QBE and Content Representation 基于图例检索和内容表示
QBE and Content Representation
- Query by Example (QBE) Paradigm
- Basic goals of the QBE retrieval
- Interactive QBE retrieval
- Evaluation of the QBE retrieval
- MPEG-7 Multimediua Content Description Interface
- MPEG-21 Multimedia Framework
- Visual Information at Multiple Levels
- References
Query by Example (QBE) Paradigm
Querying in information retrieval has to be "user-friendly", that is, formulated in such a way that maximally corresponds to the user's cognition and intuition. A text-based paradigm assuming that the information the user is looking for can be described with a few keywords or phrases is mostly invalid in the case when visual information is sought. The global content of an image may easily be described by the names of objects composing it, but it is not an easy matter to exactly describe the semantic meaning of the image content, especially when the user only has a "fuzzy" idea of what should be looked for (Rahman, 2002).
A query-by-example (QBE) paradigm pursues the goal of solving the above-mentioned problem by more flexible description of the content of an image and more versatile formulation of a query than the textual annotations may permit. The QBE paradigm assumes that
- it is easier for a user to show examples of what should be looked for rather than verbally describe it,
- the query becomes more compact, natural, and convenient for the user, and
- the results can be more easily evaluated by the user through a direct comparison with the initial query.
 |
 |
 |
 |
| Query image and the Imspector's outputs | Query sketch and the Imspector's outputs | ||
Because it is unlikely to find an example image containing exactly all the features needed, the natural extension of the QBE paradigm is a querying system accepting multiple examples from the user, gathering all the presented information into a joint pseudo-example, and responding with the best possible matches to this latter image from the database (Rahman, 2002). The QBE-based retrieval of visual information complements the text-based querying, rather than tends to replace it.
Due to subjective choices and typical incompleteness of examples, one need not expect that the CBIR system will retrieve the correct data at the very first querying step. To improve the result on the basis of a previous search, the relevance feedback is frequently used to generalise the QBE. In this case the returned set of retrieved images classified by the user into positive and negative matches is used to reformulate the query. Such a dynamic dialog between the user and the CBIR system stimulates on-line learning and facilitates the target information search. An example below shows the CBIR-user interaction where the user had classified the initial outputs (the positive and negative ones are maked with green and red squares, respectively), so that the next search returns more adequate outputs (an experimental CBIR system "Ikona" developed for IMEDIA Project, INRIA Rocquencourt, France:
 |
 |
| Initial outputs classified by the user | Refined Ikona's outputs |
Basic goals of the QBE retrieval
Therefore, for a human, the main goal of the QBE is to provide a more comfortable and intuitive querying paradigm. From a computational viewpoint, the QBE paradigm relies on a detailed automated analysis of the content of the query image(s). From the cognitive side, the QBE paradigm relies on explicit representation of the knowledge about the search domain (Smeulders e.a., 2000). Syntactic (literal), perceptual, and physical criteria of similarity and equality between pixels or features of images and geometric and topological rules describing equality and differences of 3D objects on images are typical examples of this general knowledge.
Although the user seeks mostly semantic similarity, the CBIR can only provide similarity by data processing results (Smeulders e.a., 2000). The challenge for the CBIR engines is to focus on a narrow information domain the user has in mind via specification, examples, and interaction. Early CBIR engines required from users to first select some low-level visual features of interest and then specify the relative weight for each their possible representation (Castelli & Bergman, 2002). In this case the user had to know in detail how the features are represented and used in the engine. Limitations of such a retrieval have been caused also by the difficulties of representing semantic contents in terms of low-level features and by the highly subjective human visual perception. The user typically forms queries based on semantics, e.g., "penguins on icebergs" or "a sunset image", rather than on low-level features, such as "predominantly oval black blobs on a white background" or "a predominantly red and orange image", respectively. It is obvious that these latter queries will retrieve a big number of irrelevant images having the like dominant colours. One should conclude that low-level features cannot adequately represent image content. Moreover, due to the subjective nature of human perception, different users and even the same user under different conditions may interpret the same image differently. Images are visually perceived as similar due to similar semantic meaning, rather than similar low-level features.
This is why recent experimental CBIR systems such as Photobook (with FourEyes) or MARS are based on an interactive retrieval process where user's feedback helps the system to adjust the query and approach closer the user's expectations.

Architecture of an interactive CBIR system
An interactive CBIR system contains an image database, a feature database, a selector of feature similarity metric, and a block for evaluating feature relevance. When a query arrives, the system has no prior knowledge about the query. All features have the same weight and are used to compute the similarity measure. Then a fixed number of the top-rank (by the similarity to the query) images are retrieved to the user who provides relevance feedback. Learning algorithms are used in the feature relevance block in order to re-evaluate the weights of each feature in accord with the user's feedback. The metric selector chooses the best similarity metric for the weighted features by using reinforcement learning. By iteratively accounting for the user's feedback, the system automatically adjusts the query and brings the retrieval results closer to the user's expectations. Simultaneously, the user need not map semantic concepts onto features and specify weights. Instead, the user should only inform the system which images are relevant to the query, and the weight of each feature in the similarity computation is iteratively updated in accord with the high-level and subjective human perception.
