如何用Spark实现一个通用大数据引擎
Github 上的开源项目 Waterdrop,此项目Star + Fork的有将近1200人,是一个基于Spark和Flink构建的生产环境的海量数据计算产品。Waterdrop的特性包括
- 简单易用,灵活配置,无需开发;
- 同时支持流式和离线处理;
- 模块化和插件化,易于扩展;
- 支持利用SQL做数据处理和聚合;
- 支持选择Spark或Flink作为底层引擎层。
作为 Spark 或者 Flink 的开发者,你是否也曾经想过要打造这样一款通用的计算引擎,是是否曾经有这样的疑问,Waterdrop为什么能实现这么多实用又吸引人的特性呢?
哈哈哈,其实都是有”套路“的,今天我们特别邀请到了 Waterdrop 项目的核心开发者Gary,为我们掰开了揉碎了讲讲,这个“套路”是什么?感兴趣的同学,你可以去这个地址https://github.com/InterestingLab/waterdrop,学习和研究一下Waterdrop的源代码,想进一步交流的同学,请搜索微信号(garyelephant)加Gary的微信,他是个喜欢交流技术的程序员。
Apache Spark,为开发者提供了一套分布式计算API,我们只要调用这些API,就能够完成海量数据和分布式的业务计算。当你开发了多个Spark程序以后,会发现大部分数据处理的流程相似度很高,每个环节的计算逻辑也有很多相似之处。那么我们可以通过什么办法来实现一个通用引擎,进而减少这种重复性呢?
使用Spark API开发业务需求时,由于业务的重复性,做了很多重复的Spark代码开发。Spark开发者完全可以使用Spark的API打造出一款通用的计算引擎,来应对80%的业务需求。同时,通过实现插件体系,来应对20%的特殊需求。而这样实现的计算引擎,可以大大提高大数据开发的效率。
简单的通用数据处理流程
你可能比较感兴趣的有这样几个问题,一个是通用的数据处理流程是什么样的。另一个是Spark 如何做数据输入、输出和计算。第三个问题是:如何在Spark上实现通用的数据处理工作引擎。
接下来,先来讲一下第一个问题的解决方案,看看通用的数据处理流程到底是什么样的。
最简单的流程应该很容易想到(如图),就是有一个数据输入(Source),一个数据处理(Transform)还有一个是数据输出(Sink)。
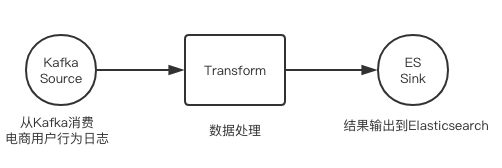
这里举一个例子,以具体的场景切入,假设有一个电商网站,每天有几千万的用户访问,用户在这个网站上的行为包括:查看商品详情、加购物车、下单、评论和收藏。各个用户行为日志已经收集上报到了分布式消息队列Kafka中,现在需要用Spark来完成分析和处理,并输出到Elasticsearch中。接下来,我们一起来看下这个数据处理流程(如图):
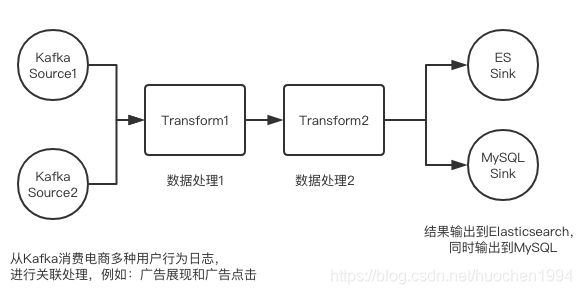
如果输出到 Elasticsearch 的同时,还想输出到 MySQL,我们称它为“分裂”,再来看下这张图(如图):

如果再增加一个transform(如图4),就是Transform-1 先处理数据,之后输出,再由Transform-2来处理,相当于一个管道化(Pipeline)数据处理流程。

当然还有更复杂的数据处理流程,比如同时处理多个数据输入,就是常说的“流关联”。这个流程实现起来就比较复杂了,而且应用场景也不是特别多,今天的课程就不详细展开了,如果你感兴趣,可以自行查阅Spark中“流关联”的相关技术(以下):
今天的分享中,主要介绍的是前两种较为通用的数据处理流程的实现。接下来,再来讲讲第二个问题:Spark 如何做数据输入、输出、数据处理?
