使用YOLOv2和MobileNet_SSD检测算法与KCF对象跟踪器进行视频流的实时对象跟踪和检测
微信公众号:小白图像与视觉
关于技术、关注
yysilence00。有问题或建议,请公众号留言。
主题:使用YOLOv2和MobileNet_SSD检测算法与KCF对象跟踪器进行视频流的实时对象跟踪和检测
1、版本:opencv3.4.1 numpy imutils
2、载权重并将其放置在model_data /中
3、项目结构:
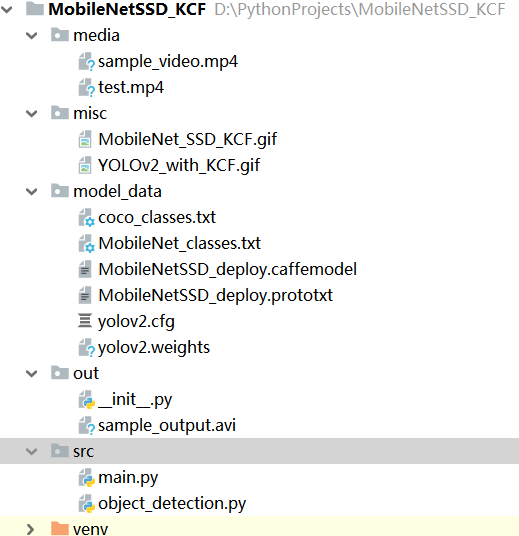
- media:存放视频文件
- misc:存放结构文件动图
- model_data:存放模型文件,这里使用coco和mobilenet数据集进行训练和测试,利用caffe框架进行网络参数训练获取模型
- out:存放结果
- src:存放源码
使用方法:先cd到项目文件中路径中,然后执行
python src/main.py -h
usage: main.py [-h] [--input INPUT] [--output OUTPUT] --model MODEL
[--config CONFIG] [--classes CLASSES] [--thr THR]
Object Detection and Tracking on Video Streams
optional arguments:
-h, --help show this help message and exit
--input INPUT Path to input image or video file. Skip this argument to
capture frames from a camera.
--output OUTPUT Path to save output as video file. Skip this argument if
you don't want the output to be saved.
--model MODEL Path to a binary file of model that contains trained weights.
It could be a file with extensions .caffemodel (Caffe) or
.weights (Darknet)
--config CONFIG Path to a text file of model that contains network
configuration. It could be a file with extensions
.prototxt (Caffe) or .cfg (Darknet)
--classes CLASSES Optional path to a text file with names of classes to
label detected objects.
--thr THR Confidence threshold for detection. Default: 0.35
然后在终端执行:
- yolov2
usge0:python src/main.py --model model_data/yolov2.weights --config model_data/yolov2.cfg --classes model_data/coco_classes.txt --input media/sample_video.mp4 --output out/sample_output.avi
-mobilenet_ssd
usge1:python src/main.py --model model_data/MobileNetSSD_deploy.caffemodel --config model_data/MobileNetSSD_deploy.prototxt --classes model_data/MobileNet_classes.txt --input media/sample_video.mp4 --output out/sample_output.avi
4、带有KCF跟踪器的YOLOv2
5、带有KCF跟踪器的MobileNet_SSD
6、完整项目代码
main.py
#usge0:python src/main.py --model model_data/yolov2.weights --config model_data/yolov2.cfg --classes model_data/coco_classes.txt --input media/sample_video.mp4 --output out/sample_output.avi
#usge1:python src/main.py --model model_data/MobileNetSSD_deploy.caffemodel --config model_data/MobileNetSSD_deploy.prototxt --classes model_data/MobileNet_classes.txt --input media/sample_video.mp4 --output out/sample_output.avi
"""
Author: Apoorva Vinod Gorur
Email: [email protected]
update Vesion:
Author: YanYong
Email: [email protected]
"""
import cv2 as cv
import argparse
import sys
import numpy as np
import time
from copy import deepcopy
import imutils
from object_detection import object_detector
#绘制预测框图
def drawPred(frame, objects_detected):
objects_list = list(objects_detected.keys())
for object_, info in objects_detected.items():
box = info[0]
confidence = info[1]
label = '%s: %.2f' % (object_, confidence)
p1 = (int(box[0]), int(box[1]))
p2 = (int(box[0] + box[2]), int(box[1] + box[3]))
#p1=(x=box[0],y=box[1])是矩阵左上点的坐标,w=box[2],h=box[3]是矩阵的宽和高 p2 =(box[0] + box[2]), int(box[1] + box[3])为右下角坐标
cv.rectangle(frame, p1, p2, (0, 255, 0))
left = int(box[0])
top = int(box[1])
labelSize, baseLine = cv.getTextSize(label, cv.FONT_HERSHEY_SIMPLEX, 0.5, 1)
top = max(top, labelSize[1])
cv.rectangle(frame, (left, top - labelSize[1]), (left + labelSize[0], top + baseLine), (255, 255, 255), cv.FILLED)
cv.putText(frame, label, (left, top), cv.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 0))
#后处理
def postprocess(frame, out, threshold, classes, framework):
frameHeight = frame.shape[0]
frameWidth = frame.shape[1]
objects_detected = dict()
if framework == 'Caffe':
# Network produces output blob with a shape 1x1xNx7 where N is a number of
# detections and an every detection is a vector of values
# [batchId, classId, confidence, left, top, right, bottom]
for detection in out[0, 0]:
confidence = detection[2]
if confidence > threshold:
left = int(detection[3] * frameWidth)
top = int(detection[4] * frameHeight)
right = int(detection[5] * frameWidth)
bottom = int(detection[6] * frameHeight)
