Linux进程间通信原理笔记
一、进程间通信
1. 在讲进程间通信之前,先来讲讲管道模式。记得最初学Linux命令的时候,有下面这样一行命令:
ps -ef | grep 关键字 | awk '{print $2}' | xargs kill -9这里面的竖线“|”就是一个管道。它会将前一个命令的输出,作为后一个命令的输入。从管道的这个名称可以看出,管道是一种单向传输数据的机制,它其实是一段缓存,里面的数据只能从一端写入,从另一端读出,如果想互相通信,需要创建两个管道才行。管道分为两种类型,“|” 表示的管道称为匿名管道,意思就是这个类型的管道没有名字,用完了就销毁了。另外一种类型是命名管道,这个类型的管道需要通过mkfifo命令显式地创建,如下所示:
mkfifo hellohello就是这个管道的名称。管道以文件的形式存在,这也符合Linux里一切皆文件的原则。这个时候ls一下,可以看到这个文件的类型是p,就是pipe的意思,如下所示:
# ls -l
prw-r--r-- 1 root root 0 May 21 23:29 hello
接下来可以往管道里面写入东西,例如写入一个字符串,如下所示:
# echo "hello world" > hello这个时候管道里面的内容没有被读出,这个命令就是停在这里的,这说明当一个进程要把它的输出交接给另一个进程做输入,当没有交接完毕的时候,前一个进程是不能撒手不管的。这个时候就需要重新连接一个terminal。在终端中,用下面的命令读取管道里面的内容:
# cat < hello
hello world
一方面能够看到,管道里面的内容被读取出来,打印到了终端上;另一方面,前一个命令行终端中的echo命令正常退出了,也即交接完毕。但可以看到,管道的使用模式不适合进程间频繁的交换数据,进程间频繁沟通的效率较为低下,就像所谓软件开发中的瀑布模型。
2. 因此,可以用消息队列的方式来达到频繁沟通的目的,就像邮件那样。和管道将信息一股脑地从一个进程倒给另一个进程不同,消息队列发送数据时,会分成一个一个独立的数据单元也就是消息体,每个消息体都是固定大小的存储块,在字节流上不连续。这个消息结构的定义如下所示,这里面的类型type和正文text没有强制规定,只要消息的发送方和接收方约定好即可:
struct msg_buffer {
long mtype;
char mtext[1024];
};
接下来需要创建一个消息队列,使用msgget函数。这个函数需要有一个参数key,这是消息队列的唯一标识。如何保持唯一性呢?这个还是和文件关联,可以指定一个文件,ftok会根据这个文件的inode,生成一个近乎唯一的key,只要在这个消息队列的生命周期内,这个文件不要被删除就可以了。只要不删除,无论什么时刻再调用ftok,也会得到同样的key。这种key的使用方式在这里会经常遇到,因为它们都属于System V IPC进程间通信机制体系中。创建消息队列的实现如下所示:
#include
#include
#include
int main() {
int messagequeueid;
key_t key;
if((key = ftok("/root/messagequeue/messagequeuekey", 1024)) < 0)
{
perror("ftok error");
exit(1);
}
printf("Message Queue key: %d.\n", key);
if ((messagequeueid = msgget(key, IPC_CREAT|0777)) == -1)
{
perror("msgget error");
exit(1);
}
printf("Message queue id: %d.\n", messagequeueid);
}
在运行上面这个程序之前,先使用命令touch messagequeuekey创建一个文件,然后多次执行的结果就会像下面这样:
# ./a.out
Message Queue key: 92536.
Message queue id: 32768.
System V IPC体系有一个统一的命令行工具:ipcmk,ipcs和ipcrm分别用于创建、查看和删除IPC对象。例如,ipcs -q就能看到上面创建的消息队列对象,如下所示:
# ipcs -q
------ Message Queues --------
key msqid owner perms used-bytes messages
0x00016978 32768 root 777 0 0
接下来看如何发送信息。发送消息主要调用msgsnd函数。第一个参数是message queue的id,第二个参数是消息的结构体,第三个参数是消息的长度,最后一个参数是flag。这里IPC_NOWAIT表示发送的时候不阻塞,直接返回。下面的这段程序,getopt_long、do-while循环以及switch,是用来解析命令行参数的:
#include
#include
#include
#include
#include
struct msg_buffer {
long mtype;
char mtext[1024];
};
int main(int argc, char *argv[]) {
int next_option;
const char* const short_options = "i:t:m:";
const struct option long_options[] = {
{ "id", 1, NULL, 'i'},
{ "type", 1, NULL, 't'},
{ "message", 1, NULL, 'm'},
{ NULL, 0, NULL, 0 }
};
int messagequeueid = -1;
struct msg_buffer buffer;
buffer.mtype = -1;
int len = -1;
char * message = NULL;
do {
next_option = getopt_long (argc, argv, short_options, long_options, NULL);
switch (next_option)
{
case 'i':
messagequeueid = atoi(optarg);
break;
case 't':
buffer.mtype = atol(optarg);
break;
case 'm':
message = optarg;
len = strlen(message) + 1;
if (len > 1024) {
perror("message too long.");
exit(1);
}
memcpy(buffer.mtext, message, len);
break;
default:
break;
}
}while(next_option != -1);
if(messagequeueid != -1 && buffer.mtype != -1 && len != -1 && message != NULL){
if(msgsnd(messagequeueid, &buffer, len, IPC_NOWAIT) == -1){
perror("fail to send message.");
exit(1);
}
} else {
perror("arguments error");
}
return 0;
}
命令行参数的格式定义在long_options里面。每一项的第一个成员“id”、“type“、“message”是参数选项的全称,第二个成员都为1,表示参数选项后面要跟参数,最后一个成员’i’、‘t’、'm’是参数选项的简称。接下来可以编译并运行上面的发送程序,如下所示:
gcc -o send sendmessage.c
./send -i 32768 -t 123 -m "hello world"
接下来看如何收消息。收消息主要调用msgrcv函数,第一个参数是message queue的id,第二个参数是消息的结构体,第三个参数是可接受的最大长度,第四个参数是消息类型, 最后一个参数是flag,这里IPC_NOWAIT表示接收的时候不阻塞,直接返回。接收消息的代码实现如下所示:
#include
#include
#include
#include
#include
struct msg_buffer {
long mtype;
char mtext[1024];
};
int main(int argc, char *argv[]) {
int next_option;
const char* const short_options = "i:t:";
const struct option long_options[] = {
{ "id", 1, NULL, 'i'},
{ "type", 1, NULL, 't'},
{ NULL, 0, NULL, 0 }
};
int messagequeueid = -1;
struct msg_buffer buffer;
long type = -1;
do {
next_option = getopt_long (argc, argv, short_options, long_options, NULL);
switch (next_option)
{
case 'i':
messagequeueid = atoi(optarg);
break;
case 't':
type = atol(optarg);
break;
default:
break;
}
}while(next_option != -1);
if(messagequeueid != -1 && type != -1){
if(msgrcv(messagequeueid, &buffer, 1024, type, IPC_NOWAIT) == -1){
perror("fail to recv message.");
exit(1);
}
printf("received message type : %d, text: %s.", buffer.mtype, buffer.mtext);
} else {
perror("arguments error");
}
return 0;
}
接下来可以编译并运行这个发送程序。可以看到,如果有消息,可以正确地读到消息;如果没有,则返回没有消息,如下所示:
# ./recv -i 32768 -t 123
received message type : 123, text: hello world.
# ./recv -i 32768 -t 123
fail to recv message.: No message of desired type
3. 但是有时候,进程之间的沟通需要特别紧密,而且要分享一些比较大的数据。如果使用消息队列,就发现一方面数据的来去不及时;另外一方面,数据大小也有限制,所以这个时候,经常采取的方式就是共享内存模型。以前提到内存管理的时候,知道每个进程都有自己独立的虚拟内存空间,不同进程的虚拟内存空间映射到不同的物理内存中去。这个进程访问A地址和另一个进程访问A地址,其实访问的是不同的物理内存地址,对于数据的增删查改互不影响。
但是可以变通一下,拿出一块虚拟地址空间来,映射到相同的物理内存中。这样这个进程写入的东西,另外一个进程马上就能看到了,就不需要互相拷贝来拷贝去。共享内存也是System V IPC进程间通信机制体系中的,所以从它使用流程可以看到熟悉的面孔。
创建一个共享内存可以调用shmget。在这个体系中,创建一个IPC对象都是xxxget,这里面第一个参数是key,和msgget里面的key一样,都是唯一定位一个共享内存对象,也可以通过关联文件的方式实现唯一性。第二个参数是共享内存的大小。第三个参数如果是IPC_CREAT,同样表示创建一个新的,如下所示:
int shmget(key_t key, size_t size, int flag);创建完毕之后,可以通过ipcs命令查看这个共享内存,如下所示:
#ipcs --shmems
------ Shared Memory Segments ------
key shmid owner perms bytes nattch status
0x00000000 19398656 marc 600 1048576 2 dest
接下来,如果一个进程想要访问这一段共享内存,需要将这个内存加载到自己的虚拟地址空间的某个位置,通过shmat函数,就是attach的意思。其中addr就是要指定attach到这个地方。但是这个地址的设定难度比较大,除非对于内存布局非常熟悉,否则可能会attach到一个非法地址。所以,通常的做法是将addr设为NULL,让内核选一个合适的地址,返回值就是真正被attach的地方,如下所示:
void *shmat(int shm_id, const void *addr, int flag);如果共享内存使用完毕,可以通过shmdt解除绑定,然后通过shmctl将cmd设置为IPC_RMID,从而删除这个共享内存对象,如下所示:
int shmdt(void *addr);
int shmctl(int shm_id, int cmd, struct shmid_ds *buf);
4. 如果两个进程都同时写一个地址,那先写的那个进程会发现内容被别人覆盖了。所以这里就需要一种保护机制,使得同一个共享的资源,同一时间只能被一个进程访问。在System V IPC进程间通信机制体系中,早就想好了应对办法,就是信号量(Semaphore)。因此,信号量和共享内存往往要配合使用。信号量其实是一个计数器,主要用于实现进程间的互斥与同步,而不是用于存储进程间通信数据。
可以将信号量初始化为一个数值,来代表某种资源的总体数量。对于信号量来讲会定义两种原子操作,一个是P操作,称为申请资源操作。这个操作会申请将信号量的数值减去N,表示这些数量被他申请使用了,其他人不能用了。另一个是V操作,称为归还资源操作,这个操作会申请将信号量加上M,表示这些数量已经还给信号量了,其他人可以使用了。
所谓原子操作(Atomic Operation),就是任何一个最细单位的资源,都只能通过P操作借给某一个进程,不能同时借给两个进程,必须分个先来后到。如果想创建一个信号量,可以通过semget函数,又是xxxget,第一个参数key也是类似的,第二个参数num_sems不是指资源的数量,而是表示可以创建多少个信号量,形成一组信号量,也就是说,如果有多种资源需要管理,可以创建一个信号量组,如下所示:
int semget(key_t key, int num_sems, int sem_flags);接下来需要初始化信号量的总的资源数量。通过semctl函数,第一个参数semid是这个信号量组的id,第二个参数semnum才是在这个信号量组中某个信号量的id,第三个参数是命令,如果是初始化则用SETVAL,第四个参数是一个union,如果初始化应该用里面的val设置资源总量,如下所示:
int semctl(int semid, int semnum, int cmd, union semun args);
union semun
{
int val;
struct semid_ds *buf;
unsigned short int *array;
struct seminfo *__buf;
};
无论是P操作还是V操作,统一用semop函数。第一个参数还是信号量组的id,一次可以操作多个信号量。第三个参数numops就是有多少个操作,第二个参数将这些操作放在一个数组中,如下所示:
int semop(int semid, struct sembuf semoparray[], size_t numops);
struct sembuf
{
short sem_num; // 信号量组中对应的序号,0~sem_nums-1
short sem_op; // 信号量值在一次操作中的改变量
short sem_flg; // IPC_NOWAIT, SEM_UNDO
}
数组的每一项是一个struct sembuf,里面的第一个成员是这个操作的对象是哪个信号量。第二个成员就是要对这个信号量做多少改变。如果sem_op < 0,就请求sem_op的绝对值的资源。如果相应的资源数可以满足请求,则将该信号量的值减去sem_op的绝对值,函数成功返回。
当相应的资源数不能满足请求时,就要看sem_flg了。如果把sem_flg设置为IPC_NOWAIT,也就是没有资源也不等待,则semop函数出错返回EAGAIN表示过会重试。如果sem_flg没有指定IPC_NOWAIT,则进程挂起,直到当相应的资源数可以满足请求。若sem_op > 0,表示进程归还相应的资源数,将sem_op的值加到信号量的值上。如果有进程正在休眠等待此信号量,则唤醒它们。
5. 上面讲的进程间通信的方式,都是常规状态下的工作模式,就像平时的工作交接(管道),收发邮件(消息队列)、联合开发(共享内存与信号量)等,其实还有一种异常情况下的工作模式,叫信号。信号没有特别复杂的数据结构,就是用一个代号一样的数字。Linux提供了几十种信号分别代表不同的意义。信号之间依靠它们的值来区分。信号可以在任何时候发送给某一进程,进程需要为这个信号配置信号处理函数。当某个信号发生的时候,就立刻默认执行这个函数就可以了。这就相当于运维的系统应急手册,当遇到什么情况做什么事情,都事先准备好,出了事情照着做就可以了。
二、信号
6. 在Linux操作系统中,为了响应各种各样的事件,也是定义了非常多的信号。可以通过kill -l命令,查看所有的信号:
# kill -l
1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL 5) SIGTRAP
6) SIGABRT 7) SIGBUS 8) SIGFPE 9) SIGKILL 10) SIGUSR1
11) SIGSEGV 12) SIGUSR2 13) SIGPIPE 14) SIGALRM 15) SIGTERM
16) SIGSTKFLT 17) SIGCHLD 18) SIGCONT 19) SIGSTOP 20) SIGTSTP
21) SIGTTIN 22) SIGTTOU 23) SIGURG 24) SIGXCPU 25) SIGXFSZ
26) SIGVTALRM 27) SIGPROF 28) SIGWINCH 29) SIGIO 30) SIGPWR
31) SIGSYS 34) SIGRTMIN 35) SIGRTMIN+1 36) SIGRTMIN+2 37) SIGRTMIN+3
38) SIGRTMIN+4 39) SIGRTMIN+5 40) SIGRTMIN+6 41) SIGRTMIN+7 42) SIGRTMIN+8
43) SIGRTMIN+9 44) SIGRTMIN+10 45) SIGRTMIN+11 46) SIGRTMIN+12 47) SIGRTMIN+13
48) SIGRTMIN+14 49) SIGRTMIN+15 50) SIGRTMAX-14 51) SIGRTMAX-13 52) SIGRTMAX-12
53) SIGRTMAX-11 54) SIGRTMAX-10 55) SIGRTMAX-9 56) SIGRTMAX-8 57) SIGRTMAX-7
58) SIGRTMAX-6 59) SIGRTMAX-5 60) SIGRTMAX-4 61) SIGRTMAX-3 62) SIGRTMAX-2
63) SIGRTMAX-1 64) SIGRTMAX
这些信号都是什么作用呢?可以通过man 7 signal命令查看,里面会有一个列表:
Signal Value Action Comment
──────────────────────────────────────────────────────────────────────
SIGHUP 1 Term Hangup detected on controlling terminal
or death of controlling process
SIGINT 2 Term Interrupt from keyboard
SIGQUIT 3 Core Quit from keyboard
SIGILL 4 Core Illegal Instruction
SIGABRT 6 Core Abort signal from abort(3)
SIGFPE 8 Core Floating point exception
SIGKILL 9 Term Kill signal
SIGSEGV 11 Core Invalid memory reference
SIGPIPE 13 Term Broken pipe: write to pipe with no
readers
SIGALRM 14 Term Timer signal from alarm(2)
SIGTERM 15 Term Termination signal
SIGUSR1 30,10,16 Term User-defined signal 1
SIGUSR2 31,12,17 Term User-defined signal 2
……
就像应急预案里面给出的一样,每个信号都有一个唯一的ID,还有遇到这个信号时的默认操作。一旦有信号产生,就有下面这几种用户进程对信号的处理方式:
(1)执行默认操作。Linux对每种信号都规定了默认操作,例如上面列表中的Term,就是终止进程的意思。Core 的意思是Core Dump,也即终止进程后,通过Core Dump将当前进程的运行状态保存在文件里面,方便程序员事后进行分析问题在哪里。
(2)捕捉信号。可以为信号定义一个信号处理函数,当信号发生时就执行相应的信号处理函数。
(3)忽略信号。当不希望处理某些信号的时候,就可以忽略该信号不做任何处理。有两个信号是应用进程无法捕捉和忽略的,即SIGKILL和SEGSTOP,它们用于在任何时候中断或结束某一进程。
7. 接下来看一下信号处理最常见的流程。这个过程主要是分成两步,第一步是注册信号处理函数。第二步是发送信号。现在先主要看第一步。如果不想让某个信号执行默认操作,一种方法就是对特定的信号注册相应的信号处理函数,设置信号处理方式的是signal函数,如下所示:
typedef void (*sighandler_t)(int);
sighandler_t signal(int signum, sighandler_t handler);
这其实就是定义一个方法,并且将这个方法和某个信号关联起来。当这个进程遇到这个信号的时候,就执行这个方法。如果在Linux下面执行man signal的话,会发现Linux不建议直接用这个方法,而是改用sigaction,定义如下:
int sigaction(int signum, const struct sigaction *act,
struct sigaction *oldact);
这两者的区别在哪里呢?其实它还是将信号和一个动作进行关联,只不过这个动作由一个结构struct sigaction表示了,如下所示:
struct sigaction {
__sighandler_t sa_handler;
unsigned long sa_flags;
__sigrestore_t sa_restorer;
sigset_t sa_mask; /* mask last for extensibility */
};
和signal类似的是,这里面还是有__sighandler_t。但是,其他成员变量可以更加细致地控制信号处理的行为,而signal 函数没有机会设置这些。需要注意的是,signal不是系统调用,而是glibc封装的一个函数。这样就像man signal里面写的一样,不同的实现方式设置的参数会不同,会导致行为的不同。例如在glibc里面会看到了这样一个实现:
# define signal __sysv_signal
__sighandler_t
__sysv_signal (int sig, __sighandler_t handler)
{
struct sigaction act, oact;
......
