ShardingSphere对接京东白条实战
—
“作者
张永伦,京东数科高级软件工程师,Apache ShardingSphere(Incubating) PPMC。长期从事分布式系统的高可用、高并发相关工作。热衷于网络IO、性能优化方面的技术挑战。目前专注于Sharding-Proxy的持续优化和PostgreSQL协议的开发工作。2018年11月10日,ShardingSphere进入Apache孵化器,团队在经历了短暂的庆祝和喜悦后,立即投入到了3.1.0的开发工作中。3.1.0版本首次支持了DISTINCT子句,并且在全新解析引擎的支持下,能够100%兼容路由至单一数据节点的全部SQL(目前仅MySQL)。正是在这两个重要特性的支持下,Apache ShardingSphere迎来了2018年度的最后一个挑战:对接京东金融的杀手级应用——京东白条!

激活京东白条,请扫描二维码↑↑↑
京东白条由于业务体量巨大,数据库不可避免地进行了水平拆分。拆分之后的数据节点规模达到了十万级别,是极度少见的金融级、高并发、海量数据并存的应用系统。为了追求性能极致以及代码的可控性,京东白条之前是在业务框架中,根据分片键替换数据库和表名称进行分片的。
随着业务的发展,通过业务框架进行分片的方式,使得代码的维护成本不断攀升。ShardingSphere在经过了大量系统的验证之后,理所当然的成为了京东白条的数据分片中间件的首选方案,ShardingSphere团队也非常愿意帮助京东白条团队解耦业务和底层技术代码,缓解开发工程师肩上的重担。
虽然开源三年有余,ShardingSphere经历了大量系统的检验,项目已经相对成熟,但面对国内乃至世界上屈指可数的京东金融王牌级产品,仍将是一次严峻的考验。而事实上,对接工作也确实不是一帆风顺,遇到了很多在以往系统上遇不到的深层次问题。本文将这些问题的解决过程记录下来,供大家参考。

分布式链路追踪系统
值得一提的是,本次对接大量运用了分布式链路追踪技术,对问题定位起到了事半功倍的作用。京东数科平台开发部的SGM(Service Governance And Monitoring),是一套致力于分布式服务监控、跟踪、预警的综合服务治理解决方案,是实现全链路监控的基础。它的特点:
亚秒级延迟(被监控方法从调用产生到图形展示、预警的总延时在10秒左右)
代码零侵入(启动脚本指定探针即可实现全链路的监控与预警)
全链路分析,快速故障定位(调用链整体分析,每个节点数据库耗时、缓存耗时、日志耗时、网络耗时一目了然,快速根源问题定位)
高吞吐,弹性伸缩(数据结构及算法极度优化,单核心支持5000QPS的计算量,支持横向扩容)
性能影响小(服务平均响应时间在5ms时,性能影响小于3%)
多维度业务监控(灵活可配置的多维度业务监控,如分类监控、比值监控、累加监控、状态转移监控、业务流程监控等)
更多详情请点击官网: http://imsgm.io
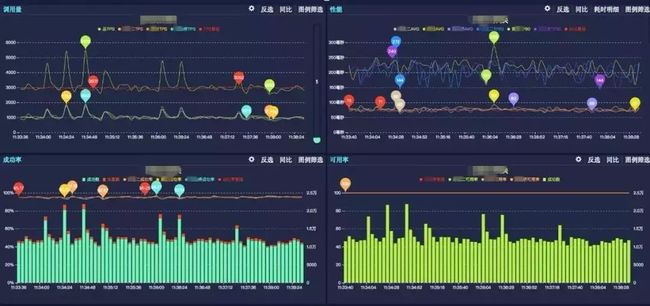
连接池配置
很多人根据经验或公式设置数据库连接池的大小,从几十到几百都有。但对于大规模分布式系统,每个实例可能只允许分配2~3个连接。比如,500个实例的系统,每个实例分配3个连接,那么对于一个MySQL实例来说就产生了1500个连接。这种配置下,数据库连接的问题会被无限放大,任何风吹草动都会导致getConnection()超时等问题。这次对接暴露出的问题,多少都与这种配置有关,所以有必要在前面单独说明一下。京东白条为了更高的性能以及无中心化架构,采用了Sharding-JDBC作为数据分片的接入端,但同时也不得不面对应用实例过多会占用数据库大量连接的问题,因此需要将每个应用的连接数降至最低。


