360面经整理
360面经整理
360服务端搜索
一面:多叉树遍历,判断二叉树B是不是A的子树,快排(int num[],int len)(递归和非递归);
多叉树遍历
递归:
void travel(Node *pNode)
{
if (pNode == Null)
{
return;
}
Deal(pNode);
for (int i=0 ;ichild_list.size(); i++)
{
Node *tmp = pNode->child_list[i];
travel(tmp);
}
} 非递归:
void travel(Node *pNode)
{
stack stack;
stack.push(pNode);
Node *lpNode;
while(!stack.empty())
{
lpNode = stack.top();
stack.pop();
Deal(lpNode);
for (int i=0 ;ichild_list.size(); i++)
{
stack.push(pNode->child_lis[i]);
}
}
} 判断二叉树B是不是A的子树:
import org.junit.Test;
public class solution {
@Test
public void testFunc(){
TreeNode root1 = new TreeNode(1);
TreeNode root2 = new TreeNode(2);
TreeNode root3 = new TreeNode(3);
root1.left=root2;
root1.right=root3;
TreeNode root4 =new TreeNode(1);
TreeNode root5 = new TreeNode(2);
TreeNode root6= new TreeNode(3);
root4.left=root5;
root4.right=root6;
boolean flag = isSubTree(root1, root4);
System.out.println("flag: "+flag);
}
//判断二叉树B是不是二叉树A的子结构
public boolean isSubTree(TreeNode aNode, TreeNode bNode){
if(bNode==null || aNode==null){
return false;
}
boolean flag =false;
if (aNode.val==bNode.val) {
flag = hasSubTree2(aNode, bNode);
}
if (!flag) {
flag = isSubTree(aNode.left, bNode);
}
if (!flag) {
flag=isSubTree(aNode.right, bNode);
}
return flag;
}
private boolean hasSubTree2(TreeNode aNode, TreeNode bNode) {
if (bNode==null) {
return true;
}
if (aNode==null) {
return false;
}
if (aNode.val!=bNode.val) {
return false;
}
return hasSubTree2(aNode.left, bNode.left) && hasSubTree2(aNode.right, bNode.right);
}
}
快排(int num[],int len)(递归和非递归):
递归:
int Parition(int *arr,int low,int high)
{
int tmp=arr[low];
while(low=tmp)high--;
arr[low]=arr[high];
while(low
非递归:
void Sort_no(int* arr, int n)
//快速排序的循环写法
{
int brr[50];
int count=0;
int low;
int high;
int mid;
brr[count++]=0;//这存放的数是数组最左边的数
brr[count++]=n-1;//这存放的数是数组最右的数
while(count>0)
{
high=brr[count-1];//重新定义high
low=brr[count-2];//重新定义low
if(low
二面:字符串逆置,找第K大个数(代码实现);
没有例子,不会写。
个人安全-服务端开发工程师
1.linux下文件的编译过程,有多个.c文件怎么编译,makefile底层原理了解吗
功能:在main.c里面调用其他两个源文件里面的函数,然后输出字符串。
main.c
#include"mytool1.h"
#include"mytool2.h"
int main(int argc,char* argv[])
{
mytool1_printf("hello.");
mytool2_print("hello");
return 1;
}
mytool1.h mytool1.c
//mytool1.h
#ifndef _MYTOOL_1_H
#define _MYTOOL_1_H
void mytool1_printf(char* print_str);
#endif
//mytool1.c
#include"mytool1.h"
#include
void mytool1_printf(char* print_str)
{
printf("This is mytool1 print %s\n",print_str);
}
mytool2.h mytool2.c
//mytool2.h
#ifndef _MYTOOL_2_H
#define _MYTOOL_2_h
void mytool2_print(char* print_str);
#endif
//mytool2.c
#include "mytool2.h"
#include
void mytool2_print(char* print_str)
{
printf("This is mytool2 print %s\n",print_str); 在linux下,把这几个文件放在同一个目录下,然后在shell中输入
gcc -c main.c
gcc -c mytool1.c
gcc -c mytool2.c
gcc main.o mytool1.o mytool2.o -o main 就可以生成可执行文件 main
关于 Makefile
如果项目中的源文件改动一次,那项目就要重新编译一次,这样会很麻烦。一个Makefile文件就可以解决这个问题。Makefile文件里面存在编译的指令,这样源文件改变一次,我们只要重新Make一下,项目就会编译好,会很方便。
在我们执行make之前,我们要先编写一个非常重要的文件.--Makefile.
main:main.o mytool1.o mytool2.o
gcc -o main main.o mytool1.o mytool2.o
main.o:main.c mytool1.h mytool2.h
gcc -c main.c
mytool1.o:mytool1.c mytool1.h
gcc -c mytool1.c
mytool2.o:mytool2.c mytool2.h
gcc -c mytool2.c
有了这个Makefile文件,不过我们什么时候修改了源程序当中的什么文件,我们只要执行make命令,我们的编译器都只会去编译和我们修改的文件有关的文件,其它的文件她连理都不想去理的.