act.sa_handler = handler;
__sigemptyset (&act.sa_mask);
act.sa_flags = SA_ONESHOT | SA_NOMASK | SA_INTERRUPT;
act.sa_flags &= ~SA_RESTART;
if (__sigaction (sig, &act, &oact) < 0)
return SIG_ERR;
return oact.sa_handler;
}
weak_alias (__sysv_signal, sysv_signal)
在这里面sa_flags进行了默认的设置。SA_ONESHOT的意思就是,这里设置的信号处理函数仅仅起作用一次。用完了一次后,就设置回默认行为。这其实并不是用户想看到的,毕竟一旦安装了一个信号处理函数,肯定希望它一直起作用,直到显式地关闭它。
另外一个设置就是SA_NOMASK即不一次后重置。通过__sigemptyset,将sa_mask设置为空,这样的设置表示在这个信号处理函数执行过程中,如果再有其他信号,哪怕相同的信号到来时,这个信号处理函数会被中断。如果一个信号处理函数真的被其他信号中断,其实问题也不大,因为当处理完了其他的信号处理函数后,还会回来接着处理这个信号处理函数。但是对于相同的信号就有点尴尬了,这就需要这个信号处理函数写的比较有技巧了。
例如,对于这个信号的处理过程中,要操作某个数据结构,因为是相同的信号,很可能操作的是同一个实例,这样同步、死锁这些都要想好。其实一般的思路应该是,当某一个信号的信号处理函数运行的时候,暂时屏蔽这个信号的再一次响应。屏蔽并不意味着信号一定丢失,而是暂存,这样能够做到信号处理函数对于相同的信号,处理完一个再处理下一个,这样信号处理函数的逻辑要简单得多。
还有一个设置就是设置了SA_INTERRUPT,清除了SA_RESTART。这是什么意思呢?我们知道信号的到来时间是不可预期的,有可能程序正在调用某个漫长系统调用的时候(可以运行man 7 signal命令,在这里找Interruption of system calls and library functions by signal handlers的部分,里面说的非常详细),这个时候一个信号来了,会中断这个系统调用,去执行信号处理函数。
那执行完了系统调用怎么办呢?这时候有两种处理方法,一种就是SA_INTERRUPT,即系统调用被中断了就不再重试这个系统调用了,而是直接返回一个-EINTR常量,告诉调用方这个系统调用被信号中断了,但是怎么处理自己看着办。如果是这样的话,调用方可以根据自己的逻辑,重新调用或者直接返回,这会使得代码非常复杂,在所有系统调用的返回值判断里面,都要特殊判断一下这个值。
另外一种处理方法是SA_RESTART。这个时候系统调用会被自动重新启动,不需要调用方自己写代码。当然也可能存在问题,例如从终端读入一个字符,这个时候用户在终端输入一个'a'字符,在处理'a'字符的时候被信号中断了,等信号处理完毕,再次读入一个字符的时候,如果用户不再输入,就停在那里了,需要用户再次输入同一个字符。因而建议使用sigaction函数,根据自己的需要定制参数。
8. 接下来看sigaction具体做了些什么。还记得系统调用中glibc里面有个文件syscalls.list,这里面定义了库函数调用哪些系统调用,在这里找到了sigaction,如下所示:
sigaction - sigaction i:ipp __sigaction sigaction接下来在glibc中,__sigaction会调 __libc_sigaction,并最终调用的系统调用是rt_sigaction,如下所示:
int
__sigaction (int sig, const struct sigaction *act, struct sigaction *oact)
{
......
return __libc_sigaction (sig, act, oact);
}
int
__libc_sigaction (int sig, const struct sigaction *act, struct sigaction *oact)
{
int result;
struct kernel_sigaction kact, koact;
if (act)
{
kact.k_sa_handler = act->sa_handler;
memcpy (&kact.sa_mask, &act->sa_mask, sizeof (sigset_t));
kact.sa_flags = act->sa_flags | SA_RESTORER;
kact.sa_restorer = &restore_rt;
}
result = INLINE_SYSCALL (rt_sigaction, 4,
sig, act ? &kact : NULL,
oact ? &koact : NULL, _NSIG / 8);
if (oact && result >= 0)
{
oact->sa_handler = koact.k_sa_handler;
memcpy (&oact->sa_mask, &koact.sa_mask, sizeof (sigset_t));
oact->sa_flags = koact.sa_flags;
oact->sa_restorer = koact.sa_restorer;
}
return result;
}
这也是很多人看信号处理内核实现的时候,比较困惑的地方。例如内核代码注释里面会说,系统调用signal是为了兼容过去,系统调用sigaction也是为了兼容过去,连参数都变成了struct compat_old_sigaction,所以说库函数虽然调用的是sigaction,到了系统调用层调用的可不是系统调用sigaction,而是系统调用rt_sigaction,如下所示:
SYSCALL_DEFINE4(rt_sigaction, int, sig,
const struct sigaction __user *, act,
struct sigaction __user *, oact,
size_t, sigsetsize)
{
struct k_sigaction new_sa, old_sa;
int ret = -EINVAL;
......
if (act) {
if (copy_from_user(&new_sa.sa, act, sizeof(new_sa.sa)))
return -EFAULT;
}
ret = do_sigaction(sig, act ? &new_sa : NULL, oact ? &old_sa : NULL);
if (!ret && oact) {
if (copy_to_user(oact, &old_sa.sa, sizeof(old_sa.sa)))
return -EFAULT;
}
out:
return ret;
}
在rt_sigaction里面,将用户态的struct sigaction结构拷贝为内核态的k_sigaction,然后调用do_sigaction。do_sigaction也很简单,还记得进程内核的数据结构里,struct task_struct里面有一个成员sighand,里面有一个action,这是一个数组,下标是信号,内容就是信号处理函数,do_sigaction就是设置sighand里的信号处理函数,如下所示:
int do_sigaction(int sig, struct k_sigaction *act, struct k_sigaction *oact)
{
struct task_struct *p = current, *t;
struct k_sigaction *k;
sigset_t mask;
......
k = &p->sighand->action[sig-1];
spin_lock_irq(&p->sighand->siglock);
if (oact)
*oact = *k;
if (act) {
sigdelsetmask(&act->sa.sa_mask,
sigmask(SIGKILL) | sigmask(SIGSTOP));
*k = *act;
......
}
spin_unlock_irq(&p->sighand->siglock);
return 0;
}
至此,信号处理函数的注册已经完成了。
9. 上面讲了如何通过API注册一个信号处理函数,整个过程如下图所示:
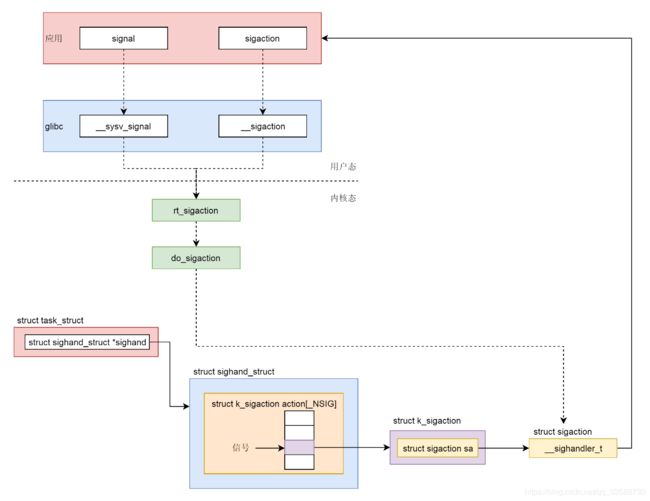
(1)在用户程序里面有两个函数可以调用,一个是signal,一个是sigaction,推荐使用sigaction。
(2)用户程序调用的是Glibc里面的函数,signal调用的是__sysv_signal,里面默认设置了一些参数,使得signal的功能受到了限制,sigaction调用的是__sigaction,参数用户可以任意设定。
(3)无论是__sysv_signal还是__sigaction,调用的都是统一的一个系统调用rt_sigaction。
(4)在内核中,rt_sigaction调用的是do_sigaction设置信号处理函数。在每一个进程的task_struct里面,都有一个sighand指向struct sighand_struct,里面是一个数组,下标是信号,里面的内容是信号处理函数。
10. 有时候在终端输入某些组合键时,会给进程发送信号,例如Ctrl+C产生SIGINT信号,Ctrl+Z产生SIGTSTP信号。有时硬件异常也会产生信号,比如执行了除以0的指令,CPU就会产生异常,然后把SIGFPE信号发送给进程。再比如进程访问了非法内存,内存管理模块就会产生异常,然后把信号SIGSEGV发送给进程。
这里同样是硬件产生的,对于中断和信号还是要加以区别。前面讲过中断要注册中断处理函数,但是中断处理函数是在内核驱动里面的,信号也要注册信号处理函数,信号处理函数是在用户态进程里面的。对于硬件触发的,无论是中断还是信号,肯定是先到内核的,然后内核对于中断和信号处理方式不同。一个是完全在内核里面处理完毕,一个是将信号放在对应的进程task_struct里信号相关的数据结构里面,然后等待进程在用户态去处理。
当然有些严重的信号,内核会把进程干掉。但是这也能看出来,中断和信号的严重程度不一样,信号影响的往往是某一个进程,处理慢了甚至错了,也不过这个进程被干掉,而中断影响的是整个系统,一旦中断处理中有了bug,可能整个Linux都挂了。
有时候内核在某些情况下,也会给进程发送信号。例如向读端已关闭的管道写数据时产生SIGPIPE信号,当子进程退出时要给父进程发送SIG_CHLD信号等。最直接的发送信号的方法就是,通过命令kill来发送信号了。例如kill -9 pid可以发送信号给一个进程杀死它。另外还可以通过kill或者sigqueue系统调用,发送信号给某个进程,也可以通过tkill或者tgkill发送信号给某个线程。虽然方式多种多样,但是最终都是调用了do_send_sig_info函数,将信号放在相应的task_struct的信号数据结构中。do_send_sig_info会调用send_signal,进而调用__send_signal,如下所示:
SYSCALL_DEFINE2(kill, pid_t, pid, int, sig)
{
struct siginfo info;
info.si_signo = sig;
info.si_errno = 0;
info.si_code = SI_USER;
info.si_pid = task_tgid_vnr(current);
info.si_uid = from_kuid_munged(current_user_ns(), current_uid());
return kill_something_info(sig, &info, pid);
}
static int __send_signal(int sig, struct siginfo *info, struct task_struct *t,
int group, int from_ancestor_ns)
{
struct sigpending *pending;
struct sigqueue *q;
int override_rlimit;
int ret = 0, result;
......
pending = group ? &t->signal->shared_pending : &t->pending;
......
if (legacy_queue(pending, sig))
goto ret;
if (sig < SIGRTMIN)
override_rlimit = (is_si_special(info) || info->si_code >= 0);
else
override_rlimit = 0;
q = __sigqueue_alloc(sig, t, GFP_ATOMIC | __GFP_NOTRACK_FALSE_POSITIVE,
override_rlimit);
if (q) {
list_add_tail(&q->list, &pending->list);
switch ((unsigned long) info) {
case (unsigned long) SEND_SIG_NOINFO:
q->info.si_signo = sig;
q->info.si_errno = 0;
q->info.si_code = SI_USER;
q->info.si_pid = task_tgid_nr_ns(current,
task_active_pid_ns(t));
q->info.si_uid = from_kuid_munged(current_user_ns(), current_uid());
break;
case (unsigned long) SEND_SIG_PRIV:
q->info.si_signo = sig;
q->info.si_errno = 0;
q->info.si_code = SI_KERNEL;
q->info.si_pid = 0;
q->info.si_uid = 0;
break;
default:
copy_siginfo(&q->info, info);
if (from_ancestor_ns)
q->info.si_pid = 0;
break;
}
userns_fixup_signal_uid(&q->info, t);
}
......
