【C/C++内存问题检测工具】 AddressSanitizer(Asan)介绍与分析
感谢原作者分享,转自:https://zhuanlan.zhihu.com/p/37515148
Google出品的内存检测工具AddressSanitizer介绍与分析
介绍
AddressSanitizer是Google旗下的一个内存问题检测工具,项目地址:https://github.com/google/sanitizers/wiki/AddressSanitizer
论文地址:https://www.usenix.org/system/files/conference/atc12/atc12-final39.pdf
https://github.com/google/sanitizers/wiki/AddressSanitizerAlgorithm
是一个C/C++的内存检测工具,可以发现的问题包括:
悬空指针
它与传统的内存问题检测工具,例如 Valgrind ,有何区别?
用过 Valgrind 的朋友应该都清楚,其会极大的降低程序运行速度,大约降低10倍,而 AddressSanitizer 大约只降低2倍,这是什么概念,果然是Google大法好!
具体使用
在LLVM及高版本编译器中已经自带了该工具,编译时添加 -fsanitize=address 选项。
正常运行程序,如有内存相关问题,即会打印异常信息。
工具原理
工具用法比较简单,这里想重点说说该工具的原理。
可参考文档:https://github.com/google/sanitizers/wiki/AddressSanitizerAlgorithm
由于是内存检测工具,其需要对每一次内存读写操作进行检查:*address = ...; // or: ... = *address;
进行如下的逻辑判断:
if (IsPoisoned(address)) {
ReportError(address, kAccessSize, kIsWrite);
}
*address = ...; // or: ... = *address;
如果指针读写异常,则统计及打印异常信息,可见整个工具的关键在于 IsPoisoned 如何实现,该函数需要快速而且准确。
内存映射
其将内存分为两块:
主内存:程序常规使用
影子内存:记录主内存是否可用等meta信息
如果有个函数 MemToShadow 可以根据主内存地址获取到对应的影子内存地址,那么内存检测的实现,可以改写为:
shadow_address = MemToShadow(address);
if (ShadowIsPoisoned(shadow_address)) {
ReportError(address, kAccessSize, kIsWrite);
}
影子内存
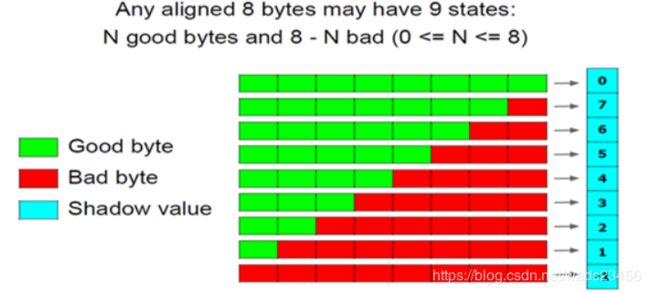
AddressSanitizer 用 1 byte 的影子内存,记录主内存中 8 bytes 的数据。
为什么是 8 bytes ,因为malloc分配内存是按照 8 bytes 对齐。
这样,8 bytes 的主内存,共构成 9 种不同情况:
- 8 bytes 的数据可读写,影子内存中的value值为 0
- 8 bytes 的数据不可读写,影子内存中的value值为 负数
- 前 k bytes 可读写,后 (8 - k) bytes 不可读写,影子内存中的value值为 k 。
如果 malloc(13) ,根据 8 bytes 字节对齐的原则,需要 2 bytes 的影子内存,第一个byte的值为 0,第二个byte的值为 5。
这时,整个判断流程,可改写为:
byte *shadow_address = MemToShadow(address);
byte shadow_value = *shadow_address;
if (shadow_value) {
if (SlowPathCheck(shadow_value, address, kAccessSize)) {
ReportError(address, kAccessSize, kIsWrite);
}
}
// Check the cases where we access first k bytes of the qword
// and these k bytes are unpoisoned.
bool SlowPathCheck(shadow_value, address, kAccessSize) {
last_accessed_byte = (address & 7) + kAccessSize - 1;
return (last_accessed_byte >= shadow_value);
}
主内存映射到影子内存
进程的虚拟内存空间被ASAN划分为2个独立的部分:
a) 主应用内存区 (Mem): 普通APP代码内存使用区。
b) 影子内存区 (Shadow): 该内存区仅ASAN感知,影子顾名思义是指该内存区与主应用内存区存在一种类似“影子”的对应关系。ASAN在将主内存区的一个字节标记为“中毒”状态时,也会在对应的影子内存区写一个特殊值,该值称为“影子值”。
这两个内存区需要精心划分,确保可以快速从主应用内存区映射到影子内存区(MemToShadow),ASAN将8字节的主应用区内存映射为1字节的影子区内存,如下图:
MemToShadow 采用简单直接映射的方式
64-bit Shadow = (Mem >> 3) + 0x7fff8000;
32-bit Shadow = (Mem >> 3) + 0x20000000;
例子
如何检测数组访问越界:
void foo() {
char a[8];
...