问题1 请求响应时间变长
现象
集成ShardingSphere后,请求响应较白条原系统慢,且GC比原系统多。
分析
经过一段时间的观察,这个问题在几分钟后逐步恢复。查看线程使用情况,发现系统启动后,线程数量飙升。

而原系统的线程数量稳定。同时,还发现新系统的负载也比较高。

看到这个现象后,问题就很容易定位了。熟悉ShardingSphere的小伙伴都知道,程序启动后会对所有分表的Metadata进行校验。对于几十,几百张表的校验,用户几乎感知不到,但面向十万级别的数据库表,再加上业务的压力,导致校验需要几分钟才能完成,严重降低系统性能。
处理
Metadata的校验是非常有必要的,之前是强制必须校验。经过讨论决定,将校验调整为可配置,用户可以通过check.table.metadata.enabled属性设置是否校验,默认不校验。
问题2 获取数据库连接超时
现象
随着业务量的增加,系统频繁抛出异常: java.sql.SQLTransientConnectionException: HikariPool-25 - Connection is not available, request timed out after 3000ms.
同时,大量的请求超时,监控平台不停报警。
分析
通过SGM的秒级监控,可以看到平均响应时间达到3秒,TP99高于15秒。

看到这个异常后,首先怀疑的是有慢SQL,会导致数据库连接被长时间占用,连接池队列阻塞,大量超时,比较容易解释这个现象,但可能性较小。
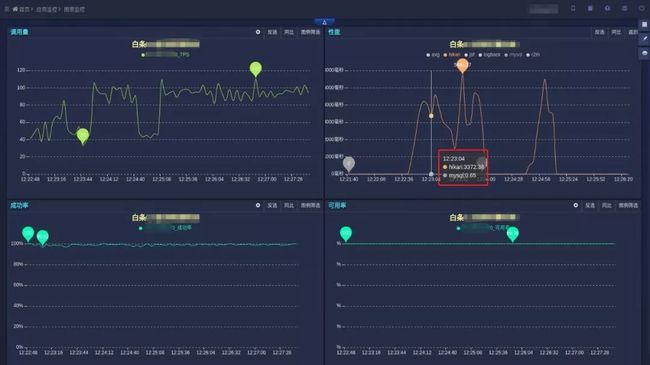
事实上,确实不是慢SQL的问题,随便找一次请求,显示Hikari耗时3372ms,MySQL耗时0.65ms,一定还存在更深层次的问题。是性能问题吗?可是其他系统从来没有测出过如此差的性能,Sharding-JDBC相对于原始JDBC的损耗是很小的。
经过一番波折,又有了新的发现。在查看某个接口完整调用链的时候,发现了getConnection()被调用了6次,但只执行了3次SQL。多出来一倍的getConnection()干什么?这又与获取连接超时有什么关系呢?
还是在调用链中,发现了业务框架会在每次执行SQL前调用getMetaData()方法进行元数据检查,这个方法返回一个DatabaseMetaData对象,并且需要额外占用一个连接。这就能解释,为什么getConnection()被调用了6次,但只执行了3次SQL了。连接消耗大了一倍,连接池又配置的那么小,所以超时很合理吧?
了解Apache ShardingSphere原理的小伙伴会知道,Sharding-JDBC的Connection对象是先于真正的数据库Connection对象创建的,原因是如果不知道当前要执行SQL,是无法预知最终分片结果的,因此也无法预先创建与数据库的真实连接。业务框架在每次执行SQL前调用getMetaData()方法,ShardingSphere只能在将第一个真实数据源的MetaData取出。这就造成了无论最终执行的SQL路由在那个数据分片,所有的getMetaData()操作都将路由至第一个真实数据源。显然,单一的数据源难以承受来自白条系统的全部压力,因此导致了该数据源的连接获取超时。
处理
解决方法比较简单,缓存DatabaseMetaData对象,每次调用getMetaData()直接返回缓存结果。当时并没有意识到,DatabaseMetaData被缓存的同时,也保持了与每一个物理库的连接。但是,这次更新为另一个大型翻车埋下了伏笔。
问题3 SQL解析耗时高
现象
SQL解析偶尔出现几十毫秒的耗时。这是在SGM中对parse()方法的耗时进行排序时发现的。