out_set:
signalfd_notify(t, sig);
sigaddset(&pending->signal, sig);
complete_signal(sig, t, group);
ret:
return ret;
}
在这里看到,在进程数据结构中task_struct里面的sigpending。在上面代码中,先是要决定应该用哪个sigpending,这就要看发送的信号是给进程的还是线程的。如果是kill发送的,也就是发送给整个进程的,就应该发送给 t->signal->shared_pending,这里面是整个进程所有线程共享的信号;如果是tkill发送的,也就是发给某个线程的,就应该发给t->pending,这里是这个线程的task_struct独享的信号。struct sigpending里面有两个成员,一个是一个集合sigset_t,表示都收到了哪些信号,还有一个链表也表示收到了哪些信号,它的结构如下:
struct sigpending {
struct list_head list;
sigset_t signal;
};
如果都表示收到了信号,这两者有什么区别呢?接着往下看__send_signal里的代码。接下来要调用legacy_queue,如果满足条件那就直接退出。那legacy_queue里面判断的是什么条件呢?来看它的代码:
static inline int legacy_queue(struct sigpending *signals, int sig)
{
return (sig < SIGRTMIN) && sigismember(&signals->signal, sig);
}
#define SIGRTMIN 32
#define SIGRTMAX _NSIG
#define _NSIG 64
当信号小于SIGRTMIN,也即32时,如果发现这个信号已经在集合里面了,就直接退出了,这样会造成信号的丢失。例如发送给进程100个SIGUSR1(对应的信号为10),那最终能够被信号处理函数处理的信号有多少就不好说了,比如总共5个SIGUSR1,分别是A、B、C、D、E。如果这五个信号来得太密,A来了但是信号处理函数还没来得及处理,B、C、D、E就都来了。根据上面的逻辑,因为A已经将SIGUSR1放在sigset_t集合中了,因而后面四个都要丢失。
如果是另一种情况,A来了已经被信号处理函数处理了,内核在调用信号处理函数之前,会将集合中的标志位清除,这个时候B再来,B还是会进入集合,还是会被处理,也就不会丢。这样信号能够处理多少,和信号处理函数什么时候被调用,信号多大频率被发送,都有关系,而且从后面的分析可以知道,信号处理函数的调用时间也是不确定的。因此小于32的信号如此不靠谱,就称它为不可靠信号。
11. 如果大于32的信号是什么情况呢?接下来__sigqueue_alloc会分配一个struct sigqueue对象,然后通过list_add_tail挂在struct sigpending里面的链表上。这样就靠谱多了。如果发送过来100个信号,变成链表上的100项都不会丢,哪怕相同的信号发送多遍,也处理多遍。因此,大于32的信号称为可靠信号。当然队列的长度也是有限的,如果执行ulimit命令可以看到,这个限制pending signals (-i) 15408。当信号挂到了task_struct结构之后,最后需要调用complete_signal。这里面的逻辑也很简单,就是说既然这个进程有了一个新的信号,赶紧找一个线程处理一下吧:
static void complete_signal(int sig, struct task_struct *p, int group)
{
struct signal_struct *signal = p->signal;
struct task_struct *t;
/*
* Now find a thread we can wake up to take the signal off the queue.
*
* If the main thread wants the signal, it gets first crack.
* Probably the least surprising to the average bear.
*/
if (wants_signal(sig, p))
t = p;
else if (!group || thread_group_empty(p))
/*
* There is just one thread and it does not need to be woken.
* It will dequeue unblocked signals before it runs again.
*/
return;
else {
/*
* Otherwise try to find a suitable thread.
*/
t = signal->curr_target;
while (!wants_signal(sig, t)) {
t = next_thread(t);
if (t == signal->curr_target)
return;
}
signal->curr_target = t;
}
......
/*
* The signal is already in the shared-pending queue.
* Tell the chosen thread to wake up and dequeue it.
*/
signal_wake_up(t, sig == SIGKILL);
return;
}
在找到了一个进程或者线程的task_struct之后,要调用signal_wake_up来企图唤醒它,signal_wake_up会调用signal_wake_up_state,如下所示:
void signal_wake_up_state(struct task_struct *t, unsigned int state)
{
set_tsk_thread_flag(t, TIF_SIGPENDING);
if (!wake_up_state(t, state | TASK_INTERRUPTIBLE))
kick_process(t);
}
signal_wake_up_state里面主要做了两件事情。第一就是给这个线程设置TIF_SIGPENDING表示信号来了,这就说明其实信号的处理和进程的调度是采取这样一种类似的机制:当发现一个进程应该被调度的时候,并不直接把它赶下来,而是设置一个标识位TIF_NEED_RESCHED表示等待调度,然后等待系统调用结束或者中断处理结束,从内核态返回用户态的时候,调用schedule函数进行调度。信号也是类似的,当信号来的时候并不直接处理这个信号,而是设置一个标识位TIF_SIGPENDING,来表示已经有信号等待处理,同样等待系统调用结束,或者中断处理结束,从内核态返回用户态的时候,再进行信号的处理。
signal_wake_up_state的第二件事情,就是试图唤醒这个进程或者线程。wake_up_state会调用try_to_wake_up方法,就是将这个进程或者线程设置为TASK_RUNNING状态准备被调度,然后放在运行队列中,这个时候随着时钟不断的滴答,迟早会被调用。如果wake_up_state返回0,说明进程或者线程已经是TASK_RUNNING状态了,如果它在另外一个CPU上运行,则调用kick_process发送一个处理器间中断,强制那个进程或者线程重新调度,重新调度完毕后,会返回用户态运行,这是一个时机,会检查TIF_SIGPENDING标识位。
12. 这样,信号已经发送到位了,什么时候真正处理它呢?就是在从系统调用或者中断返回的时候,无论是从系统调用返回还是从中断返回,都会调用exit_to_usermode_loop,接下来重点关注_TIF_SIGPENDING标识位,如下所示:
static void exit_to_usermode_loop(struct pt_regs *regs, u32 cached_flags)
{
while (true) {
......
if (cached_flags & _TIF_NEED_RESCHED)
schedule();
......
/* deal with pending signal delivery */
if (cached_flags & _TIF_SIGPENDING)
do_signal(regs);
......
if (!(cached_flags & EXIT_TO_USERMODE_LOOP_FLAGS))
break;
}
}
如果在前一个环节中已经设置了_TIF_SIGPENDING,就会调用do_signal进行处理,如下所示:
void do_signal(struct pt_regs *regs)
{
struct ksignal ksig;
if (get_signal(&ksig)) {
/* Whee! Actually deliver the signal. */
handle_signal(&ksig, regs);
return;
}
/* Did we come from a system call? */
if (syscall_get_nr(current, regs) >= 0) {
/* Restart the system call - no handlers present */
switch (syscall_get_error(current, regs)) {
case -ERESTARTNOHAND:
case -ERESTARTSYS:
case -ERESTARTNOINTR:
regs->ax = regs->orig_ax;
regs->ip -= 2;
break;
case -ERESTART_RESTARTBLOCK:
regs->ax = get_nr_restart_syscall(regs);
regs->ip -= 2;
break;
}
}
restore_saved_sigmask();
}
do_signal会调用handle_signal。按理说,信号处理就是调用用户提供的信号处理函数,但是这事儿没有看起来这么简单,因为信号处理函数是在用户态的,这里还在内核态没法直接调用。这样又要来回忆系统调用的过程了,这个进程当时在用户态执行到某一行Line A,调用了一个系统调用,在进入内核的那一刻,在内核pt_regs里面保存了用户态执行到Line A这个状态。现在从系统调用返回用户态了,按说应该从pt_regs拿出Line A,然后接着Line A执行下去,但是为了响应信号不能回到用户态的时候返回Line A了,而是应该返回信号处理函数的起始地址。handle_signal的实现如下所示:
static void
handle_signal(struct ksignal *ksig, struct pt_regs *regs)
{
bool stepping, failed;
......
/* Are we from a system call? */
if (syscall_get_nr(current, regs) >= 0) {
/* If so, check system call restarting.. */
switch (syscall_get_error(current, regs)) {
case -ERESTART_RESTARTBLOCK:
case -ERESTARTNOHAND:
regs->ax = -EINTR;
break;
case -ERESTARTSYS:
if (!(ksig->ka.sa.sa_flags & SA_RESTART)) {
regs->ax = -EINTR;
break;
}
/* fallthrough */
case -ERESTARTNOINTR:
regs->ax = regs->orig_ax;
regs->ip -= 2;
break;
}
}
......
failed = (setup_rt_frame(ksig, regs) < 0);
......
signal_setup_done(failed, ksig, stepping);
}
这个时候就需要干预和自己来定制pt_regs了。这时要看是否从系统调用中返回。如果是从系统调用返回的话,还要区分是从系统调用中正常返回,还是在一个非运行状态的系统调用中,因为被信号中断而返回。这里解析一个最复杂的场景,还记得以前解析进程调度时举的一个例子,就是从一个tap网卡中读取数据。当时主要关注schedule那一行,即如果发现没有数据的时候就调用schedule(),自己进入等待状态然后将CPU让给其他进程。具体的代码如下:
static ssize_t tap_do_read(struct tap_queue *q,
struct iov_iter *to,
int noblock, struct sk_buff *skb)
{
......
while (1) {
if (!noblock)
prepare_to_wait(sk_sleep(&q->sk), &wait,
TASK_INTERRUPTIBLE);
/* Read frames from the queue */
skb = skb_array_consume(&q->skb_array);
if (skb)
break;
if (noblock) {
ret = -EAGAIN;
break;
}
if (signal_pending(current)) {
ret = -ERESTARTSYS;
break;
}
/* Nothing to read, let's sleep */
schedule();
}
......
}
这里关注和信号相关的部分,这其实是一个信号中断系统调用的典型逻辑。首先把当前进程或者线程的状态设置为TASK_INTERRUPTIBLE,这样才能是使这个系统调用可以被中断。其次,可以被中断的系统调用往往是比较慢的调用,并且会因为数据不就绪而通过schedule让出CPU进入等待状态。在发送信号的时候,除了设置这个进程和线程的_TIF_SIGPENDING标识位之外,还试图唤醒这个进程或者线程,也就是将它从TASK_INTERRUPTIBLE等待状态中设置为TASK_RUNNING。
当这个进程或者线程再次运行的时候,会从schedule函数中返回,然后再次进入while循环。由于这个进程或者线程是由信号唤醒的,而不是因为数据来了而唤醒的,因而是读不到数据的,但是在signal_pending函数中检测到了_TIF_SIGPENDING标识位,这说明系统调用没有真的做完,于是返回一个错误ERESTARTSYS,然后带着这个错误从系统调用返回。
然后到了exit_to_usermode_loop->do_signal->handle_signal。在这里面当发现出现错误ERESTARTSYS的时候,就知道这是从一个没有调用完的系统调用返回的,设置系统调用错误码EINTR。接下来就开始折腾pt_regs了,主要通过调用setup_rt_frame->__setup_rt_frame,如下所示:
static int __setup_rt_frame(int sig, struct ksignal *ksig,
sigset_t *set, struct pt_regs *regs)
{
struct rt_sigframe __user *frame;
void __user *fp = NULL;
int err = 0;
frame = get_sigframe(&ksig->ka, regs, sizeof(struct rt_sigframe), &fp);
......
put_user_try {
......
/* Set up to return from userspace. If provided, use a stub
already in userspace. */
/* x86-64 should always use SA_RESTORER. */
if (ksig->ka.sa.sa_flags & SA_RESTORER) {
put_user_ex(ksig->ka.sa.sa_restorer, &frame->pretcode);
}
} put_user_catch(err);
err |= setup_sigcontext(&frame->uc.uc_mcontext, fp, regs, set->sig[0]);
err |= __copy_to_user(&frame->uc.uc_sigmask, set, sizeof(*set));
/* Set up registers for signal handler */
regs->di = sig;
/* In case the signal handler was declared without prototypes */
regs->ax = 0;
regs->si = (unsigned long)&frame->info;
regs->dx = (unsigned long)&frame->uc;
regs->ip = (unsigned long) ksig->ka.sa.sa_handler;
regs->sp = (unsigned long)frame;
regs->cs = __USER_CS;
......
return 0;
}
frame的类型是rt_sigframe,这个frame就是一个栈帧。在get_sigframe中会得到pt_regs的sp变量,也就是原来这个程序在用户态的栈顶指针,然后get_sigframe中会将sp减去sizeof(struct rt_sigframe),也就是把这个栈帧塞到了栈里面,然后又在__setup_rt_frame中把regs->sp设置成等于frame。这就相当于强行在程序原来的用户态的栈里面插入了一个栈帧,并在最后将regs->ip设置为用户定义的信号处理函数sa_handler。这意味着本来返回用户态应该接着原来的代码执行的,现在不了要执行sa_handler了。执行完了以后按照函数栈的规则,弹出上一个栈帧来,也就是弹出了之前硬塞进去的frame。
13. 那如果假设sa_handler成功返回了,怎么回到程序原来在用户态运行的地方呢?玄机就在frame里面。要想恢复原来运行的地方,首先原来的pt_regs不能丢,是在setup_sigcontext里面,将原来的pt_regs保存在了frame中的uc_mcontext里面。
另外很重要的一点,程序如何跳过去呢?在__setup_rt_frame中还有一个不引起重视的操作,那就是通过put_user_ex,将sa_restorer放到了frame->pretcode里面,而且还是按照函数栈的规则,函数栈里面包含了函数执行完跳回去的地址。当sa_handler执行完之后,弹出的函数栈是frame,也就应该跳到sa_restorer的地址。
这是什么地址呢?在前面sigaction介绍的时候就没有介绍它,在Glibc的__libc_sigaction函数中也没有注意到,它被赋值成了restore_rt。这其实就是sa_handler执行完毕之后,马上要执行的函数。从名字就能感觉到,它将恢复原来程序运行的地方。在Glibc中可以找到它的定义,它竟然调用了一个系统调用,系统调用号为__NR_rt_sigreturn,如下所示:
RESTORE (restore_rt, __NR_rt_sigreturn)
#define RESTORE(name, syscall) RESTORE2 (name, syscall)
# define RESTORE2(name, syscall) \
asm \
( \
".LSTART_" #name ":\n" \
" .type __" #name ",@function\n" \
"__" #name ":\n" \
" movq $" #syscall ", %rax\n" \
" syscall\n" \
......
