WAV文件格式解析
来源:
http://www.codeguru.com/cpp/g-m/multimedia/audio/article.php/c8935/PCM-Audio-and-Wave-Files.htm#page-1
源程序下载地址:
http://www.codeguru.com/dbfiles/get_file/WaveFun_Src.zip?id=8935&lbl=WAVEFUN_SRC_ZIP
http://www.codeguru.com/dbfiles/get_file/WaveFun_Bin.zip?id=8935&lbl=WAVEFUN_BIN_ZIPWAVE文件支持很多不同的比特率、采样率、多声道音频。WAVE是PC机上存储PCM音频最流行的文件格式,基本上可以等同于原始数字音频。
WAVE文件为了与IFF保持一致,数据采用“chunk”来存储。因此,如果想要在WAVE文件中补充一些新的信息,只需要在在新chunk中添加信息,而不需要改变整个文件。这也是设计IFF最初的目的。
WAVE文件是很多不同的chunk集合,但是对于一个基本的WAVE文件而言,以下三种chunk是必不可少的。
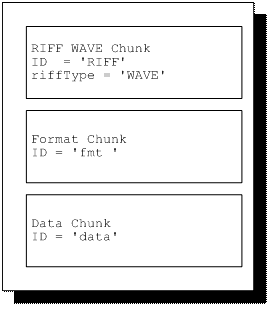
使用WAVE文件的应用程序必须具有读取以上三种chunk信息的能力,如果程序想要复制WAVE文件,必须拷贝文件中所有的chunk。
文件中第一个chunk是RIFFchunk,然后是fmtchunk,最后是datachunk。对于其他的chunk,顺序没有严格的限制。
以下是一个最基本的WAVE文件,包含三种必要chunk。
文件组织形式:
1. 文件头
RIFF/WAV文件标识段
声音数据格式说明段
2. 数据体:
由 PCM(脉冲编码调制)格式表示的样本组成。

描述WAVE文件的基本单元是“sample”,一个sample代表采样一次得到的数据。因此如果用44KHz采样,将在一秒中得到44000个sample。每个sample可以用8位、24位,甚至32位表示(位数没有限制,只要是8的整数倍即可),位数越高,音频质量越好。
此处有一个值得注意的细节,8位代表无符号的数值,而16位或16位以上代表有符号的数值。
例如,如果有一个10bit的样本,由于sample位数要求是8的倍数,我们就需要把它填充到16位。16位中:0-5位补0,6-15位是原始的10bit数据。这就是左补零对齐原则。
上述只是单声道,如果要处理多声道,就需要在任意给定时刻给出多个sameple。例如,在多声道中,给出某一时刻,我们需要分辨出哪些sample是左声道的,哪些sample是右声道的。因此,我们需要一次读写两个sample.
假如以44KHz取样立体声音频,我们需要一秒读写44*2 KHz的sample. 给出公式:
每秒数据大小(字节)=采样率 * 声道数 * sample比特数 / 8
处理多声道音频时,每个声道的样本是交叉存储的。我们把左右声道数据交叉存储在一起:先存储第一个sample的左声道数据,然后存储第一个sample的右声道数据。
当一个设备需要重现声音时,它需要同时处理多个声道,一个sample中多个声道信息称为一个样本帧。
下面将介绍如何使用C++处理WAVE文件。
RIFF头chunk表示如下:
1. struct RIFF_HEADER
2. {
3. TCHAR szRiffID[4]; // 'R','I','F','F'
4. DWORD dwRiffSize;
5.
6. TCHAR szRiffFormat[4]; // 'W','A','V','E'
7. };
第二个块是fmt chunk,它用来描述WAVE文件的特性,例如比特率、声道数。可以使用结构体来描述fmt chunk.
1. struct WAVE_FORMAT
2. {
3. WORD wFormatTag;
4. WORD wChannels;
5. DWORD dwSamplesPerSec;
6. DWORD dwAvgBytesPerSec;
7. WORD wBlockAlign;
8. WORD wBitsPerSample;
9. };
10. struct FMT_BLOCK
11. {
12. TCHAR szFmtID[4]; // 'f','m','t',' ' please note the
13. // space character at the fourth location.
14. DWORD dwFmtSize;
15. WAVE_FORMAT wavFormat;
16. };
最后,描述包含实际声音数据的data chunk:
1. struct DATA_BLOCK
2. {
3. TCHAR szDataID[4]; // 'd','a','t','a'
4. DWORD dwDataSize;
5. };
以上就是一个WAV文件的三个最基本的chunk,也可以有很多可选chunk位于fmt block和data block之间,下面是一个可选chunk的例子(note chunk)。
1. struct NOTE_CHUNK
2. {
3. TCHAR ID[4]; // 'note'
4. long chunkSize;
5. long dwIdentifier;
6. TCHAR dwText[];
7. };
原文:
The WAVE FileFormat
The WAVE File Format supports a variety of bitresolutions, sample rates, and channels of audio. I would say that this is themost popular format for storing PCM audio on the PC and has become synonymouswith the term "raw digital audio."