下面我们学习Makefile是如何编写的.
在Makefile中也#开始的行都是注释行.Makefile中最重要的是描述文件的依赖关系的说明.一般的格式是:
target: components
TAB rule
第一行表示的是依赖关系.第二行是规则.
比如说我们上面的那个Makefile文件的第二行
main:main.o mytool1.o mytool2.o
表示我们的目标(target)main的依赖对象(components)是main.o mytool1.o mytool2.o 当倚赖的对象在目标修改后修改的话,就要去执行规则一行所指定的命令.就象我们的上面那个Makefile第三行所说的一样要执行 gcc -o main main.o mytool1.o mytool2.o 注意规则一行中的TAB表示那里是一个TAB键
Makefile有三个非常有用的变量.分别是$@,$^,$<代表的意义分别是:
$@--目标文件,$^--所有的依赖文件,$<--第一个依赖文件.
如果我们使用上面三个变量,那么我们可以简化我们的Makefile文件为:
# 这是简化后的Makefile
main:main.o mytool1.o mytool2.o
gcc -o $@ $^
main.o:main.c mytool1.h mytool2.h
gcc -c $<
mytool1.o:mytool1.c mytool1.h
gcc -c $<
mytool2.o:mytool2.c mytool2.h
gcc -c $<经过简化后我们的Makefile是简单了一点,不过人们有时候还想简单一点.这里我们学习一个Makefile的缺省规则
.c.o:
gcc -c $<
这个规则表示所有的 .o文件都是依赖与相应的.c文件的.例如mytool.o依赖于mytool.c这样Makefile还可以变为:
# 这是再一次简化后的Makefile
main:main.o mytool1.o mytool2.o
gcc -o $@ $^
.c.o:
gcc -c $<
2.路由表,
下面这篇博文解释得很详细
http://www.cnblogs.com/zzp28/articles/1746188.html
3.怎样生成动态链接库,静态链接库
本质上来说库是一种可执行代码的二进制形式,可以被操作系统载入内存执行。库有两种:静态库(.a、.lib)和动态库(.so、.dll)。 windows上对应的是.lib .dll ;linux上对应的是.a .so
将一个程序编译成可执行程序的步骤:
图:编译过程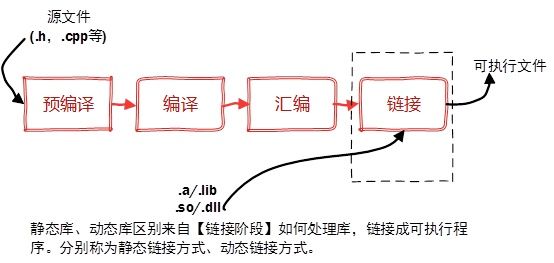
静态库
之所以成为【静态库】,是因为在链接阶段,会将汇编生成的目标文件.o与引用到的库一起链接打包到可执行文件中。因此对应的链接方式称为静态链接。
试想一下,静态库与汇编生成的目标文件一起链接为可执行文件,那么静态库必定跟.o文件格式相似。其实一个静态库可以简单看成是一组目标文件(.o/.obj文件)的集合,即很多目标文件经过压缩打包后形成的一个文件。静态库特点总结:
l 静态库对函数库的链接是放在编译时期完成的。
l 程序在运行时与函数库再无瓜葛,移植方便。
l 浪费空间和资源,因为所有相关的目标文件与牵涉到的函数库被链接合成一个可执行文件。
Linux下创建与使用静态库
Linux静态库命名规则
Linux静态库命名规范,必须是"lib[your_library_name].a":lib为前缀,中间是静态库名,扩展名为.a。
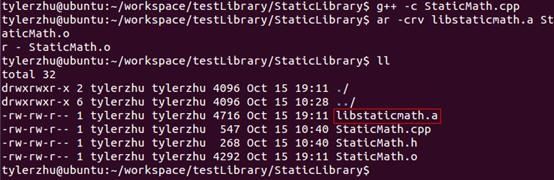
创建静态库(.a)
通过上面的流程可以知道,Linux创建静态库过程如下:
l 首先,将代码文件编译成目标文件.o(StaticMath.o)
g++ -c StaticMath.cpp注意带参数-c,否则直接编译为可执行文件
然后,通过ar工具将目标文件打包成.a静态库文件
ar -crv libstaticmath.a StaticMath.o生成静态库libstaticmath.a。
动态库
通过上面的介绍发现静态库,容易使用和理解,也达到了代码复用的目的,那为什么还需要动态库呢?