Interactive QBE retrieval
The interactive retrieval based the relevance feedback results in a two-stage process of formulating a query:
- the initial formulation, when the user has no precise idea of what should be searched for, and
- the refined formulation, after the user took part in the iterative feedback process.
At the second stage, the user gives some positive and negative feedback to the system by labelling the retrieved images in accord with their relevance to user's expectations, e.g., as highly relevant, relevant, neutral, irrelevant, or highly irrelevant retrieval results. The CBIR system processes then both the query and the labelled retrieved images in order to update the feature weights and choose more adequate similarity metric such that the irrelevant outputs are suppressed and the relevant ones are enhanced (Castelli & Bergman, 2002). For instance, if the range of feature values for the relevant images is similar to that for the irrelevant ones, then this feature cannot effectively separate these image sets and its weight should decrease. But if the "relevant" values vary in a relatively small range containing no or almost no "irrelevant" values, it is a crucial feature which weight should increase.
Evaluation of the QBE retrieval
Performance of a QBE-based CBIR system is evaluated with respect to a representative test bed (database) containing a known number N of images providing there is a set of benchmark queries to this database such that a "ground-truth" quantitative assessment of to what extent each retrieved image is relevant to the corresponding benchmark query is available (Castelli & Bergman, 2002). The retrieval performance takes into account how many relevant and irrelevant images are presented to the user. Relevance of each image to a query is quantitatively computed by a CBIR system as a real-valued "weight", or score W in the range [0,1]. The values W=1 and W=0 mean the total relevance and the total irrelevance, respectively. The inverse of the relevance score, 1−W, gives the irrelevance of the same image to the query.
Let all N images of a database be ordered by the decreasing relevance Wr to the query where r=1,2,...,N is the position (called rank) of the image in the ordered database: W1≥W2≥... ≥WN−1≥WN&ge, i.e. the image of rank 1 has the maximum relevance and the image of rank N has the minimum relevance. Because the CBIR system returns to the user a particular cutoff number n; 1 ≤ n ≤ N, of images with the higher relevance, the adequacy of the retrieved n outputs is typically evaluated with the following four characteristics: (1) the overall relevance An= W1 + ... + Wn of the returned n outputs ("true positive" decisions, or true detection), (2) the overall irrelevance Bn = (1−W1) + ... + (1−Wn) = n − An of thereturned n outputs ("false positive" decisions, or false alarm), (3) the overall relevance Cn = Wn+1 + ... + WN of the non-returned N − n outputs ("false negative" decisions, or misses), and (4) the overall irrelevance Dn = (1−Wn+1) + ... + (1−WN) = N − n − Cn of of the non-returned N − noutputs ("true negative" decisions, or correct dismissals):
| Relevance of outputs | Irrelevance of outputs | |
|---|---|---|
| Returned n outputs | An | Bn |
| Non-returned N − n outputs | Cn | Dn |
These values suggest the three retrieval effectiveness measures:
- recall Rn = An / (An + Cn), the relative number of the relevant results in the n returned outputs with respect to all relevant results in the database;
- precision Pn = An / (An + Bn) = An / n, the proportion of the relevant results in the n returned outputs; and
- fallout, or false alarm rate Fn = Bn / (Bn + Dn), the relative number of the dismissed irrelevant results.
An additional measure focusses on the missed instead the retrieved relevant items: missed results Mn = Cn / (An + Cn), the relative number of the missed relevant results, or the inverse recall: Mn = 1−Rn.
The retrieval performance of a system can be roughly evaluated by averaging recall and precision over all the benchmark queries. According to multiple experiments, it is difficult to achieve a high level of recall but do not decrease precision. Typically, if the recall rate increases, the precision decreases fast, and the Recall-Precision (R,P) graph is L-shaped.
As shown by Huijsmans & Sebe, when the number of irrelevant items in the database is changing for a fixed-size relevant class, a series of precision-recall curves is obtained that contains both well- and bad-performing curves (the ones at the top and at the lower left side of the graph below, respectively):

Typical precision-recall curves for retrieving a constant size class of 8 totally relevant items
embedded in a growing number of irrelevant items: the generality value G=8/N
decreases from 1.0 to 0.00025 when N increases from 8 to 32,000, respectively.
