TensorFlow高级API系列(三):Dataset API
前言
tf.data非常的好用,这里不多说,如果你停留在placeholder,feed_dict,你可能对这篇博客并不感兴趣。如果在处理大规模数据,tf.data就极其好用了。
从内存里面读取数据
我们先放代码,再慢慢解读
import tensorflow as tf
import numpy as np
dataset = tf.data.Dataset.from_tensor_slices(np.array([1.0, 2.0, 3.0, 4.0, 5.0]))
#如何取出数据呢?
iterator = dataset.make_one_shot_iterator()
one_element = iterator.get_next()
with tf.Session() as sess:
for i in range(5):
print(sess.run(one_element))
从代码中我们可以看出,one_element本质上还是个tensorflow,需要sess才能打印出结果。
tf.data.Dataset.from_tensor_slices的功能不止如此,它的真正作用是切分传入Tensor的第一个维度,生成相应的dataset。
dataset = tf.data.Dataset.from_tensor_slices(np.random.uniform(size=(5, 2)))
传入的数值是一个矩阵,它的形状为(5, 2),tf.data.Dataset.from_tensor_slices就会切分它形状上的第一个维度,最后生成的dataset中一个含有5个元素,每个元素的形状是(2, ),即每个元素是矩阵的一行。
从dict中构建dataset
dataset = tf.data.Dataset.from_tensor_slices(
{
"a": np.array([1.0, 2.0, 3.0, 4.0, 5.0]),
"b": np.random.uniform(size=(5, 2))
}
)
这时函数会分别切分"a"中的数值以及"b"中的数值,最终dataset中的一个元素就是类似于{“a”: 1.0, “b”: [0.9, 0.1]}的形式。
从文件中读取数据
大部分时间,我们是需要从文件中读取数据的,不可能总是从内存里面读取数据。这也是tf.data设计的初衷。目前Dataset API提供了三种从文件读取数据并创建Dataset的方式,分别用来读取不同存储格式的文件
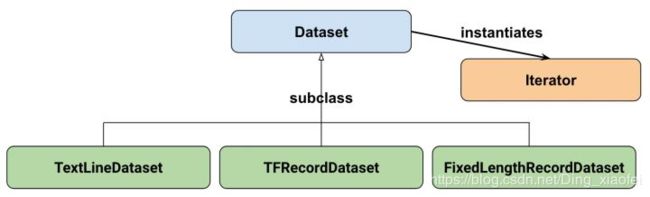
常用的两个接口是前两个。
tf.data.TextLineDataset():这个函数的输入是一个文件的列表,输出是一个dataset。dataset中的每一个元素就对应了文件中的一行。可以使用这个函数来读入CSV文件。
tf.data.TFRecordDataset():顾名思义,这个函数是用来读TFRecord文件的,dataset中的每一个元素就是一个TFExample。
tf.data.FixedLengthRecordDataset():这个函数的输入是一个文件的列表和一个record_bytes,之后dataset的每一个元素就是文件中固定字节数record_bytes的内容。通常用来读取以二进制形式保存的文件,如CIFAR10数据集就是这种形式。这个接口我没有使用过,之后有机会再补充。
后面会有代码详细介绍这几个接口的使用。这里的接口都是可以直接读取HDFS上的数据的。
DataSet的常用变换
一个Dataset通过数据变换操作可以生成一个新的Dataset。下面介绍数据格式变换、过滤、数据打乱、生产batch和epoch等常用Transformation操作。
(1)map操作
这个操作很有用,基本读数据都会用到。
map接收一个函数,Dataset中的每个元素都会被当作这个函数的输入,并将函数返回值作为新的Dataset,如我们可以对dataset中每个元素的值取平方:
dataset = tf.data.Dataset.from_tensor_slices(np.array([1.0, 2.0, 3.0, 4.0, 5.0]))
dataset = dataset.map(lambda x: x * x) # 1.0, 4.0, 9.0, 16.0, 25.0
(2)filter操作
过滤操作
filter操作可以过滤掉dataset不满足条件的元素,它接受一个布尔函数作为参数,dataset中的每个元素都作为该布尔函数的参数,布尔函数返回True的元素保留下来,布尔函数返回False的元素则被过滤掉。
dataset = dataset.filter(filter_func)
(3)shuffle
shuffle功能为打乱dataset中的元素,它有一个参数buffer_size,表示打乱时使用的buffer的大小:
dataset = dataset.shuffle(buffer_size=10000)
(4)repeat
repeat的功能就是将整个序列重复多次,主要用来处理机器学习中的epoch,假设原先的数据是一个epoch,使用repeat(5)就可以将之变成5个epoch:
dataset = dataset.repeat(5)
如果直接调用repeat()的话,生成的序列就会无限重复下去,没有结束,因此也不会抛出tf.errors.OutOfRangeError异常。很多代码会直接使用这个,主要原因是训练步数已经设置好了,数据可以一直重复
(5)batch
batch就是将多个元素组合成batch,如下面的程序将dataset中的每个元素组成了大小为32的batch:
dataset = dataset.batch(32)
需要注意的是,必须要保证dataset中每个元素拥有相同的shape才能调用batch方法,否则会抛出异常。在调用map方法转换元素格式的时候尤其要注意这一点。
实战代码
这里我会人造一些数据来演示代码。
解析csv文件
这种文件格式在我们平时做数据处理的时候经常遇到。
一般会使用tf.decode_csv来处理。我们先看一下这个接口的接受的一些参数,这个能够帮你方便的处理一些特殊情况。
大家可以先看一下官方api文档,相信会有帮助https://tensorflow.google.cn/api_docs/python/tf/compat/v1/decode_csv?hl=en
columns_name = ["field1", "field2", "field3", "label"]
columns_default = [[""], [""], [29], [1.0]]
def parse_csv(value):
columns = tf.decode_csv(value, record_defaults=columns_default, field_delim=',')
features = dict(zip(columns_name, columns))
labels = features.pop('label')
return features, labels
data_file = "../data/data_csv"
dataset = tf.data.TextLineDataset(data_file)
dataset = dataset.map(parse_csv, num_parallel_calls=10)
iterator = dataset.make_one_shot_iterator()
one_element = iterator.get_next()
with tf.Session() as sess:
for i in range(1):
print(sess.run(one_element))
数据你可以构建一个txt文件,写入下面数据
male,ding,29,1
male,xiao,27,0
我使用tf.decode_csv会出现一些bug,细心一点总是能够找到解决的方案。
解析特殊文本数据
这里蛮多坑的,要使用到python的接口,之前我找了蛮多教程,都很少有讲的清楚的。只有杨老师的那片博客写得十分清楚。
有时候我们的训练数据可能有特殊的格式,比如CVS文件其中某些字段是JSON格式的字符串,我们要把JSON字符串的内容也解析出来,这个时候tf.decode_csv函数就不够用了。
是时候请万能函数tf.py_func上场了,tf.py_func函数能够把一个任意的python函数封装成tensorflow的op,提供了极大的灵活性,其定义如下:
tf.py_func(
func,
inp,
Tout,
stateful=True,
name=None
)
tf.py_func的核心是一个func函数(由用户自己定义),该函数被封装成graph中的一个节点(op)。第二个参数inp是一个由Tensor组成的list,在执行时,inp的各个Tensor的值被取出来传给func作为参数。func的返回值会被tf.py_func转换为Tensors,这些Tensors的类型由Tout指定。当func只有一个返回值时,Tout是一个单独的tensorflow数据类型;当func函数有多个返回值时,Tout是一个tensorflow数据类型组成的元组或列表。参数stateful表示func函数是否有状态(产生副作用)
在使用过程中,有几个需要注意的地方:
- func函数的返回值类型一定要和Tout指定的tensor类型一致。
- tf.py_func中的func是脱离Graph的,在func中不能定义可训练的参数参与网络训练(反传)。
- tf.py_func操作只能在CPU上运行;如果使用分布式TensorFlow,tf.py_func操作必须放在与客户端相同进程的CPU设备上。
- tf.py_func操作返回的tensors是没有定义形状(shape)的,必须调用set_shape方法为各个返回值设置shape,才能参与后续的计算。
单个参数很好理解
def filter_func(line):
fields = line.decode().split("\t")
if len(fields) < 8:
return False
for field in fields:
if not field:
return False
return True