为什么还需要动态库?
为什么需要动态库,其实也是静态库的特点导致。
l 空间浪费是静态库的一个问题。
![clip_image021[4]](http://img.e-com-net.com/image/info8/4071939bf72e487484fceb8ac3a47bcc.jpg)
另一个问题是静态库对程序的更新、部署和发布页会带来麻烦。如果静态库liba.lib更新了,所以使用它的应用程序都需要重新编译、发布给用户(对于玩家来说,可能是一个很小的改动,却导致整个程序重新下载,全量更新)。
动态库在程序编译时并不会被连接到目标代码中,而是在程序运行是才被载入。不同的应用程序如果调用相同的库,那么在内存里只需要有一份该共享库的实例,规避了空间浪费问题。动态库在程序运行是才被载入,也解决了静态库对程序的更新、部署和发布页会带来麻烦。用户只需要更新动态库即可,增量更新。
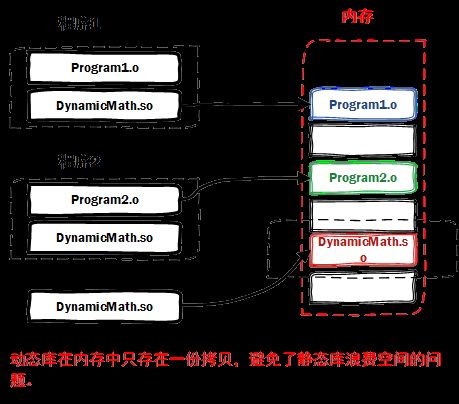
动态库特点总结:
l 动态库把对一些库函数的链接载入推迟到程序运行的时期。
l 可以实现进程之间的资源共享。(因此动态库也称为共享库)
l 将一些程序升级变得简单。
l 甚至可以真正做到链接载入完全由程序员在程序代码中控制(显示调用)。
Window与Linux执行文件格式不同,在创建动态库的时候有一些差异。
l 在Windows系统下的执行文件格式是PE格式,动态库需要一个DllMain函数做出初始化的入口,通常在导出函数的声明时需要有_declspec(dllexport)关键字。
l Linux下gcc编译的执行文件默认是ELF格式,不需要初始化入口,亦不需要函数做特别的声明,编写比较方便。
与创建静态库不同的是,不需要打包工具(ar、lib.exe),直接使用编译器即可创建动态库。
4.正则表达式匹配一个url
(https?|ftp|file)://[-A-Za-z0-9+&@#/%?=~_|!:,.;]+[-A-Za-z0-9+&@#/%=~_|]
5.epoll处理多个请求的过程
https://blog.csdn.net/hjxhjh/article/details/9374837
6.符号表
https://blog.csdn.net/hk2291976/article/details/51406050
7.服务器是怎样处理动态内容的
8.DNS
https://blog.csdn.net/kim_weir/article/details/78465641
C++服务端
360:
一面
vector
堆排序
千万商铺的经纬度坐标、辐射范围,你的经纬度坐标,计算你在哪些商铺辐射范围内
10亿数字,内存小,计算中位数
二面:
编写中序遍历二叉树的迭代器
大量2n 1个数,一个个数为奇数,找出来
多态原理
空类默认创建那些函数
拷贝构造函数参数,const &作用
搜索关键字提示(字典树),提示顺序(权重)
设计系统,根据浏览网页中的图片,推荐淘宝之类商家相似商品
搜索服务端开发
一面
自我介绍,上来问项目,看做了象棋游戏抓住智能走棋问了好久(博弈和剪枝),花图加解释,聊天室项目问了实现方式,多线程和多进程,服务端端监听方式,怎么实现消息队列,还有一些细节。然后看我是转行的告诉我互联网也饱和了你转进来干嘛(心想再饱能有航天饱)然后问了QT树控件,线程同步方式,事件,阻塞,IO模型,设计模式,工厂模式有哪些,最后写了个分钱币的算法结束。
二面)
自我介绍,然后项目,又问了博弈算法,然后问你这个和图的遍历有相似点没,我说了下DFS BFS原理,然后说感觉不太像,让我优化,没见过不会,问导航算法(单源最短路的几种算法和怎么优化),然后问聊天室项目,说用到高并发没有,没有用到,然后问那你说说如果有,怎么解决,说了使用消息队列削峰,异步处理,然后问10亿个数找中位数,最后来了句看你之前学的有数值分析,我再问你一个问题,你实现一下牛顿迭代法,我说那就是个公式怎么实现…那你实现一下sqrt,我说用牛顿迭代法,他说那个不算,再想一个,想了个二分法实现结束。