Because the aforementioned retrieval effectiveness measures strongly depend on the sizes of relevant and irreleveant classes in a database, the common practice of averaging precision and recall values for various queries is invalid. The conventional Precision-Recall graphs are meaningful only when their points are measured under a common generality value G = (An+ Cn) / N that coincides with the average expected performance level. To have more adequate performance estimates, a logarithmic generality dimension, log G, should be added to the conventional 2D Precision-Recall space to build the 3D Generality-Recall-Precision graphs. In practice, complete ground truth to evaluate recall and generality is unknown, and only their lower bounds, An / (N−n+An) and An / N, respectively, can be used to analyse a CBIR system.
MPEG-7 Multimedia Content Description Interface
| MPEG-7 is an ISO/IEC standard developed by MPEG (Moving Picture Experts Group), the committee that also developed the Emmy Award winning standards known as MPEG-1 and MPEG-2, and the MPEG-4 standard. MPEG-1 and MPEG-2 standards made interactive video on CD-ROM and Digital Television possible. MPEG-4 is the multimedia standard for the fixed and mobile web enabling integration of multiple paradigms. |
Audiovisual multimedia information may be used for various purposes by different users and in different situations. Over the last decade, a large variety of multimedia content has become available to an increasing number of users who access it through various devices and over heterogeneous networks. Interoperability became a must for enabling transparent and augmented access to and manipulation with this content using a wide range of networks and devices. Standardization efforts within the Moving Picture Experts Group (MPEG), in particular MPEG-7 and MPEG-21, focus on appropriate tools for universal multimedia access. The MPEG-7 "Multimedia Content Description Interface" standard is developed by the International Standard Organization (ISO) and MPEG in order to enable fast and efficient search for multimedia data of interest to the user in spite of continuously increasing numbers of potentially interesting materials. MPEG-7 provides semantic descriptions of multimedia data including still images, graphics, 3D models, audio, speech, video, and information about how these elements are combined in a multimedia presentation (Hellwagner & Timmerer; Rao e.a.,2002). Special cases of the general multimedia data are facial expressions and personal characters.
MPEG-7 differs from other MPEG standards because data representations ensuring subsequent accurate data reconstruction (as in MPEG-1, MPEG-2, and MPEG-4) are not defined. Audiovisual sources play increasingly pervasive role in human lives, so that more advanced forms of representation of such data are of interest than the simple waveforms / pixels and frames as in MPEG-1 and MPEG-2 or objects as in MPEG-4. MPEG-7 allows some degree of interpreting the information's meaning. The goal of the content description (i.e., metadata) standard MPEG-7 is to enable fast and efficient searching,filtering, and adaptation of multimedia content. Using MPEG-7 descriptions of features of multimedia content, users can search, browse, and retrieve the content more efficiently and effectively that with a text-based search engine. MPEG-7 supplies the scalable or adaptive delivery of multimedia (in other words, universal multimedia access) with description tools to specify content encoding, content variations, user preferences, usage history, space / frequency views, and summaries, whereas MPEG-21 describes the multimedia usage environment, e.g. devices and networks.
Standard representations of image features, extracted objects, and object relationships in MPEG-7, in particular, standard descriptors for colour, texture, shape, motion, and other features of audiovisual data enable fast and effective content-based multimedia data search and filtering. The standard provides a variety of tools to describe and structure multimedia information and facilitate its search. Also, MPEG-7 provides standard means to define other descriptors, structures for descriptors, and their relationships to be associated with the content in order to allow fast and efficient search for material of the user's interest.
The search includes feature extraction and standard descriptions where the terms "features" or "descriptions" relate to several levels of abstraction. But MPEG-7 does not specify algorithms for feature extraction and only defines the standard description to be fed to a search engine. The key concepts of data and feature are defined in MPEG-7 as follows (Rao e.a.,2002):
- Data refers to audio and visual information to be described with MPEG-7 regardless of storage, coding, display, transmission medium, or technology (e.g. a video tape, an audio CD with music, speech, or sound, a picture printed on paper, or an interactive multimedia presentation on the Web).
- A feature is a distinctive characteristic of the data that signifies something for somebody (e.g. colour of an image, pitch of a speech segment, rhythm of an audio segment, camera motion in a video, style in a video, the title of a movie, etc).
Descriptions in MPEG-7 vary according to the types of data, and the description framework consists of a set of descriptors, a set of description schemes, a language to specify description schemes, and one or more schemes for encoding the description (Castelli & Bergman, 2002; Rao e.a.,2002):
- A Descriptor (D) represents a feature and defines the syntax and the semantics of the feature representation. Examples of descriptors are the colour histogram, the average of the frequency components, the motion field, the text of the title, and so forth. Multiple descriptors can be assigned to a single feature, e.g., the colour feature has the descriptors such as the average colour, the dominant colour, and the colour histogram. A descriptor value is an instantiation of a descreop[tor for a given dataset or subset.