#classId = int(detection[1]) - 1 # Skip background label
classId = int(detection[1])
i = 0
label = classes[classId]
label_with_num = str(label) + '_' + str(i)
while(True):
if label_with_num not in objects_detected.keys():
break
label_with_num = str(label) + '_' + str(i)
i = i+1
objects_detected[label_with_num] = [(int(left),int(top),int(right - left), int(bottom-top)),confidence]
print(label_with_num + ' at co-ordinates '+ str(objects_detected[label_with_num]))
else:
# Network produces output blob with a shape NxC where N is a number of
# detected objects and C is a number of classes + 4 where the first 4
# numbers are [center_x, center_y, width, height]
for detection in out:
confidences = detection[5:]
classId = np.argmax(confidences)
confidence = confidences[classId]
if confidence > threshold:
center_x = int(detection[0] * frameWidth)
center_y = int(detection[1] * frameHeight)
width = int(detection[2] * frameWidth)
height = int(detection[3] * frameHeight)
left = center_x - (width / 2)
top = center_y - (height / 2)
i = 0
label = classes[classId]
label_with_num = str(label) + '_' + str(i)
while(True):
if label_with_num not in objects_detected.keys():
break
label_with_num = str(label) + '_' + str(i)
i = i+1
objects_detected[label_with_num] = [(int(left),int(top),int(width),int(height)),confidence]
print(label_with_num + ' at co-ordinates '+ str(objects_detected[label_with_num]))
return objects_detected
#中途检测处理函数
def intermediate_detections(stream, predictor, threshold, classes):
_,frame = stream.read()
predictions = predictor.predict(frame)
objects_detected = postprocess(frame, predictions, threshold, classes, predictor.framework)
objects_list = list(objects_detected.keys())
print('Tracking the following objects', objects_list)
trackers_dict = dict()
#multi_tracker = cv.MultiTracker_create()
if len(objects_list) > 0:
trackers_dict = {key : cv.TrackerKCF_create() for key in objects_list}
for item in objects_list:
trackers_dict[item].init(frame, objects_detected[item][0])
return stream, objects_detected, objects_list, trackers_dict
#处理函数
def process(args):
objects_detected = dict()
#选择跟踪器
tracker_types = ['BOOSTING', 'MIL','KCF', 'TLD', 'MEDIANFLOW', 'GOTURN']
tracker_type = tracker_types[2] #选择KCF 类型
tracker = None
if tracker_type == 'BOOSTING':
tracker = cv.TrackerBoosting_create()
if tracker_type == 'MIL':
tracker = cv.TrackerMIL_create()
if tracker_type == 'KCF':
tracker = cv.TrackerKCF_create()
if tracker_type == 'TLD':
tracker = cv.TrackerTLD_create()
if tracker_type == 'MEDIANFLOW':
tracker = cv.TrackerMedianFlow_create()
if tracker_type == 'GOTURN':
tracker = cv.TrackerGOTURN_create()
#调用对象检测器(在自定义object_detection.py模块中导入自己写的类object_detector) 返回预测器
predictor = object_detector(args.model, args.config)#传入带参数的的类对象,调用后自动运行到_init_构造函数及后续api
stream = cv.VideoCapture(args.input if args.input else 0)
window_name = "Tracking in progress"
cv.namedWindow(window_name, cv.WINDOW_NORMAL)
cv.setWindowProperty(window_name, cv.WND_PROP_AUTOSIZE, cv.WINDOW_AUTOSIZE)
cv.moveWindow(window_name,10,10)
if args.output:
_, test_frame = stream.read()
height = test_frame.shape[0]
width = test_frame.shape[1]
fourcc = cv.VideoWriter_fourcc(*'XVID')#编解码器的fourcc 用于解析视频文件
#out = cv.VideoWriter(args.output,fourcc, 20.0, (640,480))
out = cv.VideoWriter(args.output,fourcc, 20.0, (width, height))
failTolerance = 0
if args.classes:
with open(args.classes, 'rt') as f:
classes = f.read().rstrip('\n').split('\n')
else:
classes = list(np.arange(0,100))
stream, objects_detected, objects_list, trackers_dict = intermediate_detections(stream, predictor, args.thr, classes)
while stream.isOpened():
grabbed, frame = stream.read()
if not grabbed:
break
timer = cv.getTickCount()
"""
#Did not use OpenCV's multitracker because of the restrivtive nature of its Python counterpart.
#If one tracker in the multitracker fails, there's no way to find out which tracker failed.
#There's no easy way to delete individual trackers in the multitracker object.
