XGBoost + Boosting 原理简介
XGBoost原理简介
文章目录
- XGBoost原理简介
- 1. 背景
- 2. Boosting
- 2.1. 建立映射
- 2.2. 计算参数
- 3. XGBoost的目标函数
- 4. 化简目标函数
- 5. 使用泰勒级数近似目标函数
- 6. 模型参数化
- 7. 寻找最佳分裂点
- 8. 参考文献
1. 背景
今天听了贪心学院主办,李文哲老师主讲的《XGBoost的技术剖析》直播,让我对XGB的原理有了一些了解。于是我想写一篇笔记整理一下听课的内容。
老师讲得挺通俗易懂的,不过由于XGB本身具有一定的复杂性,要看懂这篇笔记需要有如下的背景知识:
- 决策树的原理
- 泰勒级数
- 损失函数
- 惩罚函数
如果对这些概念不太了解,推荐阅读复旦大学邱锡鹏老师的开源书《神经网络与深度学习》还有人民邮电出版社的《机器学习实战》,泰勒级数可以参考高数课本和网络资料。
2. Boosting
从 XGBoost 这个名字就能看出来,这个模型使用了 Boosting 的方法,那么我们就来先了解一下 Boosting 它是个啥玩意儿。

Figure 1. Bagging vs Boosting \text{Figure 1. Bagging vs Boosting} Figure 1. Bagging vs Boosting
老师的PPT中对比了 Bagging 和 Boosting 两种常用的集成学习方法。
-
Bagging:利用多个过拟合的弱学习器来获得更好的效果。典型的算法有随机森林。
-
Boosting:利用多个欠拟合的弱学习器来获得更好的效果。典型的算法有GBDT/GBRT,Adaboost,XGBoost和LightGBM。
Boosting 本身在不同算法中的具体应用也不完全相同,而从 XGBoost 1的论文 中我们能够了解到,它主要借鉴了 GBDT 的 Boosting 方法
为了加深对 Boosting 的了解,我把 GBDT 2 的论文也找出来看了一下。
2.1. 建立映射
首先,我们通过公式 ( 1 ) (1) (1)建立从 x \mathbf{x} x 到 y y y 的映射。
y ^ = F ( x ; { β m , a m } 1 M ) = ∑ m = 1 M β m h ( x ; a m ) (1) \widehat{y} = F\left(\mathbf{x} ;\left\{\beta_{m}, \mathbf{a}_{m}\right\}_{1}^{M}\right)=\sum_{m=1}^{M} \beta_{m} h\left(\mathbf{x} ; \mathbf{a}_{m}\right) \tag{1} y =F(x;{βm,am}1M)=m=1∑Mβmh(x;am)(1)
这里的 x \mathbf{x} x 和 a m \mathbf{a}_{m} am 用粗体显示,表示它们都是向量, y ^ \widehat{y} y 表示模型的预测值。
公式 ( 1 ) (1) (1)中的 h ( x ; a m ) h\left(\mathbf{x} ; \mathbf{a}_{m}\right) h(x;am) 表示一个个弱分类器, a m \mathbf{a}_{m} am 是弱分类器的参数, β m \beta_m βm 是其权重, { β m , a m } 1 M \left\{\beta_{m}, \mathbf{a}_{m}\right\}_{1}^{M} {βm,am}1M 是 a m \mathbf{a}_{m} am 和 β m \beta_m βm 的 M M M 个组合。 M M M表示弱分类器的数量。
公式 ( 1 ) (1) (1)表示 GBDT 是通过对多个弱分类器结果进行线性加权求和从而求出最终结果的。
2.2. 计算参数
建立了 x \mathbf{x} x 到 y y y 的映射之后,我们就需要考虑如何去计算函数中的参数。
( β m , a m ) = arg min β , a ∑ i = 1 N L ( y i , F m − 1 ( x i ) + β h ( x i ; a ) ) (2) \left(\beta_{m}, \mathbf{a}_{m}\right)=\arg \min _{\beta, \mathbf{a}} \sum_{i=1}^{N} L\left(y_{i}, F_{m-1}\left(\mathbf{x}_{i}\right)+\beta h\left(\mathbf{x}_{i} ; \mathbf{a}\right)\right) \tag{2} (βm,am)=argβ,amini=1∑NL(yi,Fm−1(xi)+βh(xi;a))(2)