三面(打电话让我一点半到,自己两点半了还没来)
自我介绍,然后问为什么转行,对比分析两个行业的区别,对在北京工作什么看法,为什么,家人怎么看你在北京工作,怎么看你转行,给自己上午两面打分,说说朋友眼中的你,问对互联网的看法,未来发展对什么感兴趣,说对智能家居感兴趣,但现在能力不够还不能胜任,问为什么投360,我说360做安全的,一直在用,然后说你这基础不够项目也不相关喜欢的是安全为什么投的搜索岗?说看岗位要求感觉搜索符合的更多一些,又问那你是不是投了搜索入行就像你转行一样又跳走了………问到这我就懵逼了,强行解释了一波说现在不想以后,以后还会变得感觉之后脸色就变了…然后问毕业时间,论文发了没,实验室做了哪些项目,给我一个理由说服我你适合这个岗位…最后问了点问题结束这后半程贼尴尬的面试。
360商业产品部web后端工程师面经
一面
一面是个小胖小胖的面试官,说我的实习经历挺丰富的(几个校内项目跟一个小公司实习项目),基本上问项目跟场景,中间穿插一些基础知识
• 讲实习项目的简单业务流程,数据库有水平拆分什么的吗?没有,数据量还没到,然后没啥问的
• Slice与数组区别,Slice底层结构
• 项目里的微信支付这块,在支付完微信通知这里,收到两次微信相同的支付通知,怎么防止重复消费(类似接口的幂等性),说了借助Redis或者数据库的事务
• 项目里的消息推送怎么做的(业务有关)
• Go的反射包怎么找到对应的方法(这里忘记怎么问的,直接说不会,只用了DeepEqual,简单讲了DeepEqual)
• Redis基本数据结构
• Redis的List用过吗?底层怎么实现的?知道但是没用过,不知道怎么实现
• Mysql的索引有几种,时间复杂度
• InnoDb是表锁还是行锁,为什么(这里答不出来为什么,只说了行锁)
• Go的channel(有缓冲和无缓冲)
• 退出程序时怎么防止channel没有消费完,这里一开始有点没清楚面试官问的,然后说了监听中断信号,做退出前的处理,然后面试官说不是这个意思,然后说发送前先告知长度,长度要是不知道呢?close channel下游会受到0值,可以利用这点(这里也有点跟面试官说不明白)
• 用过什么消息中间件之类吗?没有
• 有什么问题吗?评价?后面还有面试,后面再问吧
二面
二面的面试官好像是部门技术总监,面完了加微信,可能需要Go的人,感觉很多不会然后给过了,面完面试官人超好,微信推荐我看书
• 生产者消费者模式,手写代码(Go直接使用channel实现很简单,还想着面试官会不会不让用channel实现,不用channel的可以使用数组加条件变量),channel缓冲长度怎么决定,怎么控制上游生产速度过快,这里没说出解决方案,只是简单说了channel长度可以与上下游的速度比例成线性关系,面试官说这是一种解决方案
• 手写循环队列
• 写的循环队列是不是线程安全,不是,怎么保证线程安全,加锁,效率有点低啊,然后面试官就提醒Go推崇原子操作和channel
• 写完代码面试官说后面问的问题回答就可以,不知道的话没关系
• Linux会不会,只会几个命令,面试官就说一共也就一百多个命令
• TimeWait和CloseWait原因
• 线段树了解吗?不了解,字典树?了解
• 看过啥源码,nsq(Go的消息中间件),简单问了我里面的waitgroup包证明我看过
• sync.Pool用过吗,为什么使用,对象池,避免频繁分配对象(GC有关),那里面的对象是固定的吗?不清楚,没看过这个的源码
• 有什么问题吗?评价?基础不错,Linux尚缺,Go的理解不够深入,高级数据结构不了解,优点是看源码
• 后面面试官讲了他们做的东西,主要是广告部分,说日均数据量至少百万以上,多达上亿,高并发使用Go支撑,有微服务,服务治理,说我需要学的东西挺多的
数据开发(大数据)
一面-技术