- A Description Scheme (DS) specifies the structure and semantics of the relationship between its components being both descriptors and description schemes, for example, a movie structured in time as scenes and shots and contained some textural descriptors at the scene level, and colour, motion, and audio descriptors at the shot level. Description schemes refer to image classification or describe image contents with specific indexing structures. For example, a classification DS should contain the description tools to allow image classification or a segment DS should represent a section of a multimedia content unit.
- A description consists of a DS structure and the set of descriptor values that describe the data. A coded description is a description encoded to meet relevant requirements, e.g. compression efficiency, error, resilience, random access, etc.
- A Description Definition Language (DDL) allows to create new (i.e. being absent in standard) or extend existing description schemes and possibly, descriptors. The XML eXtensible Markup Language with MPEG-7-specific extensions is adopted as the DDL.
The MPEG-7 framework allows many ways to encode the description, specifies a standard set of descriptors for describing various types of multimedia information, and provides standards for defining other descriptors and structures for descriptors and their relationships. This description is associated with the contents itself, thus allowing fast and efficient search for material of interest. In particular, images become more self-describing of their contents by carrying the MPEG-7 annotations, enabling richer descriptions of features, structure, and semantic information (Castelli & Bergman, 2002).
MPEG-7 addresses many applications and types of usage, including real-time and non-real-time applications, interactive and unidirectional (broadcast) presentations, and offline and online usage. In a real-time application, descriptions are built for the contents while capturing the data. MPEG-7 descriptions support various query modalities such as text-based only, subject navigation, interactive browsing, visual navigation and summarisation, search by example, and using features and sketches (Rao e.a.,2002).
This standard does not define what description is to be used for a particular piece of content, but only provides the tools to represent such a description. Comparing to other toolboxes for multimedia description, MPEG-7 is general, i.e. capable to describe content in various application domains, has an object-oriented data model that allows to independently describe individual objects within a scene, integrates low- and high-level features / descriptors into a single architecture that combines the power of both types of descriptors, and can be extended, due to the DDL, to new application domains and integrate novel description tools.
MPEG-7 Visual description tools will be discussed in more detail in the subsequent parts of these lecture notes. Here, we only overview them in brief. The tools consist of basic structures and descriptors for visual features such as colour, texture, shape, motion, localisation, etc (Rao e.a.,2002). Each category consists of elementary and advanced descriptors. There are five basic structures, namely, grid layout, time series, multiview, spatial 2D coordinates, and temporal interpolation, relating to visual descriptions :
- The grid layout descriptor splits an image into a set of rectangular regions of equal size; each region can be described separately in terms of other descriptors, e.g. as colour texture, as well as subdescriptors can be assigned to either all rectangular regions or an arbitrary subset of them.
- A time series descriptor defines a temporal sequence of descriptors in a video segment and provides image-to-video matching and video-frames-to-video-frames matching functionalities; two types of time series available are:
- regular time series where descriptors locate regularly, with constant intervals, within a given time span (a simple representation for low-complexity cases)
- irregular time series where descriptors locate irregularly, with various intervals, within a given time span (an efficient representation for narrow transmission bandwidth or low memory size)
- The 2D/3D multiview descriptor specifies a structure that combines 2D descriptors of a visual feature of a 3D object observed from different view angles; it forms a complete 3D view-based representation of the object in terms of any 2D visual descriptor, such as, e.g. contour shape, region shape, colour or texture, and allows the matching of 3D objects by comparing their views as well as comparing pure 2D views with 3D objects.
- The spatial 2D coordinates descriptor defines a 2D spatial coordinate system to be used in other relevan descriptors and description schemes (DSs); it supports two kinds of coordinate systems:
- a local coordinate system where all images are mapped to the same position with respect to the origin and aligned with the coordinate axes (the horizontal X axis from left to right and the vertical top-down Y axis) and
- an integrated coordinate system where each (image) frame may be mapped to different areas which are possibly rotated with respect to the coordinate axes; this system can be used to represent coordinates as a mosaic of a video shot.
- The temporal interpolation descriptor uses connected polynomials to approximate multidimensional variable values that change in time, such as an object position in a video (the beginning of the interpolation is always aligned to time 0); the description size of the temporal interpolation is usually much smaller than describing all values.
Visual features related to semantic contents are represented by the following descriptors:
- the colour descriptors - colour space, colour quantisation, dominant colours, scalable colour, colour-structure, colour layout, and group of frames / group of pictures colour descriptor;
- the texture descriptors - homogeneous texture, texture browsing, and edge histogram;
- the shape descriptors - object region-based shape, contour-based shape, 3D shape, and 2D-3D multiple view;
- the motion descriptors - camera motion, object motion trajectory, parametric object motion, and motion activity;
- the localisation descriptors - region locator and spatiotemporal locator,
- and other descriptors such as, e.g. the face recognition descriptor.