公式 ( 2 ) (2) (2) 中, arg min β , a \displaystyle\arg \min _{\beta, \mathbf{a}} argβ,amin 表示使其右边的表达式最小的 ( β , a ) (\beta, \mathbf{a}) (β,a) 组合, L ( y i , y i ^ ) L(y_i, \hat{y_i}) L(yi,yi^) 为损失函数。
公式 ( 2 ) (2) (2) 说明参数 ( β m , a m ) \left(\beta_{m}, \mathbf{a}_{m}\right) (βm,am)是通过使得损失函数最小化计算出来的,具体如何计算就取决于我们使用什么具体的损失函数和优化器了。
同时, 我们还可以推出公式 ( 3 ) (3) (3)。
F m ( x ) = F m − 1 ( x ) + β m h ( x ; a m ) (3) F_{m}(\mathbf{x})=F_{m-1}(\mathbf{x})+\beta_{m} h\left(\mathbf{x} ; \mathbf{a}_{m}\right) \tag{3} Fm(x)=Fm−1(x)+βmh(x;am)(3)
公式 ( 3 ) (3) (3) 中 F m ( x ) F_{m}(\mathbf{x}) Fm(x) 是训练完 m m m 个弱分类器以后,模型的输出结果。
公式 ( 3 ) (3) (3) 说明 GBDT 在训练每第 m m m 个弱分类器时,我们需要先将前 m − 1 m-1 m−1 个弱分类器的预测结果求和,从而获得一个新的预测结果,在此基础上对第 m m m 个弱分类器进行训练和预测。即新的弱分类器是在已有模型的残差上进行训练的。
可理解为如下公式。
β m h ( x ; a m ) → ( y i − ∑ k = 1 m − 1 β k h ( x ; a k ) ) (4) \beta_{m} h\left(\mathbf{x} ; \mathbf{a}_{m}\right) \to (y_i - \sum_{k=1}^{m-1} \beta_{k} h\left(\mathbf{x} ; \mathbf{a}_{k}\right)) \tag{4} βmh(x;am)→(yi−k=1∑m−1βkh(x;ak))(4)
即第 m m m 个弱分类器的训练目标是输出趋近于 y i y_i yi 和 前 m − 1 m - 1 m−1 个弱分类器的结果之和的差值。
再结合老师PPT中的例子,应该就能够很好地理解 Boosting 的作用。

Figure 2. Boost Tree \text{Figure 2. Boost Tree} Figure 2. Boost Tree

Figure 3. Model Predict \text{Figure 3. Model Predict} Figure 3. Model Predict
3. XGBoost的目标函数
了解了 Boosting 之后,我们就可以开始学习 XGBoost 了,首先从它的目标函数开始分析。
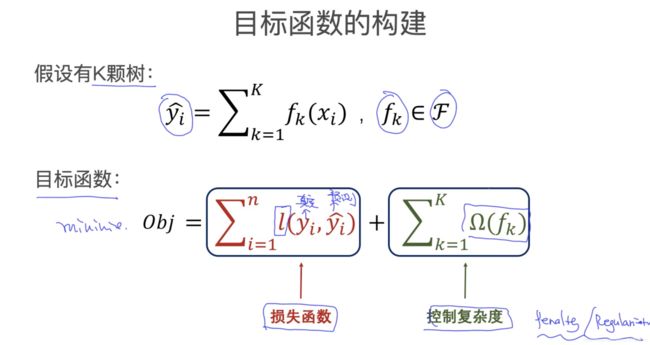
Figure 4. Object Function \text{Figure 4. Object Function} Figure 4. Object Function
我们一般使用树模型来作为弱分类器,假设有 K K K 颗树,对第 i i i 个输入,它们的预测值为 y ^ i \widehat{y}_i y i。
y ^ i = ∑ k = 1 K f k ( x i ) , f k ∈ F (5) \widehat{y}_{i}=\sum_{k=1}^{K} f_{k}\left(\mathbf{x}_{i}\right),\ \ f_{k} \in {\mathcal{F}} \tag{5} y i=k=1∑Kfk(xi), fk∈F(5)
公式 ( 5 ) (5) (5) 中 f k ( x i ) f_k(\mathbf{x}_i) fk(xi) 表示第 k k k 颗树对第 i i i 个输入向量的预测输出。
而 XGBoost 的目标函数由损失函数和惩罚函数组成,这一点大多数机器学习模型都差不多。通过最小化损失函数来提高预测精度,引入惩罚函数来控制模型复杂度,防止过拟合。
O b j = ∑ i = 1 n l ( y i , y ^ i ) + ∑ k = 1 K Ω ( f k ) (6) Obj = \sum_{i = 1}^n {l(y_i, \widehat{y}_{i})} + \sum_{k = 1}^K \Omega (f_k) \tag{6} Obj=i=1∑nl(yi,y i)+k=1∑KΩ(fk)(6)
