文本识别 使用 Tesseract 进行 OpenCV OCR 和 文本识别
原文链接 文本识别 使用 Tesseract 进行 OpenCV OCR 和 文本识别
在 2019年7月18日 上张贴 由 hotdog发表回复
文本识别 用 Tesseract 进行 OpenCV OCR 和 文本识
在本教程中,您将学习如何应用OpenCV OCR(光学字符识别)。我们将使用OpenCV,Python和Tesseract 执行(1)文本检测 和(2)文本识别 。
几周前,我向您展示了如何使用OpenCV的EAST深度学习模型进行文本检测。使用此模型,我们能够检测并本地化图像中包含的文本的边界框坐标。
下一步是采用包含文本的每个区域,并使用OpenCV和Tesseract实际识别和OCR文本。
要了解如何构建自己的OpenCV OCR和 文本识别 系统,请继续阅读!
寻找这篇文章的源代码?
跳到下载部分。
使用Tesseract进行OpenCV OCR和 文本识别
为了执行OpenCV OCR文本识别,我们首先需要安装Tesseract v4,其中包括一个高度准确的基于深度学习的文本识别模型。
从那里,我将向您展示如何编写以下Python脚本:
- 使用OpenCV的EAST文本检测器执行文本检测,这是一种高度精确的深度学习文本检测器,用于检测自然场景图像中的文本。
- 一旦我们用OpenCV 检测到文本区域,我们就会提取每个文本ROI并将它们传递给Tesseract,使我们能够构建一个完整的OpenCV OCR管道!
最后,我将通过向您展示使用OpenCV应用 文本识别 的一些示例结果以及讨论该方法的一些限制和缺点来结束今天的教程。
让我们继续开始使用OpenCV OCR吧!
如何安装Tesseract 4

Tesseract是一种非常受欢迎的OCR引擎,最初由Hewlett Packard在20世纪80年代开发,然后于2005年开源。谷歌于2006年采用该项目,并一直赞助它。
如果您已经阅读过我之前关于使用Tesseract OCR和Python的帖子,您就会知道Tesseract在受控条件下可以很好地工作……
…但如果在应用Tesseract之前有大量噪音或图像没有经过适当的预处理和清洁,表现会很差。
正如深度学习几乎影响了计算机视觉的每个方面一样,字符识别和手写识别也是如此。
基于深度学习的模型已经设法获得前所未有的 文本识别 准确性,远远超出传统的特征提取和机器学习方法。
Tesseract采用深度学习模型来进一步提高OCR准确度只是时间问题 – 实际上,时机已到。
Tesseract (V4)的最新版本支持深学习型OCR是显著更准确。
底层OCR引擎本身使用长短期记忆(LSTM)网络,一种回归神经网络(RNN)。
在本节的其余部分中,您将学习如何在计算机上安装Tesseract v4。
在本博文后面,您将学习如何在单个Python脚本中将OpenCV的EAST文本检测算法与Tesseract v4相结合,以自动执行OpenCV OCR。
让我们开始配置您的机器!