MPEG-7 Multimedia Description Schemes (MMDS) focus on standartising a set of description tools (descriptors and description schemes) dealing with generic and multimedia entities (Hellwagner & Timmerer, 2005; Rao e.a.,2002). Features used in audio, visual, and text descriptions are generic entities, i.e. generic to all media, e.g. vector, histogram, time, and so forth. Apart from this set of generic description tools, five different classes of more complex tools in line with their functionalities are used whenever more than one medium (audio and video) is to be described:
- Content description - representation of perceivable information
- Content management - information about media features and the creation of the use of the audiovisual content
- Content organisation - representation of the analysis and classification of several audiovisual contents
- Navigation and access - specification of summaries and variations of the audiovisual content
- User interaction - Description of user preferences pertaining to the consumption of the multimedia material
Description schemes for content descriptions describe the structure (regions, video frames and audio segments) and semantics (objects, events and abstract notions). The structure DSs are organised around segment DSs representing the spatial, temporal, or spatiotemporal structure of the audiovisual content. The segment DS is a hierarchical structure producing a table of contents for accessing or an index for searching the audiovisual content. The segments are further described in terms of (i) perceptual features using MPEG-7 descriptors for colour, texture, shape, motion, audio features and (ii) semantic information using textual annotations. The semantic DSs involve objects, events, abstract concepts, and relationships. The structure DSs and semantic DSs are related by a set of links in order to jointly describe the audiovisual content on the basis of both content structure and semantics.
Description schemes for content management describe together different aspects of creation and production, media coding, storage and file formats, and content usage. Functionality of each of these classes of DSs is defined as creation information, usage information, and media description. The creation information describes the creation, production, and classification of the audiovisual content and other material related to that content, provides a title, textual annotation and information about creators, creation locations and dates, describes how the audiovisual material is classified into categories, such as gear, subject, purpose, langiage, etc, provides review and guidance information (such as age classification, subjective review, parental guidance and so forth, and whether other audiovisual materials relate to the same content. The usage information describes user rights, availability, usage record, and financial issues, and is changing during the lifetime of the audiovisual content. The media description describes the storage media (compression, coding, and storage format) of the audiovisual data, identifies in its description schemes the master media, i.e. the original source from which different instances of the audiovisual content, called media profiles, are produced, anddescribe each media profile individually in terms of the encoding parameters, storage media information, and location.
Description schemes for content organisation provide encryption schemes for organising and modelling collections of audiovisual content, segments, events and/or objects, and for describing their common properties. The collection structure DS uses different models and statistics to characterise attributes of the collection members (e.g. audiovisual content, temporal segments or video), builds collection clusters of the audiovisual content, segments, events or objects, and specifies properties common to the elements.
Description schemes for navigation and access of audiovisual content specify summaries, views, partitions, and variations of multimedia data. Summaries and abstracts of audiovisual content provided by the MPEG-7 summary description schemes enable efficient browsing and navigating of audiovisual data. The space and frequency domain views allow multiresolution and progressive access. The variation DSs specify the relation between different variations of audiovisual material in order to adaptively select different variations of the content under different terminal and delivery conditions.
Description schemes for user interaction deal with the user preference information describing user frequencies of consumption of the multimedia material. This allows matching between user preferences and MPEG-7 content descriptions in order to personalise audiovisual content access, presentation and consumption. The user preference description scheme specifies preferences for different types of content and modes of browsing, including context dependencies in terms of time and place, assigns weights to the relative importance of different preferences, specifies the privacy characteristics of the preferences, and determines whether preferences are subject to update (e.g. by automatic learning through interaction with the user.
Basic application domains for MPEG-7 are digital libraries (e.g. video libraries, image catalogs, musical dictionaries, film-video-radio archives, future home multimedia databases, etc), multimedia direcory services (like The Yellow Pages), broadcast media selection (e.g. radio channel, TV channel, and Internet broadcast search and selection), multimedia editing (e.g. personalised electronic news services and media authoring), universal access to multimedia content, automated processing of multimedia information (e.g. an automated analysis of the output of a surveillance camera using MPEG-7 descriptions), professional journalism, history / art museums, tourist information, geographical information systems (GIS), surveillance systems (e.g. traffic control), biomedical imaging, architecture / real estate / interior design, and many other general-purpose and specialised professional and control applications.