return;
}
AddressSanitizer 将其改写为:
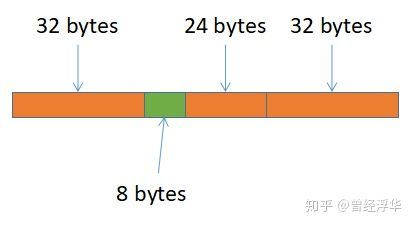
void foo() {
char redzone1[32]; // 32-byte aligned
char a[8]; // 32-byte aligned
char redzone2[24];
char redzone3[32]; // 32-byte aligned
int *shadow_base = MemToShadow(redzone1);
shadow_base[0] = 0xffffffff; // poison redzone1
shadow_base[1] = 0xffffff00; // poison redzone2, unpoison 'a'
shadow_base[2] = 0xffffffff; // poison redzone3
...
shadow_base[0] = shadow_base[1] = shadow_base[2] = 0; // unpoison all
return;
}
如图:
将 char a[8] 两侧用 redzone 包夹,这样数组访问越界时,立马能够侦测。
原理
ASAN的原理是影子内存、编译插桩和替换运行库,这里介绍其基本思想,有兴趣可以了解原论文(篇幅不长),见附件。
影子内存(Shadow Memory)
Malloc分配的地址一般是至少按照8bytes对齐的,因此ASAN设计一种8:1的投影关系:每8bytes的内存对应1byte的影子内存,即在进程的内存中,约1/8的内存用作影子内存,其他内存才是编译器分配给程序使用的,如图1。一个内存地址可以通过偏移量获取对应的影子地址,如ShadowAddr = (Addr >> 3) + Offset。
8bytes存在9状态(0 <= k <= 8),即前k个字节是可寻址的而后8 – k个字节是不可寻址的,这个状态可以编码进对应1byte的影子内存中,而明显1byte还有足够的可编码空间(还有256 – 9余量),如1byte的值为负数时表示8bytes是不可寻址且不同负数值表示不同的不可寻址类型(如已经释放内存、已退栈的局部变量等)。
图1 内存投影
如当操作一个4字节内存区时,地址为Addr,编译器实际会在编译时插入类似这样的一段代码指令:
ShadowAddr = (Addr >> 3) + Offset;
if (*ShadowAddr != 4)
ReportAndCrash(Addr);
ReportAndCrash可以是一个函数或者一个硬件中断。值得一提的时,编译插桩是安排在编译的最后阶段,意味着这阶段的代码已经是优化后的,有些潜在的内存问题会因为优化而发现不了(关闭编译器优化)。
3 替换运行库(Run-time Library)
加上地址消毒选项的编译器会将默认的运行库(如glibc)替换为ASAN版本的运行库,运行库主要用于管理影子内存,另外是替换了malloc和free等内存管理相关的函数,用于堆内存的监控。
Malloc每分配一块内存,运行库实际上会多分配一些区域(红区,redZone),n块内存存在n + 1个红区,如图2。
图2 redZone
这些红区用于malloc保存内部数据,如线程ID、内存块大小等信息,因此每块红区设计最小为32bytes。这些红区已经被“下毒”了,即红区对应的影子内存的byte都写为负数状态,应用程序代码一旦踩到红区的内存会报错。
当free一块内存时,这整块内存都会被“下毒”,且这个内存放在一个“隔离区”,未来一段时间内该内存不会再被malloc分配出去。目前该隔离区实现为一个FIFO,具有一个固定的总内存大小。
运行时库主要提供malloc/free等内存申请释放操作,动态加载后,会接管应用程序中的malloc/free等操作,malloc时会在应用程序分配内存前后增加redzone内存(成为红区)标记为“中毒”状态,而释放的内存则会被隔离起来(暂时不会分配出去)且也会被标记为“中毒”状态,后续如果访问中毒位置,则会被认为是越界访问;
5 漏报
存在以下几种情况,ASAN会检测不出来而漏报:
(1)不对齐寻址
int *a = new int[2]; // 8-aligned
int *u = (int*)((char*)a + 6);
*u = 1; // Access to range [6-9]
对于上述代码,由于ASAN的8:1地址投影特性,地址a + 1和地址u的影子地址是一样的,而a + 1是可寻址4字节的,因此即使u溢出了2字节也检测不出来。
(2)越界太离谱
由于红区的大小有限(一般为128bytes),访问越界太离谱而跨过红区而踩到别的有效内存,这种情况会漏报。
(3)隔离区溢出
ASAN运行库的内存隔离区(FIFO)大小有限,如256M,无法记录所有的已释放内存(太旧的、太大的),在操作已释放内存时,可能漏报,如以下代码:
char *a = new char[1 << 20]; // 1MB
delete [] a; // <<< "free"
char *b = new char[1 << 28]; // 256MB
delete [] b; // drains the quarantine queue
char *c = new char[1 << 20]; // 1MB
a[0] = 0; // "use". May land in ’c’
(4)类/结构体内部(PODs)
避免破环结构体内存布局的向下兼容性,类和结构体内部的成员变量之间不设红区,因此结构体内变量的溢出将不会被检测到,该问题在gcc的4.8版本有效,不知其他版本有没解决优化。如以下代码:
struct S { char a[4]; int b; }
S s;
s.a[5] = 0;
(5)其他
对于memcpy的dest和src是在同一个malloc的内存块中时,内存重叠的情况无法检测到。
对于有些use-after-return,如访问已经退栈的内存,不能检测。
无法发现“操作未初始化”的问题,不过这个编译器原本就可以检测。
一些显而易见的访问无效内存操作可能会被编译器优化而会漏报。