日志 7.13 pwn 堆溢出基础知识
十六进制两位表示一个字节
堆溢出
先上堆图:
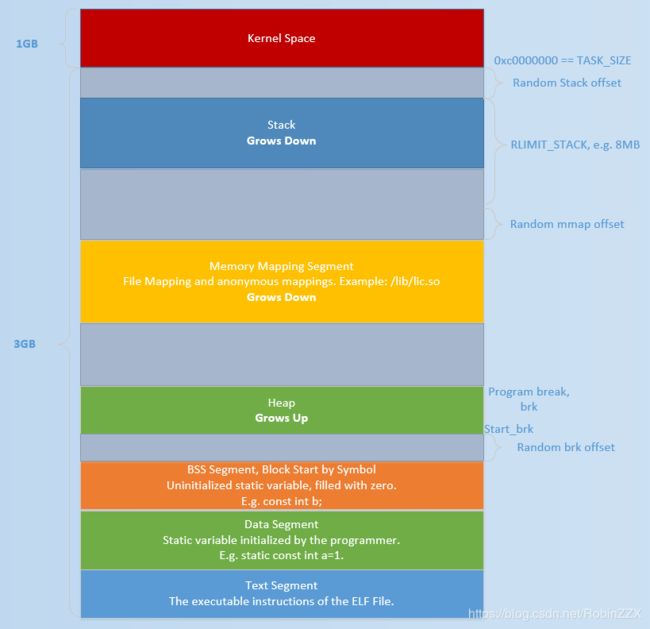
堆的数据结构
一般情况下,物理相邻的两个空闲 chunk 会被合并为一个 chunk
struct malloc_chunk {
INTERNAL_SIZE_T prev_size; /*上一个chunk空闲时记录上一个chunk的大小,上一个chunk被使用时作为上个chunk的数据部分 */
INTERNAL_SIZE_T size; /* 本chunk的大小,低三位是标志位*/
struct malloc_chunk* fd; /* 本chunk空闲时指向下一空闲的chunk,被使用时作为数据部分的指针 */
struct malloc_chunk* bk; /* 本chunk空闲时指向上一空闲的chunk,被使用时作为数据部分 */
/* 仅在大chunk中使用,指向的都是大的chunk ,用于对大的chunk按照大小排序,以减少遍历chunk的开销*/
struct malloc_chunk* fd_nextsize; /* 指向上一个与本chunk不同大小的chunk */
struct malloc_chunk* bk_nextsize; /* 指向下一个与本chunk不同大小的chunk */
};
size的低三位标志位从高到低是:
A:NON_MAIN_ARENA,是否不属于主线程,1 表示不属于,0 表示属于。
M:IS_MAPPED,是否由 mmap 分配
P:PREV_INUSE,是否被分配
bin
会根据空闲的 chunk 的大小以及使用状态将 chunk 初步分为 4 类:fast bins,small bins,large bins,unsorted bin
其中 unsorted bin, small bins,large bins 依次被组织到一个数组中,数组下标表示的是chunk上的fd或者bk指针,并不代表第几个bin。每一个bin中都是一个链表,包含着多个chunk
1 unsorted bin
没有排序的bin
来源:
1)当一个较大的 chunk 被分割成两半后,如果剩下的部分大于 MINSIZE,就会被放到 unsorted bin 中。
2)释放一个不属于 fast bin 的 chunk,并且该 chunk 不和 top chunk 紧邻时,该 chunk 会被首先放到 unsorted bin 中。
2 small bins
数组下标 2 - 63 是small bin,每一个bin下的链表存储着相同大小的chunk,每两个相邻的bin代表的大小为 2个机器字长
small bins 中每个 chunk 的大小与其所在的 bin 的 index 的关系为:chunk_size = 2 * SIZE_SZ *index,具体如下
| 下标 | SIZE_SZ=4(32 位) | SIZE_SZ=8(64 位) |
|---|---|---|
| 2 | 16 | 32 |
| 3 | 24 | 48 |
| 4 | 32 | 64 |
| 5 | 40 | 80 |
| x | 2*4*x | 2*8*x |
| 63 | 504 | 1008 |
分配采用 FIFO 的规则
3 large bin
small bin之后是large bin,一共有63个bin,每个bin代表一定范围内的chunk,相同大小的按照最近使用排列
以 32 位平台的 large bin 为例,第一个 large bin 的起始 chunk 大小为 512 字节,位于第一组,所以该 bin 可以存储的 chunk 的大小范围为 [512,512+64)。
| 组 | 数量 | 公差 |
|---|---|---|
| 1 | 32 | 64B |
| 2 | 16 | 512B |
| 3 | 8 | 4096B |
| 4 | 4 | 32768B |
| 5 | 2 | 262144B |
| 6 | 1 | 不限制 |
4 fast bin
当释放的空间大小小于MAX_FAST_SIZE时,为了节省下一次的遍历开销,会将这部分的空间存放到fastbin中,这样这些经常用到的小块就不用花时间在合并和分割上。(fastbin 范围的 chunk 的 inuse 始终被置为 1。因此它们不会和其它被释放的 chunk 合并。)
分配采用LIFO后进先出的规则
fastbin 最多可以支持的 bin 的个数为 10 个
/* The maximum fastbin request size we support */
#define MAX_FAST_SIZE (80 * SIZE_SZ / 4)
默认情况下(32 位系统为例), fastbin 中默认支持最大的 chunk 的数据空间大小为 64 字节