MPEG-21 Multimedia Framework
| A comprehensive standard framework for networked digital multimedia designed by the Moving Picture Experts Group. MPEG-21 includes a Rights Expression Language (REL) and a Rights Data Dictionary. Unlike other MPEG standards that describe compression coding methods, MPEG-21 describes a standard that defines the description of content and also processes for accessing, searching, storing and protecting the copyrights of content. (Webopedia) REL is a language for specifying rights to content, fees or other consideration required to secure those rights, types of users qualified to obtain those rights, and other associated information necessary to enable e-commerce transactions in content rights. (Webopedia) The MPEG-21 standard aims at defining an open framework for multimedia applications. Specifically, MPEG-21 defines a "Rights Expression Language" standard as means of sharing digital rights/permissions/restrictions for digital content from content creator to content consumer. As an XML-based standard, MPEG-21 is designed to communicate machine-readable license information and do so in an "ubiquitous, unambiguous and secure" manner. |
MPEG-21 Multimedia Framework (see http://www.chiariglione.org/mpeg/standards/mpeg-21/mpeg-21.htm for more detail) aims at enabling transparent and augmented use of multimedia resources across a wide range of networks and devices (Rao e.a., 2002). While MPEG-7 deals mainly with providing descriptions of multimedia content, MPEG-21is much broader and aims to deals with composite units that consist of multiple resources, how the resources are interrelated as well as the methods by which content can be distributed (see MPEG-21 FAQs). The basic elements of the framework are (i) Digital Items (structured digital objects with a standard representation, identification, and description, or metadata within the MPEG-21 framework) and (ii) Users of all entities that interact in the MPEG-21 envoronment or make use of MPEG-21 digital items. The Digital Item is a fundamental unit of distribution and transaction within the MPEG-21 multimedia framework and can be considered the �what� of this framework, e.g. a video collection or a music album. The Users interacting with Digital Items can be considered the �who� of the Multimedia Framework.
Key areas to be addressed in order to provide an interoperable multimedia framework are:
- Digital Item Declaration (a uniform and flexible abstraction and interoperable schema for declaring Digital Items);
- Digital Item Identification and Description (a framework for identification and description of any entity regardless of its nature, type or granularity);
- Content Handling and Usage (provide interfaces and protocols that enable creation, manipulation, search, access, storage, delivery, and (re)use of content across the content distribution and consumption value chain);
- Intellectual Property Management and Protection (the means to enable intellectual property rights on content to be persistently and reliably managed and protected across a wide range of networks and devices);
- Terminals and Networks (the ability to provide interoperable and transparent access to content across networks and terminals);
- Content Representation (how the media resources are represented);
- Event Reporting (the metrics and interfaces that enable Users to understand precisely the performance of all reportable events within the framework);
MPEG-21 defines a normative open framework for multimedia delivery and consumption for use by all the players in the delivery and consumption chain. This open framework will provide content creators, producers, distributors and service providers with equal opportunities in the MPEG-21 enabled open market. This will also be to the benefit of the content consumer providing them access to a large variety of content in an interoperable manner The goal of MPEG-21 can thus be rephrased to: defining the technology needed to support Users to exchange, access, consume, trade and otherwise manipulate Digital Items in an efficient, transparent and interoperable way.
MPEG-21 identifies and defines the mechanisms and elements needed to support the multimedia delivery chain as described above as well as the relationships between and the operations supported by them. Within the parts of MPEG-21, these elements are elaborated by defining the syntax and semantics of their characteristics, such as interfaces to the elements.
Audiovisual content representation is addressed in MPEG-21 in specific ways. First, content is no longer seen as essence (what the user has traditionally consumed) or as metadata (the description of essence), but as an integrated whole. Secondly, the interfaces with content access are identified in such a way that content protection - a necessity for the holders of the rights in order to retain control of their assets - is transparent to the end user. Third, fast advances in content digitisation make urgent the need to identify and describe content in such a way that it cannot be tampered with, i.e. due to watermarking or fingerprinting techniques.
As shown by (Hellwagner & Timmerer, 2005; Rao e.a., 2002), content representation technology provided by MPEG-21 represents efficiently any content of all relevant data types of natural and synthetic origin, or any their combination, in a scalable and error-recilient way. The various elements in a multimedia scene are independently accessible, synchronisable, and multiplexed and allow various types of interaction . Digital item identification means a uniquely designated token enabling to recognise a digital item, its organisation and attributes. The interoperable and integrated framework for identification and description of a digital item provides accurate, reliable, unique, and seamless identification for any entity, persistent and efficient association of identifiers with digital items, secure and integral identification and description regardless of all kinds of manipulations and alterations, automated processing of rights transactions, and content location, retrieval, and acquisition.
The MPEG-21 multimedia framework provides interfaces and protocols to enable creation, manipulation, search, access, storage, delivery, and (re)use of content across the content distribution and consumption value chain. The content can be any media data and descriptive data. The emphasis of the framework is on improving the interaction model for users with personalisation and content management. The personalisation is supported both when the human user is performing these functions and when the functions are delegated to nonhuman entities such as agents.
But content management does not manage the rights of the content. MPEG-21 provides a multimedia digital rights management framework to manage and protect intellectual property. This framework enables all users to express their rights and interests in digital items as well as agreements related to these items. The users have assurance that those rights, interests and agreements will be persistently and reliably managed and protected across a wide range of networks and devices, updates of relevant legislation, regulations, agreements and cultural norms will be captured, codified, disseminated and reflected to build a universally acceptable societal platform for e-commerce with digital items, and a uniform technical and organisational foundation will be provided for governing on behalf of all users the behaviour of devices, systems and applications interacting with digital items and services.