安装OpenCV
要运行今天的脚本,您需要安装OpenCV。需要3.4.2或更高版本。
要在您的系统上安装OpenCV,只需按照我的一个OpenCV安装指南,确保您在此过程中下载正确/所需版本的OpenCV和OpenCV-contrib。
在Ubuntu上安装Tesseract 4
用于在Ubuntu上安装Tesseract 4的确切命令将根据您使用的是Ubuntu 18.04还是Ubuntu 17.04及更早版本而有所不同。
要检查您的Ubuntu版本,您可以使用 lsb_release 命令$ lsb_release -a对于Ubuntu 18.04用户,Tesseract 4是主要apt-get存储库的一部分,通过以下命令可以非常轻松地安装Tesseract$ sudo apt install tesseract-ocr如果您正在使用Ubuntu 14,16或17,则由于依赖性要求,您将需要一些额外的命令。
好消息是Alexander Pozdnyakov 为Tesseract创建了一个Ubuntu PPA(个人包存档),这使得在旧版本的Ubuntu上安装Tesseract 4非常容易。
只需将 alex – p / tesseract – ocr PPA存储库添加到您的系统,更新您的包定义,然后安装Tesseract$ sudo add-apt-repository ppa:alex-p/tesseract-ocr$ sudo apt-get update$ sudo apt install tesseract-ocr假设没有错误,您现在应该在您的计算机上安装Tesseract 4。
在macOS上安装Tesseract 4
如果您的系统上安装了Homebrew,macOS’“非官方”软件包管理器,那么在macOS上安装Tesseract非常简单。
只要运行下面的命令,确保指定 – HEAD 参数,Tesseract V4将您的Mac上安装:$ brew install tesseract --HEAD如果您已经在Mac上安装了Tesseract(例如,如果您按照我以前的Tesseract安装教程),您首先要取消原始安装的链接$ brew unlink tesseract从那里你可以运行install命令。
验证您的Tesseract版本
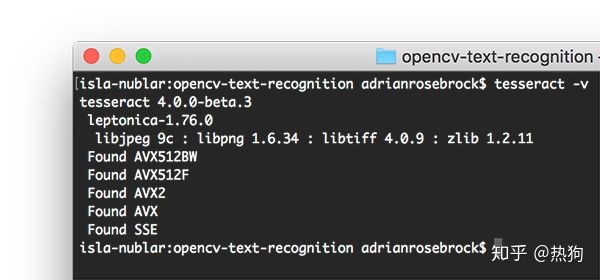
在计算机上安装Tesseract后,应执行以下命令以验证Tesseract版本$ tesseract -v安装Tesseract + Python绑定
现在我们已经安装了Tesseract二进制文件,现在我们需要安装Tesseract + Python绑定,这样我们的Python脚本就可以与Tesseract进行通信,并对OpenCV处理的图像执行OCR。
如果您使用的是Python虚拟环境(我强烈建议您使用独立的独立Python环境),请使用 workon 命令访问您的虚拟环境$ workon cv从那里,我们将使用pip来安装Pillow,一个更适合Python的PIL版本,然后是 pytesseract 和 imutils :OpenCV OCR and text recognition with TesseractShell
在这种情况下,我正在访问名为cv (“计算机视觉”的缩写)的Python虚拟环境 – 您可以将cv替换 为您命名为虚拟环境的任何内容。$ pip install pillow$ pip install pytesseract$ pip install imutils现在打开一个Python shell并确认您可以导入OpenCV和 pytesseract
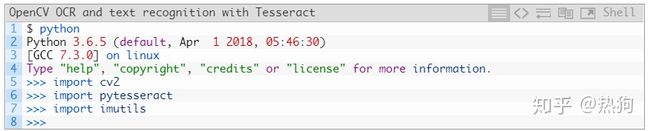
Congratulations!
如果您没有看到任何导入错误,您的计算机现在配置为使用OpenCV执行OCR和文本识别
让我们继续下一节(跳过Pi指令),我们将学习如何实际实现Python脚本来执行OpenCV OCR。
在 树莓派 Raspberry Pi和Raspbian上安装Tesseract 4和支持软件
注意: 如果您不在Raspberry Pi上,可以跳过本节。
不可避免地,我会被问到如何在Rasberry Pi上安装Tesseract 4。
以下说明不适合胆小的人 – 您可能会遇到问题。它们经过测试,但里程可能因您自己的Raspberry Pi而异。
