伯禹学习平台6
学习笔记Task9
目标检测基础
目标检测的定义,专业术语什么的就不讲了,教材都讲的很好,教材比较难理解的是它的实现部分,着重描述。
边界框
这种就是边界框的形式,标出了目标在图片的位置,一般边界框的格式有两种,1.(左上x, 左上y, 右下x, 右下y),2.(左上x, 左上y, 宽, 高),看需求使用。

锚框
目标检测算法通常会在输入图像中采样大量的区域,然后判断这些区域中是否包含我们感兴趣的目标,并调整区域边缘从而更准确地预测目标的真实边界框(ground-truth bounding box)。不同的模型使用的区域采样方法可能不同。这里我们介绍其中的一种方法:它以每个像素为中心生成多个大小和宽高比(aspect ratio)不同的边界框。这些边界框被称为锚框(anchor box)。我们将在后面基于锚框实践目标检测。(原文讲的挺好的,直接贴了)
生成多个锚框
假设输入图像高为 h ,宽为 w 。我们分别以图像的每个像素为中心生成不同形状的锚框。设大小为 s∈(0,1] 且宽高比为 r>0 ,那么锚框的宽和高将分别为 wsr√ 和 hs/r√ 。当中心位置给定时,已知宽和高的锚框是确定的。
下面我们分别设定好一组大小 s1,…,sn 和一组宽高比 r1,…,rm 。如果以每个像素为中心时使用所有的大小与宽高比的组合,输入图像将一共得到 whnm 个锚框。虽然这些锚框可能覆盖了所有的真实边界框,但计算复杂度容易过高。因此,我们通常只对包含 s1 或 r1 的大小与宽高比的组合感兴趣,即
(s1,r1),(s1,r2),…,(s1,rm),(s2,r1),(s3,r1),…,(sn,r1).
也就是说,以相同像素为中心的锚框的数量为 n+m−1 。对于整个输入图像,我们将一共生成 wh(n+m−1) 个锚框。(先上原文)
实现步骤:
1.先得到n+m-1个框(大小和宽高比的组合)
2.再得到n+m-1个框的宽高sr√ ,s/r√(宽高/2就是左上角右下角相对每个像素中心点的位移)
3.得到每个像素的坐标点
4.坐标点和位移结合起来就是(左上x, 左上y, 右下x, 右下y),
anchors = shifts.reshape((-1, 1, 4)) + base_anchors.reshape((1, -1, 4))
教材pytorch实现坐标和位移结合所使用的方法,各自reshape后相加就会把相同的那一维元素进行相加,不相同的维度则保留,shape是(元素个数,锚框个数n+m-1, 四个元素左上右下)。
5.最后reshape成(1, 总锚框个数w * h(n+m-1), 四个元素),1的原因是每个batch_size的锚框位置大小都是一样的。
交并比
交并比的定义没什么好说的,用来衡量采样的锚框和真实框之间的相似度,直接上图。

标注训练集的锚框
在训练集中,我们将每个锚框视为一个训练样本。为了训练目标检测模型,我们需要为每个锚框标注两类标签:一是锚框所含目标的类别,简称类别;二是真实边界框相对锚框的偏移量,简称偏移量(offset)。在目标检测时,我们首先生成多个锚框,然后为每个锚框预测类别以及偏移量,接着根据预测的偏移量调整锚框位置从而得到预测边界框,最后筛选需要输出的预测边界框。
我们知道,在目标检测的训练集中,每个图像已标注了真实边界框的位置以及所含目标的类别。在生成锚框之后,我们主要依据与锚框相似的真实边界框的位置和类别信息为锚框标注。那么,该如何为锚框分配与其相似的真实边界框呢?
