前端开发基础知识总结
前端开发基础知识 – 总结
1. HTML
- 常用的 meta 头
html 中的 meta 标签总是位于 head 标签中,用于定义关于页面的一些原数据
meta 标签中的属性是以属性名=属性值的形式定义的
meta标签的两大属性:name(页面描述信息)、http-equiv(http标题信息)
- name属性
(1)keywords(关键字)
(2)description(页面内容描述)
(3)author(作者)
(4)viewport(视口)
<meta name="viewport" content="width=device-width, initial-scale=1.0, user-scaleable=no">
2.http-equive属性
(1)content-type(页面字符集的设定)
(2)expires(期限,网页的到期时间)
(3)pragma(cache模式)
(4)refresh(刷新)
(5)set-cookie(cookie设定)
(6)window-target(显示窗口的设定)
- 对标签语义化的理解
(1)清晰的页面结构
(2)便于团队开发和维护
(3)支持更多的设备(比如:屏幕阅读器)
(4)有利于SEO尽可能少的使用无语义的标签div和span;在语义不明显时,既可以使用div或者p时,尽量用p, 因为p在默认情况下有上下间距,对兼容特殊终端有利;
不要使用纯样式标签,如:b、font、u等,改用css设置。需要强调的文本,可以包含在strong或者em标签中(浏览器预设样式,能用CSS指定就不用他们),strong默认样式是加粗(不要用b),em是斜体(不用i);
使用表格时,标题要用caption,表头用thead,主体部分用tbody包围,尾部用tfoot包围。表头和一般单元格要区分开,表头用th,单元格用td;
表单域要用fieldset标签包起来,并用legend标签说明表单的用途;每个input标签对应的说明文本都需要使用label标签,并且通过为input设置id属性,在lable标签中设置for=someld来让说明文本和相对应的input关联起来。
html5新增的一些语义化标签
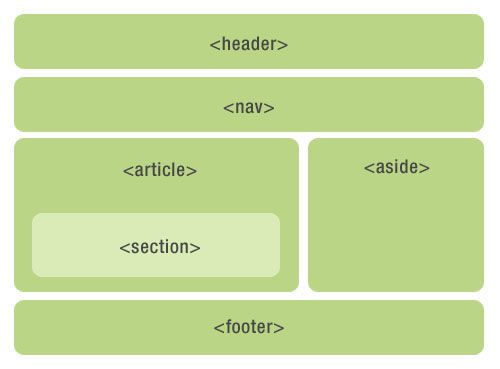
- HTML 5 新增的能力
绘画 canvas 元素
audio、video标签
localStorage(本地数据持久化存储,即使关闭浏览器,数据也存在)
一系列语义化的标签,如:header、nav、article、section、sider、footer
线性渐变(grandient)
边框圆角(border-radius)
阴影(shadow)
- HTML的渲染解析知识(比如:为什么CSS放前面,JS放后面;怎样理解并行加载串行执行)
- CSS 要放在 HTML 的body标签前面,也就是 head 标签中
因为这样的话,浏览器会先读取CSS样式,将样式文件准备好。然后再读取body标签中的结构内容。此时,边渲染DOM元素的同时,也就把样式添加上了。
如果把CSS放在后面,可能会出现白屏问题(IE、Chrome),也可能出现无样式闪烁(Firefox)- JS要放在HTML的后面,也就是body的结束标签之前。
因为在加载JS的时候,会阻塞其他一切的活动,包括:其他资源的下载和页面的呈现。如何用户的网速很慢或者JS文件过大,可能所需的加载时间比较长,此时,可能带给用户页面老是刷不出来的感觉,用户体验会很差。因此,要把它放在后面,先加载HTML和CSS,在静态页面出来了以后,再读取加载JS,让页面动起来。- CSS阻塞:当CSS放在JS之前时,会出现CSS阻塞(因为,浏览器为了保持HTML中CSS和JS的顺序,会在将CSS加载完毕以后才去加载JS,而加载JS具有阻塞其他资源下载的特性,故而会出现CSS阻塞的现象。而将JS放在CSS之前时,就不会出现CSS阻塞)