公式 ( 6 ) (6) (6) 中的 n n n 表示输入数据的总数目,我们的优化目标就是最小化目标函数。
min O b j (7) \min Obj \tag{7} minObj(7)
4. 化简目标函数
有了目标函数以后,我们还没有好的办法直接对它进行求解,还需要进行化简。图5是老师的PPT。
Figure 5. Additive Traning \text{Figure 5. Additive Traning} Figure 5. Additive Traning
图5的左半部分主要在解释Additive Traning,和我们在 Boosting 部分提到的类似。我们主要关注右半部分的化简过程。
通过将 y ^ i \widehat{y}_{i} y i 展开,去除常数项,可以将目标函数化简为
O b j = ∑ i = 1 n l ( y i , y ^ i ( k ) ) + ∑ k = 1 K Ω ( f k ) = ∑ i = 1 n l ( y i , y ^ i ( k − 1 ) + f k ( x i ) ) + Ω ( f k ) (8) { \begin{aligned} Obj &= \sum_{i = 1}^n {l(y_i, \widehat{y}_{i}^{(k)})} + \sum_{k = 1}^K \Omega (f_k) & \\ &= \sum_{i = 1}^n {l(y_i, \widehat{y}_{i}^{(k-1)} + f_k(\mathbf{x}_i) )} + \Omega (f_k) & \\ \end{aligned} } \tag{8} Obj=i=1∑nl(yi,y i(k))+k=1∑KΩ(fk)=i=1∑nl(yi,y i(k−1)+fk(xi))+Ω(fk)(8)
此处利用了公式 ( 5 ) (5) (5) 将 y ^ i ( k ) \widehat{y}_{i}^{(k)} y i(k) 中前 k − 1 k-1 k−1 项分离了出来。因为前 k − 1 k-1 k−1 项已经在各自的训练过程中优化过了,在这里可以视为常数项,所以我们将惩罚函数中的前 k − 1 k-1 k−1 项去除,仅考虑要优化的 f k f_k fk 部分。
5. 使用泰勒级数近似目标函数
尽管我们对目标函数进行了化简,但直接对目标函数进行求解,运算的复杂度会非常高,所以我们选择对目标函数进行二级泰勒展开,提高模型的训练速度。
Figure 6. Taylor Expansion \text{Figure 6. Taylor Expansion} Figure 6. Taylor Expansion
根据公式 ( 9 ) (9) (9) 中的二级泰勒展开式。
f ( x + Δ x ) ≈ f ( x ) + f ′ ( x ) ⋅ Δ x + 1 2 f ′ ′ ( x ) ⋅ Δ x 2 (9) f(x + \Delta x) \approx f(x) + f'(x) \cdot \Delta x + \frac{1}{2} f''(x) \cdot \Delta x^2 \tag{9} f(x+Δx)≈f(x)+f′(x)⋅Δx+21f′′(x)⋅Δx2(9)
对目标函数进行展开:
O b j = ∑ i = 1 n l ( y i , y ^ i ( k − 1 ) + f k ( x i ) ) + Ω ( f k ) = ∑ i = 1 n [ l ( y i , y ^ ( k − 1 ) ) + g i f k ( x i ) + 1 2 h i f k 2 ( x i ) ] + Ω ( f k ) (10) { \begin{aligned} Obj &= \sum_{i = 1}^n {l(y_i, \widehat{y}_{i}^{(k-1)} + f_k(\mathbf{x}_i) )} + \Omega (f_k) & \\ &= \sum_{i=1}^{n}\left[l\left(y_{i}, \hat{y}^{(k-1)}\right)+g_{i} f_{k}\left(\mathbf{x}_{i}\right)+\frac{1}{2} h_{i} f_{k}^{2}\left(\mathbf{x}_{i}\right)\right]+\Omega\left(f_{k}\right) &\\ \end{aligned} } \tag{10} Obj=i=1∑nl(yi,y i(k−1)+fk(xi))+Ω(fk)=i=1∑n[l(yi,y^(k−1))+gifk(xi)+21hifk2(xi)]+Ω(fk)(10)