这里需要注意一下,我们介绍的是电商数据处理场景下,使用Spark Streaming的常见用法,要构建的是这样的数据处理流程。
一个是Kafka Source:数据源是 Kafka,数据类型是字符串,其中的各个字段以tab(\t)分割。另外,来看下Split Transform:数据进入Spark后,经过一次字符串分割后,把非结构化数据转换成了结构化数据。再一个就是Elasticsearch Sink:数据计算完成后输出到Elasticsearch。
首先,来看看Kafka Source的实现方式(如下):
/// kafka consumer配置
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "localhost:9092,anotherhost:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "use_a_separate_group_id_for_each_stream",
"auto.offset.reset" -> "latest",
"enable.auto.commit" -> (false: java.lang.Boolean)
)
// 待消费的topic
val topics = Array("topicA", "topicB")
// 创建DStream
val dstream = KafkaUtils.createDirectStream[String, String](
streamingContext,
PreferConsistent,
Subscribe[String, String](topics, kafkaParams)
)
// 生成 DStream[String],其中每条数据的内容就是从Kafka消费到的数据。
val resultDstream = dstream.map(record => record.value)
有了Kafka Source以后,接下来我们只要处理代码中生成的result Dstream就可以了,如果你有开发过Spark Streaming的话,就会知道,DStream提供了一个foreachRDD()方法,允许我们处理每个streaming批次的数据。在foreachRDD方法中,我们可以把默认用来表示分布式数据集的RDD,转换为Dataset[Row] 。Row表示的是Dataset中 m的每一行数据,是数据处理的基本单位。
Dataset是Spark中常用的分布式数据集,不仅可以用在Spark SQL中,也可用在Spark Streaming中。在Dataset上面,开发者可以执行预定义好的UDF和SQL,也可以执行自己实现的函数,非常方便。所以,我们把Dataset作为整个数据处理流程中的核心数据结构。
这段代码演示的是如何从DStream 生成Dataset,我们一起来看下:
resultDstream.foreachRDD(rdd => {
val rowsRDD = rdd.map(element => {
element match {
case (topic, message) => {
RowFactory.create(topic, message)
}
}
})
val schema = StructType(
Array(StructField("topic", DataTypes.StringType), StructField("raw_message", DataTypes.StringType)))
val inputDf = sparkSession.createDataFrame(rowsRDD, schema)
// 生成dataset后,在后面完成其他计算,并输出到Elasticsearch
})
其次,Split Transform 的实现方式是这样的(如下)。我们先定义一个字符串 split() 函数:
/**
* Split string by delimiter, if size of splited parts is less than fillLength,
* empty string is filled; if greater than fillLength, parts will be truncated.
* */
private def split(str: String, delimiter: String, fillLength: Int): Seq[String] = {
val parts = str.split(delimiter).map(_.trim)
val filled = (fillLength compare parts.size) match {
case 0 => parts
case 1 => parts ++ Array.fill[String](fillLength - parts.size)("")
case -1 => parts.slice(0, fillLength)
}
filled.toSeq
}
然后,在分布式数据集(Dataset)上,执行字符串分割:
// 定义字段名称列表
val fieldNames = List("timestamp", "uid", "product_id", "user_agent")
// 定义UDF
val splitUdf = udf((s: String) => { split(s, "\t", fieldNames.size()) })
// 定义临时字段名
val tmpField = "_tmp_";
// 在数据集上执行UDF,把split后的字段都放到临时字段
tmpDf = inputDf.withColumn(tmpField, splitUdf(col(srcField)))
// 把split后的字段都放到Top Level
for (i <- 0 until fieldNames.size()) {
tmpDf = tmpDf.withColumn(fieldNames.get(i), col(tmpField)(i))
}
// 删掉临时字段
var resultDf = tmpDf.drop(tmpField)
最后,Elasticsearch Sink的实现方式是这样的(如下):
// Elasticsearch输出配置
val esCfg : Map[String, String] = Map()
esCfg += ("es.index.auto.create" -> true)
esCfg += ("es.batch.size.entries" -> 100000)
esCfg += ("es.nodes" -> "localhost:9200")
// 指定索引名称
val indexName = "myindex"
val indexType = "logs"
// 数据输出到Elasticsearch
resultDf.saveToEs(indexName + "/" + indexType, esCfg)
完成了前面这些代码,只要将打包好的spark程序Jar包,通过spark-submit脚本,提交到Spark集群上就可开始运行,完成指定的业务逻辑计算。目前讲到的是3个具体的 Source、Transform、Sink 案例,实际上你可以参考这些代码,开发出更多的数据处理逻辑。
这里我们开始回答第三个问题:如何在Spark上实现通用的数据处理工作流?
