基于文件存储UFS的Pytorch训练IO五倍提升实践
我们在协助某AI客户排查一个UFS文件存储的性能case时发现,其使用的Pytorch训练IO性能和硬件的IO能力有很大的差距(后面内容有具体性能对比数据)。
让我们感到困惑的是:UFS文件存储,我们使用fio自测可以达到单实例最低10Gbps带宽、IOPS也可达到2w以上。该AI客户在高IOPS要求的AI单机小模型训练场景下,或者之前使用MXNet、TensorFlow框架时,IO都能跑到UFS理论性能,甚至在大型分布式训练场景中,UFS也可以完全胜任。
于是我们开启了和客户的一次深度联合排查。
初步尝试优化
1、调整参数
基于上述情况,首先考虑是不是使用Pytorch的姿势不对?参考网上提到经验,客户调整batch_size、Dataloader等参数。
Batch_size
默认batch_size为256,根据内存和显存配置尝试更改batch_size大小,让一次读取数据更多,发现实际对效率没有提升。通过分析是由于batch_size设置与数据读取逻辑没有直接关系,IO始终会保留单队列与后端交互,不会降低网络交互上的整体延时(因为用的是UFS文件存储,后面会讲到为什么用)。
Pytorch Dataloader
Pytorch框架dataloader的worker负责数据的读取和加载、分配。通过batch_sampler将batch数据分配给对应的worker,由worker从磁盘读取数据并加载数据到内存,dataloader从内存中读取相应batch做迭代训练。这里尝试调整了worker_num参数为CPU核数或倍数,发现提升有限,反而内存和CPU的开销提升了不少,整体加重了训练设备的负担,通过 worker加载数据时的网络开销并不会降低,与本地SSD盘差距依然存在。
这个也不难理解,后面用strace排查的时候,看到CPU更多的时候在等待。
所以:从目前信息来看,调整Pytorch框架参数对性能几乎没有影响。
2、尝试不同存储产品
在客户调整参数的同时,我们也使用了三种存储做验证,来看这里是否存在性能差异、差异到底有多大。在三种存储产品上放上同样的数据集:
1、 单张平均大小20KB的小图片,总量2w张。
2、 以目录树方式存到三种存储下的相同路径,使用Pytorch常用的标准读图接口CV2和PIL
测试结果,如下图:
| 读取方式 | SSHFS | 本地SSD | UFS文件存储 |
| CV2 | 319.94张/s | 554.73张/s | 72.41张/s |
| PIL(image_open) | 435.93张/s | 3507.93张/s | 115.78张/s |
注:SSHFS基于X86物理机(32核/64G/480G SSD*6 raid10)搭建,网络25Gbps
结论:通过对存储性能实测, UFS文件存储较本地盘、单机SSHFS性能差距较大。
为什么会选用这两种存储(SSHFS和本地SSD)做UFS性能对比?
当前主流存储产品的选型上分为两类:自建SSHFS/NFS或采用第三方NAS服务(类似UFS产品),个别场景中也会将需要的数据下载到本地SSD盘做训练。传统SSD本地盘拥有极低的IO延时,一个IO请求处理基本会在us级别完成,针对越小的文件,IO性能越明显。受限于单台物理机配置,无法扩容,数据基本 “即用即弃”。而数据是否安全也只能依赖磁盘的稳定性,一旦发生故障,数据恢复难度大。但是鉴于本地盘的优势,一般也会用作一些较小模型的训练,单次训练任务在较短时间即可完成,即使硬件故障或者数据丢失导致训练中断,对业务影响通常较小。
用户通常会使用SSD物理机自建SSHFS/NFS共享文件存储,数据IO会通过以太网络,较本地盘网络上的开销从us级到ms级,但基本可以满足大部分业务需求。但用户需要在日常使用中同时维护硬件和软件的稳定性,并且单台物理机有存储上限,如果部署多节点或分布式文件系统也会导致更大运维精力投入。
我们把前面结论放到一起看:
1、 隐形结论:Tensorflow、Mxnet框架无问题。
2、 调整Pytorch框架参数对性能几乎没有影响。
3、Pytorch+UFS的场景下, UFS文件存储较本地SSD盘、单机SSHFS性能差距大。
结合以上几点信息并与用户确认后的明确结论:UFS结合非Pytorch框架使用没有性能瓶颈, Pytorch框架下用本地SSD盘没有性能瓶颈,用SSHFS性能可接受。那原因就很明显了,就是Pytorch+UFS文件存储这个组合存在IO性能问题。
深入排查优化
看到这里,大家可能会有个疑问:是不是不用UFS,用本地盘就解决了?
