华为机试,1-20题,python版
(华为机试(牛客网),1-20题,python版)
1.计算字符串最后一个单词的长度
a = input().split()
b = a.pop()
print(len(b))
2.写出一个程序,接受一个由字母和数字组成的字符串,和一个字符,然后输出输入字符串中含有该字符的个数。不区分大小写。
a = input().lower()
b = input().lower()
c = a.count(b)
print(c)
3明明的随机数
明明想在学校中请一些同学一起做一项问卷调查,为了实验的客观性,他先用计算机生成了N个1到1000之间的随机整数(N≤1000),对于其中重复的数字,只保留一个,把其余相同的数去掉,不同的数对应着不同的学生的学号。然后再把这些数从小到大排序,按照排好的顺序去找同学做调查。请你协助明明完成“去重”与“排序”的工作(同一个测试用例里可能会有多组数据,希望大家能正确处理)。
while True:
try:
n = int(input())
myset = set()
l=[]
for i in range(n):
m = input()
myset.add(m)
for i in myset:
l.append(int(i))
l.sort()
for i in l:
print(i)
except:
break
4.字符串拆分
•连续输入字符串,请按长度为8拆分每个字符串后输出到新的字符串数组;
•长度不是8整数倍的字符串请在后面补数字0,空字符串不处理。
def f(zifu):#定义函数,两次测试则可以调用两次
if len(zifu)<8:
zifu = zifu +'0'*(8-len(zifu))
print(zifu)
else:
while len(zifu)>8:#循环测试长度是否大于八
qian8 = zifu[:8]
print(qian8)
zifu = zifu[8:]#取去掉前8个的字符串作为新的字符串,循环判断是否长度大于8
print(zifu+'0'*(8-len(zifu)))#当跳出循环后说明,字符串长度已经不满8
return zifu
a = input()
b = input()
f(a)
f(b)
5.进制转换
写出一个程序,接受一个十六进制的数,输出该数值的十进制表示。(多组同时输入 )
while True:
try:
a = input()
b = int(a,16)
print(b)
except:
break
6.质数因子
功能:输入一个正整数,按照从小到大的顺序输出它的所有质因子(重复的也要列举)(如180的质因子为2 2 3 3 5 )
a = int(input())
if a == 1:
print(str(a) + ' ')
i=2
while True:
yushu = a%i#从2开始做除法,定义余数变量
if yushu == 0:
a = a//i#余数为零,则令商作为被除数,继续除以2
print(str(i)+' ',end='')#输出不换行end = ’‘
else:
i+=1#若余数不为0.则除数加1
if a==1:
break
7.取近似值
写出一个程序,接受一个正浮点数值,输出该数值的近似整数值。如果小数点后数值大于等于5,向上取整;小于5,则向下取整。
a = float(input())
b = int(a)
c = a-b
if c>=0.5:
b+=1
print(b)
else:
print(b)
方法二:
a = input().split('.')#表示以小数点进行分隔输入
if int(a[1])>=5:
print(int(a[0])+1)
else:
print(int(a[0]))
8.数据表记录
数据表记录包含表索引和数值(int范围的整数),请对表索引相同的记录进行合并,即将相同索引的数值进行求和运算,输出按照key值升序进行输出。
a = int(input())
dic = {}
for i in range(a):
m, n = map(int, input().split())
if m in dic.keys():
dic[m]+=n
else:
dic[m]=n
l = sorted(dic.keys())#对字典的键进行排序
for i in l:#从排过序的键中,依次取值
print(str(i)+ ' ' + str(dic[i]))
9.提取不重复的整数
输入一个int型整数,按照从右向左的阅读顺序,返回一个不含重复数字的新的整数。
a = int(input())
b = str(a)[::-1]
res=''
for i in b:
if i not in res:
res+=i
print(res)
10.字符个数统计
编写一个函数,计算字符串中含有的不同字符的个数。字符在ACSII码范围内(0~127),换行表示结束符,不算在字符里。不在范围内的不作统计。注意是不同的字符。
a = input().split()
r = ''
count = 0
for i in a:
r+=str(i)
re = set(r)
for i in re:
if ord(i) in range(128):
