一起做个简单的数据库(七):B树介绍

本系列文章一共13篇,本文为第7篇,请关注公众号,后续文章会陆续发布。
系列文章列表:
《手把手教你从零开始实现一个数据库系统》
《世上最简单的SQL编译器和虚拟机》
《一个在内存中仅能做追加操作的单表数据库》
《第一次测试 (含bug处理)》
《持久化存储》
《The Cursor Abstraction》
B树是SQLite用来表示表和索引的数据结构,因此它是一个非常重要的概念。本文将仅介绍数据结构,没有任何代码。
为什么树是数据库较好的一种数据结构?
搜索特定值的速度快(指数级logarithmic time)
插入/删除很快(constant-ish time to rebalance重新平衡的时间稳定)
遍历很快(和HASH MAP相比)
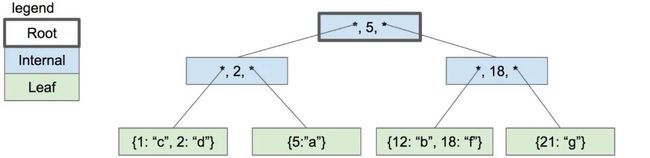
B树不同于二叉树(“B”可能是发明者的名字,但也可能是“平衡”的意思)。这是一个B树示例:
不同于二叉树,每个B树的节点都可以有两个以上的孩子,每个节点都可以至多有M个孩子,我们称M为树的阶(order)。为了使树保持平衡,我们规定节点必须至少有M/2个孩子(向上取整)。
例外情况:
叶子没有子节点
跟节点的数量可以小于M,要大于等于2
如果跟节点是叶子节点(意味着整个B树只有一个节点)它的子节点数仍然为0
上面的图片是一个被SQLite用来存储索引的B树。SQLite使用称为B+树的变体SQLite存储表。
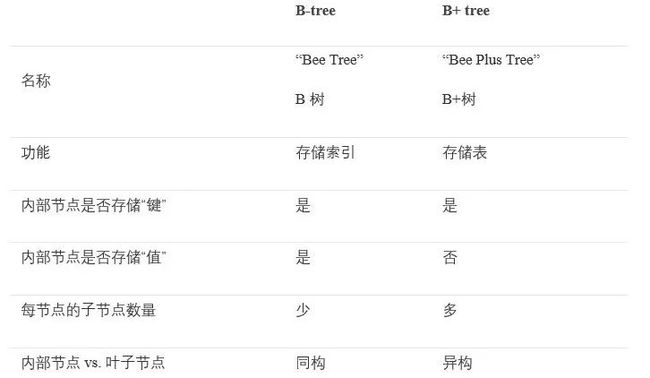
在实现索引之前,我将仅讨论B+树,但在这里我称其称为B树。
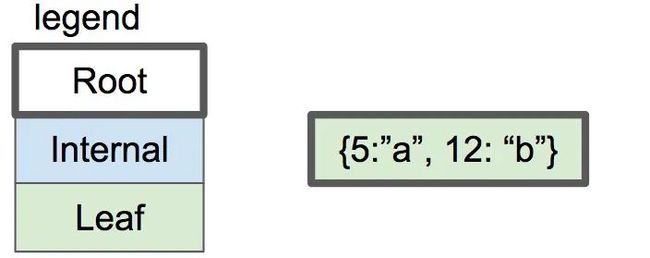
具有子节点的节点称为“内部”节点。内部节点和叶节点的结构不同:
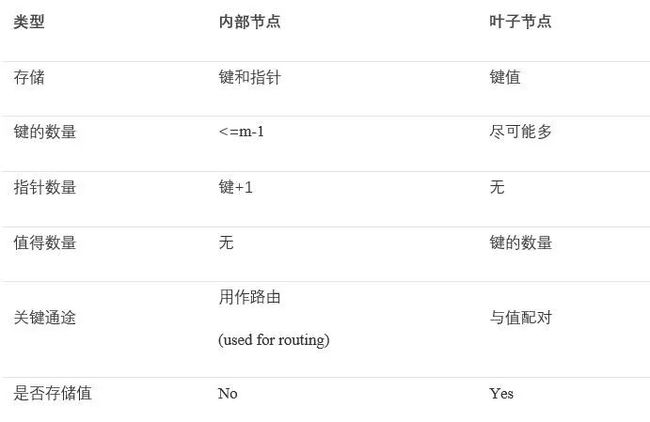
我们通过个例子来看看当我们向B树中插入个元素,B树是如何变化的。简单起见,树的阶数为3。这意味着:
每个内部节点最多有3个子节点
每个内部节点最多有2个键
每个内部节点最少有2个子节点
每个内部节点最少有1个键
一个空的B树只有一个节点,即根节点。这个根节点一开始等同于叶子节点,键值对为0:
空树
如果我们插入一个键值对,他们将按顺序存储在叶子节点中。
单节点B树
假设叶节点的容量是两个键/值对。当我们插入另一个键值对时,我们必须拆分叶节点,并在每个节点中放入键值对的一半。两个节点都成为新内部节点的子节点,原内部节点现在将成为根节点。
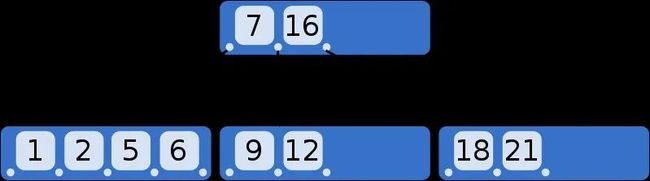
内部节点具有1个键和2个指向子节点的指针。如果我们要查找小于或等于5的键,我们在左侧子节点查找。如果我们想查找大于5的键,我们在右侧子节点查找。

我们继续添加键18和21。节点要再次拆分,但是父节点中没有空间可以容纳另一个键/指针对。

解决的办法是把根节点再拆分成2个内部节点,再新生成根节点作为这2个内部节点的父节点。
仅当我们不断地拆分根节点,B树的深度才会不断增加。每个叶子节点具有相同的深度,键值对的数量也趋近相同。所以B树保持平衡,并且查询也会很快。
直到我们实施插入操作之前,我不讨论如何从树中删除键。
当我们采用这种数据结构时,每个节点将对应一个页面。根节点将存在于页面0中。子指针将仅是包含子节点的页码。
下一篇,我们开始实现B树!
原文链接:https://cstack.github.io/db_tutorial/parts/part7.html
基于Kubernetes的DevOps实战培训

基于Kubernetes的DevOps实战培训将于2020年6月19日在上海开课,3天时间带你系统掌握Kubernetes,学习效果不好可以继续学习。本次培训包括:容器特性、镜像、网络;Kubernetes架构、核心组件、基本功能;Kubernetes设计理念、架构设计、基本功能、常用对象、设计原则;Kubernetes的数据库、运行时、网络、插件已经落地经验;微服务架构、组件、监控方案等,点击下方图片或者阅读原文链接查看详情。