假设图像中锚框分别为 A1,A2,…,Ana ,真实边界框分别为 B1,B2,…,Bnb ,且 na≥nb 。定义矩阵 X∈Rna×nb ,其中第 i 行第 j 列的元素 xij 为锚框 Ai 与真实边界框 Bj 的交并比。 首先,我们找出矩阵 X 中最大元素,并将该元素的行索引与列索引分别记为 i1,j1 。我们为锚框 Ai1 分配真实边界框 Bj1 。显然,锚框 Ai1 和真实边界框 Bj1 在所有的“锚框—真实边界框”的配对中相似度最高。接下来,将矩阵 X 中第 i1 行和第 j1 列上的所有元素丢弃。找出矩阵 X 中剩余的最大元素,并将该元素的行索引与列索引分别记为 i2,j2 。我们为锚框 Ai2 分配真实边界框 Bj2 ,再将矩阵 X 中第 i2 行和第 j2 列上的所有元素丢弃。此时矩阵 X 中已有两行两列的元素被丢弃。 依此类推,直到矩阵 X 中所有 nb 列元素全部被丢弃。这个时候,我们已为 nb 个锚框各分配了一个真实边界框。 接下来,我们只遍历剩余的 na−nb 个锚框:给定其中的锚框 Ai ,根据矩阵 X 的第 i 行找到与 Ai 交并比最大的真实边界框 Bj ,且只有当该交并比大于预先设定的阈值时,才为锚框 Ai 分配真实边界框 Bj 。
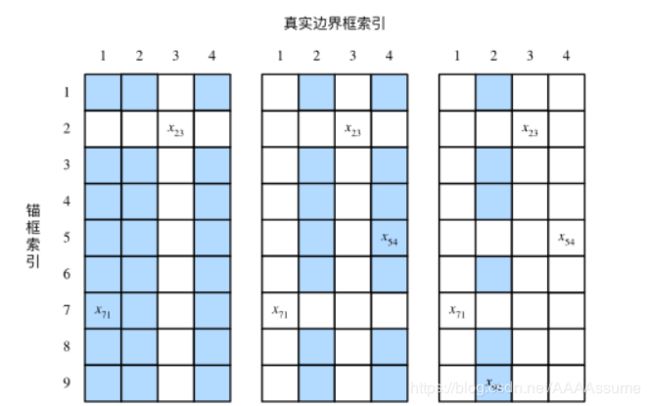
如图9.3(左)所示,假设矩阵 X 中最大值为 x23 ,我们将为锚框 A2 分配真实边界框 B3 。然后,丢弃矩阵中第2行和第3列的所有元素,找出剩余阴影部分的最大元素 x71 ,为锚框 A7 分配真实边界框 B1 。接着如图9.3(中)所示,丢弃矩阵中第7行和第1列的所有元素,找出剩余阴影部分的最大元素 x54 ,为锚框 A5 分配真实边界框 B4 。最后如图9.3(右)所示,丢弃矩阵中第5行和第4列的所有元素,找出剩余阴影部分的最大元素 x92 ,为锚框 A9 分配真实边界框 B2 。之后,我们只需遍历除去 A2,A5,A7,A9 的剩余锚框,并根据阈值判断是否为剩余锚框分配真实边界框。
现在我们可以标注锚框的类别和偏移量了。如果一个锚框 A 被分配了真实边界框 B ,将锚框 A 的类别设为 B 的类别,并根据 B 和 A 的中心坐标的相对位置以及两个框的相对大小为锚框 A 标注偏移量。由于数据集中各个框的位置和大小各异,因此这些相对位置和相对大小通常需要一些特殊变换,才能使偏移量的分布更均匀从而更容易拟合。设锚框 A 及其被分配的真实边界框 B 的中心坐标分别为 (xa,ya) 和 (xb,yb) , A 和 B 的宽分别为 wa 和 wb ,高分别为 ha 和 hb ,一个常用的技巧是将 A 的偏移量标注为

其中常数的默认值为 μx=μy=μw=μh=0,σx=σy=0.1,σw=σh=0.2 。如果一个锚框没有被分配真实边界框,我们只需将该锚框的类别设为背景。类别为背景的锚框通常被称为负类锚框,其余则被称为正类锚框。
(精简版)目标检测实际使用的训练样本是锚框而非真实框,成功匹配的锚框为正样本分类类别为匹配的类别,没有成功匹配的锚框为负样本分类类别为背景。匹配的规则有二:
1.先保证每一个真实框成功匹配一个锚框,直接找与该真实框交并比(IOU)最大的锚框。2.保证每一个真实框成功匹配一个锚框后还剩余大量的锚框,则设置一个阈值,若剩余的锚框和某个真实框的IOU超过该阈值则也和该真实框匹配。
其余未匹配的锚框就分为背景。
成功匹配的锚框类别标注为匹配的真实框的类别,并标注与该真实框之间的偏移值。未匹配的锚框则类别为0,偏移值为0.