#Even when multitracker fails, bboxes will have old values, but 'ok' will be false
#if len(objects_list) > 0:
#ok, bboxes = multi_tracker.update(frame)
#bboxes = multi_tracker.getObjects()
#ok = multi_tracker.empty()
"""
print('Tracking - ',objects_list)
if len(objects_detected) > 0:
del_items = []
for obj,tracker in trackers_dict.items():
ok, bbox = tracker.update(frame)
if ok:
objects_detected[obj][0] = bbox
else:
print('Failed to track ', obj)
del_items.append(obj)
for item in del_items:
trackers_dict.pop(item)
objects_detected.pop(item)
fps = cv.getTickFrequency() / (cv.getTickCount() - timer)
if len(objects_detected) > 0:
drawPred(frame, objects_detected)
# Display FPS on frame
cv.putText(frame, "FPS : " + str(int(fps)), (100,50), cv.FONT_HERSHEY_SIMPLEX, 0.75, (50,170,50), 2)
else:
cv.putText(frame, 'Tracking Failure. Trying to detect more objects', (50,80), cv.FONT_HERSHEY_SIMPLEX, 0.75,(0,0,255),2)
stream, objects_detected, objects_list, trackers_dict = intermediate_detections(stream, predictor, args.thr, classes)
# Display result
#If resolution is too big, resize the video
if frame.shape[1] > 1240:
cv.imshow(window_name, cv.resize(frame, (1240, 960)))
else:
cv.imshow(window_name, frame)
#Write to output file
if args.output:
out.write(frame)
k = cv.waitKey(1) & 0xff
#Force detect new objects if 'q' is pressed
if k == ord('q'):
print('Refreshing. Detecting New objects')
cv.putText(frame, 'Refreshing. Detecting New objects', (100,80), cv.FONT_HERSHEY_SIMPLEX, 0.75,(0,0,255),2)
stream, objects_detected, objects_list, trackers_dict = intermediate_detections(stream, predictor, args.thr, classes)
# Exit if ESC pressed
if k == 27 : break
stream.release()
if args.output:
out.release()
cv.destroyAllWindows()
def main():
parser = argparse.ArgumentParser(description='Object Detection and Tracking on Video Streams')
parser.add_argument('--input', help='Path to input image or video file. Skip this argument to capture frames from a camera.')
parser.add_argument('--output', help='Path to save output as video file. If nothing is given, the output will not be saved.')
parser.add_argument('--model', required=True,
help='Path to a binary file of model contains trained weights. '
'It could be a file with extensions .caffemodel (Caffe), '
'.weights (Darknet)')
parser.add_argument('--config',
help='Path to a text file of model contains network configuration. '
'It could be a file with extensions .prototxt (Caffe), .cfg (Darknet)')
parser.add_argument('--classes', help='Optional path to a text file with names of classes to label detected objects.')
parser.add_argument('--thr', type=float, default=0.35, help='Confidence threshold for detection')
args = parser.parse_args()
process(args)
if __name__ == '__main__':
main()
object_detection.py
import cv2 as cv
import sys
import numpy as np
def imcv2_recolor(im, a=.1):
# t = [np.random.uniform()]
# t += [np.random.uniform()]
# t += [np.random.uniform()]
# t = np.array(t) * 2. - 1.
t = np.random.uniform(-1, 1, 3)
print(t)
# random amplify each channel
im = im.astype(np.float)
im *= (1 + t * a)
mx = 255. * (1 + a)
up = np.random.uniform(-1, 1)
im = np.power(im / mx, 1. + up * .5)
# return np.array(im * 255., np.uint8)
return im
#定义检测器对象类
class object_detector:
#初始化(相当于构造函数)
def __init__(self, model, cfg):
self.model = model
self.cfg = cfg
self.framework = None
self.load_model()
#载入何种模型
def load_model(self):
if self.model.endswith('weights') and self.cfg.endswith('cfg'):
self.net = cv.dnn.readNetFromDarknet(self.cfg, self.model)
self.framework = 'Darknet'
elif self.model.endswith('caffemodel') and self.cfg.endswith('prototxt'):
self.net = cv.dnn.readNetFromCaffe(self.cfg, self.model)
# self.net = cv.dnn.readNet(self.cfg, self.model)
self.framework = 'Caffe'
else:
sys.exit('Wrong input for model weights and cfg')
self.net.setPreferableBackend(cv.dnn.DNN_BACKEND_DEFAULT)
self.net.setPreferableTarget(cv.dnn.DNN_TARGET_CPU)
#定义检测器预测函数
def predict(self,frame):
# Create a 4D blob from a frame.
if self.framework == 'Darknet':
#blob = cv.dnn.blobFromImage(frame, 0.007843, (416, 416), 127.5, crop = False)
blob = cv.dnn.blobFromImage(cv.resize(frame, (416, 416)), 0.003921, (416, 416), (0,0,0), swapRB=True, crop=False)
else:
blob = cv.dnn.blobFromImage(cv.resize(frame, (300, 300)),0.007843, (300, 300), 127.5)
# Run a model 运行模型
self.net.setInput(blob)
#预测时候只前向传播
out = self.net.forward()
return out
更多请扫码关注:
