嵌入式攻城狮 II Linux C基础
1.C语言写代码步骤:
- 第一步:编辑源代码(使用vi或者其他编辑器)
- 第二步:编译。编译就是用编译器把源程序转化成可执行程序的过程,编译要用到编译器。我们在linux中使用编译器一般是gcc。譬如:gcc hello.c 把当前目录下hello.c文件编译,得到的可执行文件名字叫a.out。也可以自己指定编译后生成的可执行程序的名字,使用gcc hello.c -o hello
- 第三步:执行编译生成的可执行程序,执行方式是./hello
- 第四步:调试。当你执行后发现程序结果不对,不是自己想要的,这时候就是返回来看源代码哪里不对。然后修改,再编译执行,再看结果。如此循环直接结果正确。
2.VMWare共享文件夹使用
当我们裸机安装了Windows,并且在Windows中安装了虚拟机软件VMWare,并且在虚拟机中安装了ubuntu后。我们一般在Windows中编辑源代码,而在linux中编译、执行源代码。这时候就需要在Windows和linux之间进行交互。怎么来进行交互呢?之前通过smb服务器,现在通过VMWare的共享文件夹就可以轻松实现。
怎么建立Windows的共享文件夹?
- 第一步:先在Windows中创建一个文件夹,主要要使用英文名称。
- 第二步:VMWare中,菜单栏 VM -> Settings -> Options -> Shared Folders选项卡,右边上侧选择Always Enabled,下面点击Add,next,在打开的选项卡中Host Path项目中浏览选择刚才第一步中创建的文件夹,下面Name中会自动弹出一个相同的名字,这个名字是将来Windows中的文件夹在linux虚拟机中的映射文件夹,名字可以改也可以不改。然后一直OK,完成即可。
- 第三步:在linux中,直接到 /mnt/hgfs目录下,即可找到刚才第二步中Name相同的名字的文件夹,这个目录即是第一步中Windows中目录在linux下的映射。
3.数据类型
3.1 基本数据类型
- 数据类型分2类:基本数据类型+复合类型
- 基本类型:char short int long float double
- 复合类型:数组 结构体 共用体 类(C语言没有类,C++有)
3.1.1 内存占用与sizeof运算符
- 数据类型就好像一个一个的模子,这个模子实例化出C语言的变量。变量存储在内存中,需要占用一定的内存空间。一个变量占用多少空间是由变量的数据类型决定的。
- 每种数据类型,在不同的机器平台上占用内存是不同的。我们一般讲的时候都是以32位CPU为默认硬件平台来描述:
- char 1字节 8位
- short 2字节 16位
- int 4字节 32位
- long 4字节 32位
- float 4字节 ...
- double 8字节 ...
- 指针 4字节 ...
3.1.2 有符号数和无符号数
- 对于char short int long等整型类型的数,都分有符号有无符号数。而对于float和double这种浮点型数来说,只有有符号数,没有无符号数。
- 对于C语言来说,数(也就是变量)是存储在内存中一个一个的格子中的。存储的时候是以二进制方式存储的。对于有符号数和无符号数来说,存储方式不同的。
- 譬如对于int来说:unsigned int 无符号数,32位(4字节)全部用来存数的内容 所以表示的数的范围是0 ~ 4294967295(2^32 - 1)。
- signed int 有符号数,32位中最高位用来存符号(0表示正数,1表示负数),剩余的31位用来存数据。所以可以表示的数的范围是 -2147483648(2^32) ~ 2147483647(2^31 - 1)
- 结论:从绝对数值来说,无符号数所表示的范围要大一些。因为有符号数使用1个二进制位来表示正负号。
3.1.3 整形数和浮点型数存储方式上的不同