4.JS阻塞:JS无论放在哪,都会阻塞其他资源的下载。不同的一点是,放在HTML的head标签中时,会阻止其它资源的加载以及页面的呈现;而放在HTML的后面,也就是body结束标签时,则只会阻塞其后的资源的加载。
2. CSS
- 怎样写出更好的CSS,
(0)reset(初始化样式表)
html, body, div, h1, h2, h3, h4, h5, h6, ul, ol, dl, li, dt, dd, p, blockquote, pre, form, fieldset, table, th, td { margin: 0; padding: 0; }
(1)如层级不宜过深
一般不宜超过3层。层级过深会导致查询> >DOM节点耗时耗资源;在浏览器渲染页面>的过程中,DOM树和CSSOM树的关联成>本会更高;CSS代码易读性较差。
(2)何时用 ID 和何时用 class
只有一个独立样式的元素适合用 id,而有>多个元素拥有的相同的样式的元素适合用 >class。
(3)怎么拆分组织
尽量使用CSS外部样式文件,少使用内联>样式和内部样式。
- 盒模型
盒模型有 IE 盒模型和 W3C 盒模型(标准盒模型)。
无论是哪种,都有:content(内容)、padding(内边距)、border(边框)、margin(外边距)
不同之处:
W3C盒模型中,元素的宽度指的就是content的宽度
IE盒模型中,元素的宽度指的是(content的宽度+两边padding的宽度+两边border的宽度)通过设置box-sizing这个属性,可以确定盒模型中元素尺寸的计算方式
/* box-sizing 的默认值是content-box。
尺寸计算公式:width = 内容的宽度,height = 内容的高度。*/
。contentBox{
box-sizing: content-box;
}
/* 推荐使用border-box。
width = border + padding + 内容的 width,
height = border + padding + 内容的 height。*/
.borderBox{
box-sizing: border-box;
}
- 非常常用的 CSS3 知识
(1)比如 CSS3 动画(2)弹性布局
/* 弹性盒子的一般使用方法 */
.container{
display: -webkit-flex;
display: flex;
}
.flex1{
-webkit-flex: 1;
flex: 1;
}
.flex2{
-webkit-flex: 2;
flex: 2;
}
/* 弹性盒子实现元素居中 */
.center{
height: 100px;
-webkit-align-item: center;
align-item: center;
-webkit-justify-content: center;
justify-content: center;
}
3. JavaScript
- 事件模型
JS 中的事件模型包括三种:DOM0事件模型(原始事件模型)、DOM2事件模型、IE事件模型
(1)DOM0事件模型
特点:
- 没有事件传播。事件一旦触发,就会立即执行事件处理函数。
- 一个DOM元素上只能绑定一种类型的事件的一个事件处理程序。若为同一事件绑定了两个事件处理程序,则后面那个事件处理程序会覆盖前面那一个。
- 事件句柄名:on + 事件名
myDiv
document.getElementById('myDiv').onClick = function(e){
alert(e);
};
// 移除事件处理程序
document.getElementById('myDiv').onClick = null;
(2)DOM2事件模型
特点:
- 一个DOM元素上可以为同一事件绑定多个事件处理程序
- 事件会传播
- 方法:
[dom].addEventListener( [event],[function],[true/false] ) --> 绑定事件监听