首先,从系统站点包卸载OpenCV绑定$ sudo rm /usr/local/lib/python3.5/site-packages/cv2.so 从我的cv2开始,我在这里使用了 rm命令 。所以 在site中的文件 – 包 只是一个sym-link。如果是 cv2 。所以 绑定是你 真正的OpenCV绑定,那么你可能想要将文件移出 站点- 包 安全保存。
现在在您的系统上安装两个QT包$ sudo apt-get install libqtgui4 libqt4-test然后,通过Thortex的GitHub安装tesseract$ cd ~$ git clone https://github.com/thortex/rpi3-tesseract$ cd rpi3-tesseract/release$ ./install_requires_related2leptonica.sh$ ./install_requires_related2tesseract.sh$ ./install_tesseract.sh无论出于何种原因,安装中缺少经过培训的英语语言数据文件,因此我需要下载并将其移动到正确的目录中$ cd ~$ wget https://github.com/tesseract-ocr/tessdata/raw/master/eng.traineddata$ sudo mv -v eng.traineddata /usr/local/share/tessdata/从那里,创建一个新的Python虚拟环境$ mkvirtualenv cv_tesseract -p python3并安装必要的包$ workon cv_tesseract$ pip install opencv-contrib-python imutils pytesseract pillow你完成了!请记住,您的体验可能会有所不同。
了解OpenCV OCR和Tesseract文本识别
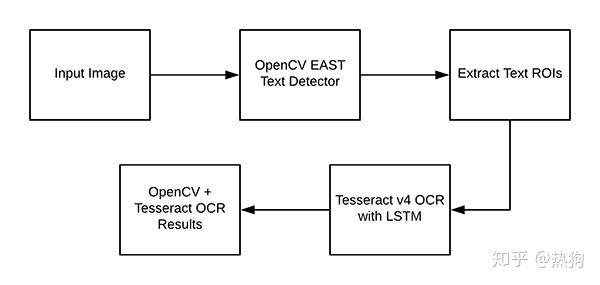
现在我们已经在我们的系统上成功安装了OpenCV和Tesseract,我们需要简要回顾一下我们的管道和相关命令。
首先,我们将应用OpenCV的EAST文本检测器 来检测图像中是否存在文本。EAST文本检测器将为我们提供文本ROI 的边界框(x,y) –坐标。
我们将提取每个ROI,然后将它们传递给Tesseract v4的LSTM深度学习文本识别算法。
LSTM的输出将为我们提供实际的OCR结果。
最后,我们将在输出图像上绘制OpenCV OCR结果。
但在我们实际进入项目之前,让我们简要回顾一下Tesseract命令(将由pytesseract 库在引擎盖下 调用)。
在调用 tessarct 二进制文件时,我们需要提供许多标志。最重要的三个是 – l , – oem 和 – psm 。
本 – l 标志控制输入文本的语言。我们将在 此示例中使用 eng(英语),但您可以在此处查看Tesseract支持的所有语言。(支持中文)
的 – OEM 参数,或者OCR引擎模式,控制由超正方体使用的算法的类型。
您可以通过执行以下命令来查看可用的OCR引擎模式

我们将使用–oem 1表示我们只希望使用深度学习LSTM引擎。
最后一个重要标志, – psm 控制Tesseract使用的自动页面分割模式
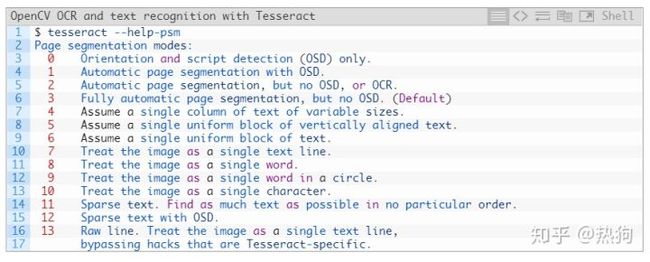
对于OCR的文本ROI,我发现模式6和7运行良好,但如果你是OCR的大块文本,那么你可能想尝试3,默认模式
每当您发现自己获得不正确的OCR结果时,我强烈建议您调整 – psm, 因为它会对您的输出OCR结果产生巨大影响。
项目结构
请务必从博客文章的“下载”部分获取zip 。
从那里解压缩文件并导航到目录。该 树 命令让我们看到在我们的终端目录结构
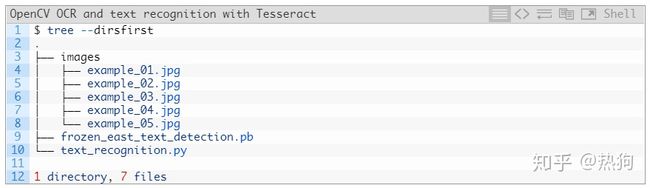
我们的项目包含一个目录和两个值得注意的文件:
- images / :包含六个包含场景文本的测试图像的目录。我们将尝试使用这些图像中的每一个OpenCV OCR。
- frozen_east_text_detection .pb :EAST文本检测器。CNN经过预先培训,可以进行文本检测并准备就绪。我没有训练这个模型 – 它提供OpenCV; 为方便起见,我还将其包含在 “下载”中。
- text_recognition .py :我们的OCR脚本 – 我们将逐行查看此脚本。该脚本利用EAST文本检测器查找图像中的文本区域,然后利用Tesseract v4进行识别。
实现我们的OpenCV OCR算法
我们现在准备用OpenCV进行文本识别!