count+=1
print(count)
也可以直接使用set()函数中的.update()命令
str1 = input()
count = 0
myset = set()
myset.update(str1)#将输入abc拆成‘a',’b‘,’c'三个元素放入集合
for i in myset:
if ord(i) in range(128):# ord()命令将ACSLL码转为数字
count += 1
print(count)
11.数字颠倒
描述:
输入一个整数,将这个整数以字符串的形式逆序输出
程序不考虑负数的情况,若数字含有0,则逆序形式也含有0,如输入为100,则输出为001
a = input()
print(str(a)[::-1])
12.字符串反转
写出一个程序,接受一个字符串,然后输出该字符串反转后的字符串。(字符串长度不超过1000)
a=input()
print(str(a)[::-1])
13.句子逆序
将一个英文语句以单词为单位逆序排放。例如“I am a boy”,逆序排放后为“boy a am I”
所有单词之间用一个空格隔开,语句中除了英文字母外,不再包含其他字符
a = input().split()
b = a[::-1]
print(' '.join(b))
14.字符串连接最长路径
给定n个字符串,请对n个字符串按照字典序排列。
a = int(input())
l =[]
for i in range(a):
b = input()
l.append(b)
e=sorted(l)
for i in e:
print(i)
15.求int型的正整数在内存中1的个数
输入一个int型的正整数,计算出该int型数据在内存中存储时1的个数。(进制转换)
a = int(input())
b = bin(a)[2:]
c='1'
print(b.count(c))
16.购物单
王强今天很开心,公司发给N元的年终奖。王强决定把年终奖用于购物,他把想买的物品分为两类:主件与附件,附件是从属于某个主件的,下表就是一些主件与附件的例子:
主件 附件
电脑 打印机,扫描仪
书柜 图书
书桌 台灯,文具
工作椅 无
如果要买归类为附件的物品,必须先买该附件所属的主件。每个主件可以有 0 个、 1 个或 2 个附件。附件不再有从属于自己的附件。王强想买的东西很多,为了不超出预算,他把每件物品规定了一个重要度,分为 5 等:用整数 1 ~ 5 表示,第 5 等最重要。他还从因特网上查到了每件物品的价格(都是 10 元的整数倍)。他希望在不超过 N 元(可以等于 N 元)的前提下,使每件物品的价格与重要度的乘积的总和最大。
设第 j 件物品的价格为 v[j] ,重要度为 w[j] ,共选中了 k 件物品,编号依次为 j 1 , j 2 ,……, j k ,则所求的总和为:
v[j 1 ]*w[j 1 ]+v[j 2 ]*w[j 2 ]+ … +v[j k ]*w[j k ] 。(其中 * 为乘号)
请你帮助王强设计一个满足要求的购物单。
n, m = map(int, input().split())
# 创建二维数组,行数为M,列数为4,且初始值均为0
v = [[0 for i in range(4)] for j in range(m+1)] # 创建一个(m+1)x4的表格,v表示钱数
w = [[0 for i in range(4)] for j in range(m+1)] # 创建一个(m+1)x4的表格,因为有m件物品,每个物品又可以放入四种情况,w用来表示钱和重要度的乘积
#建表时,必须多建立一个空行
f = [0]*(n+1)#价格从n减到0,所以需要n+1个空
n=n//10
for i in range(1,m+1): # 一共m行输入,遍历输入。只能用range(1,m+1)
x, y, z = map(int, input().split()) # x:钱数,y:重要度,z:主件号
x=x//10
#依次从m个物品中取,并且判断其是主件还是附件,分别填入四种情况,假设这四种情况为四个筒,若是主件则每个桶填一个
#若是附件1则填入b,d两个筒子
if z == 0: # 当前物品为主件
for t in range(4): # 将主件物品x的钱数、钱数与重要度的乘积,放入四个桶中
v[i][t], w[i][t] = v[i][t] + x, w[i][t] + x * y
elif v[z][1] == v[z][0]: # 如果a==b,添加附件1,即表示目前还未添加附件,所以添加的附件作为附件1
# 将附件1放入对应的主件z的b桶和d桶中
v[z][1], w[z][1] = v[z][1] + x, w[z][1] + x * y
v[z][3], w[z][3] = v[z][3] + x, w[z][3] + x * y
else: # 添加附件2,因为每个筒子只能装两个附件,之前有一个附件了,这个就只能是附件2
# 将附件2放入对应的主件z的c桶和d桶中
v[z][2], w[z][2] = v[z][2] + x, w[z][2] + x * y
v[z][3], w[z][3] = v[z][3] + x, w[z][3] + x * y
for i in range(1,m+1): # 遍历物品
for j in range(n, -1, -1): # 遍历钱数,倒序
for k in range(4): # 遍历四个桶
if j >= v[i][k]: # 当前钱数大于物品i的k桶需要的钱数
f[j] = max(f[j], f[j - v[i][k]] + w[i][k]) # 放或者不放,
print(10*f[n])
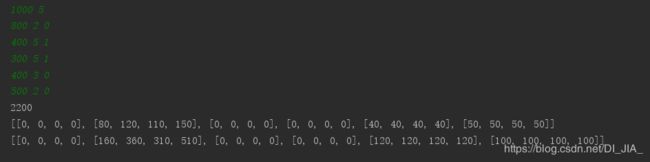 输入例子后,输出效果如上,为了更为直观,输出了v和w 两个列表
输入例子后,输出效果如上,为了更为直观,输出了v和w 两个列表
17.坐标移动
开发一个坐标计算工具, A表示向左移动,D表示向右移动,W表示向上移动,S表示向下移动。从(0,0)点开始移动,从输入字符串里面读取一些坐标,并将最终输入结果输出到输出文件里面。
输入:
合法坐标为A(或者D或者W或者S) + 数字(两位以内)
坐标之间以;分隔。
非法坐标点需要进行丢弃。如AA10; A1A; (%$); YAD; 等。
下面是一个简单的例子 如:
A10;S20;W10;D30;X;A1A;B10A11;;A10;
处理过程:
起点(0,0)
- A10 = (-10,0)
- S20 = (-10,-20)
- W10 = (-10,-10)
- D30 = (20,-10)
- x = 无效
- A1A = 无效
- B10A11 = 无效
- 一个空 不影响
- A10 = (10,-10)
结果 (10, -10)
#str.startswith检查字符串是否是以指定子字符串开头,直接用str[0]当字符串为空时存在越界。
#str.isdigit检测字符串是否只由数字组成
while True:
try:
a = input().split(";")#字符串输入,以;隔开
cd = [0,0]
for i in a:
if i.startswith("A") and len(i)<=3 and i[1:].isdigit():#.startswith()检查是否以指定字符开头.isdigit()检查字符串是否只由数字组成
cd[0] += - int(i[1:])
elif i.startswith("D") and len(i)<=3 and i[1:].isdigit():
cd[0] += int(i[1:])
elif i.startswith("W") and len(i)<=3 and i[1:].isdigit():
cd[1] += int(i[1:])
elif i.startswith("S") and len(i)<=3 and i[1:].isdigit():
cd[1] += - int(i[1:])
else:
continue
print("{0},{1}".format(cd[0], cd[1]))#格式化输出,索引是根据format后的数据进行的,前面的{0},{1}表示索引,索引必须要加双引号,{0}显示cd[0],{1}显示cd[1]
except:
break
18.识别有效的IP地址
请解析IP地址和对应的掩码,进行分类识别。要求按照A/B/C/D/E类地址归类,不合法的地址和掩码单独归类。
所有的IP地址划分为 A,B,C,D,E五类
A类地址1.0.0.0~126.255.255.255;
B类地址128.0.0.0~191.255.255.255;
C类地址192.0.0.0~223.255.255.255;
D类地址224.0.0.0~239.255.255.255;
E类地址240.0.0.0~255.255.255.255
私网IP范围是:
10.0.0.0~10.255.255.255
172.16.0.0~172.31.255.255
192.168.0.0~192.168.255.255
子网掩码为二进制下前面是连续的1,然后全是0。(例如:255.255.255.32就是一个非法的掩码)
注意二进制下全是1或者全是0均为非法
注意:
- 类似于【0...】和【127...】的IP地址不属于上述输入的任意一类,也不属于不合法ip地址,计数时可以忽略
- 私有IP地址和A,B,C,D,E类地址是不冲突的
import re
def isLegalIP(IP):
if not IP or IP == "":
return False
pattern = re.compile(r"^\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}$")
match = pattern.match(IP)
if not match:
return False
nums = IP.split(".")
for num in nums:
n = int(num)
if n<0 or n>255:
return False
return True
def CatagoryIP(IP):
if not IP or IP == "":
return False
nums = IP.split(".")
