date: 2017-02-03 19:59:33

教务系统爬虫工作初步完成
关于教务系统的一系列爬取工作已经初步完成,Holi爬虫组的工作也算正式进入优化阶段。
我们需要根据后台组的需要,转换成CVS或数据库形式。需要和后台组进行商量。
实现的功能
模拟登陆
- 此为爬取数据的第一步,之前试过很多方法,遇到的问题也各种各样。
问题的解决:
模拟登陆需要很多东西,一定要根据抓包来进行数据分析,分析报头的组成形式,再模拟报头所需的东西进行模拟post。
- 模拟登陆作为爬取教务系统的第一步,花的时间也比较久。在学习模拟登陆上也花了很多时间。
- 通过此次模拟登录的实现,了解到了从发送其请求,到浏览器解析出的网页的整个过程。
鲁棒性问题:
之前缺少所需的报头消息而意外的触发了教务系统的验证码机制。现在报头已经完整,只要学号密码正确是不会触发验证码机制的。但是,如果学号或密码输入错误,是会触发验证码机制的。简单的验证码可以使用Python来进行OCR识别,但是教务处的验证码比较复杂。此问题的解决方案暂定为讲验证码图片呈现给用户,让其进行手动输入。
课表的爬取
- 课表的行列组合比较复杂,这里只是简单的把课表消息从HTML中解析出来。
后期的工作重点仍在HTML解析和数据处理方面。需要和后台组沟通。
课表的技术文档在上一次文档中简单讲过,现在为了整体阅读性,将其搬移过来:
1、init():两个URL分别为用抓包软件获取的实际登录网址和实际提交账号密码的网址。
2、login():用抓包软件获取的用Chrome浏览器登录教务处的head报文,login()为模拟登录教务处的所需信息。
3、Print():将登录进去的课程表HTML网页打印出来。
4、使用前请确认安装BeautifulSoup模块。请修改里面的学号id和password再进行运行。
5、后续将从HTML网页中提取出有用的信息。
6、运行login()后便可以登录进教务处系统,修改Print()中的URL即可完成不同信息的获取,比如换成成绩网页的URL、教务通知的URL等等。
成绩查询
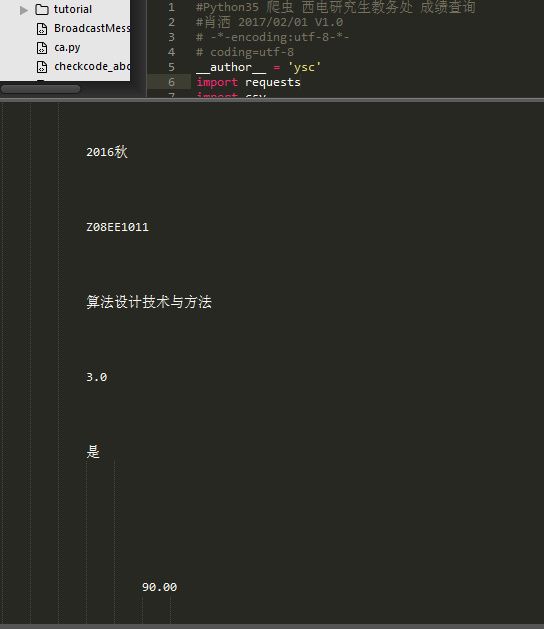
- 在 Print 函数中将 get 的网址换成课表的网址即可进行爬取。
- 对返回的HTML进行了简单的解析,提取了简单的标签,获取的数据可读性不是很强。
- 与课表的问题一样,后期的重点仍在数据处理。
通知公告的爬取

在西电,最令人烦恼就是你今天去上课了,可是老师翘课了!!!
- 一般情况下学生是不会经常去刷教务处网页的,但是教务系统有一个滚动的通知公告。
- 只要有老师在上面发布调课通知或考试通知,上面就显示。
- 这上面的公告是全校性的。
- 同理,这个网页的解析提取比较简单,数据看起来也很和谐。
我的消息

- 只要用户的老师翘课或者出成绩,个人就会收到该通知。
- 这个功能的实现,也可以解决后台组一直提倡的个性化推送,教务处已经帮咱们实现了,哈哈哈!
- 后期我们只需要隔断时间判断是否有新的通知产生即可得到最新的消息,弹窗通知给用户即可。
待解决的问题
数据处理!!这个的工作量和爬取来比还是比较大的。
但是已经迈出了第一步,后面的路会好走许多。
come on !