输出预测边界框
(全部贴上)
在模型预测阶段,我们先为图像生成多个锚框,并为这些锚框一一预测类别和偏移量。随后,我们根据锚框及其预测偏移量得到预测边界框。当锚框数量较多时,同一个目标上可能会输出较多相似的预测边界框。为了使结果更加简洁,我们可以移除相似的预测边界框。常用的方法叫作非极大值抑制(non-maximum suppression,NMS)。
我们来描述一下非极大值抑制的工作原理。对于一个预测边界框 B ,模型会计算各个类别的预测概率。设其中最大的预测概率为 p ,该概率所对应的类别即 B 的预测类别。我们也将 p 称为预测边界框 B 的置信度。在同一图像上,我们将预测类别非背景的预测边界框按置信度从高到低排序,得到列表 L 。从 L 中选取置信度最高的预测边界框 B1 作为基准,将所有与 B1 的交并比大于某阈值的非基准预测边界框从 L 中移除。这里的阈值是预先设定的超参数。此时, L 保留了置信度最高的预测边界框并移除了与其相似的其他预测边界框。 接下来,从 L 中选取置信度第二高的预测边界框 B2 作为基准,将所有与 B2 的交并比大于某阈值的非基准预测边界框从 L 中移除。重复这一过程,直到 L 中所有的预测边界框都曾作为基准。此时 L 中任意一对预测边界框的交并比都小于阈值。最终,输出列表 L 中的所有预测边界框。
下面来看一个具体的例子。先构造4个锚框。简单起见,我们假设预测偏移量全是0:预测边界框即锚框。最后,我们构造每个类别的预测概率。
anchors = torch.tensor([[0.1, 0.08, 0.52, 0.92], [0.08, 0.2, 0.56, 0.95],
[0.15, 0.3, 0.62, 0.91], [0.55, 0.2, 0.9, 0.88]])
offset_preds = torch.tensor([0.0] * (4 * len(anchors)))
cls_probs = torch.tensor([[0., 0., 0., 0.,], # 背景的预测概率
[0.9, 0.8, 0.7, 0.1], # 狗的预测概率
[0.1, 0.2, 0.3, 0.9]]) # 猫的预测概率
在图像上打印预测边界框和它们的置信度。

fig = d2l.plt.imshow(img)
show_bboxes(fig.axes, anchors * bbox_scale,
['dog=0.9', 'dog=0.8', 'dog=0.7', 'cat=0.9'])
下面我们实现MultiBoxDetection函数来执行非极大值抑制。
from collections import namedtuple
Pred_BB_Info = namedtuple("Pred_BB_Info", ["index", "class_id", "confidence", "xyxy"])
def non_max_suppression(bb_info_list, nms_threshold = 0.5):
"""
非极大抑制处理预测的边界框
Args:
bb_info_list: Pred_BB_Info的列表, 包含预测类别、置信度等信息
nms_threshold: 阈值
Returns:
output: Pred_BB_Info的列表, 只保留过滤后的边界框信息
"""
output = []
# 先根据置信度从高到低排序
sorted_bb_info_list = sorted(bb_info_list, key = lambda x: x.confidence, reverse=True)
# 循环遍历删除冗余输出
while len(sorted_bb_info_list) != 0:
best = sorted_bb_info_list.pop(0)
output.append(best)
if len(sorted_bb_info_list) == 0:
break
bb_xyxy = []
for bb in sorted_bb_info_list:
bb_xyxy.append(bb.xyxy)
iou = compute_jaccard(torch.tensor([best.xyxy]),
torch.tensor(bb_xyxy))[0] # shape: (len(sorted_bb_info_list), )
n = len(sorted_bb_info_list)
sorted_bb_info_list = [sorted_bb_info_list[i] for i in range(n) if iou[i] <= nms_threshold]
return output
def MultiBoxDetection(cls_prob, loc_pred, anchor, nms_threshold = 0.5):
"""