- 对于float和double这种浮点类型的数,它在内存中的存储方式和整型数不一样。所以float和int相比,虽然都是4字节,但是在内存中存储的方式完全不同。所以同一个4字节的内存,如果存储时是按照int存放的,取的时候一定要按照int型方式去取。如果存的时候和取的时候理解的方式不同,那数据就完全错了。
- 备注:详细的数制存储可以查找资料:计算机原码、反码、补码等知识。
- 总结:存取方式上主要有两种,一种是整型、一种是浮点型。这两种存取方式完全不同,没有任何关联,所以是绝对不能随意改变一个变量的存取方式。在整形和浮点型之内,譬如说4种整型char、short、int、long只是范围大小不同而已,存储方式是一模一样的。float和double存储原理是相同的,方式上有差异,导致了能表示的浮点型的范围和精度不同。
3.2 空类型(关键字void)
- C语言中的void类型,代表任意类型,而不是空的意思。任意类型的意思不是说想变成谁就变成谁,而是说它的类型是未知的,是还没指定的。
- void * 是void类型的指针。void类型的指针的含义是:这是一个指针变量,该指针指向一个void类型的数。void类型的数就是说这个数有可能是int,也有可能是float,也有可能是个结构体,哪种类型都有可能,只是我当前不知道。
- void型指针的作用就是,程序不知道那个变量的类型,但是程序员自己心里知道。程序员如何知道?当时给这个变量赋值的时候是什么类型,现在取的时候就还是什么类型。这些类型对不对,能否兼容,完全由程序员自己负责。编译器看到void就没办法帮你做类型检查了。
#include
#include
int main()
{
int a=444;
void *p;
p = &a;
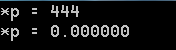
printf("*p = %d\n",*(int *)p); //先做强制类型转换,再取值
printf("*p = %f\n",*(float *)p);
return 0;
} 
- 在函数的参数列表和返回值中,void代表的含义是:
- 一个函数形参列表为void,表示这个函数调用时不需要给它传参。
- 返回值类型是void,表示这个函数不会返回一个有意义的返回值。所以调用者也不要想着去使用该返回值。
- C语言设计基本理念:C语言相信程序员永远是对的,C语言相信程序员都是高手,C语言赋予了程序员最大的权利。所以C语言的程序员必须自己对程序的对错负责,必须随时脑袋清楚,知道自己在干嘛。
3.3 数据类型转换
- C语言中有各种数据类型,写程序时需要定义各种类型的变量。这些变量需要参与运算。C语言有一个基本要求就是:不同类型的变量是不能直接运算的。
3.3.1 隐式转换
- 隐式转换就是自动转换,是C语言默认会进行的,不用程序员干涉。
- C语言的理念:隐式类型转换默认朝精度更高、范围更大的方向转换。
3.3.2 强制类型转换
- C语言默认不会这么做,但是程序员我想这么做,所以我强制这么做了。
3.4 C语言与bool类型
- C语言中原生类型没有bool,C++中有。在C语言中如果需要使用bool类型,可以用int来代替。
- 很多代码体系中,用以下宏定义来定义真和假
- #define TRUE 1
- #define FALSE 0
4.变量和常量
变量——在程序运行过程中,可以通过代码使它的值改变的量
局部变量——定义在函数中的变量
普通局部变量(auto)——定义时直接定义,或者在定义前加auto关键字
void func1(void)
{
int i = 1;
i++;
printf("i = %d.\n", i);
}局部变量i的解析:
- 在连续三次调用func1中,每次调用时,在进入函数func1后都会创造一个新的变量i,并且给它赋初值1,然后i++时加到2,然后printf输出时输出2.然后func1本次调用结束,结束时同时杀死本次创造的这个i。这就是局部变量i的整个生命周期。
- 下次再调用该函数func1时,又会重新创造一个i,经历整个程序运算,最终在函数运行完退出时再次被杀死。