Visual Information at Multiple Levels
Images represent content information at multiple levels, starting from the most basic level of pixelwise responses to light (intensities or colours). The pixel patterns produce more general low-level elements such as colour regions, texture, motion (inter-frame changes in a video sequence), shapes (object boundaries), and so on. No special knowledge is involved at these levels. But at the most complex level, images represent abstract ideas depending on individual knowledge, experience, and even on a particular mood (Castelli & Bergman, 2002).
Image syntax refers to perceived visual elements and their spatial - temporal arrangement with no consideration to the meaning of the elements or arrangements, wheras semantics deals just with the meaning. Syntax can be met at several perceptual levels - from simple global colour and texture to local geometric forms, such as lines and circles. Semantics can also be treated at different levels.
Objects depicted in images are characterised both with general concepts and visual concepts. These concepts are different and may vary among individuals. A visual concept includes only visual attributes, and a general concept refers to any kind of attribures. In the CBIR different users have different concepts of even simple objects, and even simple objects can be seen at different conceptual levels. Specifically, general concepts help to answer the question: "What is it?", whereas visual concepts helps to answer the question "What does it look like?"

General and visual attributes used by different individuals to describe the same object (a ball).
The above figure shows attributes selected by different individuals, namely, a volleyball player (the left circle) and a baseball player (the right circle), for describing the same object. The volleyball and the baseball player choose "soft, yellow, round, leather, light weight" and "hard, heavy, white, round, leather" as the general attributes, respectively, because the both individuals have different general concepts of a ball. Naturally, there is also a correlation between some visual and general attributes (e.g., big and round). Thus, in creating conceptual indexing structures one needs to discriminate between visual and nonvisual content. The visual content of an image corresponds to directly observed items such as lines, shapes, colours, objects, and so on. The nonvisual content corresponds to information that is closely related to, but is not present in the image. QBE relates primarily to the visual content, although an indexing structure for the nonvisual content is also of a notable practical interest. Generally, the visual content is a multilevel structure where the lower levels refer to syntax, rather than semantics. The pyramidal indexing structure below has been developed in Columbia University New York, USA, and proposed to MPEG-7 (Castelli & Bergman, 2002).
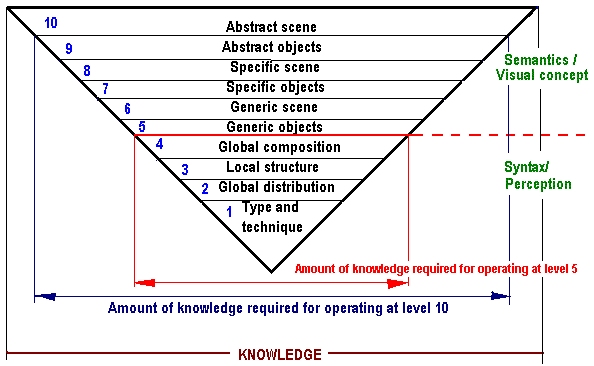
The pyramidal indexing structure
(the width of each layer represents the amount of knowledge
that is necessary for operating at that level).
The bottom four levels focus on image perception, require no knowledge of actual objects to index an image, and involve only low-level processing. At the most basic level of types (categories) and techniques, the user is interested in the general visual characteristics of the image or the video sequence such as painting, drawing, black and white photo, or colour photo. Digital images may include additional descriptions such as number of colours, compression scheme, resolution, and so on.
The type and technique level provides general information about the image or video sequence, but gives almost no information about the visual content. The next global distribution level provides a global description of the image as a whole, without detecting and processing individual components of the content. Global distribution perceptual features include global colour (e.g., dominant colour, average colour, or colour histogram), global texture in terms of coarseness, contrast, directionality, or other descriptors, and global shape (e.g., aspect ratio). For video data, the features include also global motion (e.g., speed, acceleration, and trajectory), camera motion, global deformation (e.g., growing speed), and temporal and spatial dimensions. Some global characteristics are less intuitive than others. For example, it is difficult for a human to imagine what the colour histogram of an image looks like). Nonetheless, these global low-level features have been succesfully used in various CBIR systems, e.g., QBIC, WebSEEk, or Virage, to perform QBE and to organise the contents of a database for browsing.
At the higher local structure level basic image components, or basic syntax symbols, are extracted by low-level processing. The elements include dots, lines, and texture, as well as temporal and spatial position, local colour, local motion, local deformation, local shape, and 2D geometry. Such elements have also been used in CBIR systems, mainly in query-by-user sketch interfaces. This level manipulates with basic elements that represent objects, and may include some simple shapes such as a circle, an ellipse, and a polygon.