top chunk
地址最高的chunk
当所有的bin都无法满足时,若 top chunk 大于申请的空间,则分割,分割后剩余的部分作为新的 top chunk。
初始情况下,我们可以将 unsorted chunk 作为 top chunk。
名词:
chunk:块
arena:操作系统分配给程序的一块较大的(大于所申请的)内存区域
last remainder:在用户使用 malloc 请求分配内存时,ptmalloc2 找到的 chunk 可能并不和申请的内存大小一致,这时候就将分割之后的剩余部分称之为 last remainder chunk ,unsort bin 也会存这一块。top chunk 分割剩下的部分不会作为 last remainer.
堆操作:
- malloc(size_t n)
返回对应大小字节的内存块的指针
当 n=0 时,返回当前系统允许的堆的最小内存块
当 n 为负数时,由于在大多数系统上,size_t 是无符号数(这一点非常重要),所以程序就会申请很大的内存空间,但通常来说都会失败,因为系统没有那么多的内存可以分配
使用brk申请的堆空间会挨着数据段,而使用mmap的堆空间在较高的地址
这些内存在释放之后一般不会返回系统而是在程序中等待申请
malloc()会使用两种系统调用:
1)brk()或者sbrk()函数
操作系统提供了 brk 函数,glibc 库提供了 sbrk 函数,sbrk会调用brk
初始时,堆的起始地址 start_brk 以及堆的当前末尾 brk 指向同一地址
brk(address) 直接将program break修改到address,返回值 0成功 -1 失败
sbrk(n) 修改program break向高地址增长n个字节,返回开辟之前的program break地址
sbrk(0)返回当前program break的地址
但是program break的增长不是无限制的,天花板是Memory Mapping Segment
2)mmap()
当申请的空间大于128k时,malloc()调用mmap()
- free(void* p)
会释放由 p 所指向的内存块
当 p 为空指针时,函数不执行任何操作
当 p 已经被释放之后,再次释放会出现乱七八糟的效果,这其实就是double free
除了被禁用 (mallopt) 的情况下,当释放很大的内存空间时,程序会将这些内存空间还给系统,以便于减小程序所使用的内存空间
申请空间
malloc --> __libc_malloc --> _int_malloc
__libc_malloc(size)
用户申请的字节一旦进入申请内存函数中就变成了 无符号整数。
寻找钩子hook ----》 寻找arena ----》 调用_int_malloc分配内存 -+--》成功,返回内存
↑ |
| ↓
+-----分配失败,再寻找一个arena
_int_malloc()
--------------------------------------------------------------------------------
将size转化为对应的chunk大小 ----》 fastbin ----》 遍历(后进先出),检查大小是否符合 ----》 符合则计算索引 ----》 chunk转换为内存返回
根据大小选择bin ----》 smallbin ----》获取索引、指针 ----》 检查该bin是否为空 ----》 不为空 ----》将链表中最后一个chunk分配(先进先出)
| +----》 初始化
+---》 该bin为空
----》 不在fastbin和smallbin中 ----》 malloc_consolidate():处理fastbin ----》 可以合并的合并,然后放 unsorted bin ----》大循环
----------------------------------------------------------------------------------
大循环 ----》 遍历unsorted bin ----》 FIFO寻找大小刚好合适的bin ----》若有,bin转为内存后返回
循环10000次 ----》若没有,则将当前的unsorted bin按照大小放至对应的small或large中
----》 遍历large bin ----》对应的 bin 中从小(链表尾部)到大(头部)进行扫描 ----》 找到第一个合适的返回
----》 若大小合适的bin都不存在,则在map中找更大的bin遍历 ----》 找到,返回内存
----》 找不到,使用top chunk ----》 满足,分割后返回
----》 不满足,使用 sysmalloc 来申请内存