前面我们讲过了一个数据处理流程的具体案例,接下来面临的问题是,这个案例和其他的案例有哪些相似之处,哪些地方可以做一下抽象分层,来实现一套通用的计算引擎呢?
使用 Spark 构建通用引擎
我来提供一种方案,供你参考。概括来讲,用Spark实现一个通用的计算引擎的步骤是这样的,我们一起来看下:
- 第一部分:搭建一套插件API体系,定义完整的
BaseSouceBaseTransform以及BaseSinkAPI (SPI) - 第二部分:基于插件API体系,开发出对应的流程控制代码。
- 第三部分:集成插件API实现常用的
Source,Transform和Sink插件
第一步:构建一套插件API体系
我们来看一下Waterdrop相关的 API 定义。

再来看下第二部分,基于插件API体系,开发出对应的流程控制代码。第三部分是使用插件API实现常见的 Source,Transform,Sink 插件。
接下来,我们来逐个拆解。先来看看第一部分,定义插件接口。这里我们需要先定义一个最基础的Plugin插件接口。这里演示的代码都是用Scala写的,可能有些同学不熟悉Scala,在这里简单地把trait理解为Java里面的interface就可以。
import com.typesafe.config.Config
...
trait Plugin extends Serializable with Logging {
/**
* Set Config.
* */
def setConfig(config: Config): Unit
/**
* Get Config.
* */
def getConfig(): Config
/**
* Return true and empty string if config is valid,
return false and error message if config is invalid.
*/
def checkConfig(): (Boolean, String)
/**
* Get Plugin Name.
*/
def name: String = this.getClass.getName
/**
* Prepare before running, do things like set
config default value, add broadcast variable,
accumulator.
*/
def prepare(spark: SparkSession): Unit = {}
}
代码中,setConfig(), getConfig(), checkConfig()这3个方法,分别用来设置、获取、检查传入的插件配置;name 是插件名称的定义;preprare() 方法的作用是在插件开始处理数据之前,需要做的一些预处理逻辑可以在 prepare() 中实现。接下来,再定义所有 Source 的接口:
abstract class BaseSource[T] extends Plugin {
/**
* Things to do after filter and before output
* */
def beforeOutput: Unit = {}
/**
* Things to do after output, such as update offset
* */
def afterOutput: Unit = {}
/**
* This must be implemented to convert RDD[T] to
Dataset[Row] for later processing
* */
def rdd2dataset(spark: SparkSession, rdd: RDD[T]):
Dataset[Row]
/**
* start should be invoked in when data is ready.
* */
def start(spark: SparkSession, ssc: StreamingContext,
handler: Dataset[Row] => Unit): Unit = {
getDStream(ssc).foreachRDD(rdd => {
val dataset = rdd2dataset(spark, rdd)
handler(dataset)
})
}
/**
* Create spark dstream from data source, you can
specify type parameter.
* */
def getDStream(ssc: StreamingContext): DStream[T]
}
BaseSource的定义中,我们用到了泛型符号T,来指定通过 Source 获取到的 DStream 的数据类型。rdd2dataset(), getDStream(), start() ,这三个方法在 Source 插件的运行流程中完成从数据源获取数据,生成 RDD 并将 RDD 转换为Dataset,让流程后面的插件可以直接处理 Dataset,这跟我们之前的预期一样。
接下来定义所有Transform的接口:
abstract class BaseTransform extends Plugin {
def process(spark: SparkSession, df: Dataset[Row]): Dataset[Row]
}
这个接口看起来就要简单一点,只有一个 process() 方法,输入是上一个插件处理后输出的Dataset,输出是当前这个process()方法处理后生成的Dataset。最后再定义所有Sink的接口:
abstract class BaseSink extends Plugin {
def process(df: Dataset[Row])
}
这个也很简单,只有一个 process() 方法,输入是Dataset[Row],没有输出,因为在此处,插件的开发者实现自己的插件时,就需要把数据输出到外部存储系统了。
第二部:流程控制逻辑实现
开发出对应的流程控制逻辑,概括来说就是这几个步骤的流程控制(如图):

我们假设有一个描述数据处理流程的配置文件,内容是这样的:
# application.conf
source {
kafka {
topic = ...
consumer_group_id = ...
broker_list = ...