[dom].removeEventListener( [event],[function],[true/false] ) --> 移除事件监听
event.stopPropagation() --> 取消事件冒泡
event.preventDefault() --> 取消事件的默认行为
DOM2事件模型中,事件传播被分为3个阶段:捕获阶段(不具体的元素-》具体的目标元素)、处于目标阶段(到达目标元素)、冒泡阶段(具体的元素-》不具体的元素)
DOM2中的方法的第3个参数,指定的是:是否在捕获阶段调用事件处理函数,默认为 false,即在冒泡阶段调用事件处理函数。
(3)IE事件模型
特点:- 一个DOM元素可以针对一个事件可以绑定多个事件处理程序
- 事件处理程序的调用都是在事件冒泡阶段
方法:
[dom].attach( [event],[function] ) -->绑定事件
[dom].detach( [event],[function] ) --> 移除事件
- 闭包
指的是:可以访问另一个函数作用域中的变量的函数。创建闭包的最简单的方式就是在一个函数的内部再创建另一个函数。
特点:
- 内部的函数可以访问外部函数的变量,反之则不行。
- 返回的内部函数,保存有状态。
用途:
它的最大用处有两个,一个是可以读取函数内部的变量,另一个就是让这些变量的值始终保持在内存中。- 返回一个函数,延迟执行;
- 将多参数的函数简化为单参数的函数;
- 突破作用域链,保存函数状态;
- …
使用闭包的注意点
1)由于闭包会使得函数中的变量都被保存在内存中,内存消耗很大,所以不能滥用闭包,否则会造成网页的性能问题,在IE中可能导致内存泄露。解决方法是,在退出函数之前,将不使用的局部变量全部删除。
2)闭包会在父函数外部,改变父函数内部变量的值。所以,如果你把父函数当作对象(object)使用,把闭包当作它的公用方法(Public Method),把内部变量当作它的私有属性(private value),这时一定要小心,不要随便改变父函数内部变量的值。
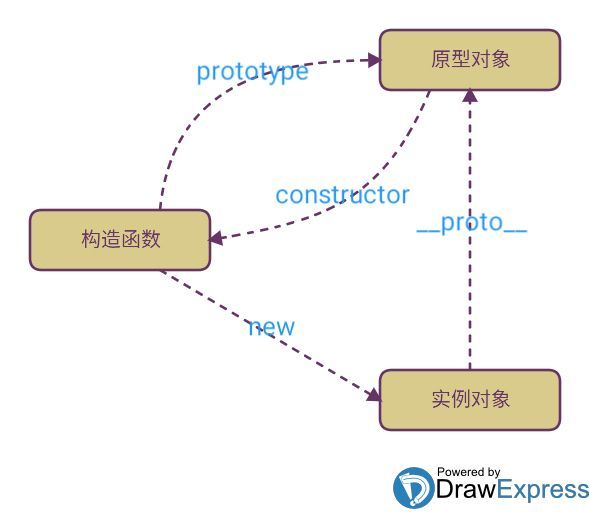
- 原型链
每个实例对象(object )都有一个私有属性(称之为 proto)指向它的原型对象(prototype)。该原型对象也有一个自己的原型对象 ,层层向上直到一个对象的原型对象为 null。根据定义,null 没有原型,并作为这个原型链中的最后一个环节。
几乎所有 JavaScript 中的对象都是位于原型链顶端的Object的实例。
- 浏览器的解析渲染原理
简要来说:
- 解析HTML标签,生成DOM树;
- 解析CSS规则,生成CSS规则树;
- 解析JS文件,根据CSSOM API 和 DOM API 来操作CSS 规则树和 DOM 树;
- 将DOM树与CSS规则树关联起来,构造渲染树(rendering tree)(渲染树中会去除了一些不可见的节点);
- 计算渲染树的节点的几何结构(位置,尺寸等)(layout 和 reflow 的过程);
- 调用操作系统的Native GUI 的 API,渲染绘制页面。
浏览器工作大流程:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fBEYpcSA-1587351247775)(https://coolshell.cn/wp-content/uploads/2013/05/Render-Process-768x250.jpg)]
参考文章:参考文章
- DOM树、渲染树、重排重绘、分层渲染、为什么DOM操作过多会影响性能等
(1)DOM树:DOM是针对HTML和XML文档的一个API。DOM可以将任何的HTML文档和XML文档描绘成一个层次化的节点树。
操作DOM的一些常用方法:
document.documentElement();
document.head();
document.body();
[context].querySelector();
[context].querySelectorAll();