答案是不行,原因是训练所需的数据总量很大,很容易超过了单机的物理介质容量,另外也出于数据安全考虑,存放单机有丢失风险,而UFS是三副本的分布式存储系统,并且UFS可以提供更弹性的IO性能。
根据以上的信息快速排查3个结论,基本上可以判断出:Pytorch在读UFS数据过程中,文件读取逻辑或者UFS存储IO耗时导致。于是我们通过strace观察Pytorch读取数据整体流程:
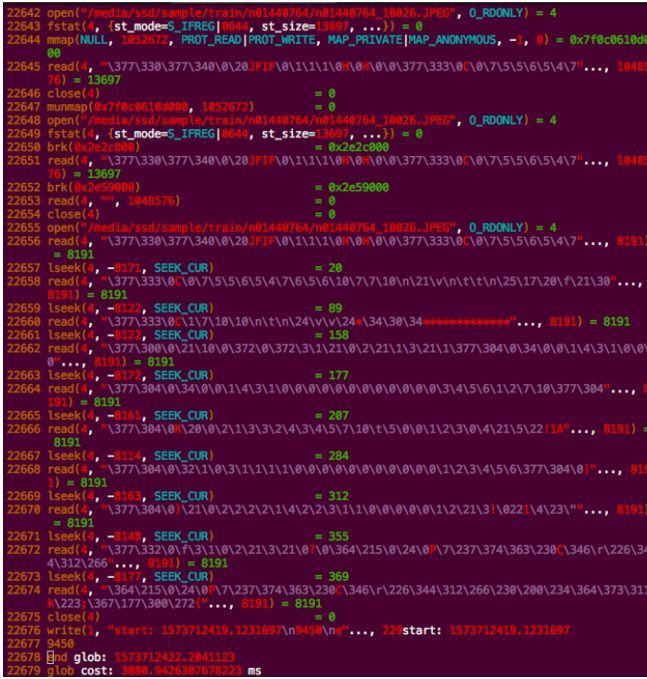
通过strace发现,CV2方式读取UFS里的文件(NFSV4协议)有很多次SEEK动作,即便是单个小文件的读取也会“分片”读取,从而导致了多次不必要的IO读取动作,而最耗时的则是网络,从而导致整体耗时成倍增长。这也是符合我们的猜测。
简单介绍一下NFS协议特点:NAS所有的IO都需要经过以太网,一般局域网内延时在1ms以内。以NFS数据交互为例,通过图中可以看出,针对一次完整的小文件IO操作将涉及元数据查询、数据传输等至少5次网络交互,每次交互都会涉及到client与server集群的一个TTL,其实这样的交互逻辑会存在一个问题,当单文件越小、数量越大时则延时问题将越明显,IO过程中有过多的时间消耗在网络交互,这也是NAS类存储在小文件场景下面临的经典问题。

对于UFS的架构而言,为了达到更高扩展性、更便利的维护性、更高的容灾能力,采用接入层、索引层和数据层的分层架构模式,一次IO请求会先经过接入层做负载均衡,client端再访问后端UFS索引层获取到具体文件信息,最后访问数据层获取实际文件,对于KB级别的小文件,实际在网络上的耗时比单机版NFS/SSHFS会更高。
从Pytorch框架下两种读图接口来看:CV2读取文件会“分片”进行,而PIL虽然不会“分片”读取,但是基于UFS分布式架构,一次IO会经过接入、索引、数据层,网络耗时也占比很高。我们存储同事也实际测试过这2种方法的性能差异:通过strace发现,相比OpenCV的方式,PIL的数据读取逻辑效率相对高一些。
优化方向一:如何降低与UFS交互频次,从而降低整体存储网络延时
1、CV2:对单个文件而言,“分片读取”变“一次读取”
通过对Pytorch框架接口和模块的调研,如果使用 OpenCV方式读取文件可以用2个方法, cv2.imread和cv2.imdecode。
默认一般会用cv2.imread方式,读取一个文件时会产生9次lseek和11次read,而对于图片小文件来说多次lseek和read是没有必要的。cv2.imdecode可以解决这个问题,它通过一次性将数据加载进内存,后续的图片操作需要的IO转化为内存访问即可。
两者的在系统调用上的对比如下图:
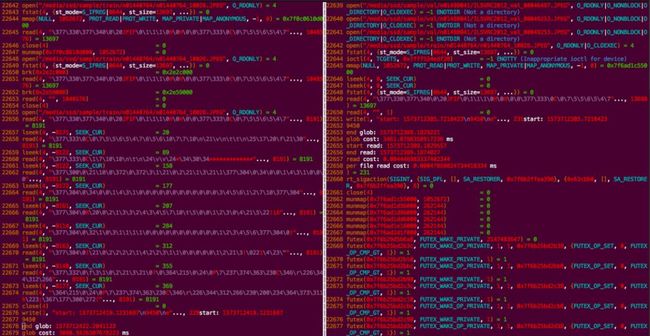
我们通过使用cv2.imdecode方式替换客户默认使用的cv2.imread方式,单个文件的总操作耗时从12ms下降到6ms。但是内存无法cache住过大的数据集,不具备任意规模数据集下的训练,但是整体读取性能还是提升明显。使用cv2版本的benchmark对一个小数据集进行加载测试后的各场景耗时如下(延迟的非线性下降是因为其中包含GPU计算时间):