附代码,作备份。
1、课表
#Python35 爬虫 西电 研究生教务处 课表
#注:请修改login()学号密码进行爬取
#肖洒 2017/1/19 V1.0
# -*-encoding:utf-8-*-
# coding=utf-8
__author__ = 'ysc'
import requests
import csv
from bs4 import BeautifulSoup
class ScrapeGrade:
def __init__(self, auth_url=None, log_url=None):
if not auth_url:
self.auth_url = "http://ids.xidian.edu.cn/authserver/login?service=http%3A%2F%2Fjwxt.xidian.edu.cn%2Fcaslogin.jsp"
self.log_url = "http://jwxt.xidian.edu.cn/caslogin.jsp"
else:
self.auth_url = auth_url
self.log_url = log_url
self.session = requests.Session()
def login(self, id='学号', password='密码'):
r = self.session.get(self.auth_url)
data = r.text
bsObj = BeautifulSoup(data, "html.parser")
lt_value = bsObj.find(attrs={"name": "lt"})['value']
exe_value = bsObj.find(attrs={"name": "execution"})['value']
params = {'username': id, 'password': password,
"submit": "", "lt": lt_value, "execution": exe_value,
"_eventId": "submit", "rmShown": '1'}
headers = {'User-Agent': "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:44.0) Gecko/20100101 Firefox/44.0",
'Accept': "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Language": "zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3",
"Accept-Encoding": "gzip, deflate",
"Referer": "http://ids.xidian.edu.cn/authserver/login?service=http%3A%2F%2Fjwxt.xidian.edu.cn%2Fcaslogin.jsp",
"Content-Type": "application/x-www-form-urlencoded"}
s = self.session.post(self.auth_url, data=params, headers=headers)
s = self.session.get(self.log_url)
def Print(self):
grade_page = self.session.get("http://yjsxt.xidian.edu.cn/eduadmin/findCaresultByStudentAction.do")
bsObj2 = BeautifulSoup(grade_page.text, "html.parser")
nameList = bsObj2.findAll("td", {"class":"textCenter"})
for name in nameList:
print(name.get_text())
if __name__ == '__main__':
# 初始化爬虫对象
sg = ScrapeGrade()
# 登录(在此处传入正确的个人学号与密码信息)
sg.login(id='学号', password='密码')
sg.Print()
2、通知公告
#Python35 爬虫 西电研究生教务处 通知公告
#注:请修改 login()学号密码进行爬取
#肖洒 2017/1/25 V1.0
# -*-encoding:utf-8-*-
# coding=utf-8
__author__ = 'ysc'
import requests
import csv
from bs4 import BeautifulSoup
class ScrapeGrade:
def __init__(self, auth_url=None, log_url=None):
if not auth_url:
self.auth_url = "http://ids.xidian.edu.cn/authserver/login?service=http%3A%2F%2Fjwxt.xidian.edu.cn%2Fcaslogin.jsp"
self.log_url = "http://jwxt.xidian.edu.cn/caslogin.jsp"
else:
self.auth_url = auth_url
self.log_url = log_url
self.session = requests.Session()
def login(self, id='学号', password='密码'):
r = self.session.get(self.auth_url)
data = r.text
bsObj = BeautifulSoup(data, "html.parser")
lt_value = bsObj.find(attrs={"name": "lt"})['value']
exe_value = bsObj.find(attrs={"name": "execution"})['value']
params = {'username': id, 'password': password,
"submit": "", "lt": lt_value, "execution": exe_value,
"_eventId": "submit", "rmShown": '1'}
headers = {'User-Agent': "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:44.0) Gecko/20100101 Firefox/44.0",
'Accept': "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Language": "zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3",
"Accept-Encoding": "gzip, deflate",
"Referer": "http://ids.xidian.edu.cn/authserver/login?service=http%3A%2F%2Fjwxt.xidian.edu.cn%2Fcaslogin.jsp",
"Content-Type": "application/x-www-form-urlencoded"}
s = self.session.post(self.auth_url, data=params, headers=headers)
s = self.session.get(self.log_url)
def Print(self):
grade_page = self.session.get("http://yjsxt.xidian.edu.cn/info/findAllBroadcastMessageAction.do?flag=findAll")
bsObj2 = BeautifulSoup(grade_page.text, "html.parser")
nameList = bsObj2.findAll("td", {"class":"textTop"})
for name in nameList:
print(name.get_text())
if __name__ == '__main__':
# 初始化爬虫对象
sg = ScrapeGrade()
# 登录(在此处传入正确的个人学号与密码信息)
sg.login(id='学号', password='密码')