可以在内核里面找到__NR_rt_sigreturn对应的系统调用,如下所示:
asmlinkage long sys_rt_sigreturn(void)
{
struct pt_regs *regs = current_pt_regs();
struct rt_sigframe __user *frame;
sigset_t set;
unsigned long uc_flags;
frame = (struct rt_sigframe __user *)(regs->sp - sizeof(long));
if (__copy_from_user(&set, &frame->uc.uc_sigmask, sizeof(set)))
goto badframe;
if (__get_user(uc_flags, &frame->uc.uc_flags))
goto badframe;
set_current_blocked(&set);
if (restore_sigcontext(regs, &frame->uc.uc_mcontext, uc_flags))
goto badframe;
......
return regs->ax;
......
}
在这里面,把上次填充的那个rt_sigframe拿出来,然后restore_sigcontext将pt_regs恢复成为原来用户态的样子。从这个系统调用返回的时候,应用还误以为从上次的系统调用返回的。至此,整个信号处理过程才全部结束。
14. 信号的发送与处理是一个复杂的过程,这里来总结一下,如下图所示:
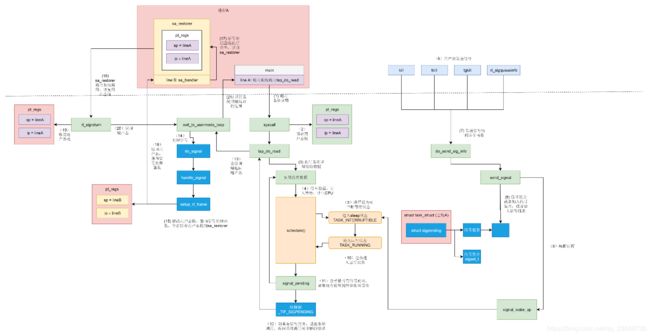
(1)假设有一个进程A,main函数里面调用系统调用进入内核。
(2)按照系统调用的原理,会将用户态栈的信息保存在pt_regs里面,即记住原来用户态是运行到了line A的地方。
(3)在内核中执行系统调用读取数据。
(4)当发现没有什么数据可读取的时候,只好进入睡眠状态,并且调用schedule让出CPU。
(5)将进程状态设置为TASK_INTERRUPTIBLE即可中断的睡眠状态,也就是如果有信号来的话是可以唤醒它的。
(6)其他的进程或者shell发送一个信号,有四个函数可以调用:kill、tkill、tgkill、rt_sigqueueinfo。
(7)四个发送信号的函数,在内核中最终都是调用do_send_sig_info。
(8)do_send_sig_info调用send_signal给进程A发送一个信号,其实就是找到进程A的task_struct,或者加入信号集合成为不可靠信号,或者加入信号链表成为可靠信号。
(9)do_send_sig_info调用signal_wake_up唤醒进程A。
(10)进程A重新进入运行状态TASK_RUNNING,一定会接着schedule运行。
(11)进程A被唤醒后,检查是否有信号到来,如果没有重新循环到一开始,尝试再次读取数据,如果还是没有数据,再次进入TASK_INTERRUPTIBLE即可中断的睡眠状态。
(12)当发现有信号到来的时候,就返回当前正在执行的系统调用,并返回一个错误表示系统调用被中断了。
(13)系统调用返回的时候,会调用exit_to_usermode_loop。这是一个处理信号的时机。
(14)调用do_signal开始处理信号。
(15)根据信号,得到信号处理函数sa_handler,然后修改pt_regs中的用户态栈的信息,让pt_regs指向sa_handler。同时修改用户态的栈,插入一个栈帧sa_restorer,里面保存了原来的指向line A的pt_regs,并且设置让sa_handler运行完毕后,跳到sa_restorer运行。
(16)返回用户态,由于pt_regs已经设置为sa_handler,则返回用户态执行sa_handler。
(17)sa_handler 执行完毕后,信号处理函数就执行完了,接着根据第15步对于用户态栈帧的修改,会跳到sa_restorer 运行。
(18)sa_restorer会调用系统调用rt_sigreturn再次进入内核。
(19)在内核中rt_sigreturn恢复原来的pt_regs,重新指向line A。
(20)从rt_sigreturn返回用户态,还是调用exit_to_usermode_loop。
(21)这次因为pt_regs已经指向line A了,于是就到了进程A中,接着系统调用之后运行,当然这个系统调用返回的是它被中断了没有执行完的错误。
三、管道
15. 先来看常用的匿名管道(Anonymous Pipes),即把多个命令串起来的竖线,背后的原理到底是什么。上次提到它是基于管道的,那管道如何创建呢?需要通过下面这个系统调用:
int pipe(int fd[2])在这里创建了一个管道pipe,返回了两个文件描述符,这表示管道的两端,一个是管道的读取端描述符fd[0],另一个是管道的写入端描述符fd[1]。来看在内核里面是如何实现的,如下所示:
SYSCALL_DEFINE1(pipe, int __user *, fildes)
{
return sys_pipe2(fildes, 0);
}
SYSCALL_DEFINE2(pipe2, int __user *, fildes, int, flags)
{
struct file *files[2];
int fd[2];
int error;
error = __do_pipe_flags(fd, files, flags);
if (!error) {
if (unlikely(copy_to_user(fildes, fd, sizeof(fd)))) {
......
error = -EFAULT;
} else {
fd_install(fd[0], files[0]);
fd_install(fd[1], files[1]);
}
}
return error;
}
在内核中,主要的逻辑在pipe2系统调用中。这里面要创建一个数组files,用来存放管道的两端的打开文件,另一个数组fd存放管道两端的文件描述符。如果调用__do_pipe_flags没有错误,那就调用fd_install,将两个fd和两个struct file关联起来,这一点和打开一个文件的过程很像了。来看__do_pipe_flags,这里面调用了create_pipe_files,然后生成了两个fd。从这里可以看出,fd[0]是用于读的,fd[1]是用于写的,如下所示:
static int __do_pipe_flags(int *fd, struct file **files, int flags)
{
int error;
int fdw, fdr;
......
error = create_pipe_files(files, flags);
......
error = get_unused_fd_flags(flags);
......
fdr = error;
error = get_unused_fd_flags(flags);
......
fdw = error;
fd[0] = fdr;
fd[1] = fdw;
return 0;
......
}
创建一个管道,大部分的逻辑其实都是在create_pipe_files函数里面实现的。之前提过,命名管道是创建在文件系统上的。从这里可以看出,匿名管道也是创建在文件系统上的,只不过是一种特殊的文件系统,创建一个特殊的文件,对应一个特殊的inode,就是这里面的get_pipe_inode,如下所示:
int create_pipe_files(struct file **res, int flags)
{
int err;
struct inode *inode = get_pipe_inode();
struct file *f;
struct path path;
......
path.dentry = d_alloc_pseudo(pipe_mnt->mnt_sb, &empty_name);
......
path.mnt = mntget(pipe_mnt);
d_instantiate(path.dentry, inode);
f = alloc_file(&path, FMODE_WRITE, &pipefifo_fops);
......
f->f_flags = O_WRONLY | (flags & (O_NONBLOCK | O_DIRECT));
f->private_data = inode->i_pipe;
res[0] = alloc_file(&path, FMODE_READ, &pipefifo_fops);
......
path_get(&path);
res[0]->private_data = inode->i_pipe;
res[0]->f_flags = O_RDONLY | (flags & O_NONBLOCK);
res[1] = f;
return 0;
......
}
从下面get_pipe_inode的实现可以看出,匿名管道来自一个特殊的文件系统pipefs。这个文件系统被挂载后,就得到了struct vfsmount *pipe_mnt,然后挂载的文件系统的superblock就变成了:pipe_mnt->mnt_sb,如下所示:
static struct file_system_type pipe_fs_type = {
.name = "pipefs",
.mount = pipefs_mount,
.kill_sb = kill_anon_super,
};
static int __init init_pipe_fs(void)
{
int err = register_filesystem(&pipe_fs_type);
if (!err) {
pipe_mnt = kern_mount(&pipe_fs_type);
}
......
}
static struct inode * get_pipe_inode(void)
{
struct inode *inode = new_inode_pseudo(pipe_mnt->mnt_sb);
struct pipe_inode_info *pipe;
......
inode->i_ino = get_next_ino();
pipe = alloc_pipe_info();
......
inode->i_pipe = pipe;
pipe->files = 2;
pipe->readers = pipe->writers = 1;
inode->i_fop = &pipefifo_fops;
inode->i_state = I_DIRTY;
inode->i_mode = S_IFIFO | S_IRUSR | S_IWUSR;
inode->i_uid = current_fsuid();
inode->i_gid = current_fsgid();
inode->i_atime = inode->i_mtime = inode->i_ctime = current_time(inode);
return inode;
......
}
从new_inode_pseudo函数创建一个inode,这里面开始填写inode的成员,这里和文件系统的很像,这里值得注意的是struct pipe_inode_info,这个结构里面有个成员是struct pipe_buffer *bufs。因此可以知道,所谓的匿名管道,其实就是内核里面的一串缓存。
16. 另外一个需要注意的是pipefifo_fops,将来对于文件描述符的操作,在内核里面都是对应这里面的操作,如下所示:
const struct file_operations pipefifo_fops = {
.open = fifo_open,
.llseek = no_llseek,
.read_iter = pipe_read,
.write_iter = pipe_write,
.poll = pipe_poll,
.unlocked_ioctl = pipe_ioctl,
.release = pipe_release,
.fasync = pipe_fasync,
};
回到create_pipe_files函数,创建完了inode,还需创建一个dentry和它对应。dentry和inode对应好了,就要开始创建struct file对象了。先创建用于写入的,对应的操作为pipefifo_fops;再创建读取的,对应的操作也为pipefifo_fops。然后把private_data设置为pipe_inode_info,这样从struct file这个层级上,就能直接操作底层的读写操作。
至此,一个匿名管道就创建成功了。如果对于fd[1]写入,调用的是pipe_write,向pipe_buffer里面写入数据;如果对于fd[0]的读入,调用的是pipe_read,也就是从pipe_buffer里面读取数据。但是这个时候,两个文件描述符都是在一个进程里面的,并没有起到进程间通信的作用,怎么样才能使得管道是跨两个进程的呢?
还记得创建进程调用的fork吗?在这里面,创建的子进程会复制父进程的struct files_struct,在这里面fd的数组会复制一份,但是fd指向的struct file对于同一个文件还是只有一份,这样就做到了,两个进程各有两个fd指向同一个struct file的模式,两个进程就可以通过各自的fd写入和读取同一个管道文件,实现跨进程通信了。
由于管道只能一端写入,另一端读出,所以上面的这种模式会造成混乱,因为父进程和子进程都可以写入,也都可以读出,通常的方法是父进程关闭读取的fd,只保留写入的fd,而子进程关闭写入的fd,只保留读取的fd,如果需要双向通行,则应该创建两个管道,如下所示:

一个典型的使用管道在父子进程之间的通信代码如下:
#include
#include
#include
#include
#include
#include
int main(int argc, char *argv[])
{
int fds[2];
if (pipe(fds) == -1)
perror("pipe error");
pid_t pid;
pid = fork();
if (pid == -1)
perror("fork error");
if (pid == 0){
close(fds[0]);
char msg[] = "hello world";
write(fds[1], msg, strlen(msg) + 1);
close(fds[1]);
exit(0);
} else {
close(fds[1]);
char msg[128];
read(fds[0], msg, 128);
close(fds[0]);
printf("message : %s\n", msg);
return 0;
}
}
到这里仅仅解析了使用管道进行父子进程之间的通信,但是在shell里面的不是这样的。在shell里面运行A|B的时候,A进程和B进程都是shell创建出来的子进程,A和B之间不存在父子关系。不过有了上面父子进程之间的管道这个基础,实现A和B之间的管道就方便多了。
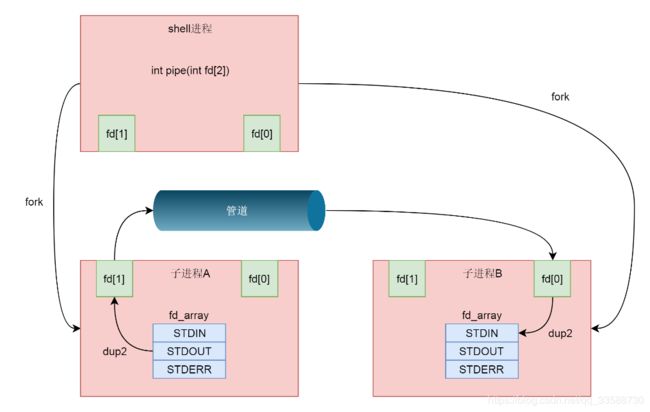
首先从shell创建子进程A,然后在shell和A之间建立一个管道,其中shell保留读取端,A进程保留写入端,然后shell再创建子进程B,这又是一次fork,所以shell里面保留的读取端的fd也被复制到了子进程B里面。这个时候相当于shell和B都保留读取端,只要shell主动关闭读取端就变成了一个管道,写入端在A进程,读取端在B进程,如下图所示:

17. 接下来要做的事情就是,将这个管道的两端和输入输出关联起来。这就要用到dup2系统调用了,如下所示:
int dup2(int oldfd, int newfd);这个系统调用将老的文件描述符赋值给新的文件描述符,让newfd的值和oldfd一样。在files_struct里面有这样一个表,下标是fd,内容指向一个打开的文件struct file,如下所示:
struct files_struct {
struct file __rcu * fd_array[NR_OPEN_DEFAULT];
}
在这个表里面前三项是定下来的,其中第零项STDIN_FILENO表示标准输入,第一项STDOUT_FILENO表示标准输出,第三项STDERR_FILENO表示错误输出。在A进程中,写入端可以做这样的操作:dup2(fd[1],STDOUT_FILENO),将STDOUT_FILENO(即第一项)不再指向标准输出,而是指向创建的管道文件,那么以后往标准输出写入的任何东西,都会写入管道文件。
在B进程中,读取端可以做这样的操作:dup2(fd[0],STDIN_FILENO),将STDIN_FILENO即第零项不再指向标准输入,而是指向创建的管道文件,那么以后从标准输入读取的任何东西,都来自于管道文件。至此才将A|B的功能完成,如下图所示:
18. 为了模拟A|B的情况,可以将前面的那一段代码,进一步修改成为下面这样:
#include
#include
#include
#include
#include
#include
int main(int argc, char *argv[])
{
int fds[2];
if (pipe(fds) == -1)
perror("pipe error");
pid_t pid;
pid = fork();
if (pid == -1)
perror("fork error");
if (pid == 0){
dup2(fds[1], STDOUT_FILENO);
close(fds[1]);
close(fds[0]);
execlp("ps", "ps", "-ef", NULL);
} else {
dup2(fds[0], STDIN_FILENO);
close(fds[0]);
close(fds[1]);
execlp("grep", "grep", "systemd", NULL);
}
return 0;
}
接下来看命名管道。在讲命令的时候提过,命名管道需要事先通过命令mkfifo进行创建。如果是通过代码创建命名管道,也有一个函数但不是一个系统调用,而是Glibc提供的函数,它的定义如下:
int
mkfifo (const char *path, mode_t mode)
{
dev_t dev = 0;
return __xmknod (_MKNOD_VER, path, mode | S_IFIFO, &dev);
}
int
__xmknod (int vers, const char *path, mode_t mode, dev_t *dev)
{
unsigned long long int k_dev;
......