在牛客的视频面试平台。上午11:20,一面面试官(男)迟到了一会吧,不过没事,人挺好的,让我介绍一下我做的项目。我有三个项目,两个跟大数据无关的,一个跟大数据有关的。让我大致说一下三个项目,然后让我重点介绍一下我最深刻的一个项目,我说了我自己做的非大数据相关的项目。blabla。然后一边说,他也问了自己想了解的地方。重点在隐私和NLP方面探讨了一下。然后侧面了解了一下我的学习能力。他的反馈是我比之前面的两位应聘者要好一点(不知道是不是都这么说),然后直接告诉我面试通过了。
二面-技术
14:00。面试官(女)重点了解了一下我的大数据相关的项目,深入探讨了一下。然后整体感觉难度中等偏上。
三面-HR
没多久打电话让我进聊天室。问的问题挺多的,基本上都是关于个人的发展类的问题,考不考研,实习时间,学习能力等。
后台PHP开发
一面:
1.以自我介绍开始(找工作以来,已经不知道自我介绍了多少遍)
2.手写单例设计模式(基础问题,好开心)
3.介绍一下PHP面向对象和java面向对象的不同
4.PHP类里面的三个指针(懵逼,其实就是问self this 类名这三个的使用)
5.OSI网络分层,三次握手
6.输入一个域名,到得到页面的过程(其实就是计算机网络每层做了什么,又以LAMP为例说了一下服务器端的解析过程)
7.数据库innodb引擎和myisam引擎的区别
8.redis实习的时候是怎么用的
9.项目中怎么做的中文检索,回答使用结巴分词+mysql模糊查询(面试官表示数据量小还可以,如果数据量大呢,回答的加上redis缓存,或者使用apache基金会的solr之类的,蒙混过关)
10.好像还问看你用过hadoop,掌握程度怎么样(恰好本来准备论文用的,研究了一下机制,回答的还可以)
11.说一下mapreduce的过程
12.有没有什么代码爱好(脑残回答了喜欢写shell自动化脚本)
13.删除某一指定用户名的进程(忘记pkil了,用awk+ps写的,还好过关)
14.hadoop的hdfs是怎么存储数据的,hadoop分那哪几部分(他知道的是hadoop 1.X的,我说的事2.6.0的,略尴尬)
15.对360印象如何,脑残亮点在此(回答了你们的搜索、浏览器、输入法都不错,旁边的同学笑喷,哪里来的输入法)
二面:(面试官很套路,问题吧都不直接问,拐着弯问,绕的我好辛苦)
1.数据库的索引设计(又是最左前缀)
2.sql查询,and之类的语句索引的顺序影响索引使用吗(不影响,and语句中mysql自己会优化,符合最左前缀就ok了)
3.问如果不使用http,让你自己设计客户端和服务器端如何传递表单数据(表示不懂什么意思,最后回答了按指定格式封装,然后socket通信,面试官竟然没说不行)
4.忘记问题是什么了,反正是个认证之类的,开始没有懂什么意思。后来明白了就是想问session和cookie,然后回答了,顺利过关
5.memcache用过吗,回答没有,然后说用过redis,稍微问了一下。
6.如果用户的请求一直在服务端丢失,排查一下什么情况(从cpu占用率,内存占用率,io,服务器状态,日志查询上回答的,顺便介绍了一下几个用到的linux命令,比较坑的是非要问我top按内存排序是M还是m,之后承认平时都是man一下,没背过)
7.介绍一下你们为什么做云计算虚拟化用KVM,其他方案调研过吗(早就调研过,引经据典,完美回答),告诉我他们用的是xen的解决方案,然后我问他们用的是openstack管理还是买服务。
8.mysql隔离级别和默认的是哪个。
9.怎么用hadoop+hive做的日志分析(详细介绍了一下)
HR面:
人生、理想
啦啦啦
最后加了小姐姐的微信。
又接到另一个部门的电话(记得好像是创新事业部来),好像是不冲突,不过面的很尴尬,还好也过了。
一面:
1.请求失败,服务端怎么排查(CPU,memory,io,数据库慢查询等,我也只知道这些)
2.mysql的inndob介绍一下