其中 g i = ∂ y ^ ( k − 1 ) l ( y i , y ^ ( k − 1 ) ) g_{i}=\partial_{\hat{y}(k-1)} l\left(y_{i}, \hat{y}^{(k-1)}\right) gi=∂y^(k−1)l(yi,y^(k−1)) 且 h i = ∂ y ^ ( k − 1 ) 2 l ( y i , y ^ ( k − 1 ) ) h_{i}=\partial_{\hat{y}(k-1)}^{2} l\left(y_{i}, \hat{y}^{(k-1)}\right) hi=∂y^(k−1)2l(yi,y^(k−1)), 对应二级泰勒展开式中的一阶导数和二阶导数,由于它们都是基于前 k − 1 k - 1 k−1 个模型的,所以在训练第 k k k 个模型时也是已知的,可以视为常数项。
公式 ( 10 ) (10) (10) 中, l ( y i , y ^ ( k − 1 ) ) l(y_{i}, \hat{y}^{(k-1)}) l(yi,y^(k−1)) 也可视为常数项,并且这一项没有和变量 f k ( x i ) f_k(\mathbf{x}_i) fk(xi)相乘,所以我们可以将展开后的目标函数再次进行化简,结果为:
O b j = ∑ i = 1 n [ g i f k ( x i ) + 1 2 h i f k 2 ( x i ) ] + Ω ( f k ) (11) Obj =\sum_{i=1}^{n}\left[g_{i} f_{k}\left(\mathbf{x}_{i}\right)+\frac{1}{2} h_{i} f_{k}^{2}\left(\mathbf{x}_{i}\right)\right]+\Omega\left(f_{k}\right) \tag{11} Obj=i=1∑n[gifk(xi)+21hifk2(xi)]+Ω(fk)(11)
6. 模型参数化
在公式 ( 5 ) (5) (5) 中 ,我们提到 f k ( x i ) f_k(\mathbf{x}_i) fk(xi) 表示第 k k k 颗树对第 i i i 个输入向量的预测输出。那么我们又应该如何在公式中将 f k ( x i ) f_k(\mathbf{x}_i) fk(xi) 展开,从而进行训练和调优,最终达到优化模型的目的呢。这里我们就需要将模型参数化,将问题转化为参数优化的问题。
那么我们这一节要解决的子问题就是,如何用参数的形式来表示一颗决策树,或者说,如何将决策树的模型参数化。
我们参考周志华老师《机器学习》 3 书中的一个例子。
Figure 7. Decision Tree \text{Figure 7. Decision Tree} Figure 7. Decision Tree
设 y ^ i = 1 \widehat{y}_i = 1 y i=1表示模型预测第 i i i 个瓜为好瓜, y ^ i = 0 \widehat{y}_i = 0 y i=0表示模型预测第 i i i 个瓜为坏瓜。叶子节点标签后的数字为叶子节点的标号。
设 I j = { i ∣ q ( x i ) = j } I_j = \{i | q(\mathbf{x}_{i}) = j\} Ij={i∣q(xi)=j} 为被分到第 j j j 个叶子节点中的 x i \mathbf{x}_{i} xi 的序号集合。 q ( x i ) q(\mathbf{x}_{i}) q(xi) 为输入 x i \mathbf{x}_{i} xi到叶子节点序号的映射。
设 w j = α ( j ) w_j = \alpha (j) wj=α(j) 为第 j j j 个叶子节点的 y ^ \widehat{y} y 值。取样例数据进行说明:
Table 1. Sample Data \text{Table 1. Sample Data} Table 1. Sample Data
| 序号 | 纹理 | 触感 | 密度 | 好瓜 |
|---|---|---|---|---|
| 1 | 清晰 | 硬滑 | 0.697 | 是 |
| 2 | 清晰 | 软粘 | 0.267 | 否 |
| 3 | 稍糊 | 硬滑 | 0.091 | 否 |
则