分析
ShardingSphere在3.1.0版为了更好的SQL兼容性,采用基于ANTLR的解析引擎,其效率比原有自研解析引擎会低一些。但是由于解析结果的缓存,真实应用时,影响可以忽略不计。上图中的系统已经运行了几个小时,不存在新出现并未加入缓存的SQL情况,因此基本可以断定是缓存出了问题。
处理
直接看缓存的代码,解析结果是通过弱引用保存的。弱引用遇到GC就会被回收,应该改成软引用,软引用只会在OOM之前的那次GC被回收。
问题4 获取数据库连接超时
现象
标题怎么跟问题2重复了?是的,前面一顿操作猛于虎,本以为可以高枕无忧了,然而却被现实啪啪打脸。依然抛异常,获取连接依然失败,而且响应时间居高不下,也就比原系统慢个六七倍吧。

经过一段时间的观察,又发现了响应时间很不稳定,存在较大的抖动。

同时,Young GC频率明显比原系统高。

分析
是时候认真分析一下这个异常了:java.sql.SQLTransientConnectionException: HikariPool-25 - Connection is not available, request timed out after 3000ms.
之所以会抛出这个异常,与HikariCP的两个参数有关:

如果你的应用等待连接池中连接的时间超过connectionTimeout,就会抛出上面那个异常,所以Connection is not available, request timed out after 3000ms,说明这个参数白条配置的是3000。

这个参数控制了连接池的大小,如果maximumPoolSize个连接都不空闲,那么新的getConnection()会在一个队列里阻塞住,然后要么排队拿到连接,要么等待时间到达connectionTimeout后抛出异常。
对于当前系统,要满足什么条件才会出现这个异常呢?我们按一个请求1ms计算,3个连接处理同步请求,每个连接每秒处理1000个,那么吞吐就是3000。就是说,即使你从图上即使看到QPS是3000,连接池的队列里都不用排队的,不会存在积压,不积压就不会超时。如果积压了,就一定会超时,即使1秒只积压1个请求,按照当前的配置,排队3秒,需要队列里有9000个请求,其中的第9000个请求会超时。所以,9000秒之后,就会持续不断的抛异常。
从图上可以看到,这个实例的QPS才100左右,所以即使峰值比现在高10倍,也是抗的住的(不考虑其他资源瓶颈的情况)。心里有了这把尺子,就知道,当前连接池承受的压力,至少是正常情况的几十倍。第一时间就会怀疑存在SQL全路由的情况。这里补充一下,系统正常运行情况下,SQL只会路由到一个真实表。全路由指的是SQL被路由到所有的真实库或真实表。如果是库全路由,会增加几十倍的查询,如果是表全路由,会增加几千倍的查询。
一条逻辑SQL期望路由到一个物理表,对应一次getSQLExecuteGroup调用。在SGM中过滤出慢SQL,查看其完整调用链,发现getSQLExecuteGroup被调用了n次,基本可以确定是全路由的情况。下图就是真实翻车现场:

全路由使系统的压力数十倍的增加,不仅会造成getConnection()超时,还会导致系统响应时间抖动和GC频繁等问题。
处理
根据调用链中的接口,找到逻辑SQL,类似:

这个包含子查询的SQL没有解析正确,导致被路由至全库。
另一个SQL是CASE WHEN语法没有解析正确,同样被路由至全库:

修复这两个Bug后,系统恢复正常,再也没出现类似的异常。
PS:以上两个举例的两个SQL并非京东白条的业务系统真实SQL。
问题5 启动8小时后服务不可用
现象
服务在毫无征兆的的情况下,瞬间变为不可用。