打开 text_recognition .py 1

今天的OCR脚本需要五个导入,其中一个内置在OpenCV中。
最值得注意的是,我们将使用 pytesseract 和OpenCV。我的 imutils 包将用于非最大值抑制,因为OpenCV的 NMSBoxes 函数似乎不能与Python API一起使用。我还会注意到NumPy是OpenCV的依赖项。
该 argparse 包包括在Python和处理命令行参数-没有什么可以安装。
既然已经完成了我们的导入,那么让我们实现 decode_predictions 函数:

所述 decode_predictions 功能开始于第8行,并且 explained in detail inside the EAST text detection post. 功能:
- 使用基于深度学习的文本检测器来检测(不识别)图像中的文本区域。
- 文本检测器生成两个数组,一个包含给定区域包含文本的概率,另一个包含将分数映射到输入图像中的边界框位置。
正如我们在OpenCV OCR管道中看到的那样,EAST文本检测器模型将产生两个变量:
- scores :正文本区域的概率。
- geometry :文本区域的边界框。
…每个都是decode_predictions 函数的参数 。
该函数处理此输入数据,从而生成一个元组,其中包含(1)文本的边界框位置和(2)包含文本的区域的相应概率:
- rects :这个值基于 几何, 并且是一个更紧凑的形式,因此我们以后可以应用NMS。
- confidences 置信度 :此列表中的置信度值对应于 rects中的每个矩形 。
这两个值都由函数返回。
注意:理想情况下,旋转的边界框将包含在 rects中 ,但为今天的概念证明提取旋转的边界框并不是很简单。相反,我已经计算了水平边界矩形,它考虑了 角度 。如果要提取单词的旋转边界框以传递到Tesseract, 则可在第41行上使用 该 角度。
有关上述代码块的更多详细信息,请参阅此博客文章。
从那里让我们解析我们的命令行参数
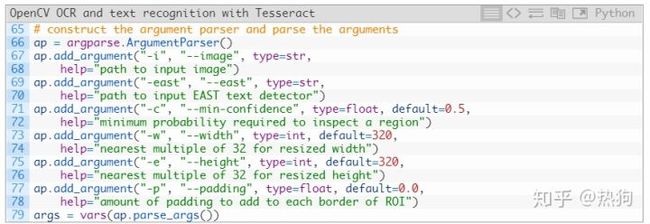
我们的脚本 需要两个命令行参数:
- –image : 输入图像的路径。
- – east :预训练EAST文本检测器的路径。
(可选)可以提供以下命令行参数:
- – min – confidence :检测到的文本区域的最小概率。
- – width :我们的图像在通过EAST文本检测器之前将调整大小的宽度。我们的探测器需要32的倍数。
- – height :与宽度相同。同样,我们的探测器要求 调整高度为 32的倍数 。
- – padding :添加到每个ROI边界的(可选)填充量。 如果您发现OCR结果不正确,您可以尝试0.05 5%或 0.10 ,10%(依此类推)。
从那里,我们将加载+预处理我们的图像并初始化关键变量
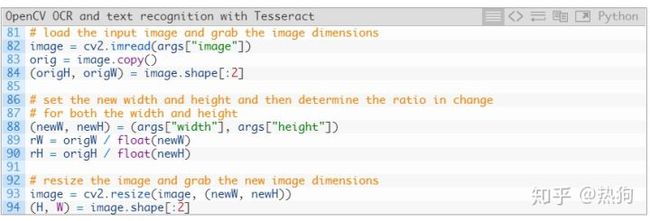
我们的 图像 被加载到内存中并被复制(因此我们可以稍后在第82和83行上绘制输出结果)。
我们抓住原始的 宽度和高度(第84行),然后 从args 字典中提取新的宽度和高度 (第88行)。
使用原始维度和新维度,我们计算用于稍后在脚本中缩放我们的边界框坐标的比率(第89和90行)。
然后调整我们的 图像大小, 忽略纵横比(第93行)。
接下来,让我们使用EAST文本检测器
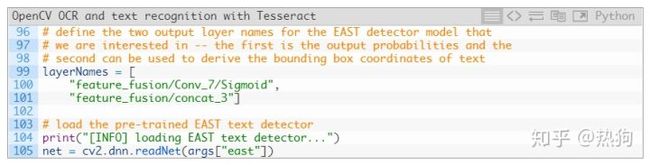
我们的两个输出图层名称放在第99-101行的列表表单中 。要了解为什么这两个输出名称很重要,您需要参考我原来的EAST文本检测教程。
然后,我们预先训练的EAST神经网络被加载到存储器中(第105行)。
我不能强调这一点:你至少需要OpenCV 3.4.2来拥有 cv2 。dnn 。readNet 实现。
接下来发生了第一个“魔术”:
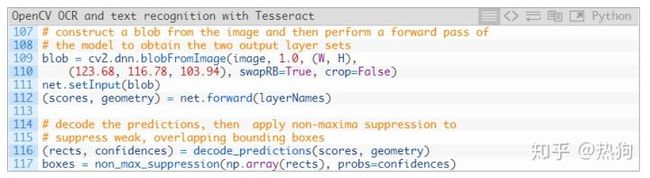
要确定文本位置,我们:
- 在 第109行和第110行构造一个 blob。了解更多关于该过程在这里。
- 将斑点传递 通过神经网络,获得 scores 和 geometry (第111和112行)。
- 使用先前定义的decode_predictions 函数解码预测 (第116行)。
- 通过我的imutils方法应用非最大值抑制(第117行)。NMS有效地采用最可能的文本区域,消除了其他重叠区域。
现在我们知道了文本区域的位置,我们需要采取措施来 识别文本!我们开始遍历边界框并处理结果,为实际文本识别做好准备
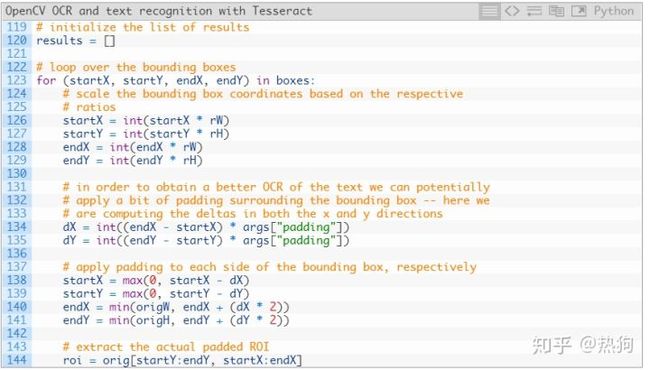
我们初始化 result列表以包含我们在第120行的 OCR边界框和文本。
然后我们开始循环 框 (第123行),我们在这里:
- 根据先前计算的比率(第126-129行)缩放边界框。
- 填充边界框(第134-141行)。
- 最后,提取填充的 roi (144行)。
我们的OpenCV OCR管道可以使用一些Tesseract v4“magic”来完成
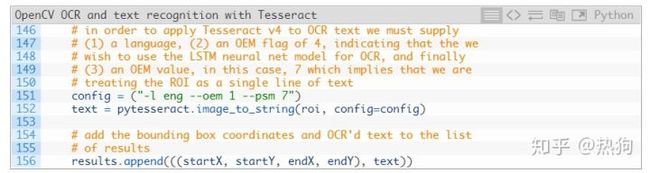
记下代码块中的注释,我们 在第151行设置了Tesseract 配置参数 (英语,LSTM神经网络和单文本)。
注意: 您可能需要配置 – PSM 使用本教程顶我的指示值,如果你发现自己得到不正确的OCR结果。
该 pytesseract 库需要照顾其余的 152行,我们称之为 pytesseract 。image_to_string ,传递我们的 roi 和 配置字符串 。
在两行代码中,您使用Tesseract v4识别图像中的文本ROI。请记住, 引擎盖下有很多事情发生。
我们的结果(边界框值和实际 文本 字符串)将附加到 结果 列表(第156行)。
然后我们继续在循环顶部的其他ROI进行此过程。
现在让我们显示/打印结果,看看它是否真的有效

基于边界框的y坐标,我们的结果 在第159行从上到下 排序(尽管您可能希望对它们进行不同的排序)。
从那里,循环 result,我们:
- 将OCR的文本打印 到终端(第164-166行)。
- 从文本中删除非ASCII字符, 因为OpenCV不支持cv2中的非ASCII字符 。putText 函数(第171行)。
- 绘制(1)围绕ROI的边界框和(2) ROI上方的结果 文本(第173-176行)。
- 显示输出并等待按下任何键(第179和180行)。
OpenCV文本识别结果
现在我们已经实现了OpenCV OCR管道,让我们看看它的实际应用。
请务必使用此博客文章的“下载”部分下载源代码,OpenCV EAST文本检测器模型和示例图像。
从那里,打开命令行,导航到您下载的位置+解压缩zip,然后执行以下命令:$ python text_recognition.py --east frozen_east_text_detection.pb \ --image images/example_01.jpg
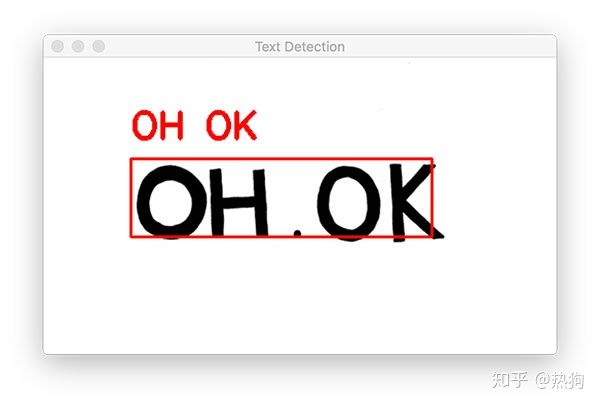
我们从一个简单的例子开始。
请注意我们的OpenCV OCR系统如何能够正确地(1)检测图像中的文本,然后(2)识别文本。
下一个示例更能代表我们在实际图像中看到的文本$ python text_recognition.py --east frozen_east_text_detection.pb \ --image images/example_02.jpg

再次,请注意我们的OpenCV OCR管道如何能够正确地本地化和识别文本; 然而,在我们的终端输出中,我们看到一个注册商标Unicode符号–Thisseract可能在这里被混淆,因为OpenCV的EAST文本检测器报告的边界框流入标志后面的草地灌木/植物。
让我们看看另一个OpenCV OCR和文本识别示例$ python text_recognition.py --east frozen_east_text_detection.pb \ --image images/example_03.jpg

在这种情况下,有三个单独的文本区域。
OpenCV的文本检测器能够对每个文本检测器进行本地化 – 然后我们应用OCR来正确识别每个文本区域。
我们的下一个示例显示了在某些情况下添加填充的重要性$ python text_recognition.py --east frozen_east_text_detection.pb \ --image images/example_04.jpg

在OCR’这个烘焙店店面的第一次尝试中,我们看到“SHOP”是正确的OCR,但是:
- “CAPUTO”中的“U”被错误地识别为“TI”。
- “CAPUTO’S”中缺少撇号和“S”。
- 最后,“BAKE”被错误地识别为带有句点(“。”)的竖线/竖线(“|”)。
通过添加一些填充,我们可以扩展ROI的边界框坐标并正确识别文本$ python text_recognition.py --east frozen_east_text_detection.pb \ --image images/example_04.jpg --padding 0.05

只需在边界框的每个角落添加5%的填充,我们不仅能够正确地OCR“BAKE”文本,而且我们还能够识别“CAPUTO”中的“U”和“S”。
当然,有一些OpenCV扁平化失败的例子$ python text_recognition.py --east frozen_east_text_detection.pb \ --image images/example_05.jpg --padding 0.25
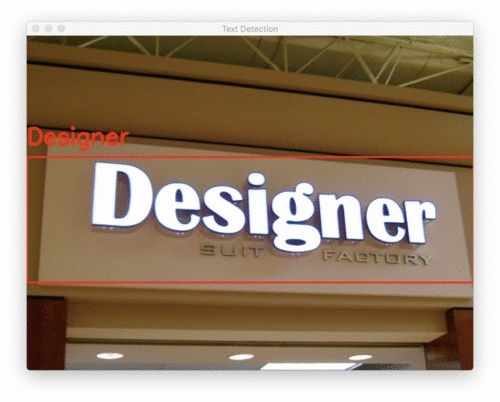
我将填充增加到25%以适应此符号中单词的角度/透视。这允许“Designer”与EAST和Tesseract v4正确地进行OCR。但较小的单词可能是由于字母与背景的颜色相似而导致丢失的原因。
在这些情况下,我们无能为力,但我建议您参考下面的限制和缺陷部分,了解如何在遇到错误的OCR结果时改进OpenCV文本识别管道。
限制和缺点
重要的是要了解没有OCR系统是完美的!
没有完美的OCR引擎,特别是在现实条件下。
此外,期望100%准确的光学字符识别是不切实际的。
我们发现,我们的OpenCV OCR系统在某些图像中运行良好,但在其他图像中却失败了。
我们将看到文本识别管道失败的主要原因有两个:
- 文本倾斜/旋转。
- 文本本身的字体与Tesseract模型训练的内容不同。
尽管Tesseract v4比Tesseract v3强大且准确,但深度学习模型仍然受到训练数据的限制 – 如果您的文本包含Tesseract未经过训练的装饰字体或字体,则Tesseract不太可能能够OCR文本。
其次,请记住,Tesseract 仍假定您的输入图像/ ROI已相对清理。
由于我们在自然场景图像中执行文本检测,因此这种假设并不总是成立。
一般情况下,您会发现我们的OpenCV OCR管道最适用于(1)以90度角(即自上而下,鸟瞰图)捕获图像的文本,以及(2)相对容易从背景细分。
如果不是这种情况,您可以应用透视变换来更正视图,但请记住,今天查看的Python + EAST文本检测器不提供旋转边界框(如我之前的帖子中所述),所以你仍然可能有点受限。
Tesseract将始终使用干净的预处理图像,因此在构建OpenCV OCR管道时请记住这一点。
如果您需要更高的准确度,并且您的系统将具有互联网连接,我建议您尝试使用“大3”计算机视觉API服务之一:
- Google Vision API OCR引擎
- 亚马逊Rekognition
- Microsoft认知服务
…每个都使用在云中的强大机器上运行的更高级的OCR方法。
摘要
在今天的教程中,您学习了如何应用OpenCV OCR来执行以下两项操作:
- 文字检测
- 文字识别
为完成这项任务,我们:
- 利用OpenCV的EAST文本检测器,使我们能够应用深度学习来定位图像中的文本区域
- 从那里,我们提取每个文本ROI,然后使用OpenCV和Tesseract v4应用文本识别。
我们还研究了Python代码,以便在单个脚本中执行文本检测和文本识别。
我们的OpenCV OCR管道在某些情况下运行良好,但在其他情况下也失败了。为了获得最佳的OpenCV文本识别结果,我建议您确保:
- 您的输入ROI将尽可能地进行清理和预处理。在理想的世界中,您的文本将与图像的其余部分完美地分割,但实际上,这并非总是可行的。
- 您的文字是从相机以90度角拍摄的,类似于自上而下的鸟瞰图。如果不是这种情况,透视变换可以帮助您获得更好的结果。
我希望你喜欢今天关于OpenCV OCR和文本识别的博客文章
原文链接
文本识别 使用 Tesseract 进行 OpenCV OCR 和 文本识别hotdog29.com
代码下载
源代码下载
文章转自 Adrian Rosebrock ,OpenCV Face Recognition,PyImageSearch,https://www.pyimagesearch.com/OpenCV OCR and text recognition with Tesseract/,2009年7月18日访问
相关文章
- 源代码 下载
- 文本检测 OpenCV EAST文本检测器 源代码
- YOLO 对象检测 OpenCV 源代码
- dlib 使用OpenCV,Python和深度学习进行人脸识别 源代码
- OpenCV 人脸识别 源代码
张贴在new、技术博客、opencv标签:opencv、深度学习、文本识别、Tesseract、OCR编辑