f k ( x 1 ) = α ( q ( x 1 ) ) = α ( 2 ) = 1 = w 2 f k ( x 2 ) = α ( q ( x 2 ) ) = α ( 1 ) = 0 = w 1 f k ( x 3 ) = α ( q ( x 3 ) ) = α ( 3 ) = 0 = w 3 { \begin{aligned} f_k(\mathbf{x}_{1}) = \alpha (q(\mathbf{x}_{1})) =\alpha(2)=1 = w_2 & \\ f_k(\mathbf{x}_{2}) = \alpha (q(\mathbf{x}_{2})) =\alpha(1)=0 = w_1 & \\ f_k(\mathbf{x}_{3}) = \alpha (q(\mathbf{x}_{3})) =\alpha(3)=0 = w_3 & \\ \end{aligned} } fk(x1)=α(q(x1))=α(2)=1=w2fk(x2)=α(q(x2))=α(1)=0=w1fk(x3)=α(q(x3))=α(3)=0=w3
根据上面的定义,我们继续对目标函数进行化简。
首先展开惩罚函数:
Ω ( f ) = γ T + 1 2 λ ∥ w ∥ 2 (12) \Omega(f)=\gamma T+\frac{1}{2} \lambda\|w\|^{2} \tag{12} Ω(f)=γT+21λ∥w∥2(12)
O b j = ∑ i = 1 n [ g i f k ( x i ) + 1 2 h i f k 2 ( x i ) ] + γ T + 1 2 λ ∑ j = 1 T w j 2 (13) \begin{aligned} Obj &=\sum_{i=1}^{n}\left[g_{i} f_{k}\left(\mathbf{x}_{i}\right)+\frac{1}{2} h_{i} f_{k}^{2}\left(\mathbf{x}_{i}\right)\right]+\gamma T+\frac{1}{2} \lambda \sum_{j=1}^{T} w_{j}^{2}\\ \end{aligned} \tag{13} Obj=i=1∑n[gifk(xi)+21hifk2(xi)]+γT+21λj=1∑Twj2(13)
公式 ( 12 ) (12) (12) 中 γ \gamma γ 为树的深度, T T T 为叶子节点个数, λ \lambda λ 为惩罚项系数。 ∥ w ∥ 2 \|w\|^{2} ∥w∥2 为L2正则化项。公式 ( 13 ) (13) (13) 为将惩罚函数带入后的目标函数。
下面将 f k ( x i ) f_{k}\left(\mathbf{x}_{i}\right) fk(xi) 从对每一项输入数据的输出求和,转为对每一个叶子节点的输出求和。
O b j = ∑ j = 1 T [ ( ∑ i ∈ I j g i ) w j + 1 2 ( ∑ i ∈ I j h i + λ ) w j 2 ] + γ T (14) Obj=\sum_{j=1}^{T}\left[\left(\sum_{i \in I_{j}} g_{i}\right) w_{j}+\frac{1}{2}\left(\sum_{i \in I_{j}} h_{i}+\lambda\right) w_{j}^{2}\right]+\gamma T \tag{14} Obj=j=1∑T⎣⎡⎝⎛i∈Ij∑gi⎠⎞wj+21⎝⎛i∈Ij∑hi+λ⎠⎞wj2⎦⎤+γT(14)
公式 ( 14 ) (14) (14) 中 I j = { i ∣ q ( x i ) = j } I_j = \{i | q(\mathbf{x}_{i}) = j\} Ij={i∣q(xi)=j} 是被分到第 j j j 个叶子节点中的 x i \mathbf{x}_{i} xi 的序号集合。
7. 寻找最佳分裂点
我们假设树的结构 q ( x i ) q(\mathbf{x}_{i}) q(xi) 是确定的,即公式 ( 13 ) (13) (13) 中, γ \gamma γ 和 T T T 两个参数是确定的, I j I_j Ij 也是确定的,剩下的自变量就只有 w j 2 w_j^2 wj2,我们就得到了一个一元二次方程。
要使这个一元二次方程最小,我们就需要找到它的极值点。
首先考虑二次项系数的正负性。 λ \lambda λ 是惩罚项系数,是非负的,而
h i = ∂ y ^ ( k − 1 ) 2 l ( y i , y ^ ( k − 1 ) ) h_{i}=\partial_{\hat{y}(k-1)}^{2} l\left(y_{i}, \hat{y}^{(k-1)}\right) hi=∂y^(k−1)2l(yi,y^(k−1)),是损失函数的二阶导数。
我们参考《神经网络与深度学习》 4 中给出的常用损失函数。

Figure 8. Loss Function \text{Figure 8. Loss Function} Figure 8. Loss Function
XGBoost 常用的是平方损失,它的二阶导函数恒为正数。所以目标函数二次项系数也恒为正。