------------------------------------------------------------------------------------
//从 fastbin 的头结点开始取 chunk(LIFO)
sysmalloc()
用于当前堆内存不足时,需要向系统申请更多的内存
函数内调用了brk()和mmap()
释放空间
free --> __libc_free --> _int_free
_int_free()
检查 ----》是否fastbin ----》是fastbin,放至fastbin链表表头
+---》是否mmap分配 ----》 是,munmap_chunk()
+---》 否,合并chunk ----》 向低地址合并 ----》想高地址合并 ----》 下一个是否是top chunk ----》 是,合并到top chunk
+---》 否,合并加入unsorted bin
tcache
ubuntu 17.10中的新数据结构,提升了堆的性能,牺牲了一定的安全性能
堆溢出原理
条件:
- 可以写入堆
- 大小无限制
利用策略:
- 覆盖下一chunk的内容
- 利用堆机制实现任意地址写
要点
由低地址向高地址方向增长
堆管理器会对用户所申请的字节数进行调整,这也导致可利用的字节数都不小于用户申请的字节数
puts()内部会调用 malloc 分配堆内存
rwxp中的p权限是指隐私数据
一个程序一旦编译好后,text segment ,data segment 和 bss segment 是确定下来的
堆分配的最小单位是机器字长的2倍,32 位系统最小是 8 个字节,64 位系统最小是 16 个字节,比如 64 位系统执行malloc(0)会返回用户区域为 16 字节的块。
prev_size字段为8字节
strlen 是我们很熟悉的计算 ascii 字符串长度的函数,这个函数在计算字符串长度时是不把结束符 ‘\x00’ 计算在内的,但是 strcpy 在复制字符串时会拷贝结束符 ‘\x00’
qword是四字节
申请一个超大的块,来使用 mmap 扩展内存。因为 mmap 分配的内存与 libc 之前存在固定的偏移因此可以推算出 libc 的基地址
堆分配函数
- malloc(size):见上文“堆操作”
- calloc(size):calloc 在分配后会自动进行清空,这对于某些信息泄露漏洞的利用来说是致命的
calloc(0x20);
//等同于
ptr=malloc(0x20);
memset(ptr,0,0x20);
- realloc(ptr,size)
当 realloc(ptr,size) 的 size 不等于 ptr 的 size 时
1)如果申请 size > 原来 size
----如果 chunk 与 top chunk 相邻,直接扩展这个 chunk 到新 size 大小
----如果 chunk 与 top chunk 不相邻,相当于 free(ptr),malloc(new_size)
2)如果申请 size < 原来 size
----如果相差不足以容得下一个最小 chunk(64 位下 32 个字节,32 位下 16 个字节),则保持不变
----如果相差可以容得下一个最小 chunk,则切割原 chunk 为两部分,free 掉后一部分
3)当 realloc(ptr,size) 的 size 等于 0 时,相当于 free(ptr)
当 realloc(ptr,size) 的 size 等于 ptr 的 size,不进行任何操作
危险函数标志
输入
gets,直接读取一行,忽略 ‘\x00’
scanf
vscanf
输出
sprintf
字符串
strcpy,字符串复制,遇到 ‘\x00’ 停止
strcat,字符串拼接,遇到 ‘\x00’ 停止
bcopy
调试方法
cat /proc/pid/maps 可以查看该进程内存映射
查看堆:
vmmap:查看堆地址
x/10gx addr:64位地址宽度以16进制打印10个地址内容
find xxxx:用来寻找你的输入内容
具体漏洞类型
- off_by_one 单字节溢出
1)溢出可控制任意字节:修改size来泄露或者覆盖其他数据
2)溢出NULL:在 size 为 0x100 的时候,溢出 NULL 字节可以使得 prev_in_use 位被清,这样前块会被认为是 free 块。
(1) 这时可以选择使用 unlink 方法(见 unlink 部分)进行处理。
(2) 另外,这时 prev_size 域就会启用,就可以伪造 prev_size(间接控制本chunk的size) ,从而造成块之间发生重叠。此方法的关键在于 unlink 的时候没有检查按照 prev_size 找到的块的后一块(理论上是当前正在 unlink 的块)与当前正在 unlink 的块大小是否相等