查看日志,发现异常信息:
com.mysql.jdbc.exceptions.jdbc4.MySQLNonTransientConnectionException:
No operations allowed after connection closed.
分析
为什么是8小时呢?根据异常信息,自然联想到某个定时器超时导致连接被释放,然后这个被释放的连接又被服务拿到了去进行数据库操作。首先想到的就是MySQL的wait_timeout和interactive_timeout两个参数。

interactive_timeout针对交互式连接,wait_timeout针对非交互式连接。所谓的交互式连接,即在mysql_real_connect()函数中使用了CLIENT_INTERACTIVE选项。说得直白一点,通过MySQL客户端连接数据库是交互式连接,通过JDBC连接数据库是非交互式连接。他们的默认值都是28800秒,也就是8小时。再一查日志,从启动到不可用这段时间也差不多8小时,貌似找到了问题的原因。
可是,在MySQL文档里写的很清楚,连接只有在8小时什么也不干的情况才会被关闭。而我们的情况是,挂掉的前一秒还在干活。

在这里纠结了很久,直到检查白条应用配置的时候看到了HikariCP的maxLifetime参数:

这个参数的原理不同于MySQL的timeout,它并不探测连接是否一直在活跃中,它的原理更加类似于缓存中的TTL概念,只要时间一到,做完当前工作后即会优雅关闭。京东白条中这个值是28770,也和日志吻合。好了,终于证明了8小时后连接会关闭,然而并没有什么用,因为连接关闭后会被连接池清理掉,下一次getConnection()不会拿到已经关闭的连接。
还记得之前我们缓存的DatabaseMetaData吗?它在系统启动的时取出DatabaseMetaData并缓存,以供应用在获取到真实的数据库连接之前调用getMetaData()时使用,缓存了DatabaseMetaData的引用之后,就将该连接关闭了。由于应用一直可以正常运行,因此让我们产生了一个错觉,认为缓存的DatabaseMetaData引用实际是无需连接的,因为连接关了仍然可用。但我们忽略了连接池的特性,采用了连接池的连接关闭,其实并不是真正的断开与数据库的连接,而是将其归还给了连接池,以便于其他请求复用。因此,缓存一份引用的DatabaseMetaData仍然在隐式的使用当初创建它的那个连接。直到maxLifetime时间阈值,这个连接才真正被关闭,导致所有对DatabaseMetaData的操作,仍然使用那个被关闭的连接而产生异常。
处理
把DatabaseMetaData常用方法的返回结果也缓存,完成之后关闭连接,也就是把连接还给连接池。最后既解决了问题,也节省了一个连接。顺便吐个槽,DatabaseMetaData这个接口好几百个方法,完全实现了一遍,工作量还是很大的。
当前进展

现在,ShardingSphere已经平稳的在白条生产环境运行了几周,性能与原生JDBC几乎一致,GC次数,资源消耗也未见异常。

与白条的对接还在继续,不知道以后还会遇到什么问题。在经历了这轮血腥洗礼后,我们相信,以后不管再遇到什么问题,都会有底气的说一句:这是常规操作。
经历了京东白条的挑战,使ShardingSphere的稳定性得到了进一步的提升。关注ShardingSphere的小伙伴们,你们有计划使用ShardingSphere了么?
福利
想了解问题定位神器SGM?
https://mp.weixin.qq.com/s/EHC1M_TIR5tyyp1oCSJTww
![]()
Apache ShardingSphere(Incubating)自2016开源以来,不断精进、不断发展,被越来越多的企业和个人认可:Github上收获6000+的stars,70+公司企业的成功案例。此外,越来越多的企业和个人也加入到Apache ShardingSphere(Incubating)的开源项目中,为它的成长和发展贡献了巨大力量。
我们从未停息过脚步,聆听社区伙伴的需求和建议,不断开发新的、强大的功能,不断使其健壮可靠!
开源不易, 我们却愿向着最终的目标,步履不停!
那么,正在阅读的你,是否可以助我们一臂之力呢?分享、转发、使用、交流,以及加入我们,都是对我们最大的鼓励!
项目地址:
https://github.com/apache/incubator-shardingsphere
更多信息请浏览官网:
http://shardingsphere.apache.org/

扫码进群
