WaterDrop on spark/flink(v2.x 支持spark/flink)
(注:flink版本>=1.9.0,spark版本>=2.x.x)
使用场景
- 海量数据ETL
- 海量数据聚合
- 多源数据处理
特性
- 简单易用,灵活配置,无需开发
- 实时流式处理
- 高性能
- 海量数据处理能力
- 模块化和插件化,易于扩展
- 支持利用SQL做数据处理和聚合
工作流程
input/Source[数据源输入] -> Filter/Transform[数据处理] -> Output/Sink[结果输出]
v2.x 和 v1.x 区别
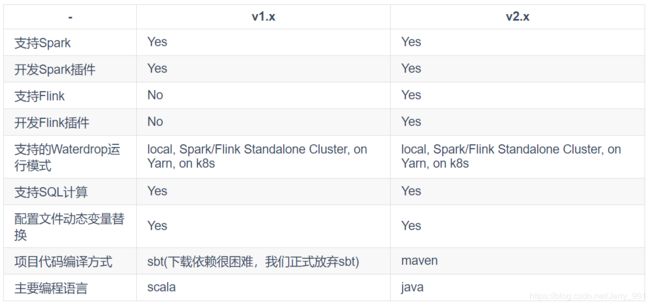
备注:Waterdrop v1.x 与 v2.x 还有一个很大的区别,就是配置文件中,input改名为source, filter改名为transform, output改名为sink。
# v1.x 的配置文件:
input {}
filter {}
output {}
# v2.x 的配置文件:
source {} # input -> source
transform {} # filter -> transform
sink {} # output -> sink为何要研发 WaterDrop 2.x
在2017年的夏天,InterestingLab 团队为了大幅提升海量、分布式数据计算程序的开发效率和运行稳定性,开源了支持Spark流式和离线批计算的Waterdrop v1.x。 直到2019年的冬天,这两年的时间里,Waterdrop逐渐被国内多个一二线互联网公司以及众多的规模较小的创业公司应用到生产环境,持续为其产生价值和收益。 在Github上,目前此项目的Star + Fork 数也超过了1000+,它的能力和价值得到了充分的认可在。
InterestingLab 坚信,只有真正为用户产生价值的开源项目,才是好的开源项目,这与那些为了彰显自身技术实力,疯狂堆砌功能和高端技术的开源项目不同,它们很少考虑用户真正需要的是什么。 然后,时代是在进步的,InterestingLab也有深深的危机感,无法停留在当前的成绩上不前进。
在2019年的夏天,InterestingLab 做出了一个重要的决策 —— 在Waterdrop上尽快支持Flink,让Flink的用户也能够用上Waterdrop,感受到它带来的实实在在的便利。 终于,在2020年的春节前夕,InterestingLab 正式对外开放了Waterdrop v2.x,一个同时支持Spark(Spark >= 2.2)和Flink(Flink >=1.9)的版本,希望它能帮助到国内庞大的Flink社区用户。
在此特此感谢,Facebook Presto项目,Presto项目是一个非常优秀的开源OLAP查询引擎,提供了丰富的插件化能力。 Waterdrop项目正式学习了它的插件化体系架构之后,在Spark和Flink上研发出的一套插件化体系架构,为Spark和Flink计算程序的插件化开发插上了翅膀。
WaterDrop 2.x 通用配置
一个完整的Waterdrop配置包含env, source, transform, sink, 即:
env {
...
}
source {
...
}
transform {
...
}
sink {
...
}env是flink任务的相关的配置,例如设置时间为event-time还是process-time
env {
execution.parallelism = 1 #设置任务的整体并行度为1
execution.checkpoint.interval = 10000 #设置任务checkpoint的频率
execution.checkpoint.data-uri = "hdfs://localhost:9000/checkpoint" #设置checkpoint的路径
}v2.0.0 插件



完整配置文件案例
######
###### This config file is a demonstration of streaming processing in waterdrop config
######
env {
# You can set flink configuration here
execution.parallelism = 1
#execution.checkpoint.interval = 10000
#execution.checkpoint.data-uri = "hdfs://localhost:9000/checkpoint"
}
source {
# This is a example source plugin **only for test and demonstrate the feature source plugin**
FakeSourceStream {
result_table_name = "fake"
field_name = "name,age"
}
# If you would like to get more information about how to configure waterdrop and see full list of source plugins,
# please go to https://interestinglab.github.io/waterdrop/#/zh-cn/configuration/base
}
transform {
sql {
sql = "select name,age from fake"
}
# If you would like to get more information about how to configure waterdrop and see full list of transform plugins,
# please go to https://interestinglab.github.io/waterdrop/#/zh-cn/configuration/base
}
sink {
ConsoleSink {}
# If you would like to get more information about how to configure waterdrop and see full list of sink plugins,
# please go to https://interestinglab.github.io/waterdrop/#/zh-cn/configuration/base
}
官网:https://interestinglab.github.io/waterdrop