document.getElementById();
[context].getElementsByTagName();
[context].getElementsByClassName();
[context].getElementsByName();
(2)渲染树:
一般来说,在浏览器对页面文件进行解析渲染的过程中,在将文件解析完成之后,将DOM树和CSS规则树关联起来,构造出来的用于后面的页面渲染的树,就是渲染树。
- 渲染树并不等同与DOM树,因为一些像header 或 display: none 的节点就没有必要放在渲染树中了。
- CSS规则树主要是为了完成匹配,并将CSS 规则附加到渲染树的每一个节点(也就是DOM节点)上。DOM节点 + CSS规则 = 渲染树的节点,也就是Frame。
(3)重绘和重排:
repaint(重绘):屏幕的一部分需要重画。比如:某个元素的CSS的背景颜色发生了变化,但是元素的几何尺寸没有发生改变。
reflow(layout / 重排):意味着元素的几何尺寸发生了变化(是渲染树的一部分或全部发生了变化),需要重新验证并计算。HTML的布局是基于流式布局的,所以,如果某元素的几何尺寸发生了变化的话,就会需要重新布局,这也就是 reflow
页面会发生重绘或重排的几种情况有:
- 增加、删除、修改DOM节点;
- 移动DOM的位置;
- 修改CSS样式;
- 滚动窗口;
- 修改页面的默认字体;
- …
/* 触发重排 reflow */
display: none;
/* 触发重绘 repaint */
visibility: hidden;
(4)分层渲染:
(5)为什么DOM操作过多会影响性能:
DOM操作会触发浏览器页面的重绘或重排,这两个操作对于浏览器的性能都是极大的损耗,重排更是。
4. HTTP
- 常见的 HTTP 状态码
(1)1xx 消息
- 100 客户端可以继续发送请求
(2)2xx 成功
- 200 请求已成功处理,请求的资源也已经返回
- 204 no content,请求已成功处理,但没有内容返回
(3)3xx 重定向
- 300 请求的资源可以从多个地址获得
- 301 重定向,资源永久移除,客户端不应该再继续通过该 url 访问该资源
- 302 重定向,资源临时移除,以后可能仍然使用该 url
- 303 see other,请求的资源在另一个URI,应该使用GET定向获取资源
- 304 not modefined,浏览器可以使用本地缓存
(4)4xx 客户端错误
- 400 bad request,客户端发送的请求不能理解
- 401 unauthorized,表示发送的请求需要有HTTP认证信息或是认证失败了
- 403 forbidden,服务器拒绝提供服务
- 404 not found,没找到资源
(5)5xx 服务器端错误
- 500 internal server error ,服务器内部错误
- 503 server unavaliable,服务暂不可用
- 不同请求类型的区别
(1)GET请求
向服务器请求资源,从服务器取回数据。
(2)POST请求
向服务器提交数据。
(3)PULL请求
向服务器推送数据,提交的数据量通常要比POST请求的多。
(4)PUT请求
向服务器更新数据。通过把已经存在的资源的ID和新的实体用PUT请求上传到服务器来更新资源。
(5)DELETE请求
删除服务器上的指定的资源
(6)HEAD请求
HEAD请求与GET请求类似,但仅仅返回相应的头部,没有具体的响应体。
(7)OPTIONS请求
OPTIONS允许客户端请求一个服务所支持的请求方法。它所对应的响应头是Allow,它非常简洁地列出了支持的方法。下面为服务端成功处理了OPTIONS请求后,响应的内容:
Allow: HEAD,GET,PUT,DELETE,OPTIONS
(8)CONNECT请求
主要用来建立一个对资源的网络连接。一旦建立连接后,会响应一个200状态码和一条"Connectioin Established"的消息。