所以我们根据一元二次方程的性质,求解目标函数的最小值。
w j ∗ = − ∑ i ∈ I j g i ∑ i ∈ I j h i + λ (15) w_{j}^{*}=-\frac{\sum_{i \in I_{j}} g_{i}}{\sum_{i \in I_{j}} h_{i}+\lambda} \tag{15} wj∗=−∑i∈Ijhi+λ∑i∈Ijgi(15)
带入公式 ( 14 ) (14) (14) 可求得
O b j ( q ) = − 1 2 ∑ j = 1 T ( ∑ i ∈ I j g i ) 2 ∑ i ∈ I j h i + λ + γ T (16) Obj(q)=-\frac{1}{2} \sum_{j=1}^{T} \frac{\left(\sum_{i \in I_{j}} g_{i}\right)^{2}}{\sum_{i \in I_{j}} h_{i}+\lambda}+\gamma T \tag{16} Obj(q)=−21j=1∑T∑i∈Ijhi+λ(∑i∈Ijgi)2+γT(16)
公式 ( 16 ) (16) (16) 中 q q q 为某一确定的树结构。 O b j ( q ) Obj(q) Obj(q) 可以作为评分函数,用来计算树结构的得分。类似于决策树模型中的信息熵(Information Entropy)。
由于遍历所有的树结构是一个 N P NP NP 问题,所以 XGBoost 采用了贪心算法来求得树结构的局部最优解。
假设 I L I_L IL 和 I R I_R IR 是分割后的左节点和右节点的 x i \mathbf{x}_{i} xi 的序号集合, I = I L ⋃ I R I = I_L \bigcup I_R I=IL⋃IR,那么每次分裂后 O b j ( q ) Obj(q) Obj(q) 的减少值为:
L s p l i t = 1 2 [ ( ∑ i ∈ I L g i ) 2 ∑ i ∈ I L h i + λ + ( ∑ i ∈ I R g i ) 2 ∑ i ∈ I R h i + λ − ( ∑ i ∈ I g i ) 2 ∑ i ∈ I h i + λ ] − γ (17) \mathcal{L}_{s p l i t}=\frac{1}{2}\left[\frac{\left(\sum_{i \in I_{L}} g_{i}\right)^{2}}{\sum_{i \in I_{L}} h_{i}+\lambda}+\frac{\left(\sum_{i \in I_{R}} g_{i}\right)^{2}}{\sum_{i \in I_{R}} h_{i}+\lambda}-\frac{\left(\sum_{i \in I} g_{i}\right)^{2}}{\sum_{i \in I} h_{i}+\lambda}\right]-\gamma \tag{17} Lsplit=21[∑i∈ILhi+λ(∑i∈ILgi)2+∑i∈IRhi+λ(∑i∈IRgi)2−∑i∈Ihi+λ(∑i∈Igi)2]−γ(17)
这个公式可以用来搜索最佳的分裂点,类似于决策树中的信息增益(Information Gain)。
接下来的过程就和一般的决策树训练过程类似了,论文中也给了两个搜索最佳分裂点的算法,我们就不做详细讨论了。

Figure 9. Algorithm 1 \text{Figure 9. Algorithm 1} Figure 9. Algorithm 1

Figure 10. Algorithm 2 \text{Figure 10. Algorithm 2} Figure 10. Algorithm 2
XGBoost 主要的内容大概就是这些,希望了解更加详细内容的同学可以查看原始论文。
8. 参考文献
[1] T. Chen, C. Guestrin, Xgboost: A scalable tree boosting system, CoRR abs/1603.02754. arXiv:1603.02754.
[2] J. Friedman, Greedy function approximation: A gradient boosting machine, The Annals of Statistics 29. doi:10.1214/aos/1013203451.
[3] 周志华, 机器学习, no. 84-85, 清华大学出版社, 2016.
[4] 邱锡鹏, 神经网络与深度学习, no. 74, Github, 2020.
联系邮箱:[email protected]
Github:https://github.com/CurrenWong
欢迎转载/Star/Fork,有问题欢迎通过邮箱交流。