}
}
transform {
split {
fields = ["f1", "f2", "f3"]
source_field = "message"
}
}
sink {
elasticsearch {
hosts = ...
index = ...
bulk_size = ...
}
}
那么对于这个(以上)配置文件,通用计算引擎的流程控制逻辑是怎样的呢,我们一起来看下。分为这样的几个步骤:
- 第一步就是加载配置文件
- 第二部是根据第一步加载的配置,确认要加载哪些插件,然后去加载。
- 第三步就是根据第一步加载的配置,设置好各个插件的初始配置。
- 第四步,根据第一步加载的配置,把各个插件的使用顺序串联起来,组成 Pipeline Graph。
Pipeline Graph,用来表示计算引擎中各个插件处理数据的先后顺序。例如,对于刚刚讲到的配置文件,数据会从kafkaSource插件中读取到,然后进入引擎内部,经过splitTransform的处理后,最终通过elasticsearchSink输出到 Elasticsearch。 - 最后第五步的具体操作,则是需要启动 Pipeline。其实它的底层代码,就是对 Spark Streaming 中 StreamingContext 的
start()方法的包装。
由此,我们构建出了一个插件化体系,它有三个核心要素。其中,一个是插件API;再一个就是插件的具体实现;第三个核心要素就是流程控制逻辑。
讲到这里,你可能会问,在这个计算引擎中,这么精妙的插件化体系是如何设计出来的呢。其实,这是一个很著名软件设计方法,叫“控制反转”,或者叫“依赖注入”。“控制反转”可以用一句话来概括,也就是:上层不应该依赖底层,两者应该依赖抽象。我给它又加了一句,是这样的:明确区分什么是业务逻辑,什么是流程控制。
例如,对于我们设计的这个通用的计算引擎来说,上层指的是流程控制逻辑,底层指的是各个插件的具体实现,两者不会直接互相依赖,而是都依赖插件的API。如果我们想要设计出一个扩展性比较好的插件化体系,就必须很好地区分代码中哪里是业务逻辑,哪里是流程控制,这里的业务逻辑指的是插件的具体实现。
第三步: 常用插件的实现
接下来,我们再来讲讲第三部分,使用插件API,实现常见的Source、Transform、Sink插件。
现在我们只需要按照Source、Transform、Sink插件API的定义,实现自己的插件处理逻辑就可以。这里以生产环境中常用的插件为例,一起来看下经常会用到的插件有哪些。
常见的 Source 插件有:
- Kafka: 负责从消息队列 Kafka 中读取数据
- MySQL Binlog: 负责读取 MySQL 的 Binlog 日志
- HDFS: 负责读取 HDFS 文件数据
- Hive:负责读取Hive表中的数据
那么常见的 Transform 有:
- Split:负责字符串切割
- SQL:负责执行SQL语句,通过SQL完成数据处理以及数据聚合
- Json:对数据进行JSON解析
常见的 Sink 插件有:
- ClickHouse
- Elasticsearch
- MySQL
通用引擎的优势
刚刚讲到的这些,就是关于如何打造一个通用的计算引擎的内容,整体而言,这是比较详细的介绍。那么,这么做的优势是什么呢?
- 计算逻辑配置化模块化,很容易实现各种业务逻辑的计算
- 接入新的计算需求,近乎零开发成本
- 既满足80%的常用需求,又支持20%的个性化需求
- 在高度抽象的API上开发自己的业务逻辑更加简单/功能更加清晰
- 代码复用程度高
这里顺便延伸讲一下,在有了这些优势基础上,如果我们想把这个通用的计算引擎做得更好,可以考虑增加这几个功能:一个是监控,一个是WebUI。