3.innodb什么时候可以用到索引,innodb索引与myisam索引区别(聚集、非聚集),inndob引擎使用非主键索引的检索过程(先查到主键呗),innodb索引的数据结构(B树),为什么B树不红黑(正好研究过,从树深度和计算机磁盘io消耗和局部性原则上扯了扯,成功装逼成功)
4.redis怎么使用的,redis数据结构用过哪些
5.你的日志处理shell预处理阶段怎么做的
6.你的日志处理可以显示实时数据吗,不行(阿里也问了这个问题,只有实话实说了),不过考虑过用kafka之类的做,然后说了说思路。
7.又是输入一个域名到显示出页面的整个过程
8.观察者设计模式(好像是有来,记不清了)
二面:(感觉全程问我怎么推荐,我怎么知道)
1.怎么统计模块的热度
2.怎么为用户有效推荐视频,提高访问量(实验室有做大数据的,根据听来的名词说了几句)
3.10000条数据可能只有100条被经常访问了,怎么挖掘其余的价值(回答了根据用户画像,推送,瞎蒙的)
4.说一下贝叶斯公式(也是醉了,就把本科学的全概率和贝叶斯回忆了一下,强调了一下我是做后台开发的)
5.还有一些记不清了
面完收到了二面官短信,给推荐了两本书,一本高并发一本推荐的(内心充满感激,对360面试官的好感度升级一大截),但是当时认为这是好人卡了,结果不是。
HR面:
HR是一个小姑娘,开车很快,不方便说了。
总的来说感觉360问的很全面,从数据库到基本知识到项目等等,数据结构和算法问的相对少一点(恰好我也不太会),面试官人很不错,就是面试弄得有点乱。
搜索C
一面:一个二十几岁小哥,人不错
1.自我介绍一分钟。
2.做过什么项目,项目中你实现了那个部分,怎么实现的,redis用来干什么?多线程时访问会不会问题?怎么解决?45分钟全程我一个在讲。
3.说下进程空间布局,说说你知道的,mmap使用过吗??进程间通信机制有什么? 共享内存是什么??
4.select,epoll内部原理??从select由来一直到epoll的优势,一一说明。
5.未排序的数组中查找中间的那个数,O(NlogN) , O(N) ?
6.会不会脚本?不会。。。他说:没关系,你已经不错了。
7.平时使用什么语言?C++
8.最后让我提一个问题?我就问问搜素岗是干什么的??
二面:一个三十多岁的人,感觉很威严。40分钟
1.自我介绍一分钟。
2.实现一个单例模式?
3.实现字符串切割,按空格切分?他找出了bug我修改了,他说还不错。
4.实现一个有N个工件,M种类,找出最小的子序列包含M个工件。我实现了一个时间O(N),空间O(M)的方法。以前做过原题
5.项目实现过程??20分钟自述。。。
6.epoll内部原理,给了一个场景,判断我是否了解epoll?我给他剖析了一下文件描述符原理,fd收发过程。
两面加起来说了一个多小时项目,我都说吐了。
HR面:妹子一枚
1.将来想去哪里工作,有没女朋友,家里在哪里,怎么和人相处,就不多说了。
搜索服务端-C++面经(一面+二面)
一面:
自我介绍
TCP三次握手四次挥手
指针和引用的区别
进程与线程的区别
进程的通信
树和hash表各自的适用范围
平衡二叉树的概念,如何删除一个结点
static的作用范围
快排的思想
如何检测单链表中有环,不能开辟额外空间(包括用容器和flag),提示:用两个指针实现
过河问题,ABCD四个人,单独过河分别需要1,2,5,10分钟,最多两个人同时过,并且只有一个手电筒,每次都需要电筒,两人过河按慢的时间算,问最少几分钟(答案是17分钟,同类型题牛客网里有)
感觉一面的面试官非常nice,问的都很基础很常规,每道题答出来基本的几个要点就给过了,有两道题没有思路的时候面试官也给了提示。结果很顺利地通过了一面。
二面:
二面的面试官一看就知道是部门佬大,一开始就问项目。在这里我就踩到了视频面一个大坑:不知道是耳机问题还是网络问题,部门佬大听不清我说话的声音,而我也听不太清佬大说话,好不容易对面说可以听到我说话了,就是声音有点小,一面面试官貌似也说过类似的话,结果一面面试官调整了一下耳机后就没问题了,所以我也没在意,然后我就开始介绍项目了。结果刚介绍到第二个,佬大就没让我继续介绍下去了,期间他也没问什么问题,估计没听清楚我到底说了什么,而且语音交流也有困难,所以他直接在代码框上出题让我撸代码了。。。
出的题目很简单:
第一题:实现strstr()功能
第二题:单链表倒置
两题过后,感觉面试官也不怎么看我写的代码,没问问题,也没让我做优化,本来还想着如果优化的话可以采用kmp算法优化第一题的。。。直接问我有什么问题要问的,我问了几个问题之后,对面做了解答,结果我啥都没听清,好吧-_-||,面试到此结束。。。
过了几分钟,hr小哥打电话过来:您好,很抱歉您没通过二面。。。
总结一下:一面还是比较好过的,二面遇到感觉项目方面应该占的比重会很大,听说一些面经就基本讲了项目就结束了,一般佬大会根据项目细节展开,比如里面用到的框架算法,前提是你要有良好的通信环境,否则都是白搭,所以在这里必须再三强调一下:通信很重要!通信很重要!通信很重要!希望大家以此为鉴,谨防入坑。
PHP工程师
360一面:
1、怎么用PHP设计一个网站,从最开始有想法开始到完工,全部流程大概讲一遍。
2、因为我项目中用到了Wordpress,问我Wordpress和ThinkPHP的优缺点。
3、NoSQL数据库怎么灾容
4、归并排序,描述一下大概流程,还有手写一下O(N)的归并
5、kmp算法
6、nginx的特性(可能因为我项目用的nginx)
7、nginx和php之间的调度关系(其实还隐含着想考察fpm)
8、怎么写php语言本身的拓展(基于C)
9、汇编语言的寻址方式
10、项目相关设计原因(模块的划分,类的继承,设计模式什么的)
其他的网络编译原理等方向,感觉面试官本来想问,但因为我大三这学期刚学,就只给他简单说了说讲到的部分,网络的下三层,编译原理自动机语法树什么的。。
360二面:
二面貌似就没什么技术性问题了,全是根据我的项目进行的提问,更考察工程方面的知识= =
让我讲了讲为什么项目这么设计架构,为什么选用wp和tp这俩框架,怎么拓展伸缩,怎么优化性能,opcode缓存什么的,其他好像就随便聊聊了。。。
360HR面:
HR面就是和非常nice的姐姐各种聊天了。。
1、说说优缺点
2、为什么做了这些项目
3、之前的实习经历
4、为什么想来360
5、报2B部门会不会缺少互联网的感觉
6、对加班看法什么的
各种扯一扯,自我感觉聊的还不错。。不知道能不能过,昨天面完现在还没收到通知= =
服务端开发工程师-C++
一面中间网络不稳定,给面试官造成的很多困扰
一面首先自我介绍,然后介绍项目
1.局部变量,全局变量,分别存在内存哪个位置
2.程序内存的分布,五个部分
3.new,malloc区别
4.数据结构相关问题,闲聊
5.C STL了解,说说vector,list,map区别
6.分析他们的性能
7.TCP三次握手,两次为什么不行
8.TCP,UDP区别
9.进程通信的几种方式(管道,有名管道,信号,信号量,共享内存,消息队列,套接字)
10.分析他们的区别,用于那些场景
11.链表倒数第k个数,程序思路
12.快排思路
没有手撕代码
等了一会然后通知二面
二面技术面,首先自我介绍,然后介绍项目
项目里面有多线程然后一直追问细节,二面一点紧张,答得不好。
1.项目里面用到了C 什么新特性(太抽象,答得很差)
2.堆栈的区别
3.TCP,UDP了解多少
4.B-树,B 树区别和原理,效率,应用场景,写过代码没,项目里面有没有用到(不会,没有用到)
5.项目里面除了vector还用到那些数据结构
6.红黑树
二面答得不好,有些问题太抽象了就懵逼了,面试官说计算机基础不行,数据结构了解太差。
二面十分钟后,电话通知凉凉。
总的来说,还是自己太菜,计算机基础了解的还不够,也没有系统的学习,后面继续准备秋招吧,希望后面会有好运。共勉。|