静态局部变量(static)——定义时前面加static关键字。
-
1、静态局部变量和普通局部变量不同。静态局部变量也是定义在函数内部的,静态局部变量定义时前面要加static关键字来标识,静态局部变量所在的函数在多调用多次时,只有第一次才经历变量定义和初始化,以后多次在调用时不再定义和初始化,而是维持之前上一次调用时执行后这个变量的值。本次接着来使用。
-
2、静态局部变量在第一次函数被调用时创造并初始化,但在函数退出时它不死亡,而是保持其值等待函数下一次被调用。下次调用时不再重新创造和初始化该变量,而是直接用上一次留下的值为基础来进行操作。
- 3、静态局部变量的这种特性,和全局变量非常类似。它们的相同点是都创造和初始化一次,以后调用时值保持上次的不变。不同点在于作用域不同
2.1.1.4、register关键字
register(寄存器),C语言的一个关键字
register int i = 3;
总结:register类型的局部变量表现上和auto是一样的,这东西基本没用,知道就可以了。register被称为:C语言中最快的变量。C语言的运行时环境承诺,会尽量将register类型的变量放到寄存器中去运行(普通的变量是在内存中),所以register类型的变量访问速度会快很多。但是它是有限制的:首先寄存器数目是有限的,所以register类型的变量不能太多;其次register类型变量在数据类型上有限制,譬如你就不能定义double类型的register变量。一般只在内核或者启动代码中,需要反复使用同一个变量这种情况下才会使用register类型变量。
2.1.2、全局变量
定义在函数外面的变量,就叫全局变量。
2.1.2.1、普通全局变量
普通全局变量就是平时使用的,定义前不加任何修饰词。普通全局变量可以在各个文件中使
用,可以在项目内别的.c文件中被看到,所以要确保不能重名。
2.1.2.2、静态全局变量
静态全局变量就是用来解决重名问题的。静态全局变量定义时在定义前加static关键字,
告诉编译器这个变量只在当前本文件内使用,在别的文件中绝对不会使用。这样就不用担心重名问题。所以静态的全局变量就用在我定义这个全局变量并不是为了给别的文件使用,本来就是给我这个文件自己使用的。
2.1.1.3、跨文件引用全局变量(extern)
就是说,你在一个程序的多个.c源文件中,可以在一个.c文件中定义全局变量g_a,并且可以在别的另一个.c文件中引用该变量g_a(引用前要声明)
函数和全局变量在C语言中可以跨文件引用,也就是说他们的连接范围是全局的,具有文件连接属性,总之意思就是全局变量和函数是可以跨文件看到的(直接影响就是,我在a.c和b.c中各自定义了一个函数func,名字相同但是内容不同,编译报错。)。
局部变量和全局变量的对比:
1、定义同时没有初始化,则局部变量的值是随机的,而全局变量的值是默认为0.
2、使用范围上:全局变量具有文件作用域,而局部变量只有代码块作用域。
3、生命周期上:全局变量是在程序开始运行之前的初始化阶段就诞生,到整个程序结束退出的时候才死亡;而局部变量在进入局部变量所在的代码块时诞生,在该代码块退出的时候死亡。
4、变量分配位置:全局变量分配在数据段上,而局部变量分配在栈上。
判断一个变量能不能使用,有没有定义,必须注意两点:第一,该变量定义的作用域是否在当前有效,是否包含当前位置;第二,变量必须先定义后使用。所以变量引用一定要在变量定义之前
5.完整的main()函数
- main函数的完整形式:
int main(int argv,char* argc[])
{
printf("Hello,world!");
return 0
}- C语言程序在Linux运行的时候,可以跟操作系统进行交互,可以完美兼容
- 将两个命令一起执行:命令一 && 命令二(待命令一成功执行后进行命令2)
- 判断是否执行成功: echo $? 若执行成功则返回“0”