The WAVE file format is based on Microsoft's version of theElectronic Arts Interchange File Format method for storing data. In keepingwith the dictums of IFF,data in a Wave file is stored in many different "chunks."So, if a vendor wants to store additional information in a Wave file, he justadds info to new chunks instead of trying to tweak the base file format or comeup with his own proprietary file format. That is the primary goal of the IFF.
As mentioned earlier, a WAVE file is a collection of a numberof different types of chunks. But, there are threechunks that are required tobe present in a valid wave file:
1. 'RIFF', 'WAVE' chunk
2. "fmt" chunk
3. 'data' chunk
All otherchunks are optional. The Riff wave chunk is the identifier chunkthat tells us that this is a wave file. The "fmt" chunk containsimportant parameters describing the waveform, such as its sample rate, bits per sample,and so forth. The Data chunk contains the actual waveform data.
An application that uses a WAVE file must be able to read the threerequired chunks,although it can ignore the optional chunks.But, all applications that perform a copy operation on wave files should copy all of the chunksin the WAVE.
The Riffchunk is always the first chunk. The fmt chunk should be present before thedata chunk. Apart from this, there are no restrictions upon the order of thechunks within a WAVE file.
Here is an example of the layout for a minimal WAVE file. Itconsists of a single WAVE containing the three required chunks.
While interpreting WAVE files, the unit of measurement usedis a "sample."Literally, it is what it says. A sample represents data captured during asingle sampling cycle. So, if you are sampling at 44 KHz, you will have 44 Ksamples. Each sample could be represented as 8 bits, 16 bits, 24 bits, or 32bits. (There is no restriction on how many bits you use for a sample exceptthat it has to be a multiple of 8.) To some extent, the more the number of bitsin a sample, the better the quality of the audio.
One annoying detail to note is that 8-bit samples arerepresented as "unsigned"values whereas 16-bit and higher are represented by "signed"values. I don't know why this discrepancy exists; that's just the way it is.
The data bits for each sample should be left-justified and padded with0s. For example, consider the case of a 10-bit sample (assamples must be multiples of 8, we need to represent it as 16 bits). The 10bits should be left-justified so that they become bits 6 to 15 inclusive, andbits 0 to 5 should be set to zero.
The analogy I have provided is for mono audio, meaning that you have just one"channel." When you deal with stereo audio, 3Daudio, and so forth, you are in effect dealing with multiplechannels, meaning you have multiple samples describing theaudio in any given moment in time. For example, for stereo audio, at any givenpoint in time you need to know what the audio signal was for the left channel as well as the right channel.So, you will have to read and write two samples at a time.
Say you sample at 44 KHz for stereoaudio; then effectively, you will have 44 K * 2 samples. If you are using 16bits per sample, then given the duration of audio, you can calculate the totalsize of the wave file as:
Size in bytes = sampling rate * numberof channels * (bits per sample / 8) * duration in seconds
When youare dealing with such multi-channelsounds, single sample points from each channel are interleaved. Instead of storing all of the samplepoints for the left channel first, and then storing all of the sample pointsfor the right channel next, you "interleave"the two channels' samples together. You would store the first sample of theleft channel. Then, you would store the first sample of the right channel, andso on.
When adevice needs to reproduce the stored stereo audio (or any multi-channel audio),it will process the left and right channels (or however many channels thereare) simultaneously. This collective piece of information is called a sample frame.
So far,you have covered the very basics of PCM audio and how it is represented in awave file. It is time to take a look at some code and see how you can use C++to manage wave files. Start by laying out the structures for the differentchunks of a wave file.
Thefirst chunk is the riff header chunk and can be represented as follows. You usea TCHAR that is defined as a normal ASCII char or as a wide character dependingupon whether the UNICODE directive has been set on your compiler.
- struct RIFF_HEADER
- {
- TCHAR szRiffID[4]; // 'R','I','F','F'
- DWORD dwRiffSize;
- TCHAR szRiffFormat[4]; // 'W','A','V','E'
- };
I guessit is self explanatory. The second chunk is the fmt chunk. It describes theproperties of the wave file, such as bits per sample, number of channels, andthe like. You can use a helper structure to neatly represent the chunk as:
- struct WAVE_FORMAT
- {
- WORD wFormatTag;
- WORD wChannels;
- DWORD dwSamplesPerSec;
- DWORD dwAvgBytesPerSec;
- WORD wBlockAlign;
- WORD wBitsPerSample;
- };
- struct FMT_BLOCK
- {
- TCHAR szFmtID[4]; // 'f','m','t',' ' please note the
- // space character at the fourth location.
- DWORD dwFmtSize;
- WAVE_FORMAT wavFormat;
- };
- struct DATA_BLOCK
- {
- TCHAR szDataID[4]; // 'd','a','t','a'
- DWORD dwDataSize;
- };
That's it. That's all you need todescribe a wave form. Of course, there a lot of optional chunks that you canhave (they should be before the data block and after the fmt block). Just as anexample, here is an optional chunk that you could use:
Note Chunk, used to store"comments" about the wave data:
- struct NOTE_CHUNK
- {
- TCHAR ID[4]; // 'note'
- long chunkSize;
- long dwIdentifier;
- TCHAR dwText[];
- };