/* We must convert the value to dev_t type used by the kernel. */
k_dev = (*dev) & ((1ULL << 32) - 1);
......
return INLINE_SYSCALL (mknodat, 4, AT_FDCWD, path, mode,
(unsigned int) k_dev);
}
Glibc的mkfif 函数会调用mknodat系统调用,记得之前提到字符设备时,创建一个字符设备的也是调用的mknod。这里命名管道也是一个设备,因而也用mknod,如下所示:
SYSCALL_DEFINE4(mknodat, int, dfd, const char __user *, filename, umode_t, mode, unsigned, dev)
{
struct dentry *dentry;
struct path path;
unsigned int lookup_flags = 0;
......
retry:
dentry = user_path_create(dfd, filename, &path, lookup_flags);
......
switch (mode & S_IFMT) {
......
case S_IFIFO: case S_IFSOCK:
error = vfs_mknod(path.dentry->d_inode,dentry,mode,0);
break;
}
......
}
对于mknod的解析在字符设备部分已经解析过了,即先是通过user_path_create对于这个管道文件创建一个dentry,然后因为是S_IFIFO所以调用vfs_mknod。由于这个管道文件是创建在一个普通文件系统上的,假设是在ext4文件上,于是vfs_mknod会调用ext4_dir_inode_operations的mknod,即会调用ext4_mknod,如下所示:
const struct inode_operations ext4_dir_inode_operations = {
......
.mknod = ext4_mknod,
......
};
static int ext4_mknod(struct inode *dir, struct dentry *dentry,
umode_t mode, dev_t rdev)
{
handle_t *handle;
struct inode *inode;
......
inode = ext4_new_inode_start_handle(dir, mode, &dentry->d_name, 0,
NULL, EXT4_HT_DIR, credits);
handle = ext4_journal_current_handle();
if (!IS_ERR(inode)) {
init_special_inode(inode, inode->i_mode, rdev);
inode->i_op = &ext4_special_inode_operations;
err = ext4_add_nondir(handle, dentry, inode);
if (!err && IS_DIRSYNC(dir))
ext4_handle_sync(handle);
}
if (handle)
ext4_journal_stop(handle);
......
}
#define ext4_new_inode_start_handle(dir, mode, qstr, goal, owner, \
type, nblocks) \
__ext4_new_inode(NULL, (dir), (mode), (qstr), (goal), (owner), \
0, (type), __LINE__, (nblocks))
void init_special_inode(struct inode *inode, umode_t mode, dev_t rdev)
{
inode->i_mode = mode;
if (S_ISCHR(mode)) {
inode->i_fop = &def_chr_fops;
inode->i_rdev = rdev;
} else if (S_ISBLK(mode)) {
inode->i_fop = &def_blk_fops;
inode->i_rdev = rdev;
} else if (S_ISFIFO(mode))
inode->i_fop = &pipefifo_fops;
else if (S_ISSOCK(mode))
; /* leave it no_open_fops */
else
......
}
在ext4_mknod中,ext4_new_inode_start_handle会调用__ext4_new_inode,在ext4文件系统上真的创建一个文件,但是会调用init_special_inode,创建一个内存中特殊的inode,这个函数在字符设备文件中也遇到过,只不过当时inode的i_fop指向的是def_chr_fops,这次换成管道文件了,inode的i_fop变成指向 pipefifo_fops,这一点和匿名管道是一样的。
这样管道文件就创建完毕了。接下来要打开这个管道文件,还是会调用文件系统的open函数,还是沿着文件系统的调用方式,一路调用到pipefifo_fops的open函数,也就是fifo_open,如下所示:
static int fifo_open(struct inode *inode, struct file *filp)
{
struct pipe_inode_info *pipe;
bool is_pipe = inode->i_sb->s_magic == PIPEFS_MAGIC;
int ret;
filp->f_version = 0;
if (inode->i_pipe) {
pipe = inode->i_pipe;
pipe->files++;
} else {
pipe = alloc_pipe_info();
pipe->files = 1;
inode->i_pipe = pipe;
spin_unlock(&inode->i_lock);
}
filp->private_data = pipe;
filp->f_mode &= (FMODE_READ | FMODE_WRITE);
switch (filp->f_mode) {
case FMODE_READ:
pipe->r_counter++;
if (pipe->readers++ == 0)
wake_up_partner(pipe);
if (!is_pipe && !pipe->writers) {
if ((filp->f_flags & O_NONBLOCK)) {
filp->f_version = pipe->w_counter;
} else {
if (wait_for_partner(pipe, &pipe->w_counter))
goto err_rd;
}
}
break;
case FMODE_WRITE:
pipe->w_counter++;
if (!pipe->writers++)
wake_up_partner(pipe);
if (!is_pipe && !pipe->readers) {
if (wait_for_partner(pipe, &pipe->r_counter))
goto err_wr;
}
break;
case FMODE_READ | FMODE_WRITE:
pipe->readers++;
pipe->writers++;
pipe->r_counter++;
pipe->w_counter++;
if (pipe->readers == 1 || pipe->writers == 1)
wake_up_partner(pipe);
break;
......
}
......
}
在fifo_open里面创建pipe_inode_info,这一点和匿名管道也是一样的。这个结构里面有个成员是struct pipe_buffer *bufs。可以知道所谓的命名管道,其实也是内核里面的一串缓存。接下来对于命名管道的写入,还是会调用pipefifo_fop 的pipe_write函数,向pipe_buffer里面写入数据。对于命名管道的读入,还是会调用pipefifo_fops的 pipe_read,也就是从 pipe_buffer 里面读取数据。
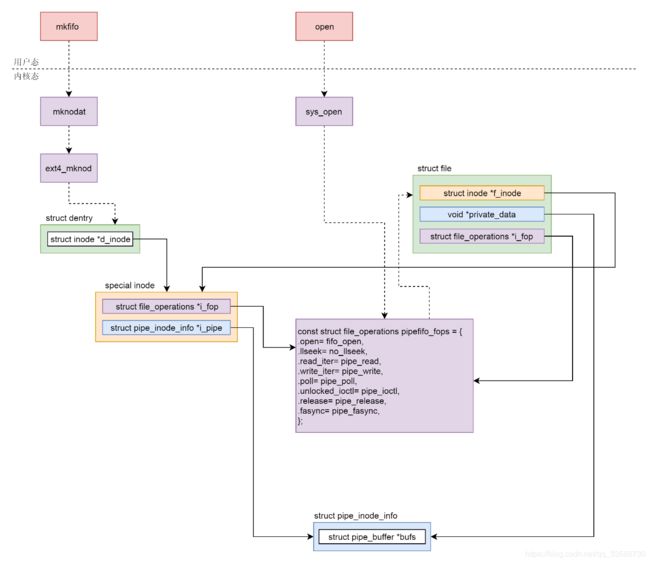
19. 无论是匿名管道还是命名管道,在内核都是一个文件,只要是文件就要有一个inode。这里又用到了特殊inode,字符设备、块设备其实都是这种特殊inode。在这种特殊的inode里面,file_operations指向管道特殊的pipefifo_fops,这个inode对应内存里面的缓存,当用文件的open函数打开这个管道设备文件的时候,会调用pipefifo_fops里面的方法创建struct file结构,它的inode指向特殊的inode,也对应内存里面的缓存,file_operations也指向管道特殊的pipefifo_fops。写入一个pipe就是从struct file结构找到缓存写入,读取一个pipe就是从struct file结构找到缓存读出,如下图所示:
四、IPC
20. 接下来详细讲讲进程之间共享内存的机制。有了这个机制,两个进程可以像访问自己内存中的变量一样,访问共享内存的变量。但是同时问题也来了,当两个进程共享内存了,就会存在同时读写的问题,就需要对于共享的内存进行保护,就需要信号量这样的同步协调机制。共享内存和信号量也是System V系列的进程间通信机制,所以很多地方和消息队列有点像。为了将共享内存和信号量结合起来使用,这里定义了一个share.h头文件,里面放了一些共享内存和信号量在每个进程都需要的函数,如下所示:
#include
#include
#include
#include
#include
#include
#include
#include
#define MAX_NUM 128
struct shm_data {
int data[MAX_NUM];
int datalength;
};
union semun {
int val;
struct semid_ds *buf;
unsigned short int *array;
struct seminfo *__buf;
};
int get_shmid(){
int shmid;
key_t key;
if((key = ftok("/root/sharememory/sharememorykey", 1024)) < 0){
perror("ftok error");
return -1;
}
shmid = shmget(key, sizeof(struct shm_data), IPC_CREAT|0777);
return shmid;
}
int get_semaphoreid(){
int semid;
key_t key;
if((key = ftok("/root/sharememory/semaphorekey", 1024)) < 0){
perror("ftok error");
return -1;
}
semid = semget(key, 1, IPC_CREAT|0777);
return semid;
}
int semaphore_init (int semid) {
union semun argument;
unsigned short values[1];
values[0] = 1;
argument.array = values;
return semctl (semid, 0, SETALL, argument);
}
int semaphore_p (int semid) {
struct sembuf operations[1];
operations[0].sem_num = 0;
operations[0].sem_op = -1;
operations[0].sem_flg = SEM_UNDO;
return semop (semid, operations, 1);
}
int semaphore_v (int semid) {
struct sembuf operations[1];
operations[0].sem_num = 0;
operations[0].sem_op = 1;
operations[0].sem_flg = SEM_UNDO;
return semop (semid, operations, 1);
}
先来看里面对于共享内存的操作。首先创建之前要有一个key来唯一标识这个共享内存。这个key可以根据文件系统上一个文件的inode随机生成。然后需要创建一个共享内存,就像创建一个消息队列差不多,都是使用xxxget来创建。其中创建共享内存使用的是下面这个函数:
int shmget(key_t key, size_t size, int shmflag);其中,key就是前面生成的那个key,shmflag如果为IPC_CREAT就表示新创建,还可以指定读写权限0777。对于共享内存需要指定一个大小size,这个一般要申请多大呢?一个最佳实践是,将多个进程需要共享的数据放在一个struct里,然后这里的size就应该是这个struct的大小。这样每一个进程得到这块内存后,只要强制将类型转换为这个struct类型,就能够访问里面的共享数据了。
在这里定义了一个struct shm_data结构。这里面有两个成员,一个是整型的数组,一个是数组中元素的个数。生成了共享内存以后,接下来就是将这个共享内存映射到进程的虚拟地址空间中,使用下面这个函数来进行操作:
void *shmat(int shm_id, const void *addr, int shmflg);这里面的shm_id,就是上面创建的共享内存的id,addr就是指定映射在某个地方。如果不指定,则内核会自动选择一个地址作为返回值返回。得到了返回地址以后,需要将指针强制类型转换为struct shm_data结构,就可以使用这个指针设置data和datalength了。当共享内存使用完毕,可以通过shmdt解除它到虚拟内存的映射,如下所示:
int shmdt(const void *shmaddr);21. 接下来看信号量。信号量以集合的形式存在的,首先创建之前同样需要有一个key,来唯一标识这个信号量集合。这个key同样可以根据文件系统上一个文件的inode随机生成。然后需要创建一个信号量集合,同样也是使用xxxget来创建,其中创建信号量集合使用的是下面这个函数:
int semget(key_t key, int nsems, int semflg);这里面的key就是前面生成的那个key,shmflag如果为IPC_CREAT就表示新创建,也可以指定读写权限0777即所有人可操作。这里nsems表示这个信号量集合里面有几个信号量,最简单的情况下设置为1。信号量往往代表某种资源的数量,如果用信号量做互斥,那往往将信号量设置为1,这就是上面代码中semaphore_init函数的作用,这里面调用semctl函数,将这个信号量集合中的第0个信号量,即唯一的这个信号量设置为1。
对于信号量,往往要定义两种操作,P操作和V操作,对应上面代码中semaphore_p函数和semaphore_v函数semaphore_p会调用semop函数将信号量的值减一,表示申请占用一个资源,发现当前没有资源的时候进入等待。semaphore_v会调用semop函数将信号量的值加一,表示释放一个资源,释放之后就允许等待中的其他进程占用这个资源。
可以用这个信号量来保护共享内存中的struct shm_data,使得同时只有一个进程可以操作这个结构。这里构建一个场景分为producer.c和consumer.c,其中producer即生产者,负责往struct shm_data塞入数据,而consumer.c负责处理struct shm_data中的数据。下面来看producer.c的代码:
#include "share.h"
int main() {
void *shm = NULL;
struct shm_data *shared = NULL;
int shmid = get_shmid();
int semid = get_semaphoreid();
int i;
shm = shmat(shmid, (void*)0, 0);
if(shm == (void*)-1){
exit(0);
}
shared = (struct shm_data*)shm;
memset(shared, 0, sizeof(struct shm_data));
semaphore_init(semid);
while(1){
semaphore_p(semid);
if(shared->datalength > 0){
semaphore_v(semid);
sleep(1);
} else {
printf("how many integers to caculate : ");
scanf("%d",&shared->datalength);
if(shared->datalength > MAX_NUM){
perror("too many integers.");
shared->datalength = 0;
semaphore_v(semid);
exit(1);
}
for(i=0;idatalength;i++){
printf("Input the %d integer : ", i);
scanf("%d",&shared->data[i]);
}
semaphore_v(semid);
}
}
}
在这里面,get_shmid创建了共享内存,get_semaphoreid创建了信号量集合,然后shmat将共享内存映射到了虚拟地址空间的shm指针指向的位置,然后通过强制类型转换,shared的指针指向放在共享内存里面的struct shm_data结构,然后初始化为0。semaphore_init将信号量进行了初始化。
接着producer进入了一个无限循环。在这个循环里面先通过semaphore_p申请访问共享内存的权利,如果发现datalength大于零,说明共享内存里面的数据没有被处理过,于是semaphore_v释放访问权利先睡一会儿,睡醒了再看。如果发现datalength等于0,说明共享内存里面的数据被处理完了,于是开始往里面放数据。让用户输入多少个数,然后每个数是什么,都放在struct shm_data结构中,然后semaphore_v释放访问权利,等待其他的进程将这些数据拿去处理。再来看consumer的代码,如下所示:
#include "share.h"
int main() {
void *shm = NULL;
struct shm_data *shared = NULL;
int shmid = get_shmid();
int semid = get_semaphoreid();
int i;
shm = shmat(shmid, (void*)0, 0);
if(shm == (void*)-1){
exit(0);
}
shared = (struct shm_data*)shm;
while(1){
semaphore_p(semid);
if(shared->datalength > 0){
int sum = 0;
for(i=0;idatalength-1;i++){
printf("%d+",shared->data[i]);
sum += shared->data[i];
}
printf("%d",shared->data[shared->datalength-1]);
sum += shared->data[shared->datalength-1];
printf("=%d\n",sum);
memset(shared, 0, sizeof(struct shm_data));
semaphore_v(semid);
} else {
semaphore_v(semid);
printf("no tasks, waiting.\n");