| 本地SSD | UFS imread方式 | UFS imdecode方式 |
| 95s | 150s | 100s左右 |
2、PIL:优化dataloader元数据性能,缓存文件句柄
通过PIL方式读取单张图片的方式,Pytorch处理的平均延迟为7ms(不含IO时间),单张图片读取(含IO和元数据耗时)平均延迟为5-6ms,此性能水平还有优化空间。
由于训练过程会进行很多个epoch的迭代,而每次迭代都会进行数据的读取,这部分操作从多次训练任务上来看是重复的,如果在训练时由本地内存做一些缓存策略,对性能应该有提升。但直接缓存数据在集群规模上升之后肯定是不现实的,我们初步只缓存各个训练文件的句柄信息,以降低元数据访问开销。
我们修改了Pytorch的dataloader实现,通过本地内存cache住训练需要使用的文件句柄,可以避免每次都尝试做open操作。测试后发现1w张图片通过100次迭代训练后发现,单次迭代的耗时已经基本和本地SSD持平。但是当数据集过大,内存同样无法cache住所有元数据,所以使用场景相对有限,依然不具备在大规模数据集下的训练伸缩性。
| 存储类型 | Real time(s) | User time(s) | Sys time(s) |
| 本地SSD | 25.10 | 475.89 | 3.66 |
| UFS | 25.90 | 491.62 | 3.73 |
3、UFS server端元数据预加载
以上client端的优化效果比较明显,但是客户业务侧需要更改少量训练代码,最主要是client端无法满足较大数据量的缓存,应用场景有限,我们继续从server端优化,尽量降低整个链路上的交互频次。
正常IO请求通过负载均衡到达索引层时,会先经过索引接入server,然后到索引数据server。考虑到训练场景具有目录访问的空间局部性,我们决定增强元数据预取的功能。通过客户请求的文件,引入该文件及相应目录下所有文件的元数据,并预取到索引接入server,后续的请求将命中缓存,从而减少与索引数据server的交互,在IO请求到达索引层的第一步即可获取到对应元数据,从而降低从索引数据server进行查询的开销。
经过这次优化之后,元数据操作的延迟较最初能够下降一倍以上,在客户端不做更改的情况下,读取小文件性能已达到本地SSD盘的50%。看来单单优化server端还是无法满足预期,通过执行Pytorch的benchmark程序,我们得到UFS和本地SSD盘在整个数据读取耗时。
| 存储类型 | 1w张耗时(s) | 2w张耗时(s) |
| 本地SSD | 48.86 | 97.06 |
| UFS | 97.98 | 195.82 |
此时很容易想到一个问题:非Pytorch框架在使用UFS做训练集存储时,为什么使用中没有遇到IO性能瓶颈?