- 程序执行后判断程序是否正常执行:echo $?-----返回0为正常----所以main函数中return必须为0,才能让系统判断为正常执行
- cp 命令:cp main.c main2.c //cp+空格+程序+空格+拷贝后的程序名
- agrc的值为该程序运行时所添加的参数数量 例如:
int main(int argv,char* argc[]) //通过该函数可以把程序运行时所添加的参数数量输出数来。
{
printf("argv is %d\n",argv); //打印出有几个参数,ls -l -a ads sda 就会打印出argv is 5
int i;
for(i=0;i- 以上内容和linux,unix联系非常紧密,尤其是在linu嵌入式,linux小工具的开发,以及linux的网络编程,都是很重要的内容。
6.Linux的输入流、输出流、错误流



- Linux认为所有的设备都是文件
- 默认输入设备:键盘 默认输出设备:显示器
- 标准输入流、输出流、错误流的使用格式:
- 标准输入流: scanf("%d", &a);==fscanf(stdin, "%d", &a);
- 标准输出流: printf("input a:");==fprintf(stdout, "input a:");
- 标准错误流: fprintf(stderr, "a must > 0");
- 标准错误流要求返回值不能为0


- 重定向输出流到a.txt文件中(1可省略不写)
- 多次重定向(使用双箭头>>)并不会覆盖原来文件中的信息(追加到结尾),单箭头(>)重定向则只保留最新信息(覆盖)
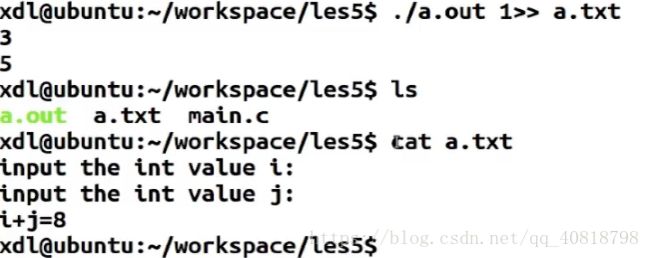 重定向一次
重定向一次
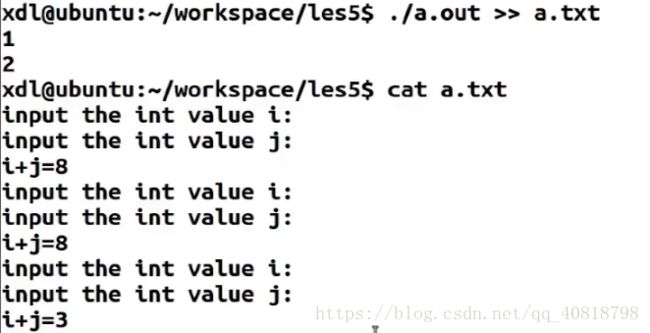 重定向三次
重定向三次

- 查看etc文件夹下的内容,并将其输出到etc.txt文件夹下

- 重定向输入流,文件input.txt中存值为6 8
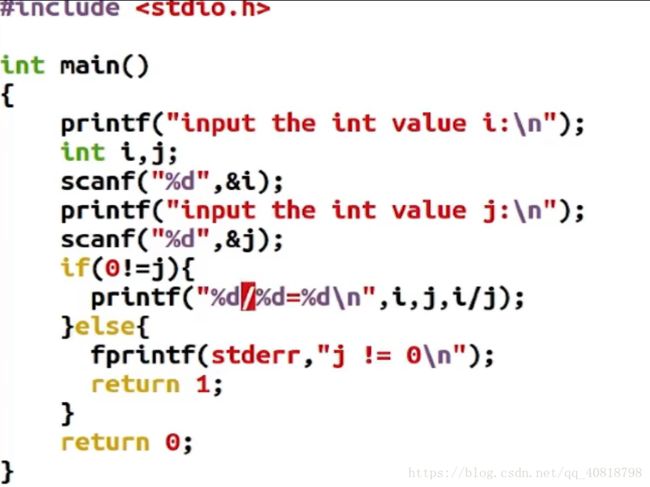

- 正常执行,返回值为0

- 标准错误流提示 j != 0 并返回1
![]()
- 标准输出流导入t.txt 标准错误流导入f.txt 标准输入流导入input.txt

7.管道原理及应用

- | 为管道命令
- 将 ls /etc/ 的输出流作为 grep命令的输入流
- grep 查找包含 某几个字符 的文件
8.打造C语言实用小程序
- 【编写使用管道的程序】 我们在文件夹下,c语言做的每个程序都有一个独立的功能,我们可以将多个小程序使用管道连接到一起。 例:
- 写一个程序avg.c,求任意个数的平均值:
#include
int main()
{
int s, n;
scanf("%d,%d", &s, &n);
float v = s / n;
printf("v = %f\n", v);
return 0;
} - 退出vim进行编译cc avg.c -o avg.out,我们得到avg.out,我们输入3000,3。
- 我们再写一个统计输入的程序input.c:
#include
int main()
{
int flag = 1;
int i;
int count = 0;
int s = 0;
while(flag)
{
scanf("%d", &i);
if(0==i) break;
count++;
s+=i;
}
printf("%d,%d\n",s,count);
return 0;
} - 我们对这个函数进行编译cc input.c -o input.out,我们输入3000 2000 0,输出总工资5000和人数2。
- 我们不妨使用以上两个程序结合起来,将所有数据进行统计input.out,之后通过管道经过avg.out计算平均值,命令可以写为./input.out | ./avg.out,然后进行输入,输入完成我们便得到了对应的平均工资。 以上就是通过管道,将两个小程序连接起来得到更复杂的程序的过程。