# 按照「9.4.1. 生成多个锚框」所讲的实现, anchor表示成归一化(xmin, ymin, xmax, ymax).
https://zh.d2l.ai/chapter_computer-vision/anchor.html
Args:
cls_prob: 经过softmax后得到的各个锚框的预测概率, shape:(bn, 预测总类别数+1, 锚框个数)
loc_pred: 预测的各个锚框的偏移量, shape:(bn, 锚框个数*4)
anchor: MultiBoxPrior输出的默认锚框, shape: (1, 锚框个数, 4)
nms_threshold: 非极大抑制中的阈值
Returns:
所有锚框的信息, shape: (bn, 锚框个数, 6)
每个锚框信息由[class_id, confidence, xmin, ymin, xmax, ymax]表示
class_id=-1 表示背景或在非极大值抑制中被移除了
"""
assert len(cls_prob.shape) == 3 and len(loc_pred.shape) == 2 and len(anchor.shape) == 3
bn = cls_prob.shape[0]
def MultiBoxDetection_one(c_p, l_p, anc, nms_threshold = 0.5):
"""
MultiBoxDetection的辅助函数, 处理batch中的一个
Args:
c_p: (预测总类别数+1, 锚框个数)
l_p: (锚框个数*4, )
anc: (锚框个数, 4)
nms_threshold: 非极大抑制中的阈值
Return:
output: (锚框个数, 6)
"""
pred_bb_num = c_p.shape[1]
anc = (anc + l_p.view(pred_bb_num, 4)).detach().cpu().numpy() # 加上偏移量
confidence, class_id = torch.max(c_p, 0)
confidence = confidence.detach().cpu().numpy()
class_id = class_id.detach().cpu().numpy()
pred_bb_info = [Pred_BB_Info(
index = i,
class_id = class_id[i] - 1, # 正类label从0开始
confidence = confidence[i],
xyxy=[*anc[i]]) # xyxy是个列表
for i in range(pred_bb_num)]
# 正类的index
obj_bb_idx = [bb.index for bb in non_max_suppression(pred_bb_info, nms_threshold)]
output = []
for bb in pred_bb_info:
output.append([
(bb.class_id if bb.index in obj_bb_idx else -1.0),
bb.confidence,
*bb.xyxy
])
return torch.tensor(output) # shape: (锚框个数, 6)
batch_output = []
for b in range(bn):
batch_output.append(MultiBoxDetection_one(cls_prob[b], loc_pred[b], anchor[0], nms_threshold))
return torch.stack(batch_output)
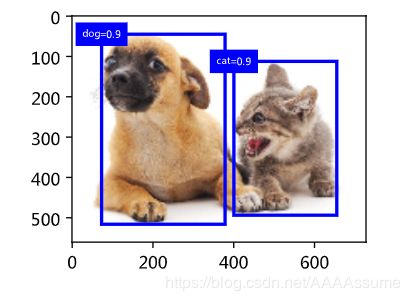
然后我们运行MultiBoxDetection函数并设阈值为0.5。这里为输入都增加了样本维。我们看到,返回的结果的形状为(批量大小, 锚框个数, 6)。其中每一行的6个元素代表同一个预测边界框的输出信息。第一个元素是索引从0开始计数的预测类别(0为狗,1为猫),其中-1表示背景或在非极大值抑制中被移除。第二个元素是预测边界框的置信度。剩余的4个元素分别是预测边界框左上角的 x 和 y 轴坐标以及右下角的 x 和 y 轴坐标(值域在0到1之间)。
output = MultiBoxDetection(
cls_probs.unsqueeze(dim=0), offset_preds.unsqueeze(dim=0),
anchors.unsqueeze(dim=0), nms_threshold=0.5)
output
tensor([[[ 0.0000, 0.9000, 0.1000, 0.0800, 0.5200, 0.9200],
[-1.0000, 0.8000, 0.0800, 0.2000, 0.5600, 0.9500],
[-1.0000, 0.7000, 0.1500, 0.3000, 0.6200, 0.9100],
[ 1.0000, 0.9000, 0.5500, 0.2000, 0.9000, 0.8800]]])
fig = d2l.plt.imshow(img)
for i in output[0].detach().cpu().numpy():
if i[0] == -1:
continue
label = ('dog=', 'cat=')[int(i[0])] + str(i[1])
show_bboxes(fig.axes, [torch.tensor(i[2:]) * bbox_scale], label)
实践中,我们可以在执行非极大值抑制前将置信度较低的预测边界框移除,从而减小非极大值抑制的计算量。我们还可以筛选非极大值抑制的输出,例如,只保留其中置信度较高的结果作为最终输出。
多尺度目标检测
(教材)
我们在实验中以输入图像的每个像素为中心生成多个锚框。这些锚框是对输入图像不同区域的采样。然而,如果以图像每个像素为中心都生成锚框,很容易生成过多锚框而造成计算量过大。举个例子,假设输入图像的高和宽分别为561像素和728像素,如果以每个像素为中心生成5个不同形状的锚框,那么一张图像上则需要标注并预测200多万个锚框( 561×728×5 )。
减少锚框个数并不难。一种简单的方法是在输入图像中均匀采样一小部分像素,并以采样的像素为中心生成锚框。此外,在不同尺度下,我们可以生成不同数量和不同大小的锚框。值得注意的是,较小目标比较大目标在图像上出现位置的可能性更多。举个简单的例子:形状为 1×1 、 1×2 和 2×2 的目标在形状为 2×2 的图像上可能出现的位置分别有4、2和1种。因此,当使用较小锚框来检测较小目标时,我们可以采样较多的区域;而当使用较大锚框来检测较大目标时,我们可以采样较少的区域。
图像风格迁移
图像分类1案例
现在,我们将运用在前面几节中学到的知识来参加Kaggle竞赛,该竞赛解决了CIFAR-10图像分类问题。比赛网址是https://www.kaggle.com/c/cifar-10
使用了torchvision.transforms集成的图像增强,torchvision.datasets.ImageFloder, torch.utils.data.DataLoader导入数据集,网络则使用了resnet-18

class ResidualBlock(nn.Module): # 我们定义网络时一般是继承的torch.nn.Module创建新的子类