sleep(1);
}
}
}
在这里面,get_shmid获得producer创建的共享内存,get_semaphoreid获得producer创建的信号量集合,然后shmat将共享内存映射到了虚拟地址空间的shm指针指向的位置,然后通过强制类型转换,shared的指针指向放在共享内存里面的struct shm_data结构。
接着consumer进入了一个无限循环,在这个循环里面先通过semaphore_p申请访问共享内存的权利,如果发现datalength等于0,就说明没什么活干需要等待。如果发现datalength大于0就说明有活干,于是将datalength个整型数字从data数组中取出来求和。最后将struct shm_data清空为0表示任务处理完毕,通过semaphore_v释放访问共享内存的权利。
通过程序创建的共享内存和信号量集合,可以通过命令ipcs查看。当然也可以通过ipcrm进行删除,如下所示:
# ipcs
------ Message Queues --------
key msqid owner perms used-bytes messages
------ Shared Memory Segments --------
key shmid owner perms bytes nattch status
0x00016988 32768 root 777 516 0
------ Semaphore Arrays --------
key semid owner perms nsems
0x00016989 32768 root 777 1
下面来运行一下producer和consumer,可以得到下面的结果:
# ./producer
how many integers to caculate : 2
Input the 0 integer : 3
Input the 1 integer : 4
how many integers to caculate : 4
Input the 0 integer : 3
Input the 1 integer : 4
Input the 2 integer : 5
Input the 3 integer : 6
how many integers to caculate : 7
Input the 0 integer : 9
Input the 1 integer : 8
Input the 2 integer : 7
Input the 3 integer : 6
Input the 4 integer : 5
Input the 5 integer : 4
Input the 6 integer : 3
# ./consumer
3+4=7
3+4+5+6=18
9+8+7+6+5+4+3=42
22. 来总结一下共享内存和信号量的配合机制,如下图所示:
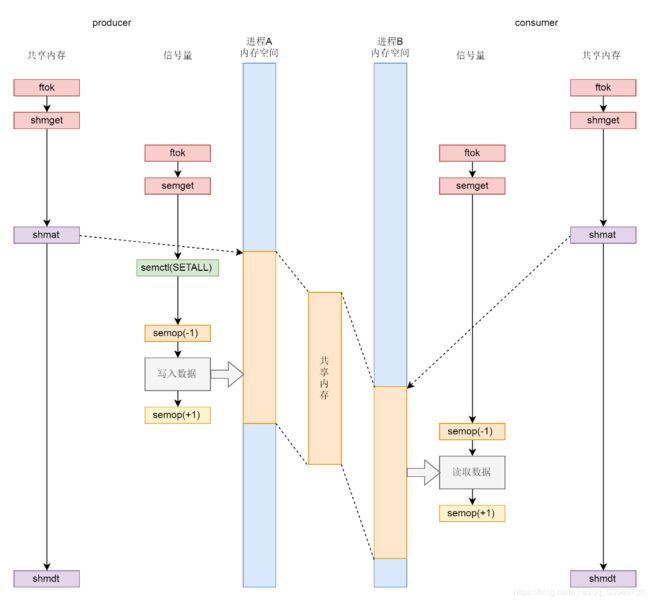
(1)无论是共享内存还是信号量,创建与初始化都遵循同样流程,即通过ftok得到key,通过xxxget创建对象并生成id;
(2)生产者和消费者都通过shmat将共享内存映射到各自的内存空间,在不同的进程里面映射的位置不同;
(3)为了访问共享内存,需要信号量进行保护,信号量需要通过semctl初始化为某个值;
(4)接下来生产者和消费者要通过semop(-1)来竞争信号量,如果生产者抢到信号量则写入,然后通过semop(+1)释放信号量,如果消费者抢到信号量则读出,然后通过semop(+1)释放信号量;
(5)共享内存使用完毕,可以通过 shmdt 来解除映射。
23. 了解了如何使用共享内存和信号量集合之后,来解析一下内核里面都做了什么。签名讲消息队列、共享内存、信号量机制的时候,其实能够从中看到一些统一的规律:它们在使用之前都要生成key,然后通过key得到唯一的id,并且都是通过xxxget函数。在内核里面,这三种进程间通信机制是使用统一的机制管理起来的,都叫ipcxxx。为了维护这三种进程间通信进制,在内核里面声明了一个有三项的数组。通过下面这段代码,来具体看一看:
struct ipc_namespace {
......
struct ipc_ids ids[3];
......
}
#define IPC_SEM_IDS 0
#define IPC_MSG_IDS 1
#define IPC_SHM_IDS 2
#define sem_ids(ns) ((ns)->ids[IPC_SEM_IDS])
#define msg_ids(ns) ((ns)->ids[IPC_MSG_IDS])
#define shm_ids(ns) ((ns)->ids[IPC_SHM_IDS])
根据代码中的定义,第0项用于信号量,第1项用于消息队列,第2项用于共享内存,分别可以通过sem_ids、msg_ids、shm_ids来访问。这段代码里面有ns全称叫namespace,可能不容易理解,现在可以将它认为是将一台Linux服务器逻辑的隔离为多台Linux服务器的机制,它背后的原理需要在容器部分详细讲述,现在可以简单的装作没有namespace,整个Linux在一个namespace下面,暂时认为这些ids也是整个Linux只有一份。接下来看struct ipc_ids里面保存了什么,如下所示:
struct ipc_ids {
int in_use;
unsigned short seq;
struct rw_semaphore rwsem;
struct idr ipcs_idr;
int next_id;
};
struct idr {
struct radix_tree_root idr_rt;
unsigned int idr_next;
};
首先in_use表示当前有多少个ipc;其次seq和next_id用于一起生成ipc唯一的id,因为信号量、共享内存、消息队列它们三个的id也不能重复;ipcs_idr是一棵基数树,这里又碰到它了,一旦涉及从一个整数查找一个对象,它都是最好的选择。也就是说,对于sem_ids、msg_ids、shm_ids各有一棵基数树。那这棵树里面究竟存放了什么,能够统一管理这三类ipc对象呢?通过下面这个函数ipc_obtain_object_idr可以看出端倪。这个函数根据id,在基数树里面找出来的是struct kern_ipc_perm:
struct kern_ipc_perm *ipc_obtain_object_idr(struct ipc_ids *ids, int id)
{
struct kern_ipc_perm *out;
int lid = ipcid_to_idx(id);
out = idr_find(&ids->ipcs_idr, lid);
return out;
}
如果看用于表示信号量、消息队列、共享内存的结构,就会发现这三个结构的第一项都是struct kern_ipc_perm,如下所示:
struct sem_array {
struct kern_ipc_perm sem_perm; /* permissions .. see ipc.h */
time_t sem_ctime; /* create/last semctl() time */
struct list_head pending_alter; /* pending operations */
/* that alter the array */
struct list_head pending_const; /* pending complex operations */
/* that do not alter semvals */
struct list_head list_id; /* undo requests on this array */
int sem_nsems; /* no. of semaphores in array */
int complex_count; /* pending complex operations */
unsigned int use_global_lock;/* >0: global lock required */
struct sem sems[];
} __randomize_layout;
struct msg_queue {
struct kern_ipc_perm q_perm;
time_t q_stime; /* last msgsnd time */
time_t q_rtime; /* last msgrcv time */
time_t q_ctime; /* last change time */
unsigned long q_cbytes; /* current number of bytes on queue */
unsigned long q_qnum; /* number of messages in queue */
unsigned long q_qbytes; /* max number of bytes on queue */
pid_t q_lspid; /* pid of last msgsnd */
pid_t q_lrpid; /* last receive pid */
struct list_head q_messages;
struct list_head q_receivers;
struct list_head q_senders;
} __randomize_layout;
struct shmid_kernel /* private to the kernel */
{
struct kern_ipc_perm shm_perm;
struct file *shm_file;
unsigned long shm_nattch;
unsigned long shm_segsz;
time_t shm_atim;
time_t shm_dtim;
time_t shm_ctim;
pid_t shm_cprid;
pid_t shm_lprid;
struct user_struct *mlock_user;
/* The task created the shm object. NULL if the task is dead. */
struct task_struct *shm_creator;
struct list_head shm_clist; /* list by creator */
} __randomize_layout;
也就是说完全可以通过struct kern_ipc_perm的指针,通过进行强制类型转换后得到整个结构。做这件事情的函数如下面三个所示:
static inline struct sem_array *sem_obtain_object(struct ipc_namespace *ns, int id)
{
struct kern_ipc_perm *ipcp = ipc_obtain_object_idr(&sem_ids(ns), id);
return container_of(ipcp, struct sem_array, sem_perm);
}
static inline struct msg_queue *msq_obtain_object(struct ipc_namespace *ns, int id)
{
struct kern_ipc_perm *ipcp = ipc_obtain_object_idr(&msg_ids(ns), id);
return container_of(ipcp, struct msg_queue, q_perm);
}
static inline struct shmid_kernel *shm_obtain_object(struct ipc_namespace *ns, int id)
{
struct kern_ipc_perm *ipcp = ipc_obtain_object_idr(&shm_ids(ns), id);
return container_of(ipcp, struct shmid_kernel, shm_perm);
}
通过这种机制,就可以将信号量、消息队列、共享内存抽象为ipc类型进行统一处理。这有点面向对象编程中抽象类和实现类的意思,C++中类的实现机制其实也是这么干的,如下图所示:

24. 有了抽象类,接下来看共享内存和信号量的具体实现。首先来看创建共享内存的的系统调用,如下所示:
SYSCALL_DEFINE3(shmget, key_t, key, size_t, size, int, shmflg)
{
struct ipc_namespace *ns;
static const struct ipc_ops shm_ops = {
.getnew = newseg,
.associate = shm_security,
.more_checks = shm_more_checks,
};
struct ipc_params shm_params;
ns = current->nsproxy->ipc_ns;
shm_params.key = key;
shm_params.flg = shmflg;
shm_params.u.size = size;
return ipcget(ns, &shm_ids(ns), &shm_ops, &shm_params);
}
这里面调用了抽象的ipcget、参数分别为共享内存对应的shm_ids、对应的操作shm_ops以及对应的参数shm_params。如果key设置为IPC_PRIVATE则永远创建新的,如果不是的话就会调用ipcget_public。ipcget的具体代码如下:
int ipcget(struct ipc_namespace *ns, struct ipc_ids *ids,
const struct ipc_ops *ops, struct ipc_params *params)
{
if (params->key == IPC_PRIVATE)
return ipcget_new(ns, ids, ops, params);
else
return ipcget_public(ns, ids, ops, params);
}
static int ipcget_public(struct ipc_namespace *ns, struct ipc_ids *ids, const struct ipc_ops *ops, struct ipc_params *params)
{
struct kern_ipc_perm *ipcp;
int flg = params->flg;
int err;
ipcp = ipc_findkey(ids, params->key);
if (ipcp == NULL) {
if (!(flg & IPC_CREAT))
err = -ENOENT;
else
err = ops->getnew(ns, params);
} else {
if (flg & IPC_CREAT && flg & IPC_EXCL)
err = -EEXIST;
else {
err = 0;
if (ops->more_checks)
err = ops->more_checks(ipcp, params);
......
}
}
return err;
}
在ipcget_public中会按照key,去查找struct kern_ipc_perm。如果没有找到那就看是否设置了IPC_CREAT;如果设置了就创建一个新的。如果找到了就将对应的id返回。这里重点看如何按照参数shm_ops,创建新的共享内存,会调用newseg,如下所示:
static int newseg(struct ipc_namespace *ns, struct ipc_params *params)
{
key_t key = params->key;
int shmflg = params->flg;
size_t size = params->u.size;
int error;
struct shmid_kernel *shp;
size_t numpages = (size + PAGE_SIZE - 1) >> PAGE_SHIFT;
struct file *file;
char name[13];
vm_flags_t acctflag = 0;
......
shp = kvmalloc(sizeof(*shp), GFP_KERNEL);
......
shp->shm_perm.key = key;
shp->shm_perm.mode = (shmflg & S_IRWXUGO);
shp->mlock_user = NULL;
shp->shm_perm.security = NULL;
......
file = shmem_kernel_file_setup(name, size, acctflag);
......
shp->shm_cprid = task_tgid_vnr(current);
shp->shm_lprid = 0;
shp->shm_atim = shp->shm_dtim = 0;
shp->shm_ctim = get_seconds();
shp->shm_segsz = size;
shp->shm_nattch = 0;
shp->shm_file = file;
shp->shm_creator = current;
error = ipc_addid(&shm_ids(ns), &shp->shm_perm, ns->shm_ctlmni);
......
list_add(&shp->shm_clist, ¤t->sysvshm.shm_clist);
......
file_inode(file)->i_ino = shp->shm_perm.id;
ns->shm_tot += numpages;
error = shp->shm_perm.id;
......
return error;
}
newseg函数的第一步,是通过kvmalloc在直接映射区分配一个struct shmid_kernel结构。这个结构就是用来描述共享内存的。这个结构最开始就是上面说的struct kern_ipc_perm结构。接下来就是填充这个struct shmid_kernel结构,例如key、权限等。
newseg函数的第二步,共享内存需要和文件进行关联。为什么要做这个呢?在之前内存映射的部分提过,虚拟地址空间可以和物理内存关联,但是物理内存是某个进程独享的。虚拟地址空间也可以映射到一个文件,文件是可以跨进程共享的。这里的共享内存需要跨进程共享,也应该借鉴文件映射的思路,只不过不应该映射一个硬盘上的文件,而是映射到一个内存文件系统上的文件。mm/shmem.c里面就定义了这样一个基于内存的文件系统。这里一定要注意区分shmem和shm的区别,前者是一个文件系统,后者是进程通信机制。
在系统初始化的时候,shmem_init注册了shmem文件系统shmem_fs_type,并且挂载到shm_mnt下面,如下所示:
int __init shmem_init(void)
{
int error;
error = shmem_init_inodecache();
error = register_filesystem(&shmem_fs_type);
shm_mnt = kern_mount(&shmem_fs_type);
......
return 0;
}
static struct file_system_type shmem_fs_type = {
.owner = THIS_MODULE,
.name = "tmpfs",
.mount = shmem_mount,
.kill_sb = kill_litter_super,
.fs_flags = FS_USERNS_MOUNT,
};
接下来,newseg函数会调用shmem_kernel_file_setup,其实就是在shmem文件系统里面创建一个文件,如下所示:
/**
* shmem_kernel_file_setup - get an unlinked file living in tmpfs which must be kernel internal.