9.预处理

- 头文件的插入
- 宏的替换(字符串替换,不做语法检查)

基本概念:
作用域:起作用的区域,也就是可以工作的范围。
代码块:所谓代码块,就是用{}括起来的一段代码。
数据段:数据段存的是数,像全局变量就是存在数据段的
代码段:存的是程序代码,一般是只读的。
栈(stack):先进后出。C语言中局部变量就分配在栈中。
C语言对内存的管理方式。
2.2、常量
常量,程序运行过程中不会改变的量。常量的值在程序运行之前初始化的时候给定一次,以后都不会变了,以后一直是这个值。
2.2.1、#define定义的常量
#define N 20 // 符号常量
int a[N];
2.2.2、const关键字
const int i = 14
const和指针结合,共有4种形式
const int *p; p是一个指针,指针指向一个int型数据。p所指向的是个常量。
int const *p; p是一个指针,指针指向一个int型数据。p所指向的是个常量。
int *const p; p是一个指针,指针指向一个int型数据。p本身是常量,p所指向的是个变量
const int *const p; p是一个指针,指针指向一个int型数据。p本身是常量,指向的也是常量
结论和记忆方法:
1、const在*前面,就表示const作用于p所指向的量。所以这时候p所指向的是个常量。
2、const在*后面,表示p本身是常量,但是p指向的不一定是常量。
const型指针有什么用?
char *strcpy(char *dst, const char *src);
字符串处理函数strcpy,它的函数功能是把src指向的字符串,拷贝到dst中。
2.2.3、枚举常量
枚举常量是宏定义的一种替代品,在某些情况下会比宏定义好用。
enum
3、多文件C语言项目
3.1、简单的C语言程序(项目)只有一个C文件(a.c),编译的时候gcc a.c -o a,执行的时候./a
3.2、复杂的C语言程序(项目)是由多个C文件构成的。譬如一个项目中包含2个c文件(a.c, b.c),编译的时候 gcc a.c b.c -o ab,执行的时候 ./ab
实验:
在a.c和b.c中分别定义main函数,各自单独编译时没问题;但是两个文件作为一个项目来编译
gcc a.c b.c -o ab的时候,就会报错。multiple definition of `main'
为什么报错?
因为a.c和b.c这时候组成了一个程序,而一个程序必须有且只能有一个main函数。
3.3、为什么需要多文件项目?为什么不在一个.c文件中写完所有的功能?
因为一个真正的C语言项目是很复杂的,包含很多个函数,写在一个文件中不利于查找、组织、识别,所以人为的将复杂项目中的很多函数,分成了一个一个的功能模块,然后分开放在不同的.c文件中,于是乎有了多文件项目。
所以,在b.c中定义的一个函数,很可能a.c中就会需要调用。你在任何一个文件中定义的任何一个函数,都有可能被其他任何一个文件中的函数来调用。但是大家最终都是被main函数调用的,有可能是直接调用,也可能是间接调用。
3.4、多文件项目中,跨文件调用函数
在调用函数前,要先声明该被调用函数的原型。只要在调用前声明了该函数,那么调用时就好像这个函数是定义在本文件中的函数一样。
总结:函数使用的三大要素:函数定义、函数声明、函数调用
1、如果没有定义,只有声明和调用:编译时会报连接错误。undefined reference to `func_in_a'
2、如果没有声明,只有定义和调用:编译时一般会报警告,极少数情况下不会报警告。但是最好加上声明。
3、如果没有调用,只有定义和声明:编译时一般会报警告(有一个函数没有使用),有时不会报警告。这时候程序执行不会出错,只是你白白的写了几个函数,而没有使用浪费掉了而已。
实验:在一个项目的两个.c文件中,分别定义一个名字相同的函数,结果?