sg.Print()
3、成绩查询
#Python35 爬虫 西电研究生教务处 成绩查询
#注:请修改login()学号密码进行爬取
#肖洒 2017/02/01 V1.0
# -*-encoding:utf-8-*-
# coding=utf-8
__author__ = 'ysc'
import requests
import csv
from bs4 import BeautifulSoup
class ScrapeGrade:
def __init__(self, auth_url=None, log_url=None):
if not auth_url:
self.auth_url = "http://ids.xidian.edu.cn/authserver/login?service=http%3A%2F%2Fjwxt.xidian.edu.cn%2Fcaslogin.jsp"
self.log_url = "http://jwxt.xidian.edu.cn/caslogin.jsp"
else:
self.auth_url = auth_url
self.log_url = log_url
self.session = requests.Session()
def login(self, id='学号', password='密码'):
r = self.session.get(self.auth_url)
data = r.text
bsObj = BeautifulSoup(data, "html.parser")
lt_value = bsObj.find(attrs={"name": "lt"})['value']
exe_value = bsObj.find(attrs={"name": "execution"})['value']
params = {'username': id, 'password': password,
"submit": "", "lt": lt_value, "execution": exe_value,
"_eventId": "submit", "rmShown": '1'}
headers = {'User-Agent': "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:44.0) Gecko/20100101 Firefox/44.0",
'Accept': "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Language": "zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3",
"Accept-Encoding": "gzip, deflate",
"Referer": "http://ids.xidian.edu.cn/authserver/login?service=http%3A%2F%2Fjwxt.xidian.edu.cn%2Fcaslogin.jsp",
"Content-Type": "application/x-www-form-urlencoded"}
s = self.session.post(self.auth_url, data=params, headers=headers)
s = self.session.get(self.log_url)
def Print(self):
grade_page = self.session.get("http://yjsxt.xidian.edu.cn/queryScoreByStuAction.do")
bsObj2 = BeautifulSoup(grade_page.text, "html.parser")
nameList = bsObj2.findAll("td")
for name in nameList:
print(name.get_text())
if __name__ == '__main__':
# 初始化爬虫对象
sg = ScrapeGrade()
# 登录(在此处传入正确的个人学号与密码信息)
sg.login(id='学号', password='密码')
sg.Print()
4、我的消息
#Python35 爬虫 西电研究生教务处 我的消息(系统消息、成绩提示等)
#注:请修改login()学号密码进行爬取
#肖洒 2017/02/01 V1.0
# -*-encoding:utf-8-*-
# coding=utf-8
__author__ = 'ysc'
import requests
import csv
from bs4 import BeautifulSoup
class ScrapeGrade:
def __init__(self, auth_url=None, log_url=None):
if not auth_url:
self.auth_url = "http://ids.xidian.edu.cn/authserver/login?service=http%3A%2F%2Fjwxt.xidian.edu.cn%2Fcaslogin.jsp"
self.log_url = "http://jwxt.xidian.edu.cn/caslogin.jsp"
else:
self.auth_url = auth_url
self.log_url = log_url
self.session = requests.Session()
def login(self, id='学号', password='密码'):
r = self.session.get(self.auth_url)
data = r.text
bsObj = BeautifulSoup(data, "html.parser")
lt_value = bsObj.find(attrs={"name": "lt"})['value']
exe_value = bsObj.find(attrs={"name": "execution"})['value']
params = {'username': id, 'password': password,
"submit": "", "lt": lt_value, "execution": exe_value,
"_eventId": "submit", "rmShown": '1'}
headers = {'User-Agent': "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:44.0) Gecko/20100101 Firefox/44.0",
'Accept': "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Language": "zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3",
"Accept-Encoding": "gzip, deflate",
"Referer": "http://ids.xidian.edu.cn/authserver/login?service=http%3A%2F%2Fjwxt.xidian.edu.cn%2Fcaslogin.jsp",
"Content-Type": "application/x-www-form-urlencoded"}
s = self.session.post(self.auth_url, data=params, headers=headers)
s = self.session.get(self.log_url)
def Print(self):
grade_page = self.session.get("http://yjsxt.xidian.edu.cn/info/findAllMessageAction.do")
bsObj2 = BeautifulSoup(grade_page.text, "html.parser")
nameList = bsObj2.findAll("li")
for name in nameList:
print(name.get_text())
if __name__ == '__main__':
# 初始化爬虫对象
sg = ScrapeGrade()
# 登录(在此处传入正确的个人学号与密码信息)
sg.login(id='学号', password='密码')
sg.Print()