* @name: name for dentry (to be seen in /proc//maps
* @size: size to be set for the file
* @flags: VM_NORESERVE suppresses pre-accounting of the entire object size */
struct file *shmem_kernel_file_setup(const char *name, loff_t size, unsigned long flags)
{
return __shmem_file_setup(name, size, flags, S_PRIVATE);
}
static struct file *__shmem_file_setup(const char *name, loff_t size,
unsigned long flags, unsigned int i_flags)
{
struct file *res;
struct inode *inode;
struct path path;
struct super_block *sb;
struct qstr this;
......
this.name = name;
this.len = strlen(name);
this.hash = 0; /* will go */
sb = shm_mnt->mnt_sb;
path.mnt = mntget(shm_mnt);
path.dentry = d_alloc_pseudo(sb, &this);
d_set_d_op(path.dentry, &anon_ops);
......
inode = shmem_get_inode(sb, NULL, S_IFREG | S_IRWXUGO, 0, flags);
inode->i_flags |= i_flags;
d_instantiate(path.dentry, inode);
inode->i_size = size;
......
res = alloc_file(&path, FMODE_WRITE | FMODE_READ,
&shmem_file_operations);
return res;
}
__shmem_file_setup会创建新的shmem文件对应的dentry和inode,并将它们两个关联起来,然后分配一个struct file结构来表示新的shmem文件,并且指向独特的shmem_file_operations,它的实现如下所示:
static const struct file_operations shmem_file_operations = {
.mmap = shmem_mmap,
.get_unmapped_area = shmem_get_unmapped_area,
#ifdef CONFIG_TMPFS
.llseek = shmem_file_llseek,
.read_iter = shmem_file_read_iter,
.write_iter = generic_file_write_iter,
.fsync = noop_fsync,
.splice_read = generic_file_splice_read,
.splice_write = iter_file_splice_write,
.fallocate = shmem_fallocate,
#endif
};
newseg函数的第三步,通过ipc_addid将新创建的struct shmid_kernel结构挂到shm_ids里面的基数树上,并返回相应的id,并且将struct shmid_kernel挂到当前进程的sysvshm队列中。至此,共享内存的创建就完成了。
25. 从上面代码解析中可以知道,共享内存的数据结构struct shmid_kernel,是通过它的成员struct file *shm_file来管理内存文件系统shmem上的内存文件的。无论这个共享内存是否被映射shm_file都是存在的。接下来要将共享内存映射到虚拟地址空间中调用的是shmat,对应的系统调用如下:
SYSCALL_DEFINE3(shmat, int, shmid, char __user *, shmaddr, int, shmflg)
{
unsigned long ret;
long err;
err = do_shmat(shmid, shmaddr, shmflg, &ret, SHMLBA);
force_successful_syscall_return();
return (long)ret;
}
long do_shmat(int shmid, char __user *shmaddr, int shmflg,
ulong *raddr, unsigned long shmlba)
{
struct shmid_kernel *shp;
unsigned long addr = (unsigned long)shmaddr;
unsigned long size;
struct file *file;
int err;
unsigned long flags = MAP_SHARED;
unsigned long prot;
int acc_mode;
struct ipc_namespace *ns;
struct shm_file_data *sfd;
struct path path;
fmode_t f_mode;
unsigned long populate = 0;
......
prot = PROT_READ | PROT_WRITE;
acc_mode = S_IRUGO | S_IWUGO;
f_mode = FMODE_READ | FMODE_WRITE;
......
ns = current->nsproxy->ipc_ns;
shp = shm_obtain_object_check(ns, shmid);
......
path = shp->shm_file->f_path;
path_get(&path);
shp->shm_nattch++;
size = i_size_read(d_inode(path.dentry));
......
sfd = kzalloc(sizeof(*sfd), GFP_KERNEL);
......
file = alloc_file(&path, f_mode,
is_file_hugepages(shp->shm_file) ?
&shm_file_operations_huge :
&shm_file_operations);
......
file->private_data = sfd;
file->f_mapping = shp->shm_file->f_mapping;
sfd->id = shp->shm_perm.id;
sfd->ns = get_ipc_ns(ns);
sfd->file = shp->shm_file;
sfd->vm_ops = NULL;
......
addr = do_mmap_pgoff(file, addr, size, prot, flags, 0, &populate, NULL);
*raddr = addr;
err = 0;
......
return err;
}
在这个函数里面shm_obtain_object_check会通过共享内存的id,在基数树中找到对应的struct shmid_kernel结构,通过它找到shmem上的内存文件。接下来要分配一个struct shm_file_data来表示这个内存文件,将shmem中指向内存文件的shm_file赋值给struct shm_file_data中的file成员。然后创建了一个struct file,指向的也是shmem中的内存文件。
为什么要再创建一个呢?这两个的功能不同,shmem中shm_file用于管理内存文件,是一个中立的、独立于任何一个进程的角色。而新创建的struct file是专门用于做内存映射的,就像一个硬盘上的文件要映射到虚拟地址空间中时,需要在vm_area_struct里面有一个struct file *vm_file指向硬盘上的文件,现在变成内存文件了,但是这个结构还是不能少。
新创建的struct file的private_data指向struct shm_file_data,这样内存映射那部分的数据结构,就能够通过它来访问内存文件了。新创建的struct file的file_operations也发生了变化,变成了shm_file_operations,如下所示:
static const struct file_operations shm_file_operations = {
.mmap = shm_mmap,
.fsync = shm_fsync,
.release = shm_release,
.get_unmapped_area = shm_get_unmapped_area,
.llseek = noop_llseek,
.fallocate = shm_fallocate,
};
接下来do_mmap_pgoff函数之前遇到过,原来映射硬盘上的文件时也是调用它。它会分配一个vm_area_struct指向虚拟地址空间中没有分配的区域,它的vm_file指向这个内存文件,然后它会调用shm_file_operations的mmap函数即shm_mmap进行映射,如下所示:
static int shm_mmap(struct file *file, struct vm_area_struct *vma)
{
struct shm_file_data *sfd = shm_file_data(file);
int ret;
ret = __shm_open(vma);
ret = call_mmap(sfd->file, vma);
sfd->vm_ops = vma->vm_ops;
vma->vm_ops = &shm_vm_ops;
return 0;
}
shm_mmap中调用了shm_file_data中file的mmap函数,这次调用的是shmem_file_operations的mmap,即shmem_mmap,如下所示:
static int shmem_mmap(struct file *file, struct vm_area_struct *vma)
{
file_accessed(file);
vma->vm_ops = &shmem_vm_ops;
return 0;
}
这里面vm_area_struct的vm_ops指向shmem_vm_ops。等从call_mmap中返回之后,shm_file_data的vm_ops指向了shmem_vm_ops,而vm_area_struct的vm_ops改为指向shm_vm_ops,要注意区分这两个不同的vm_ops。
26. 接下来看一下shm_vm_ops和shmem_vm_ops的定义,如下所示:
static const struct vm_operations_struct shm_vm_ops = {
.open = shm_open, /* callback for a new vm-area open */
.close = shm_close, /* callback for when the vm-area is released */
.fault = shm_fault,
};
static const struct vm_operations_struct shmem_vm_ops = {
.fault = shmem_fault,
.map_pages = filemap_map_pages,
};
它们里面最关键的就是fault函数,即访问虚拟内存的时候,访问不到就会发生缺页异常,先调用vm_area_struct的vm_ops,即shm_vm_ops的fault函数shm_fault。然后它会调用shm_file_data的vm_ops,即shmem_vm_ops的fault函数shmem_fault,如下所示:
static int shm_fault(struct vm_fault *vmf)
{
struct file *file = vmf->vma->vm_file;
struct shm_file_data *sfd = shm_file_data(file);
return sfd->vm_ops->fault(vmf);
}
虽然基于内存的文件系统已经为这个内存文件分配了inode,但是内存也却是一点都没分配,只有在发生缺页异常的时候才进行分配。shmem_fault的实现如下所示:
static int shmem_fault(struct vm_fault *vmf)
{
struct vm_area_struct *vma = vmf->vma;
struct inode *inode = file_inode(vma->vm_file);
gfp_t gfp = mapping_gfp_mask(inode->i_mapping);
......
error = shmem_getpage_gfp(inode, vmf->pgoff, &vmf->page, sgp,
gfp, vma, vmf, &ret);
......
}
/*
* shmem_getpage_gfp - find page in cache, or get from swap, or allocate
*
* If we allocate a new one we do not mark it dirty. That's up to the
* vm. If we swap it in we mark it dirty since we also free the swap
* entry since a page cannot live in both the swap and page cache.
*
* fault_mm and fault_type are only supplied by shmem_fault:
* otherwise they are NULL.
*/
static int shmem_getpage_gfp(struct inode *inode, pgoff_t index,
struct page **pagep, enum sgp_type sgp, gfp_t gfp,
struct vm_area_struct *vma, struct vm_fault *vmf, int *fault_type)
{
......
page = shmem_alloc_and_acct_page(gfp, info, sbinfo,
index, false);
......
}
shmem_fault会调用shmem_getpage_gfp在page cache和swap中找一个空闲页,如果找不到就通过shmem_alloc_and_acct_page分配一个新的页,它最终会调用内存管理系统的alloc_page_vma在物理内存中分配一个页。至此共享内存才真的映射到了虚拟地址空间中,进程可以像访问本地内存一样访问共享内存。
27. 来总结一下共享内存的创建和映射过程,如下图所示:

(1)调用shmget创建共享内存。
(2)先通过ipc_findkey在基数树中查找key对应的共享内存对象shmid_kernel是否已经被创建过,如果已经被创建就会被查询出来,例如producer创建过在consumer中就会查询出来。
(3)如果共享内存没有被创建过,则调用shm_ops的newseg方法,创建一个共享内存对象shmid_kernel。例如在producer中就会新建。
(4)在shmem文件系统里面创建一个文件,共享内存对象shmid_kernel指向这个文件,这个文件用struct file表示,姑且称它为file1。
(5)调用shmat,将共享内存映射到虚拟地址空间。
(6)shm_obtain_object_check先从基数树里面找到shmid_kernel对象。
(7)创建用于内存映射到文件的file和shm_file_data,这里的struct file姑且称为file2。
(8)关联内存区域vm_area_struct和用于内存映射到文件的file即file2,调用file2的mmap函数。
(9)file2的mmap函数shm_mmap,会调用file1的mmap函数shmem_mmap,设置shm_file_data和vm_area_struct的vm_ops。
(10)内存映射完毕之后,其实并没有真的分配物理内存,当访问内存的时候会触发缺页异常do_page_fault。
(11)vm_area_struct的vm_ops的shm_fault会调用shm_file_data的vm_ops的shmem_fault,在page cache中找一个空闲页或者创建一个空闲页。
28. 前面解析完了共享内存的内核机制后,来看信号量的内核机制。首先需要创建一个信号量,调用的是系统调用semget,代码如下:
SYSCALL_DEFINE3(semget, key_t, key, int, nsems, int, semflg)
{
struct ipc_namespace *ns;
static const struct ipc_ops sem_ops = {
.getnew = newary,
.associate = sem_security,
.more_checks = sem_more_checks,
};
struct ipc_params sem_params;
ns = current->nsproxy->ipc_ns;
sem_params.key = key;
sem_params.flg = semflg;
sem_params.u.nsems = nsems;
return ipcget(ns, &sem_ids(ns), &sem_ops, &sem_params);
}
之前解析过了共享内存,再看信号量就顺畅很多了。这里同样调用了抽象的ipcget,参数分别为信号量对应的sem_ids、对应的操作sem_ops以及对应的参数sem_params。ipcget的代码之前已经解析过了,如果key设置为IPC_PRIVATE则永远创建新的;如果不是的话就会调用ipcget_public。在ipcget_public中,会按照key去查找struct kern_ipc_perm,如果没有找到,那就看看是否设置了IPC_CREAT;如果设置了就创建一个新的,如果找到了就将对应的id返回。这里重点看,如何按照参数sem_ops创建新的信号量并调用newary,如下所示:
static int newary(struct ipc_namespace *ns, struct ipc_params *params)
{
int retval;
struct sem_array *sma;
key_t key = params->key;
int nsems = params->u.nsems;
int semflg = params->flg;
int i;
......
sma = sem_alloc(nsems);
......
sma->sem_perm.mode = (semflg & S_IRWXUGO);
sma->sem_perm.key = key;
sma->sem_perm.security = NULL;
......
for (i = 0; i < nsems; i++) {
INIT_LIST_HEAD(&sma->sems[i].pending_alter);
INIT_LIST_HEAD(&sma->sems[i].pending_const);
spin_lock_init(&sma->sems[i].lock);
}
sma->complex_count = 0;
sma->use_global_lock = USE_GLOBAL_LOCK_HYSTERESIS;
INIT_LIST_HEAD(&sma->pending_alter);
INIT_LIST_HEAD(&sma->pending_const);
INIT_LIST_HEAD(&sma->list_id);
sma->sem_nsems = nsems;
sma->sem_ctime = get_seconds();
retval = ipc_addid(&sem_ids(ns), &sma->sem_perm, ns->sc_semmni);
......
ns->used_sems += nsems;
......
return sma->sem_perm.id;
}
newary函数的第一步,通过kvmalloc在直接映射区分配一个struct sem_array结构。这个结构是用来描述信号量的,这个结构最开始就是上面说的struct kern_ipc_perm结构。接下来就是填充这个struct sem_array结构,例如key、权限等。struct sem_array里有多个信号量,放在struct sem sems[]数组里面,在struct sem里面有当前的信号量的数值semval,如下所示:
struct sem {
int semval; /* current value */
/*
* PID of the process that last modified the semaphore. For
* Linux, specifically these are:
* - semop
* - semctl, via SETVAL and SETALL.
* - at task exit when performing undo adjustments (see exit_sem).