通过调研其他框架的逻辑发现:无论是MXNet的rec文件,Caffe的LMDB,还是TensorFlow的npy文件,都是在训练前将大量图片小文件转化为特定的数据集格式,所以使用UFS在存储网络交互更少,相对Pytorch直接读取目录小文件的方式,避免了大部分网络上的耗时。这个区别在优化时给了我们很大的启示,将目录树级别小文件转化成一个特定的数据集存储,在读取数据做训练时将IO发挥出最大性能优势。
优化方向二:目录级内的小文件转换为数据集,最大程度降到IO网络耗时
基于其他训练框架数据集的共性功能,我们UFS存储团队赶紧开工,几天开发了针对Pytorch框架下的数据集转换工具,将小文件数据集转化为UFS大文件数据集并对各个小文件信息建立索引记录到index文件,通过index文件中索引偏移量可随机读取文件,而整个index文件在训练任务启动时一次性加载到本地内存,这样就将大量小文件场景下的频繁访问元数据的开销完全去除了,只剩下数据IO的开销。该工具后续也可直接应用于其他AI类客户的训练业务。
工具的使用很简单,只涉及到两步:
- 使用UFS自研工具将Pytorch数据集以目录形式存储的小文件转化为一个大文件存储到UFS上,生成date.ufs和index.ufs。
- 使用我方提供Folder类替换pytorch原有代码中的torchvision.datasets.ImageFolder数据加载模块(即替换数据集读取方法),从而使用UFS上的大文件进行文件的随机读取。只需更改3行代码即可。
- 20行:新增from my_dataloader import *
- 205行:train_dataset = datasets.ImageFolder改为train_dataset = MyImageFolder
- 224行:datasets.ImageFolder改为MyImageFolder
通过github上Pytorch测试demo对imagenet数据集进行5、10、20小时模拟训练,分别读取不同存储中的数据,具体看下IO对整体训练速度的影响。(数据单位:完成的epoch的个数)
| 数据读取方式 | 第一次(5小时) | 第二次(10小时) | 第三次(20小时) |
| 本地SSD盘 | 5.226 | 10.384 | 20.873 |
| UFS目录小文件 | 1.238 | 3.180 | 6.394 |
| UFS数据集 | 5.46 | 10.739 | 21.784 |
| SSHFS目录小文件 | 3.721 | 7.398 | 14.797 |
测试条件:GPU服务器:P40*4物理机,48核256G,数据盘800G*6 SATA SSD RAID10SSHFS:X86物理机32核/64G,数据盘480G*6 SATA SSD RAID10Demo:https://github.com/pytorch/examples/tree/master/imagenet数据集:总大小148GB、图片文件数量120w以上
通过实际结果可以看出:UFS数据集方式效率已经达到甚至超过本地SSD磁盘的效果。而UFS数据集转化方式,客户端内存中只有少量目录结构元数据缓存,在100TB数据的体量下,元数据小于10MB,可以满足任意数据规模,对于客户业务上的硬件使用无影响。
UFS产品
针对Pytorch小文件训练场景,UFS通过多次优化,吞吐性能已得到极大提升,并且在后续产品规划中,我们也会结合现有RDMA网络、SPDK等存储相关技术进行持续优化。详细请点击访问链接:https://docs.ucloud.cn/storage_cdn/ufs/overview。