext('data.txt'))

(13).将目录名和文件名分离
import os
# print(os.path.split('/tmp/linux/hello.png'))

2.遍历目录
import os
from os.path import join
for root,dir,files in os.walk('/var/log'):
# print(root) # 目录
# print(dir) # 子目录
# print(files) # 文件
# 遍历指定目录下的文件
for name in files:
# 连接目录和文件
print(join(root,name))

3.操作系统综合练习
案例1:
1.生成一个大文件ips.txt,要求1200行,每行随机为172.25.254.0/24段的ip;
2.读取ips.txt文件,统计这个文件中ip出现频率,输出排前10的ip;
代码:(方法1)
# 1.生成一个大文件ips.txt ......
import random
# with(上下文管理器):系统会自动关闭文件
# 以读写方式打开文件(a:不会覆盖原文件内容,如果文件不存在会自动创建)
with open('ips.txt','a+') as f:
for i in range(1200):
# 将生成的ip依次写入ips.txt文件中
# 注意:只有类型相同,才能用+连接, \n表示换行 (ip的范围:0-254)
f.write('172.25.254.' + str(random.randint(0,255)) + '\n')
# 2.读取ips.txt文件 ......
# 定义空字典
dict = {}
# 只读打开文件
with open('ips.txt','r') as f:
# 按行遍历整个文件
for i in f:
# print(i)
# 利用工厂函数,统计每个ip出现的次数
if i not in dict:
dict[i] = 1
else:
dict[i] += 1
# print(dict)
# sorted(高阶内置函数):按照指定的key排序
# lambda:匿名函数(x[1]:dict字典的value值); reverse=True:逆序
# 注意:sorted函数排好序后输出的是列表
sorted_ip=sorted(dict.items(),key=lambda x:x[1],reverse=True)
# print(sorted_ip)
# 输出列表中的前10个元素
print(sorted_ip[:10])
运行结果:
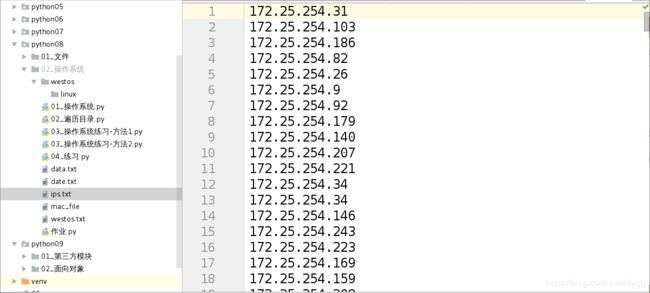

代码:(方法2:封装为函数)
import random
# 1.生成一个大文件ips.txt ......
# 定义函数
def create_ip_file(filename):
# 列表生成式:生成ip (172.25.254.0-172.25.254.254)
ip = ['172.25.254.' + str(i) for i in range(0,255)]
# with方式,读写打开文件
with open(filename,'a+') as f:
for count in range(1200):
# random.sample:在ip列表中随机生成1个ip,输出的是列表
# print(random.sample(ip,1))
# 将生成的ip写入文件中,由于生成的列表中只有一个元素
# random.sample(ip,1)[0]:取出列表中的元素
f.write(random.sample(ip,1)[0] + '\n')
# 调用函数
create_ip_file('ips.txt')
# 2.读取ips.txt文件 ......
# 定义函数,count为默认参数
def sorted_by_ip(filename,count=10):
# 工厂函数的方式,定义空字典
ips_dict = dict()
# with方式,读写打开文件
with open(filename) as f:
# 按行遍历整个文件
for ip in f:
# 利用工厂函数,统计每个ip出现的次数
if ip in ips_dict:
ips_dict[ip] += 1
else:
ips_dict[ip] = 1
# 按照指定的key排序,输出排在前10的ip
sorted_ip = sorted(ips_dict.items(),key=lambda x:x[1],reverse=True)[:count]
return sorted_ip
# 调用函数
print(sorted_by_ip('ips.txt'))
案例2:
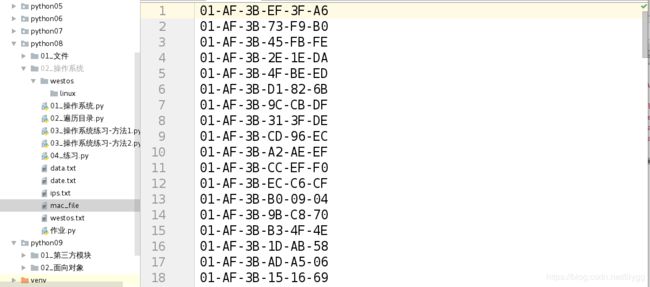
生成100个MAC地址并写入文件中,MAC地址前6位(16进制)为01-AF-3B
MAC地址:
01-AF-3B-xx-xx-xx
代码:
import random
import string
# 01-AF-3B-xx-xx-xx: 可以分为4部分: 01-AF-3B , -xx, -xx, -xx,(后三部分格式一样)
# 定义函数:生成一个MAC地址
def create_mac():
MAC = '01-AF-3B'
# 生成所有的16进制数
hex_num = string.hexdigits
# 每生成一个-xx便和MAC连接
for i in range(3):
# 在16进制数中随机选2个存入列表中
char = random.sample(hex_num,2)
# ''.join(char).upper():随机生成2位的16进制数(并将小写字母转换为大写)
chars = '-' + ''.join(char).upper()
# 将生成的chars与MAC连接
MAC += chars
return MAC
# print(create_mac())
# 定义主函数:生成100个MAC地址并写入文件中
def main():
with open('mac_file','w') as f:
for i in range(100):
mac = create_mac()
f.write(mac + '\n')
main()
运行结果: