用于深度学习的演化神经AutoML
ABSTRACT
深度神经网络(DNN)已经在许多基准测试和问题领域中产生了最先进的结果。然而,DNN的成功取决于其ar-chitecture和超参数的正确配置。这种配置很困难,因此,DNN通常不会充分发挥其潜力。此外,商业应用中的DNN通常需要满足现实世界的设计约束,例如参数的大小或数量。为了简化配置,我们开发了用于深度学习的自动机器学习(AutoML)系统,主要侧重于超参数的优化。
本文将AutoML向前推进了一步。它引入了一个名为LEAF的渐进式AutoML框架,它不仅可以优化超参数,还可以优化网络架构和网络规模。 LEAF利用最先进的进化算法(EA)和分布式计算框架。医学图像分类和自然语言分析的实验结果表明,该框架可用于实现最先进的性能。特别是,LEAF表明架构优化提供了超级参数优化的显着提升,并且可以同时最小化网络,同时性能几乎没有下降。因此,LEAF为民主化和改进人工智能奠定了基础,并使AI在未来的应用中具有实用性。
1 INTRODUCTION
最近,由于计算能力和数据质量的提高,机器学习和人工智能的应用显着增加。特别是,深度神经网络(DNN)学习了高维数据的丰富表示,超越了计算机视觉,自然语言处理,强化学习和语音识别等各种基准测试中的最新技术水平。这种最先进的DNN非常庞大,由数亿个参数组成,需要大量的计算资源来训练和运行。它们也非常复杂,它们的性能取决于它们的架构和超参数的选择。
最近深度学习的大部分研究确实侧重于发现在特定任务中表现优异的专业架构。 DNN架构之间存在很大差异(即使对于单任务域),到目前为止,没有指导它们之间的指导原则。找到正确的架构和超参数基本上简化为黑盒优化过程。但是,手动测试和评估是一个繁琐且耗时的过程,需要经验和专业知识。架构和超参数通常是根据历史和便利而不是理论或经验原则来选择的,因此,网络的表现并不尽如人意。因此,DNN的自动配置是一种引人注目的方法,原因有三:(1)找到性能良好的DNN的创新配置,(2)找到足够小的实用配置,以及(3)制作没有领域专业知识就可以找到它们。
目前,满足第一个目标的最常见方法是通过部分优化。作者可能会调整一些高参数或在几个固定架构之间切换,但很少同时优化架构和超参数。这种方法是可以理解的,因为搜索空间很大并且现有方法不会随着超参数的数量和架构复杂性的增加而扩展。用于超参数优化的标准和最广泛使用的方法是网格搜索,其中超参数被离散化为固定数量的间隔,并且穷举搜索所有组合。通过使用这些超参数训练DNN并根据基准数据集上的度量评估其性能来测试每个组合。虽然这种方法很简单并且可以很容易地并行化,但是它的计算复杂性与超参数的数量成组合,并且一旦超参数的数量超过四或五,就变得难以处理。网格搜索也没有解决DNN的最佳架构应该是什么的问题,这可能与超参数的选择同样重要。需要一种可以优化结构和参数的方法。
最近,深度学习的商业应用变得越来越重要,并且其中许多应用于智能手机。不幸的是,在大多数智能手机中,数以亿计的现代DNN不能适应几千兆字节的RAM。因此,DNN优化的一个重要的第二个目标是最小化网络的复杂性或大小,同时最大化其性能[25]。因此,需要一种用于优化多个目标的方法来满足第二目标。
为了实现第三个目标,即民主化AI,已经开发出用于自动化DNN配置的系统,例如Google AutoML [1]和Yelp的度量优化引擎(MOE [5],也作为名为SigOpt [8]的产品商业化) 。然而,现有系统通常在它们解决的问题的范围和它们向用户提供的反馈中受到限制。例如,Google AutoML系统是一个黑盒子,它隐藏了用户的网络架构和培训;它只提供一个API,用户可以使用该API查询新输入。另一方面,MOE更透明,但由于它在下面使用贝叶斯优化算法,它只调整DNN的超参数。这两种系统都不能最小化网络的大小或复杂性。
本文的主要贡献是一个名为LEAF(学习进化AI框架)的新型AutoML系统,它解决了这三个目标。 LEAF利用并扩展了现有的用于架构搜索的最先进的进化算法,称为CoDeepNEAT [35],它演变了超参数和网络结构。虽然其超参数优化能力与其他AutoML系统相匹配,但LEAF优化DNN架构的额外能力进一步使得实现最先进结果成为可能。 CoDeepNEAT中的物种形成和复杂化启发也使其可以轻松适应多目标优化,以找到最小的体系结构。 LEAF的有效性将在本文中展示两个主要问题,一个是语言:维基百科评论毒性分类(也称为Wikidetox),另一个是视觉:胸部X射线多任务图像分类。因此,LEAF为民主化,简化和改进人工智能奠定了基础。
2 BACKGROUND AND RELATED WORK
本节将回顾超参数优化和神经结构搜索中的背景和相关工作。
2.1 Hyperparameter Tuning for DNNs
正如第1节所述,最简单的超参数优化形式是穷举网格搜索,其中超大容量空间中的点以规则的间隔均匀采样[49]。直接扩展是随机搜索,其中从搜索空间随机均匀地采样点[11]。这些方法可以优化简单的DNN,但是当所有的高参数对性能至关重要并且必须调整到非常特定的值时,这些方法都是无效的。对于具有这种特征的网络,使用高斯过程[44]的贝叶斯优化是一种可行的替代方案。贝叶斯优化需要相对较少的函数评估,并且在多模态,不可分离和噪声函数上运行良好,其中存在多个局部最优。它首先创建一个最符合目标函数的函数概率分布(也称为高斯过程),然后使用该分布确定下一个样本的位置。贝叶斯优化的主要缺点是计算成本高,并且随着评估点的数量而立方体地缩放。 DNGO [45]试图通过用线性缩放贝叶斯神经网络代替高斯过程来解决这个问题。贝叶斯优化的另一个缺点是,当超参数的数量适中时,即超过10-15 [32]时,它的表现很差。
EA是另一类广泛用于复杂,多模函数的黑盒优化的算法。他们依靠生物学启发机制来迭代地改进目标函数的候选解决方案群体。已成功应用于DNN超参数调谐的一个特定EA是CMA-ES [32]。在CMA-ES中,估计群体中最佳个体的高斯分布,并用于为下一代生成/抽样群体。此外,它还具有控制步长和人口移动方向的机制。已经证明CMA-ES在许多现实世界的高维优化问题中表现良好,特别是,CMA-ES在调整卷积神经网络的参数方面表现优于贝叶斯优化[32]。然而,它仅限于持续优化,并且不会自然地扩展到架构搜索。
2.2 Architecture Search for DNNs
最近的一种方法是使用强化学习(RL)来搜索更好的架构。递归神经网络(LSTM)控制器生成一系列层,这些层从输入开始并在DNN的输出端结束[55]。 LSTM通过称为REINFORCE [51]的基于梯度的策略搜索算法进行训练。通过这种方法探索的体系结构搜索空间足以在手工设计上进行改进。在诸如CIFAR-10和ImageNet等流行的图像分类基准测试中,这种方法在最先进的技术的1-2个百分点内实现了性能,并且在语言建模基准测试中,它实现了最先进的技术。当时的表现[55]。
但是,优化网络的体系结构仍然必须具有线性或树状核心结构;任意图形拓扑都在搜索空间之外。因此,仍然由用户预先定义适当的搜索空间以使算法用作起点。可以针对每个层优化的超参数的数量也是有限的。此外,计算非常繁重;为了生成最终的最佳网络,必须对数千个候选架构进行评估和培训,这需要数十万小时的GPU时间。
架构搜索的另一个方向是进化算法(EA)。它们非常适合这个问题,因为它们是可以优化arbi-trary结构的黑盒优化算法。其中一些方法使用NEAT的修改版本[43],一种用于神经元级神经进化的[46],用于搜索网络拓扑。其他人依赖于遗传编程[47]或等级进化[31]。最近有一些关于多目标进化架构搜索的工作[18,33],其目标是优化网络的性能和训练时间/复杂性。
EA比RL方法的主要优点是它们可以在更大的搜索空间上进行优化。例如,基于NEAT [43]的方法可以为网络架构演化任意图形拓扑。最重要的是,层次化的进化方法[31]可以有效地搜索非常大的空间,并从最小的起点快速发展复杂的架构。因此,进化方法的表现达到或超过强化学习方法的表现。例如,CIFAR-10和ImageNet目前最先进的结果是通过渐进方法实现的[42]。在本文中,LEAF使用CoDeepNEAT,这是一个基于NEAT的强大EA,能够分层演化具有任意拓扑的网络。
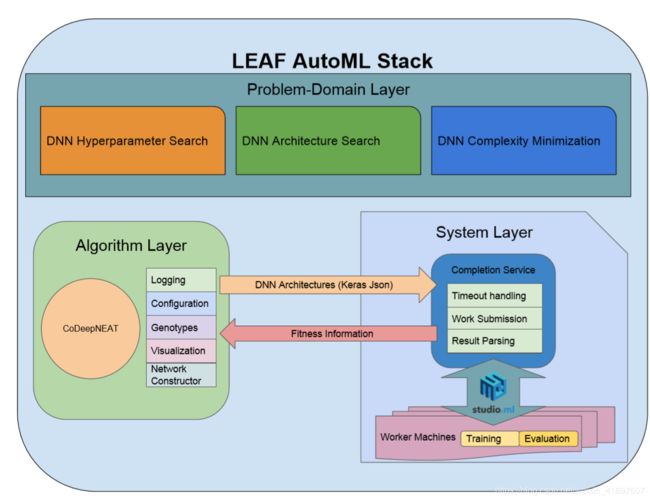
图1:LEAF及其内部子系统的可视化。 三个主要组成部分是:(1)使用CoDeepNEAT进化超参数或神经网络的算法层,(2)帮助训练和评估由算法层演化的网络的系统层,以及(3)问题域层 ,利用两个先前的层来优化DNN。 算法和系统层的解耦允许LEAF容易地应用于不同的问题类型,例如,通过多目标优化的选项和不同类型的神经网络层。
3 LEAF OVERVIEW
LEAF是一个由三个主要组件组成的AutoML系统:算法层,系统层和问题域层。 算法层允许LEAF发展DNN超参数和体系结构。 系统层将云计算基础设施(如Amazon AWS [2],Microsoft Azure [6]或Google Cloud [3])上的DNN培训并行化,这是评估算法层中演变的网络的适应性所必需的。 algo-rithm层以Keras JSON格式发送网络架构
[14]到系统层并返回健身信息。 这两个层协同工作以支持问题域层,其中LEAF解决了诸如超参数调整,架构搜索和复杂性最小化等问题。 LEAF AutomML结构概述如图1所示。
3.1 Algorithm Layer
算法层的核心由CoDeepNEAT组成,这是一种基于NEAT的协同进化算法,用于演化DNN架构和超参数[35]。 协同系数是进化计算中常用的技术,通过将更简单的组件组合在一起来发现评估期间的复杂行为。 它已在许多产品中成功使用,包括功能优化[40],捕食者 - 猎物动力学[53]和子程序优化[52]。 CoDeepNEAT中的特定协同进化机制受到分层SANE的启发
[38]但也受到ESP [20]和CoSyNE [19]的成分进化方法的影响。 这些方法与传统的神经进化不同,因为它们不会进化出整个网络。 相反,两种方法都会发展组件,然后组装成完整的网络以进行适应性评估。
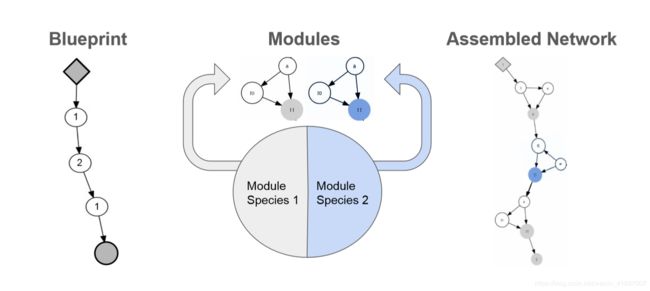
图2:CoDeepNEAT如何组装网络以进行健康评估的可视化。 通过用相应的模块替换蓝图节点,将模块和蓝图组装成网络。 这种方法允许在许多手工设计的DNN中看到不断发展的重复和深层结构。

CoDeepNEAT遵循与NEAT相同的基本过程:首先,创建最小复杂度的染色体群。每个染色体表示为图,并且也称为个体。在几代人的过程中,通过突变逐渐将结构(即节点和边缘)添加到图中。与NEAT一样,突变涉及在两个节点之间随机添加节点或连接。在交叉期间,历史标记用于确定两条染色体的基因如何排列以及如何随机交叉节点。基于相似性度量将群体划分为物种(即子群体)。每个物种与其适应性成比例地生长,并且在每个物种中分别发生进化。
CoDeepNEAT与NEAT的不同之处在于,染色体中的每个节点不再代表神经元,而是代表DNN中的一层。每个节点包含一个实数和二进制值的超级参数表,它们分别通过均匀高斯分布和随机比特翻转进行变异。这些超参数确定了层的类型(例如卷积,完全连接或重复)以及该层的属性(例如神经元的数量,内核大小和激活函数)。染色体中的边缘不再标有重量;相反,它们只是表明节点(层)是如何连接的。染色体还包含一组适用于整个网络的全局超参数(例如学习速率,训练算法和数据预处理)。
如算法1中所总结的,使用NEAT的变异和交叉算子分别进化两组模块和蓝图。蓝图染色体(也称为个体)是一个图,其中每个节点包含指向特定模块物种的指针。反过来,每个模块染色体是代表小DNN的图。在健身评估期间,组合模块和蓝图以创建大型组装网络。对于每个蓝图染色体,蓝图图中的每个节点都被从该节点指向的物种中随机选择的模块替换。如果多个蓝图节点指向相同的模块种类,则在所有这些模块中使用相同的模块。更换蓝图中的节点后,将个人转换为DNN。用于组装网络的整个过程在图2中可视化。
通过首先让网络在任务的训练数据集上学习,然后使用看不见的验证集来测量它们的性能来评估组装的网络。组装网络的适合度(即验证性能)归因于蓝图和模块,作为包含该蓝图或模块的所有组装网络的平均适合度。该方案降低了评估噪声,并允许将蓝图或模块保留到下一代,即使它们偶尔包含在性能较差的网络中。在CoDeepNEAT完成运行后,最好的进化网络将被训练直到收敛并在另一个保持测试集上进行评估。
3.2 System Layer
使用CoDeepNEAT演进DNN架构和超参数的主要挑战之一是评估网络所需的计算能力。然而,由于进化是一种并行搜索方法,因此每一代人群中的个体评估可以分布在数百台工作机器上,每台工作机器都配备有专用GPU。对于本文中描述的大多数实验,工作人员是在Microsoft Azure上运行的GPU配备的机器,Microsoft Azure是一个流行的云计算平台[6]。
为此,LEAF的系统层使用称为完成服务的API,它是名为StudioML [9]的开源软件包的一部分。首先,算法层将准备好以Keras JSON形式进行适应性评估的网络发送到系统层服务器节点。接下来,服务器节点将网络提交给完成服务。它们被推送到队列(缓冲区),每个可用的工作节点从队列中拉出一个网络进行训练。训练结束后,计算网络的适应度,并立即将信息返回给服务器。结果一次返回一个,并且没有任何订单保证通过单独的返回队列。通过使用完成服务来并行化评估,数千个候选网络在几天内被训练,从而使架构搜索易于处理。
3.3 Problem-Domain Layer
问题域层解决了前面提到的三个任务,即超参数的优化,架构和网络复杂性,使用CoDeepNEAT是一个起点。
超参数优化。 默认情况下,LEAF优化架构和超参数。 为了演示体系结构搜索的价值,可以在算法层中配置CoDeepNEAT以仅优化超参数。 在这种情况下,禁用网络结构和节点特定的高参数的突变和交叉。 仅优化每个染色体中包含的全局超参数集,如在其他超参数优化方法中的情况。

仅超参数CoDeepNEAT与传统遗传算法非常相似,因为存在精英选择,超参数经历均匀变异和交叉。 然而,它仍然具有NEAT的分配机制,通过将它们分组到子群体中来保护新的和创新的超级参数。
架构搜索。 LEAF直接利用标准CoDeepNEAT在较简单的域中执行架构搜索,例如单任务分类。 但是,LEAF也可用于搜索多任务学习(MTL)的DNN架构。 基础是软排序多任务架构[34],其中固定线性DNN的每个级别由固定数量的模块组成。 然后,这些模块在不同程度上用于不同的任务。 LEAF通过同时解决DNN [30]的模块架构和蓝图(模块之间的路由)来扩展这种MTL架构。
DNN复杂度最小化与多目标搜索。为了使CoDeepNEAT适应多项任务,LEAF还将其扩展到多个目标。在单目标进化算法中,精英主义既适用于蓝图,也适用于模块种群。如在单目标优化中,每个物种内的个体的顶部分F1被传递到下一代。该分数仅基于适合度排名。在CoDeepNEAT的多目标版本中,排名是从主要和次要目标产生的连续帕累托前锋[17,54]中计算出来的。
算法2详述了蓝图和模块的计算结果;组装网络的排名也相似。算法3示出了如何在给定已针对每个目标评估的一组个体的情况下计算排名所必需的帕累托前沿。还有一个用于多目标CoDeepNEAT的可选配置参数,允许每个帕累托前沿中的个体相对于次要目标而不是主要目标进行排序和排序。尽管主要目标即性能通常更为重要,但如果特定域必要,此参数可用于更多地强调次要目标。
因此,多目标CoDeepNEAT可用于最大化性能并同时最小化演化网络的复杂性。虽然性能通常以看不见的样本集的损失来衡量,但有很多方法可以表征DNN的复杂程度。它们包括参数的数量,浮点运算的数量(FLOPS)以及网络的训练/推理时间。最常用的度量标准是参数数量,因为其他度量标准可能会根据深度学习库实现和硬件性能而发生变化。此外,该指标在移动应用中变得越来越重要,因为移动设备在内存方面受到高度限制,并且要求网络具有尽可能高的每参数比性能。
[25]。因此,在以下部分的实验中,参数的数量被用作多目标CoDeepNEAT的次要目标。虽然参数的数量可以在不同架构之间变化很大,但是这种方差对多目标CoDeepNEAT不构成问题,因为它只关心不同目标值之间的相对排名,并且不需要缩放次要目标。
4 EXPERIMENTAL RESULTS
LEAF在人工智能化,改进现有技术和最小化解决方案方面的能力在两个困难的现实领域进行了实验验证:(1)维基百科评论毒性分类和(2)胸部X射线多任务图像分类。 LEAF的性能和效率与现有的AutoML系统进行了比较。
4.1 Wikipedia Comment Toxicity Classification Domain
维基百科是最大的百科全书之一,可在线公开获取,仅有英语语言的书面文章超过500万篇。与传统的百科全书不同,维基百科可以由注册帐户的任何用户编辑。因此,在某些文章的讨论部分中,通常会有针对其他用户的尖刻或厌恶的评论。这些评论通常被称为“有毒”,检测有毒评论并删除它们变得越来越重要。维基百科排毒数据集(Wikidetox)是160K示例评论的集合,分为93K培训,31K验证和31K测试实例[7]。评论的标签由人类使用众包方法生成,并包含四个不同类别的有毒评论。但是,按照以前的工作[15],所有毒性评论类别被组合,因此创建二进制分类问题。数据集也是不平衡的,只有大约9.6%的评论实际上被标记为有毒。
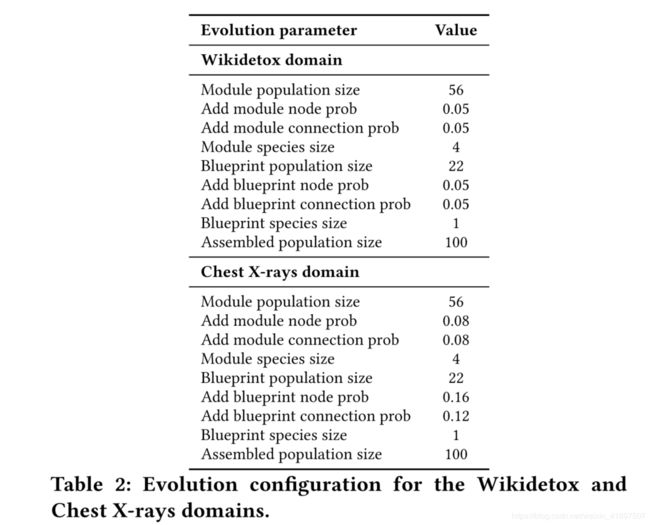
LEAF配置为使用标准CoDeepNEAT在该域中搜索性能良好的体系结构。使用循环(LSTM)层作为基本构建块来定义这些体系结构的搜索空间。由于注释本质上是一个有序的单词列表,因此复发层(已被证明在处理顺序数据[36]时有效)是一种自然的选择。为了将单词作为输入提供给循环网络,必须首先将它们转换为适当的向量表示。在作为网络输入之前,评论是使用FastText进行预处理的,FastText是最近推出的用于生成字嵌入的方法[12],它改进了更常用的Word2Vec [37]。对每个进化的DNN进行三个时期的训练,并将测试集上的分类准确度作为适应度返回。初步实验表明,三个训练时期足以使网络性能收敛。因此,与诸如胸部X射线之类的视觉领域不同,在进化之后不需要额外的步骤,其中最佳进化网络从头开始被广泛训练。每一代网络的培训和评估都分布在100多台工人机器上。有关探索的进化配置和搜索空间的更多信息,请分别参阅表2和表3。
Wikidetox域是Kaggle挑战的一部分,因此,已经存在几个手工设计的域网[4]。此外,由于可以在此数据集上训练网络的相对速度,在此数据集上评估来自Mi-crosoft,Google和MOE等公司的超参数优化方法是切实可行的。图3显示了针对其他几种方法的LEAF架构搜索的比较。第一个是来自Kaggle竞赛的基线网络,通过将标准架构应用于新问题来说明天真用户可以期待的性能。在花费仅35个CPU小时后,LEAF发现超出该性能的架构。接下来的三个比较说明了LEAF对其他AutoML系统的强大功能。大约180小时后,它超出了使用默认计算资源的Google AutoML文本分类器优化[1]的性能。大约1000小时后,LEAF超越了微软的TLC库进行模型流水线优化[10],并且在2000小时之后,它超过了MOE,一个贝叶斯优化库[5](两个库都使用了足够的计算资源来实现平台性能)。仅LEAF超参数版本的表现略好于MOE,展示了其他优化方法的演化能力。最后,如果用户愿意花费大约9000小时的CPU时间来解决这个问题,那么结果就是最先进的性能。在这一点上,LEAF发现的建筑超过了Kaggle比赛获胜者的表现,即改进了最着名的手工设计。此结果与LEAF的超参数版本之间的性能差距也很重要:它通过优化网络架构显示了增加的价值,证明它是改进现有技术的重要因素。
LEAF的有趣之处在于,培训时间/金钱的使用量与结果的质量之间存在明显的权衡。根据可用的预算,运行LEAF的用户可以提前停止以使结果与现有方法(例如TLC或Google AutomL)竞争,或者将其运行到收敛以获得最佳结果。如果用户愿意花费更多的计算,则可以获得越来越强大的架构。这种灵活性表明,LEAF不仅是改善人工智能的工具,也是人工智能民主化的工具。
4.2 Chest X-rays Multitask Image Classification
胸部X射线分类是最近引入的MTL基准[41,50]。该数据集由112,120个高分辨率额胸X射线图像组成,图像标记有14种不同疾病中的一种或多种,或根本没有疾病。数据集的多标签性质自然有助于MTL设置,其中每种疾病是单独的二元分类任务。过去的方法通常应用经典的MTL DNN架构[50],目前最先进的方法使用Densenet [41]的略微修改版本,这是一种广泛使用的手工设计架构,与状态有竞争力。 Imagenet领域的艺术[26]。图像分为70%训练,10%验证和20%测试。用于评估网络性能的指标是所有任务(AUROC)的ROC曲线下的平均面积。虽然实际图像较大,但所有方法(包括LEAF)都将图像预处理为224×224像素,这是许多Imagenet DNN架构使用的相同输入尺寸。
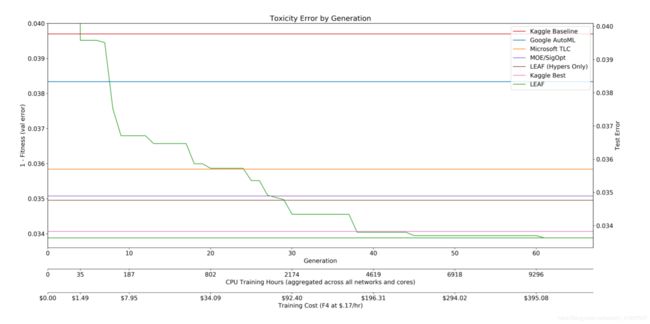
图3:Wikidetox域中的LEAF与通过几种商业方法发现的网络的比较,包括Keras,Google AutoML,MSFT TLC和MOE,以及Kaggle比较中的顶级人工设计网络。 y轴显示迄今为止实现的最佳最佳适应度(即准确度),而x轴显示世代,总训练时间和在云计算上花费的总金额。 如图所示,LEAF逐渐能够发现更好的网络,最终在第40代中找到一个优于所有其他方法的网络。
由于Chest X-ray是一个多任务数据集,因此LEAF配置为使用CoDeepNEAT的MTL变体来发展网络架构。这些体系结构的搜索空间是围绕2D卷积层设计的,包括在网络中看到的跳过连接,如ResNet [22]。对于健身评估,所有网络都使用Adam [28]训练了八个时期。训练完成后,AUROC将在验证集中的所有图像上进行计算,并作为适应度返回。在进化过程中的训练和评估过程中没有进行数据增加,但是使用Imagenet数据集中的均值和方差统计量对图像进行了标准化。培训的平均时间通常约为3-4小时,具体取决于网络规模,但对于一些较大的网络,培训时间超过12小时。与Wikidetox领域一样,培训和评估在100多台工作机器上进行了并行化。有关探索配置和搜索空间的更多信息,请分别参阅表2和表3。
在演化收敛之后,使用ADAM优化器[28]训练了最好的进化网络以增加了一些时期。与其他神经结构搜索方法[42,55]一样,使用模型增强方法,其中每个卷积层的滤波器数量增加。在每个训练时期,数据增强也应用于图像,包括随机水平翻转,平移和旋转。基于每个时期的验证AUROC向下动态调整学习速率,并且如果验证性能稳定,则有时将其重置回其原始值。在训练完成后,在启用数据增强的情况下对测试集图像进行20次评估,并对网络输出进行平均以形成最终预测结果。
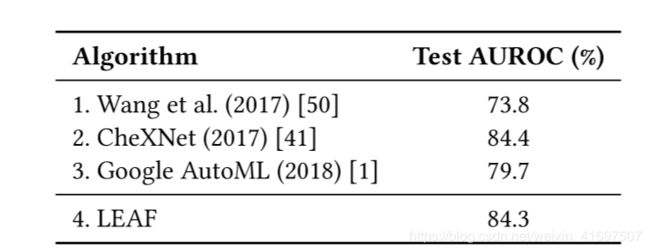
表1:针对手工设计架构的胸部X射线测试集以及使用Google AutoML和LEAF演变的网络的性能。 LEAF与Google AutoML相比显着提升,并且与最佳手工设计的DNN完美地实现了性能,在需要非常大的网络的任务中展示了最先进的结果。
表1比较了最佳演进网络的性能与在保持测试图像集上使用手工设计的网络架构的现有方法。这些包括最初引入胸部X射线数据集的作者[50]以及CheXNet [41]的结果,这是目前在该任务中发布的最新技术。为了与其他AutoML系统进行比较,还列出了Google AutoML [1]的结果。 Google AutoML设置为使用24小时的预设时间(用户可用的两个时间限制中的较高者)优化视觉任务,具有未知数量的计算机和工作机器数量。由于域的大小,用其他AutoML方法评估胸部X射线是不实际的。 LEAF发现的最佳网络的性能与人类设计的CheXNet的性能相匹配。 LEAF也能够以近4个AUROC点的大幅度超过Google AutoML的性能。这些结果表明,即使在需要大型复杂网络的领域中,也可以实现最先进的结果。
一个有趣的问题是:LEAF还可以在不牺牲性能的情况下最小化这些网络的大小吗?有趣的是,当LEAF使用CoDeep-NEAT(多目标LEAF)的多目标扩展来最大化适应度并最小化网络大小时,LEAF实际上在进化过程中更快收敛到相同的最终适应度。正如所料,多目标LEAF也能够发现参数较少的网络。如图4所示,在进化过程中由多目标LEAF(蓝色)产生的帕累托前沿在进化过程中在同一代进行比较时主导了单目标LEAF(绿色)。虽然单目标LEAF使用标准的CoDeepNEAT,但是通过将过去几代中发现的所有网络的主要和次要目标值提供给算法3,可以生成Pareto前沿。多目标LEAF的Pareto前沿也以相同的方式创建。
有趣的是,多目标LEAF在多个阶段发现了良好的网络。在第10代中,通过这两种方法找到的网络具有相似的平均复杂度,但是由多目标LEAF进化的网络具有更高的平均适应度。这种情况在演化后期发生变化,到第40代,多目标LEAF发现的网络的平均复杂度明显低于单目标LEAF,但它们之间平均适应度的差距也缩小了。多目标LEAF首先尝试优化第一个目标(适应度),并且只有当适应性开始收敛时,才尝试改进第二个目标(复杂性)。换句话说,多目标LEAF赞成目前最容易改进的指标的进展并且没有被卡住;如果当前没有取得进展,它会尝试优化另一个目标。
通过多目标LEAF演化的选定网络的可视化如图5所示.LEAF能够发现一个非常强大的网络(图5b),在仅仅8个训练时期之后就实现了77%的AUROC。 该网络具有125K参数,并且已经比使用单目标LEAF发现的具有类似适应性的网络小得多。 此外,多目标LEAF能够发现一个更小的网络(图5a),在八个训练时期后,只有56K参数和74%AUROC的适应度。 较小和较大网络之间的主要区别在于,较小的网络在其蓝图中仅使用特别复杂的模块架构(图5c)两次,而较大的网络使用相同的模块四次。 该结果显示了如何在不牺牲大部分性能的情况下将次要目标用于将搜索偏向于较小的体系结构。
5 DISCUSSION
Wikidetox域中LEAF的结果表明,优化深度神经网络的一种改进方法是可行的。通过非常轻松的努力,可以在一个天真的起点上进行改进,并且可以更加努力地击败AutoML系统和手工设计的现有技术。虽然需要大量的计算来训练数以千计的神经网络,但很有希望只需更长时间地运行LEAF并在计算上花费更多,就可以改善结果。此功能在商业环境中非常有用,因为它使用户可以灵活地找到花费的资源与结果质量之间的最佳权衡。随着计算能力在未来变得更便宜和更多可用,预计将获得明显更好的结果。并非所有的方法都能充分利用这种能力,但进化的AutoML可以。
LEAF的实验表明,多目标优化在发现折衷多个指标的网络方面是有效的。如图4的帕累托前沿所示,多目标LEAF所揭示的网络主导了单目标LEAF在几乎每一代人的复杂性和适应度指标方面的演变。更令人惊讶的是,多目标LEAF也保持了较高的平均适应度。这一发现表明,最小化网络复杂性会产生正规化效应,这也会改善网络的泛化。这种影响可能是由于与单目标LEAF相比,多目标LEAF重用模块进化的网络更常见;广泛的模块重用已被证明可以提高许多手工设计架构的性能[22,48]。
除了本文中演示的进化AutoML的三个目标之外,第四个目标是利用多个相关数据集。如先前的工作[30]所示,即使在特定任务中训练DNN的数据很少,多任务设置中的其他任务也可以帮助实现良好的性能。因此,进化AutoML形成了在域中利用DNN的框架,否则由于缺乏数据而不可行。
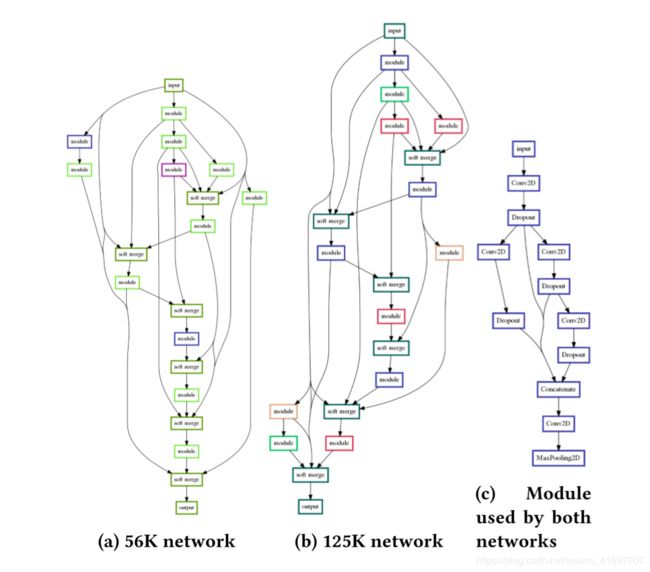
图5:由多目标LEAF发现的具有不同复杂性的网络的可视化。 较小的56K网络(图5a)的性能几乎与较大的125K网络(图5b)的性能一样好。 较小的网络仅使用图5c中所示的模块体系结构的两个实例,而较大的网络使用相同模块的四个实例。 这两个网络表明多目标LEAF能够通过巧妙地使用模块在两个相互冲突的目标之间找到良好的权衡。
6 CONCLUSION
本文表明,LEAF可以胜过现有的最先进的AutoML系统和最好的手工设计解决方案。架构的超参数,组件和拓扑都可以同时优化,以满足需求
任务,导致卓越的性能。即使用户具有很少的领域知识并且提供了一个天真的起点,LEAF也能实现这样的结果,从而使AI民主化。使用LEAF,还可以同时优化体系结构的其他方面,例如大小,使得发现的解决方案更有可能在实践中有用。
LEAF等自动化设计框架的最大影响在于,它可以在视觉,语音,语言,机器人和其他领域实现新的和意想不到的深度学习应用。从长远来看,算法和DNN的手工设计可能会被更复杂的通用自动化系统所取代,以帮助科学家进行研究或帮助工程师设计支持AI的产品。

REFERENCES
[1] 2017. AutoML for large scale image classification and object detection. https: //ai.googleblog.com/2017/11/automl-for-large-scale-image.html. (Nov 2017).
[2] 2019. Amazon Web Services (AWS) - Cloud Computing Services. aws.amazon.com. (2019).
[3] 2019. Google Cloud. cloud.google.com. (2019).
[4] 2019. Jigsaw Toxic Comment Classification Challenge. kaggle.com/ jigsaw-toxic-comment-classification-challenge. (2019).
[5] 2019. Metric Optimization Engine. https://github.com/Yelp/MOE. (2019).
[6] 2019. Microsoft Azure Cloud Computing Platform and Services. azure.microsoft. com. (2019).
[7] 2019. Research:Detox/Data Release. meta.wikimedia.org/wiki/Research:Detox.
(2019).
[8] 2019. SigOpt. sigopt.com/product. (2019).
[9] 2019. StudioML. https://www.studio.ml/. (2019).
[10] 2019. Using the Microsoft TLC Machine Learning Tool. jamesmccaffrey.wordpress. com/2017/01/13/using-the-microsoft-tlc-machine-learning-tool. (2019).
[11] James Bergstra and Yoshua Bengio. 2012. Random search for hyper-parameter optimization. Journal of Machine Learning Research 13, Feb (2012), 281–305.
[12] Piotr Bojanowski, Edouard Grave, Armand Joulin, and Tomas Mikolov. 2016. En-riching Word Vectors with Subword Information. arXiv preprint arXiv:1607.04606 (2016).
[13] Zhengping Che, Sanjay Purushotham, Kyunghyun Cho, David Sontag, and Yan Liu. 2016. Recurrent Neural Networks for Multivariate Time Series with Missing Values. CoRR abs/1606.01865 (2016). http://arxiv.org/abs/1606.01865
[14] F. Chollet et al. 2015. Keras. (2015).
[15] Theodora Chu, Kylie Jue, and Max Wang. 2016. Comment Abuse Classification with Deep Learning. Von https://web. stanford. edu/class/cs224n/reports/2762092. pdf abgerufen (2016).
[16] Ronan Collobert and Jason Weston. 2008. A unified architecture for natural lan-guage processing: Deep neural networks with multitask learning. In Proceedings of the 25th international conference on Machine learning. ACM, 160–167.
[17] Kalyanmoy Deb. 2015. Multi-objective evolutionary algorithms. In Springer Handbook of Computational Intelligence. Springer, 995–1015.
[18] Thomas Elsken, J Hendrik Metzen, and Frank Hutter. 1804. Efficient Multi-objective Neural Architecture Search via Lamarckian Evolution. ArXiv e-prints (1804).
[19] Faustino Gomez, Jürgen Schmidhuber, and Risto Miikkulainen. 2008. Accelerated neural evolution through cooperatively coevolved synapses. Journal of Machine Learning Research 9, May (2008), 937–965.
[20] Faustino J Gomez and Risto Miikkulainen. 1999. Solving non-Markovian control tasks with neuroevolution. In IJCAI, Vol. 99. 1356–1361.
[21] Alex Graves, Abdel-rahman Mohamed, and Geoffrey Hinton. 2013. Speech recog-nition with deep recurrent neural networks. In 2013 IEEE International Conference on Acoustics, Speech and Signal Processing. IEEE, 6645–6649.
[22] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 770–778.
[23] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Identity Mappings in Deep Residual Networks. CoRR abs/1603.05027 (2016). http://arxiv.org/abs/ 1603.05027
[24] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Identity mappings in deep residual networks. In European conference on computer vision. Springer, 630–645.
[25] Andrew G Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, and Hartwig Adam. 2017. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv preprint arXiv:1704.04861 (2017).
[26] Gao Huang, Zhuang Liu, Laurens Van Der Maaten, and Kilian Q Weinberger. 2017. Densely Connected Convolutional Networks… In CVPR, Vol. 1. 3.
[27] Eamonn Keogh and Abdullah Mueen. 2011. Curse of dimensionality. In Encyclo-pedia of machine learning. Springer, 257–258.
[28] D. P. Kingma and J. Ba. 2014. Adam: A Method for Stochastic Optimization. CoRR abs/1412.6980 (2014).
[29] Yann LeCun, Yoshua Bengio, and Geoffrey Hinton. 2015. Deep learning. Nature 521, 7553 (2015), 436–444.
[30] Jason Liang, Elliot Meyerson, and Risto Miikkulainen. 2018. Evolutionary Archi-tecture Search for Deep Multitask Networks. In Proceedings of the Genetic and Evolutionary Computation Conference (GECCO ’18). ACM, New York, NY, USA,
GECCO ’19, July 13–17, 2019, Prague, Czech Republic
466–473. https://doi.org/10.1145/3205455.3205489
[31] Hanxiao Liu, Karen Simonyan, Oriol Vinyals, Chrisantha Fernando, and Koray Kavukcuoglu. 2017. Hierarchical representations for efficient architecture search. arXiv preprint arXiv:1711.00436 (2017).