dataset = dataset.filter(lambda x: tf.py_func(filter_func, [x], tf.bool, False))
下面又一个复杂的例子,这个对我启示很大
该例子解析一个带有json格式字段的CSV文件,json字段被平铺开来和其他字段并列作为返回值。
import json
import numpy as np
import tensorflow as tf
def parse_line(line):
_COLUMNS = ["sellerId", "brandId", "cateId"]
_INT_COLUMNS = ["click", "productId", "matchType", "position", "hour"]
_FLOAT_COLUMNS = ["matchScore", "popScore", "brandPrefer", "catePrefer"]
_STRING_COLUMNS = ["phoneResolution", "phoneBrand", "phoneOs"]
_SEQ_COLUMNS = ["behaviorC1ids", "behaviorBids", "behaviorCids", "behaviorPids"]
def get_content(record):
import datetime
fields = record.decode().split("\t")
if len(fields) < 8:
raise ValueError("invalid record %s" % record)
for field in fields:
if not field:
raise ValueError("invalid record %s" % record)
fea = json.loads(fields[1])
if fea["time"]:
dt = datetime.datetime.fromtimestamp(fea["time"])
fea["hour"] = dt.hour
else:
fea["hour"] = 0
seq_len = 10
for x in _SEQ_COLUMNS:
sequence = fea.setdefault(x, [])
n = len(sequence)
if n < seq_len:
sequence.extend([-1] * (seq_len - n))
elif n > seq_len:
fea[x] = sequence[:seq_len]
seq_len = 20
elems = [np.int64(fields[2]), np.int64(fields[3]), np.int64(fields[4]), np.int64(fields[6]), fields[7]]
elems += [np.int64(fea.get(x, 0)) for x in _INT_COLUMNS]
elems += [np.float32(fea.get(x, 0.0)) for x in _FLOAT_COLUMNS]
elems += [fea.get(x, "") for x in _STRING_COLUMNS]
elems += [np.int64(fea[x]) for x in _SEQ_COLUMNS]
return elems
out_type = [tf.int64] * 4 + [tf.string] + [tf.int64] * len(_INT_COLUMNS) + [tf.float32] * len(_FLOAT_COLUMNS) + [
tf.string] * len(_STRING_COLUMNS) + [tf.int64] * len(_SEQ_COLUMNS)
result = tf.py_func(get_content, [line], out_type)
n = len(result) - len(_SEQ_COLUMNS)
for i in range(n):
result[i].set_shape([])
result[n].set_shape([10])
for i in range(n + 1, len(result)):
result[i].set_shape([20])
columns = _COLUMNS + _INT_COLUMNS + _FLOAT_COLUMNS + _STRING_COLUMNS + _SEQ_COLUMNS
features = dict(zip(columns, result))
labels = features.pop('click')
return features, labels
def my_input_fn(filenames, batch_size, shuffle_buffer_size):
dataset = tf.data.TextLineDataset(filenames)
dataset = dataset.filter(lambda x: tf.py_func(filter_func, [x], tf.bool, False))
dataset = dataset.map(parse_line, num_parallel_calls=100)