def __init__(self, inchannel, outchannel, stride=1):
super(ResidualBlock, self).__init__()
#torch.nn.Sequential是一个Sequential容器,模块将按照构造函数中传递的顺序添加到模块中。
self.left = nn.Sequential(
nn.Conv2d(inchannel, outchannel, kernel_size=3, stride=stride, padding=1, bias=False),
# 添加第一个卷积层,调用了nn里面的Conv2d()
nn.BatchNorm2d(outchannel), # 进行数据的归一化处理
nn.ReLU(inplace=True), # 修正线性单元,是一种人工神经网络中常用的激活函数
nn.Conv2d(outchannel, outchannel, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(outchannel)
)
self.shortcut = nn.Sequential()
if stride != 1 or inchannel != outchannel:
self.shortcut = nn.Sequential(
nn.Conv2d(inchannel, outchannel, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(outchannel)
)
# 便于之后的联合,要判断Y = self.left(X)的形状是否与X相同
def forward(self, x): # 将两个模块的特征进行结合,并使用ReLU激活函数得到最终的特征。
out = self.left(x)
out += self.shortcut(x)
out = F.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, ResidualBlock, num_classes=10):
super(ResNet, self).__init__()
self.inchannel = 64
self.conv1 = nn.Sequential( # 用3个3x3的卷积核代替7x7的卷积核,减少模型参数
nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(),
)
self.layer1 = self.make_layer(ResidualBlock, 64, 2, stride=1)
self.layer2 = self.make_layer(ResidualBlock, 128, 2, stride=2)
self.layer3 = self.make_layer(ResidualBlock, 256, 2, stride=2)
self.layer4 = self.make_layer(ResidualBlock, 512, 2, stride=2)
self.fc = nn.Linear(512, num_classes)
def make_layer(self, block, channels, num_blocks, stride):
strides = [stride] + [1] * (num_blocks - 1) #第一个ResidualBlock的步幅由make_layer的函数参数stride指定
# ,后续的num_blocks-1个ResidualBlock步幅是1
layers = []
for stride in strides:
layers.append(block(self.inchannel, channels, stride))
self.inchannel = channels
return nn.Sequential(*layers)
def forward(self, x):
out = self.conv1(x)
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
out = F.avg_pool2d(out, 4)
out = out.view(out.size(0), -1)
out = self.fc(out)
return out
def ResNet18():
return ResNet(ResidualBlock)
# 定义是否使用GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 超参数设置
EPOCH = 20 #遍历数据集次数
pre_epoch = 0 # 定义已经遍历数据集的次数
LR = 0.1 #学习率
# 模型定义-ResNet
net = ResNet18().to(device)
# 定义损失函数和优化方式
criterion = nn.CrossEntropyLoss() #损失函数为交叉熵,多用于多分类问题
optimizer = optim.SGD(net.parameters(), lr=LR, momentum=0.9, weight_decay=5e-4)
#优化方式为mini-batch momentum-SGD,并采用L2正则化(权重衰减)
# 训练
if __name__ == "__main__":
print("Start Training, Resnet-18!")
num_iters = 0
for epoch in range(pre_epoch, EPOCH):
print('\nEpoch: %d' % (epoch + 1))
net.train()
sum_loss = 0.0
correct = 0.0
total = 0
for i, data in enumerate(trainloader, 0):
#用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,
#下标起始位置为0,返回 enumerate(枚举) 对象。
num_iters += 1
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad() # 清空梯度
# forward + backward
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
sum_loss += loss.item() * labels.size(0)
_, predicted = torch.max(outputs, 1) #选出每一列中最大的值作为预测结果
total += labels.size(0)
correct += (predicted == labels).sum().item()
# 每20个batch打印一次loss和准确率
if (i + 1) % 20 == 0:
print('[epoch:%d, iter:%d] Loss: %.03f | Acc: %.3f%% '
% (epoch + 1, num_iters, sum_loss / (i + 1), 100. * correct / total))
print("Training Finished, TotalEPOCH=%d" % EPOCH)