[32] Ilya Loshchilov and Frank Hutter. 2016. CMA-ES for Hyperparameter Optimiza-tion of Deep Neural Networks. arXiv preprint arXiv:1604.07269 (2016).
[33] Zhichao Lu, Ian Whalen, Vishnu Boddeti, Yashesh Dhebar, Kalyanmoy Deb, Erik Goodman, and Wolfgang Banzhaf. 2018. NSGA-NET: A Multi-Objective Genetic Algorithm for Neural Architecture Search. arXiv preprint arXiv:1810.03522 (2018).
[34] E. Meyerson and R. Miikkulainen. 2018. Beyond Shared Hierarchies: Deep Multi-task Learning through Soft Layer Ordering. ICLR (2018).
[35] R. Miikkulainen, J. Liang, E. Meyerson, et al. 2017. Evolving deep neural networks. arXiv preprint arXiv:1703.00548 (2017).
[36] Tomáš Mikolov, Martin Karafiát, Lukáš Burget, Jan Černocky,` and Sanjeev Khu-danpur. 2010. Recurrent neural network based language model. In Eleventh Annual Conference of the International Speech Communication Association.
[37] Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg S Corrado, and Jeff Dean. 2013. Distributed representations of words and phrases and their compositionality. In
Advances in neural information processing systems. 3111–3119.
[38] David E Moriarty and Risto Miikkulainen. 1998. Hierarchical evolution of neural networks. In Evolutionary Computation Proceedings, 1998. IEEE World Congress on Computational Intelligence., The 1998 IEEE International Conference on. IEEE, 428–433.
[39] Joe Yue-Hei Ng, Matthew J. Hausknecht, Sudheendra Vijayanarasimhan, Oriol Vinyals, Rajat Monga, and George Toderici. 2015. Beyond Short Snippets: Deep Networks for Video Classification. CoRR abs/1503.08909 (2015). http://arxiv.org/ abs/1503.08909
[40] Mitchell A Potter and Kenneth A De Jong. 1994. A cooperative coevolutionary approach to function optimization. In International Conference on Parallel Problem Solving from Nature. Springer, 249–257.
[41] Pranav Rajpurkar, Jeremy Irvin, Kaylie Zhu, Brandon Yang, Hershel Mehta, Tony Duan, Daisy Ding, Aarti Bagul, Curtis Langlotz, Katie Shpanskaya, et al. 2017. Chexnet: Radiologist-level pneumonia detection on chest x-rays with deep learn-ing. arXiv preprint arXiv:1711.05225 (2017).
[42] Esteban Real, Alok Aggarwal, Yanping Huang, and Quoc V Le. 2018. Regularized evolution for image classifier architecture search. arXiv preprint arXiv:1802.01548 (2018).
[43] E. Real, S. Moore, A. Selle, et al. 2017. Large-scale evolution of image classifiers. arXiv preprint arXiv:1703.01041 (2017).
[44] Jasper Snoek, Hugo Larochelle, and Ryan P Adams. 2012. Practical bayesian optimization of machine learning algorithms. In Advances in neural information processing systems. 2951–2959.
[45] Jasper Snoek, Oren Rippel, Kevin Swersky, Ryan Kiros, Nadathur Satish, Narayanan Sundaram, Md Mostofa Ali Patwary, Mr Prabhat, and Ryan P Adams. 2015. Scalable Bayesian Optimization Using Deep Neural Networks… In ICML. 2171–2180.
[46] Kenneth O. Stanley and Risto Miikkulainen. 2002. Evolving Neural Networks Through Augmenting Topologies. Evolutionary Computation 10 (2002), 99–127. stanley:ec02
[47] M. Suganuma, S. Shirakawa, and T. Nagao. 2017. A genetic programming approach to designing convolutional neural network architectures. In Proc. of GECCO. ACM, 497–504.
[48] Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, and Andrew Rabinovich. 2015. Go-ing deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 1–9.
[49] Pascal Vincent, Hugo Larochelle, Isabelle Lajoie, Yoshua Bengio, and Pierre-Antoine Manzagol. 2010. Stacked denoising autoencoders: Learning useful repre-sentations in a deep network with a local denoising criterion. Journal of machine learning research 11, Dec (2010), 3371–3408.
[50] Xiaosong Wang, Yifan Peng, Le Lu, Zhiyong Lu, Mohammadhadi Bagheri, and Ronald M Summers. 2017. Chestx-ray8: Hospital-scale chest x-ray database and benchmarks on weakly-supervised classification and localization of common thorax diseases. In Computer Vision and Pattern Recognition (CVPR), 2017 IEEE Conference on. IEEE, 3462–3471.
[51] Ronald J Williams. 1992. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Machine learning 8, 3-4 (1992), 229–256.
[52] Kohsuke Yanai and Hitoshi Iba. 2001. Multi-agent robot learning by means of genetic programming: Solving an escape problem. In International Conference on Evolvable Systems. Springer, 192–203.
[53] Chern Han Yong and Risto Miikkulainen. 2001. Cooperative coevolution of multi-agent systems. University of Texas at Austin, Austin, TX (2001).
[54] Aimin Zhou, Bo-Yang Qu, Hui Li, Shi-Zheng Zhao, Ponnuthurai Nagaratnam Suganthan, and Qingfu Zhang. 2011. Multiobjective evolutionary algorithms: A survey of the state of the art. Swarm and Evolutionary Computation 1, 1 (2011), 32–49.
[55] Barret Zoph and Quoc V. Le. 2016. Neural Architecture Search with Reinforcement Learning. CoRR abs/1611.01578 (2016). http://arxiv.org/abs/1611.01578