While local structure is given by basic elements, global composition refers to the arrangement (spatial positioning) of these elements in terms of general concepts such as balance, symmetry, region or centre of viewing, dot, leading line, viewing angle, and so forth. This level involves no specific objects and considers only basic elements or their groups. An image is represented by a structured set of basic forms - lines, squares, circles, etc.
Although perceptual aspects of the image are easier for automatic indexing and classification, humans mainly rely on higher-level attributes when describe, classify, and search for images. The level of generic objects accounts for the object's attributes which are common to all or most members of the category. The objects are recognised using only such a general knowledge. The level of generic scenes uses general knowledge to index an image as a whole, based on all the objects it contains. Both these levels need powerful techniques of object detection and recognition. But in spite of current advances in pattern recognition and computer vision, the recognition systems still have serious limitations regarding the CBIR because of a number of additional factors complicating the recognition process, in particular, varying illumination of objects, shadows, occlusions, specular reflections, different scales, large changes of viewpoint intensive noise, arbitrary backgrounds, and clutter (foreign objects) making feature extraction more difficult.
Even more difficulties arise on the levels of specific objects and specific scenes where specific objective knowledge of individual objects and groups of objects is required. In indexing, the correct relationship between the generic and specific labels should be maintained. In particular, consistency of indexing is to be preserved, e.g., by using special templates and vocabularies. The levels of abstract objects and abstract scenesare the most challenging for indexing because they are very subjective (the interpertative knowledge of what the objects or scenes represent vary greatly among different users).

Visual and nonvisual information to semantically characterise an image or its parts.
Relationships between elements of visual content within each level are also of two types: syntactic (related to perception) and semantic (related to meaning). Syntactic relationships such as spatial, temporal, or photometric (visual), may occur at any level, but the semantic ones occur only at the semantics levels 5 through 10 of the above pyramid.
Due to difficulties in formal specification of semantics, most of the existing CBIR systems operate at syntactic levels. In particular, WebSeek and QBIC exploit only the levels 1 (type and technique) and 2 (global distribution), VideoQ involves also the level 3 (local structure), and Virage adds the level 4 (global composition). Only very few experiments have been done to account at least for generic levels of semantics.
References
- R. Blumberg and P. Hughes. Visual realism and interactivity for the Internet. Proc. IEEE Computer Society Conf. (Compcon'97), 23-26 Feb. 1997, pp. 269 - 273.
- R. R. Buckley and G. B. Beretta. Color Imaging on the Internet. NIP-16: Vancouver, 2000.
- V.Castelli and L.D.Bergman (Eds.). Image Databases: Search and Retrieval of Digital Imagery. John Wiley & Sons: New York, 2002.
- G. Chang, M. J. Healey, J. A. M. McHugh, and J. T. L. Wang. Minimg the World Wide Web: An Information Search Approach. Kluwer Academic: Norwell, 2001.
- V. Della Mea, V. Roberto, and C. A. Beltrami. Visualization issues in Telepathology: the role of the Internet Imaging Protocol. Proc. 5th Int. Conf. Information Visualization, 2001, pp. 717 - 722.
- A.Hanjalic, G. C. Langelaar, P. M. B. van Roosmalen, J. Biemond, and R. Lagendijk. Image and Video Data Bases: Restoration, Watermarking and Retrieval. Elsevier Science: Amsterdam, 2000.
- H. Hellwagner and C. Timmerer. MPEG standards enabling universal multimedia access: Tutorial description. Proc. First Int. Conf. on Automated Production of Cross Media Content for Multi-channel Distribution (AXMEDIS 2005), Florence, Italy, November/December, 2005. Electronic edition: http://www.axmedis.org/axmedis2005
- D. P. Huismans and N. Sebe. How to complete performance graphs in content-based image retrieval: Add generality and normalize scope. IEEE Trans. on Pattern Analysis and Machine Intelligence, vol.27, no.2, 2005, pp. 245 - 251.
- S. M. Rahman (Ed.). Interactive Multimedia Systems. IRM Press: Hershey, 2002.
- K. R. Rao, Z. S. Bojkovic, and D. A. Milovanovic. Multimedia Communication Systems: Techniques, Standards, and Networks. Prentice Hall PTR: Upper Saddle River, New Jersey, 2002.
- T. K. Shih. Distributed Multimedia Databases: Techniques & Applications. Idea Group Publishing: Hershey, 2002.
- A. W. M. Smeulders and R. Jain (Eds.). Image Databases and Multimedia Search. World Scientific: Singapore, 1997.
- M. Stokes, M. Anderson, S. Chandrasekar, R. Motta. A standard default color space for the Internet - sRGB. Version 1.10, Nov. 5, 1996. ICC, 1996.
Return to the general table of contents
from: https://www.cs.auckland.ac.nz/courses/compsci708s1c/lectures/Glect-html/topic2c708FSC.htm