# A
if 126 >= int(nums[0]) >= 1:
return "A"
# B
if 191 >= int(nums[0]) >= 128:
return "B"
# C
if 223 >= int(nums[0]) >= 192:
return "C"
# D
if 239 >= int(nums[0]) >= 224:
return "D"
# E
if 255 >= int(nums[0]) >= 240:
return "E"
return False
def isPrivateIP(IP):
if not IP or IP == "":
return False
nums = IP.split(".")
if int(nums[0]) == 10:
return True
if int(nums[0]) == 172:
if 31 >= int(nums[1]) >= 16:
return True
if int(nums[0]) == 192 and int(nums[1]) == 168:
return True
return False
def isLegalMaskCode(Mask):
if not Mask or Mask == "":
return False
if not isLegalIP(Mask):
return False
binaryMask = "".join(map(lambda x: bin(int(x))[2:].zfill(8), Mask.split(".")))
indexOfFirstZero = binaryMask.find("0")
indexOfLastOne = binaryMask.rfind("1")
if indexOfLastOne > indexOfFirstZero:
return False
return True
try:
A, B, C, D, E, Err, P = [0, 0, 0, 0, 0, 0, 0]
while True:
s = raw_input()
IP, Mask = s.split("~")
if not isLegalIP(IP) or not isLegalMaskCode(Mask):
Err += 1
else:
if isPrivateIP(IP):
P += 1
cat = CatagoryIP(IP)
if cat == "A":
A += 1
if cat == "B":
B += 1
if cat == "C":
C += 1
if cat == "D":
D += 1
if cat == "E":
E += 1
except:
print (A, B, C, D, E, Err, P)
pass
19.简单的错误记录
开发一个简单错误记录功能小模块,能够记录出错的代码所在的文件名称和行号。
处理:
1、 记录最多8条错误记录,循环记录(或者说最后只输出最后出现的八条错误记录),对相同的错误记录(净文件名(保留最后16位)称和行号完全匹配)只记录一条,错误计数增加;
2、 超过16个字符的文件名称,只记录文件的最后有效16个字符;
3、 输入的文件可能带路径,记录文件名称不能带路径。
dic = dict()#创建空字典,可以之间用dict[name] = 'file',生成name 和 ‘file’的键值对
name_lines = []#创建文件列表
while True:
try:
lst = list(input().split())#将输入转化列表,split()即表示以空格划分,即将文件名与行数分割,lst[0]为文件名,lst[1]为代码行数
nam = lst[0]#取出列表的第一项,即取出文件名字
name = nam.split('\\')[-1][-16:]#取文件分割最后的一个字符,即取文件名字。取名字的最后16个字符
name_line = name + ' ' + lst[1] #将文件名字 和 代码行数都存入name_line,中间用空格间隔
if name_line not in dic:
dic[name_line] = 1
else:
dic[name_line] += 1
if name_line not in name_lines:
name_lines.append(name_line)
except:
for item in name_lines[-8:]:
print(item + " " + str(dic[item]))
break
20.密码验证合格程序
密码要求:
1.长度超过8位
2.包括大小写字母.数字.其它符号,以上四种至少三种
3.不能有相同长度超2的子串重复
说明:长度超过2的子串
import re
while True:
try:
s,li = input(),[]
# 1.长度超过8位
if len(s)<9:
print('NG')
else:
# 2.包括大小写字母.数字.其它符号,以上四种至少三种
count = 0
if re.search('[0-9]',s):
count += 1
if re.search('[A-Z]',s):
count += 1
if re.search('[a-z]',s):
count += 1
if re.search('[^0-9A-Za-z]',s):
count += 1
# 3.不能有相同长度超2的子串重复
for i in range(len(s)-2):
li.append(s[i:i+3])
len1 = len(li)
len2 = len(set(li))
if count > 2 and len1==len2:
print('OK')
else:
print('NG')
except:
break