# Shuffle, repeat, and batch the examples.
if shuffle_buffer_size > 0:
dataset = dataset.shuffle(shuffle_buffer_size)
dataset = dataset.repeat().batch(batch_size)
return dataset
解析TFRECORD文件
直接使用上面的代码去解析一个原始的文本数据,是很耗时的,所以官方更加建议使用tfrecord格式
Tfrecord是tensorflow官方推荐的训练数据存储格式,它更容易与网络应用架构相匹配。
Tfrecord本质上是二进制的Protobuf数据,因而其读取、传输的速度更快。Tfrecord文件的每一条记录都是一个tf.train.Example的实例。tf.train.Example的proto格式的定义如下:
message Example {
Features features = 1;
};
message Features {
map<string, Feature> feature = 1;
};
message Feature {
oneof kind {
BytesList bytes_list = 1;
FloatList float_list = 2;
Int64List int64_list = 3;
}
};
这里关于这种格式,我写了另外两篇博客,有兴趣的可以参考一下
Tfrecord
使用tfrecord文件格式的另一个好处是数据结构统一,屏蔽了底层的数据结构。在类似于图像分类的任务中,原始数据是各个图片以单独的小文件的形式存在,label又以文件夹的形式存在,处理这样的数据比较麻烦,比如随机打乱,分batch等操作;而所有原始数据转换为一个或几个单独的tfrecord文件后处理起来就会比较方便。
来看看tensorflow读取tfrecord文件并转化为训练features和labels的代码:
def parse_exmp(serial_exmp):
features = {
"click": tf.FixedLenFeature([], tf.int64),
"behaviorBids": tf.FixedLenFeature([20], tf.int64),
"behaviorCids": tf.FixedLenFeature([20], tf.int64),
"behaviorC1ids": tf.FixedLenFeature([10], tf.int64),
"behaviorSids": tf.FixedLenFeature([20], tf.int64),
"behaviorPids": tf.FixedLenFeature([20], tf.int64),
"productId": tf.FixedLenFeature([], tf.int64),
"sellerId": tf.FixedLenFeature([], tf.int64),
"brandId": tf.FixedLenFeature([], tf.int64),
"cate1Id": tf.FixedLenFeature([], tf.int64),
"cateId": tf.FixedLenFeature([], tf.int64),
"tab": tf.FixedLenFeature([], tf.string),
"matchType": tf.FixedLenFeature([], tf.int64)
}
feats = tf.parse_single_example(serial_exmp, features=features)
labels = feats.pop('click')
return feats, labels
def train_input_fn(filenames, batch_size, shuffle_buffer_size):
dataset = tf.data.TFRecordDataset(filenames)
dataset = dataset.map(parse_exmp, num_parallel_calls=100)
# Shuffle, repeat, and batch the examples.
if shuffle_buffer_size > 0:
dataset = dataset.shuffle(shuffle_buffer_size)
dataset = dataset.repeat().batch(batch_size)
return dataset
这里我们再说说如何把原始数据转换为tfrecord文件格式,请参考下面的代码片段:
# 建立tfrecorder writer
writer = tf.python_io.TFRecordWriter('csv_train.tfrecords')
for i in xrange(train_values.shape[0]):
image_raw = train_values[i].tostring()
# build example protobuf
example = tf.train.Example(
features=tf.train.Features(feature={
'image_raw': tf.train.Feature(bytes_list=tf.train.BytesList(value=[image_raw])),
'label': tf.train.Feature(int64_list=tf.train.Int64List(value=[train_labels[i]]))
}))
writer.write(record=example.SerializeToString())
writer.close()
然而,大规模的训练数据用这种方式转换格式会比较低效,更好的实践是用hadoop或者spark这种分布式计算平台,并行实现数据转换任务。这里给出一个用Hadoop MapReduce编程模式转换为tfrecord文件格式的开源实现:Hadoop MapReduce InputFormat/OutputFormat for TFRecords。由于该实现指定了protobuf的版本,因而可能会跟自己真正使用的hadoop平台自己的protobuf版本不一致,hadoop在默认情况下总是优先使用HADOOP_HOME/lib下的jar包,从而导致运行时错误,遇到这种情况时,只需要设置mapreduce.task.classpath.user.precedence=true参数,优先使用自己指定版本的jar包即可。