编译报错 multiple definition of `func_in_a'
结论:在一个程序中,不管是一个文件内,还是该程序的多个文件内,都不能出现函数名重复的情况,一旦重复,编译器就会报错。主要是因为编译器不知道你调用该函数时到底调用的是哪个函数,编译器在调用函数时是根据函数名来识别不同的函数的。
3.5、跨文件的变量引用
(1)通过实验验证得出结论:在a.c中定义的全局变量,在a.c中可以使用,在b.c中不可以直接使用,编译时报错 error: ‘g_a’ undeclared (first use in this function)
(2)想在b.c中使用a.c中定义的全局变量,有一个间接的使用方式。在a.c中写一个函数,然后函数中使用a.c中定义的该全局变量,然后在b.c中先声明函数,再使用函数。即可达到在b.c中间接引用a.c中变量的目的。
(3)想在b.c中直接引用a.c中定义的全局变量g_a,则必须在b.c中引用前先声明g_a,如何声明变量? extern int g_a;
extern关键字:
extern int g_a; 这句话是一个全局变量g_a的声明,这句话告诉编译器,我在外部(程序中
不是本文件的另一个文件)某个地方定义了一个全局变量 int g_a,而且我现在要在这里引用它
告诉你编译器一声,不用报错了。
问题:
1、我只在b.c中声明变量,但是别的文件中根本就定义这个变量,会怎么样?
答案是编译报错(连接错误)undefined reference to `g_b'
2、我在a.c中定义了全局变量g_a,但是b.c中没有声明g_a,引用该变量会怎么样?
答案是直接抱错了,未定义
3、在a.c中定义,在b.c中声明,a.c和b.c中都没有引用该变量,会怎么样?
答案是不会出错。只是白白的定义了一个变量没用,浪费了
结论:不管是函数还是变量,都有定义、声明、引用三要素。其中,定义是创造这个变量或者函数,声明是向编译器交代它的原型,引用是使用这个变量或函数。所以如果没有定义只有声明和引用,编译时一定会报错。undefined reference to `xxx'
在一个程序里面,一个函数可以定义一次,引用可以有无数次,声明可以有无数次。因为函数定义或者变量的定义实际上是创造了这个函数/变量,所以只能有一次。(多次创造同名的变量会造成变量名重复,冲突;多次创造同名的函数也会造成函数名重名冲突)。声明是告诉编译器变量/函数的原型,在每个引用了这个全局变量/函数的文件之前都要声明该变量/函数
局部变量能不能跨文件使用?
不能。因为局部变量属于代码块作用域。他的作用域只有他定义的那个函数内部。
静态局部变量能不能跨文件使用?
不能。因为本质上还是个局部变量。
讨论跨文件使用问题,只用讨论全局变量和函数就可以了。
3.6、头文件的引入
3.6.1、为什么需要头文件?
从之前可以看到,函数的声明是很重要的。当我们在一个庞大的项目中,有很多个源文件,每一个源文件中都有很多个函数,并且需要在各个文件中相互穿插引用函数。
怎么解决函数的声明问题?靠头文件。
3.6.2、#include包含头文件时,用<>和""的区别
<>用来包含系统自带的头文件,系统自带指的是不是你写的,是编译器或者库函数或者操作系统提供的头文件。
""用来包含项目目录中的头文件,这些一般是我们自己写的。
3.6.3、防止重复包含头文件
#ifndef __A_H__
#define __A_H__
// C语言头文件中的声明
#endif
3.6.4、写程序时,最好不要在头文件中定义变量。因为这时该头文件被多个源文件包含时,就会出现重复定义问题。全局变量的定义就应该放在某个源文件中,然后在别的源文件中使用前是extern声明。