*/
int sempid;
spinlock_t lock; /* spinlock for fine-grained semtimedop */
struct list_head pending_alter; /* pending single-sop operations that alter the semaphore */
struct list_head pending_const; /* pending single-sop operations that do not alter the semaphore*/
time_t sem_otime; /* candidate for sem_otime */
} ____cacheline_aligned_in_smp;
struct sem_array和 struct sem各有一个链表struct list_head pending_alter,分别表示对于整个信号量数组的修改和对于某个信号量的修改。newary函数的第二步就是初始化这些链表。newary函数的第三步,通过ipc_addid将新创建的struct sem_array结构,挂到sem_ids里面的基数树上,并返回相应的id。
29. 信号量创建的过程到此结束,接下来看如何通过semctl对信号量数组进行初始化,如下所示:
SYSCALL_DEFINE4(semctl, int, semid, int, semnum, int, cmd, unsigned long, arg)
{
int version;
struct ipc_namespace *ns;
void __user *p = (void __user *)arg;
ns = current->nsproxy->ipc_ns;
switch (cmd) {
case IPC_INFO:
case SEM_INFO:
case IPC_STAT:
case SEM_STAT:
return semctl_nolock(ns, semid, cmd, version, p);
case GETALL:
case GETVAL:
case GETPID:
case GETNCNT:
case GETZCNT:
case SETALL:
return semctl_main(ns, semid, semnum, cmd, p);
case SETVAL:
return semctl_setval(ns, semid, semnum, arg);
case IPC_RMID:
case IPC_SET:
return semctl_down(ns, semid, cmd, version, p);
default:
return -EINVAL;
}
}
这里重点看SETALL操作调用的semctl_main函数,以及SETVAL操作调用的semctl_setval函数。对于SETALL操作来讲,传进来的参数为union semun里面的unsigned short *array,会设置整个信号量集合,如下所示:
static int semctl_main(struct ipc_namespace *ns, int semid, int semnum,
int cmd, void __user *p)
{
struct sem_array *sma;
struct sem *curr;
int err, nsems;
ushort fast_sem_io[SEMMSL_FAST];
ushort *sem_io = fast_sem_io;
DEFINE_WAKE_Q(wake_q);
sma = sem_obtain_object_check(ns, semid);
nsems = sma->sem_nsems;
......
switch (cmd) {
......
case SETALL:
{
int i;
struct sem_undo *un;
......
if (copy_from_user(sem_io, p, nsems*sizeof(ushort))) {
......
}
......
for (i = 0; i < nsems; i++) {
sma->sems[i].semval = sem_io[i];
sma->sems[i].sempid = task_tgid_vnr(current);
}
......
sma->sem_ctime = get_seconds();
/* maybe some queued-up processes were waiting for this */
do_smart_update(sma, NULL, 0, 0, &wake_q);
err = 0;
goto out_unlock;
}
}
......
wake_up_q(&wake_q);
......
}
在semctl_setval函数中,先是通过sem_obtain_object_check根据信号量集合的id,在基数树里面找到struct sem_array对象,对于SETVAL操作,直接根据参数中的val设置semval,以及修改这个信号量值的pid。
30. 至此,信号量数组初始化完毕。接下来看P操作和V操作,无论是P操作还是V操作都是调用semop系统调用,如下所示:
SYSCALL_DEFINE3(semop, int, semid, struct sembuf __user *, tsops,
unsigned, nsops)
{
return sys_semtimedop(semid, tsops, nsops, NULL);
}
SYSCALL_DEFINE4(semtimedop, int, semid, struct sembuf __user *, tsops,
unsigned, nsops, const struct timespec __user *, timeout)
{
int error = -EINVAL;
struct sem_array *sma;
struct sembuf fast_sops[SEMOPM_FAST];
struct sembuf *sops = fast_sops, *sop;
struct sem_undo *un;
int max, locknum;
bool undos = false, alter = false, dupsop = false;
struct sem_queue queue;
unsigned long dup = 0, jiffies_left = 0;
struct ipc_namespace *ns;
ns = current->nsproxy->ipc_ns;
......
if (copy_from_user(sops, tsops, nsops * sizeof(*tsops))) {
error = -EFAULT;
goto out_free;
}
if (timeout) {
struct timespec _timeout;
if (copy_from_user(&_timeout, timeout, sizeof(*timeout))) {
}
jiffies_left = timespec_to_jiffies(&_timeout);
}
......
/* On success, find_alloc_undo takes the rcu_read_lock */
un = find_alloc_undo(ns, semid);
......
sma = sem_obtain_object_check(ns, semid);
......
queue.sops = sops;
queue.nsops = nsops;
queue.undo = un;
queue.pid = task_tgid_vnr(current);
queue.alter = alter;
queue.dupsop = dupsop;
error = perform_atomic_semop(sma, &queue);
if (error == 0) { /* non-blocking succesfull path */
DEFINE_WAKE_Q(wake_q);
......
do_smart_update(sma, sops, nsops, 1, &wake_q);
......
wake_up_q(&wake_q);
goto out_free;
}
/*
* We need to sleep on this operation, so we put the current
* task into the pending queue and go to sleep.
*/
if (nsops == 1) {
struct sem *curr;
curr = &sma->sems[sops->sem_num];
......
list_add_tail(&queue.list,
&curr->pending_alter);
......
} else {
......
list_add_tail(&queue.list, &sma->pending_alter);
......
}
do {
queue.status = -EINTR;
queue.sleeper = current;
__set_current_state(TASK_INTERRUPTIBLE);
if (timeout)
jiffies_left = schedule_timeout(jiffies_left);
else
schedule();
......
/*
* If an interrupt occurred we have to clean up the queue.
*/
if (timeout && jiffies_left == 0)
error = -EAGAIN;
} while (error == -EINTR && !signal_pending(current)); /* spurious */
......
}
semop会调用semtimedop,这是一个非常复杂的函数。semtimedop做的第一件事情就是将用户的参数,例如对于信号量的操作struct sembuf,拷贝到内核里面来。另外如果是P操作,很可能让进程进入等待状态,要为这个等待状态设置一个超时即timeout参数,会把它变成时钟的滴答数目。
semtimedop做的第二件事情,是通过sem_obtain_object_check根据信号量集合的id获得struct sem_array,然后创建一个struct sem_queue表示当前的信号量操作。为什么叫queue呢?因为这个操作可能马上就能完成,也可能因为无法获取信号量不能完成,不能完成就只好排列到队列上,等待信号量满足条件的时候。semtimedop会调用perform_atomic_semop再实施信号量操作,如下所示:
static int perform_atomic_semop(struct sem_array *sma, struct sem_queue *q)
{
int result, sem_op, nsops;
struct sembuf *sop;
struct sem *curr;
struct sembuf *sops;
struct sem_undo *un;
sops = q->sops;
nsops = q->nsops;
un = q->undo;
for (sop = sops; sop < sops + nsops; sop++) {
curr = &sma->sems[sop->sem_num];
sem_op = sop->sem_op;
result = curr->semval;
......
result += sem_op;
if (result < 0)
goto would_block;
......
if (sop->sem_flg & SEM_UNDO) {
int undo = un->semadj[sop->sem_num] - sem_op;
.....
}
}
for (sop = sops; sop < sops + nsops; sop++) {
curr = &sma->sems[sop->sem_num];
sem_op = sop->sem_op;
result = curr->semval;
if (sop->sem_flg & SEM_UNDO) {
int undo = un->semadj[sop->sem_num] - sem_op;
un->semadj[sop->sem_num] = undo;
}
curr->semval += sem_op;
curr->sempid = q->pid;
}
return 0;
would_block:
q->blocking = sop;
return sop->sem_flg & IPC_NOWAIT ? -EAGAIN : 1;
}
在perform_atomic_semop函数中,对于所有信号量操作都进行两次循环。在第一次循环中,如果发现计算出的result小于0,则说明必须等待,于是跳到would_block中,设置q->blocking = sop表示这个queue是block在这个操作上,然后如果需要等待则返回1。如果第一次循环中发现无需等待,则第二个循环实施所有的信号量操作,将信号量的值设置为新的值,并且返回0。
31. 接下来回到semtimedop,来看它干的第三件事情,就是如果需要等待应该怎么办?如果需要等待,则要区分刚才的对于信号量的操作,是对一个信号量的还是对于整个信号量集合的。如果是对于一个信号量的,那就将queue挂到这个信号量的pending_alter中;如果是对于整个信号量集合的,那就将queue挂到整个信号量集合的pending_alter中。
接下来的do-while循环就是要开始等待了。如果等待没有时间限制,则调用schedule让出 CPU;如果等待有时间限制,则调用schedule_timeout让出CPU,过一段时间还回来。当回来的时候判断是否等待超时,如果没有等待超时则进入下一轮循环再次等待,如果超时则退出循环,返回错误。在让出CPU时设置进程的状态为TASK_INTERRUPTIBLE,并且循环的结束会通过signal_pending查看是否收到过信号,这说明这个等待信号量的进程是可以被信号中断的,即一个等待信号量的进程是可以通过kill杀掉的。
再来看semtimedop要做的第四件事情,如果不需要等待应该怎么办?如果不需要等待,就说明对于信号量的操作完成了,也改变了信号量的值。接下就是一个标准流程。我们过DEFINE_WAKE_Q(wake_q)声明一个wake_q,调用do_smart_update,看这次对于信号量的值的改变,可以影响并可以激活等待队列中的哪些struct sem_queue,然后把它们都放在wake_q里面,调用wake_up_q唤醒这些进程。
其实,所有对于信号量的值的修改都会涉及这三个操作,如果回过头去仔细看SETALL和SETVAL操作,在设置完毕信号量之后,也是这三个操作。来看do_smart_update是如何实现的,它会调用update_queue,如下所示:
static int update_queue(struct sem_array *sma, int semnum, struct wake_q_head *wake_q)
{
struct sem_queue *q, *tmp;
struct list_head *pending_list;
int semop_completed = 0;
if (semnum == -1)
pending_list = &sma->pending_alter;
else
pending_list = &sma->sems[semnum].pending_alter;
again:
list_for_each_entry_safe(q, tmp, pending_list, list) {
int error, restart;
......
error = perform_atomic_semop(sma, q);
/* Does q->sleeper still need to sleep? */
if (error > 0)
continue;
unlink_queue(sma, q);
......
wake_up_sem_queue_prepare(q, error, wake_q);
......
}
return semop_completed;
}
static inline void wake_up_sem_queue_prepare(struct sem_queue *q, int error,
struct wake_q_head *wake_q)
{
wake_q_add(wake_q, q->sleeper);
......
}
update_queue会依次循环整个信号量集合的等待队列pending_alter,或者某个信号量的等待队列,试图在信号量的值变了的情况下,再次尝试perform_atomic_semop进行信号量操作。如果不成功则尝试队列中的下一个;如果尝试成功,则调用unlink_queue从队列上取下来,然后调用wake_up_sem_queue_prepare将q->sleeper加到wake_q上去。q->sleeper是一个task_struct,是等待在这个信号量操作上的进程。接下来wake_up_q就依次唤醒wake_q上的所有task_struct,调用的是在进程调度部分提过的wake_up_process方法,如下所示:
void wake_up_q(struct wake_q_head *head)
{
struct wake_q_node *node = head->first;
while (node != WAKE_Q_TAIL) {
struct task_struct *task;
task = container_of(node, struct task_struct, wake_q);
node = node->next;
task->wake_q.next = NULL;
wake_up_process(task);
put_task_struct(task);
}
}
至此,对于信号量的主流操作都解析完毕了。
32. 信号量是一个整个Linux可见的全局资源,好处是可以跨进程通信,坏处就是如果一个进程通过P操作拿到了一个信号量,但是不幸异常退出了,如果没有来得及归还这个信号量,可能所有其他的进程都阻塞了。那怎么办呢?Linux有一种机制叫SEM_UNDO,也即每一个semop操作都会保存一个反向struct sem_undo操作,当因为某个进程异常退出的时候,这个进程做的所有的操作都会回退,从而保证其他进程可以正常工作。前面写的程序里面的semaphore_p函数和semaphore_v函数,都把sem_flg设置为SEM_UNDO就是这个作用。等待队列上的每一个struct sem_queue都有一个struct sem_undo,以此来表示这次操作的反向操作,如下所示:
struct sem_queue {
struct list_head list; /* queue of pending operations */
struct task_struct *sleeper; /* this process */
struct sem_undo *undo; /* undo structure */
int pid; /* process id of requesting process */
int status; /* completion status of operation */
struct sembuf *sops; /* array of pending operations */
struct sembuf *blocking; /* the operation that blocked */
int nsops; /* number of operations */
bool alter; /* does *sops alter the array? */
bool dupsop; /* sops on more than one sem_num */
};
在进程的task_struct里面对于信号量有一个成员struct sysv_sem,里面是一个struct sem_undo_list,将这个进程所有的semop所带来的undo操作都串起来,如下所示:
struct task_struct {
......
struct sysv_sem sysvsem;
......
}
struct sysv_sem {
struct sem_undo_list *undo_list;
};
struct sem_undo {
struct list_head list_proc; /* per-process list: *
* all undos from one process
* rcu protected */
struct rcu_head rcu; /* rcu struct for sem_undo */
struct sem_undo_list *ulp; /* back ptr to sem_undo_list */
struct list_head list_id; /* per semaphore array list:
* all undos for one array */
int semid; /* semaphore set identifier */
short *semadj; /* array of adjustments */
/* one per semaphore */
};
struct sem_undo_list {
atomic_t refcnt;
spinlock_t lock;
struct list_head list_proc;
};
33. 为了更清楚地理解struct sem_undo的原理,这里举一个例子。假设创建了两个信号量集合,一个叫semaphore1,它包含三个信号量,初始化值为3,另一个叫semaphore2,包含4个信号量,初始化值都为4。初始化时候的信号量以及undo结构里面的值如图中(1)标号所示:

首先来看进程1,调用semop将semaphore1的三个信号量的值,分别加1、加2和减3,从而信号量的值变为4、5、0。于是在semaphore1和进程1链表交汇的undo结构里面填写-1、-2、+3,是semop操作的反向操作,如图中(2)标号所示。
然后来看进程2,调用semop将semaphore1的三个信号量的值,分别减3、加2和加1,从而信号量的值变为1、7、1。于是在semaphore1和进程2链表交汇的undo结构里面,填写+3、-2、-1,是semop操作的反向操作,如图中(3)标号所示。
然后接着看进程2,调用semop将semaphore2的四个信号量的值分别减3、加1、加4和减1,从而信号量的值变为1、5、8、3。于是在semaphore2和进程2链表交汇的undo结构里面,填写+3、-1、-4、+1,是semop操作的反向操作,如图中(4)标号所示。
然后再来看进程1,调用semop将semaphore2的四个信号量的值,分别减1、减4、减5 和加2,从而信号量的值变为0、1、3、5。于是在semaphore2和进程1链表交汇的undo结构里面填写+1、+4、+5、-2,是semop操作的反向操作,如图中(5)标号所示。
从这个例子可以看出,无论哪个进程异常退出,只要将undo结构里面的值加回当前信号量的值,就能够得到正确的信号量的值,不会因为一个进程退出,导致信号量的值处于不一致的状态。
34. 信号量的机制也很复杂,对着下面这个图总结一下:

(1)调用semget创建信号量集合。
(2)ipc_findkey会在基数树中,根据key查找信号量集合sem_array对象。如果已经被创建就会被查询出来,例如producer被创建过,在consumer中就会查询出来。
(3)如果信号量集合没有被创建过,则调用sem_ops的newary方法,创建一个信号量集合对象sem_array,例如在producer中就会新建。
(4)调用semctl(SETALL)初始化信号量。
(5)sem_obtain_object_check先从基数树里面找到sem_array对象。
(6)根据用户指定的信号量数组,初始化信号量集合,即初始化sem_array对象的struct sem sems[]成员。
(7)调用semop操作信号量。
(8)创建信号量操作结构sem_queue,放入队列。
(9)创建undo结构放入链表。