项目:数仓采集(三)(业务数据采集模块Mysql+sqoop+hive 总结)
文章目录
- Mysql
- MySQL安装
- 安装包准备
- 安装MySQL
- 配置MySQL
- 业务数据生成
- 连接MySQL
- 生成业务数据
- sqoop
- sqoop使用场景
- Sqoop安装
- Mysql-hdfs 传输应用
- 同步策略(mysql—数据仓库 导数据)
- 全量同步策略
- 增量同步策略
- 新增及变化策略
- 特殊策略
- 业务数据导入HDFS
- 分析表同步策略
- 脚本编写
- 项目经验
- Hive
- Hive安装部署
- Hive元数据配置到MySQL
- 启动Hive
- 初始化元数据库
- 启动hive客户端

Mysql
MySQL安装
安装包准备
卸载自带的Mysql-libs
rpm -qa | grep -i -E mysql\|mariadb | xargs -n1 sudo rpm -e --nodeps
#上传安装包和jdbc驱动
01_mysql-community-common-5.7.16-1.el7.x86_64.rpm
02_mysql-community-libs-5.7.16-1.el7.x86_64.rpm
03_mysql-community-libs-compat-5.7.16-1.el7.x86_64.rpm
04_mysql-community-client-5.7.16-1.el7.x86_64.rpm
05_mysql-community-server-5.7.16-1.el7.x86_64.rpm
mysql-connector-java-5.1.27-bin.jar
安装MySQL
sudo rpm -ivh 01_mysql-community-common-5.7.16-1.el7.x86_64.rpm
sudo rpm -ivh 02_mysql-community-libs-5.7.16-1.el7.x86_64.rpm
sudo rpm -ivh 03_mysql-community-libs-compat-5.7.16-1.el7.x86_64.rpm
sudo rpm -ivh 04_mysql-community-client-5.7.16-1.el7.x86_64.rpm
#最小化安装需要安装依赖
yum install -y libaio
sudo rpm -ivh 05_mysql-community-server-5.7.16-1.el7.x86_64.rpm
#启动服务
sudo systemctl start mysqld
#查看密码
sudo cat /var/log/mysqld.log | grep password
配置MySQL
mysql -uroot -p 'password'
#因为版本问题,所以必须有大小写
mysql> set password=password("Vanas.123456");
#更改密码策略
mysql> set global validate_password_length=4;
mysql> set global validate_password_policy=0;
#重设密码
mysql> set password=password("123456");
#进入msyql库
mysql> use mysql
#查询user表
mysql> select user, host from user;
#修改user表,把Host表内容修改为%
mysql> update user set host="%" where user="root";
#刷新
mysql> flush privileges;
#退出
mysql> quit;
#测试是否好用
[vanas@hadoop102 mysql]$ mysql -uroot -p123456 -hhadoop102
业务数据生成
连接MySQL
主机名 、链接名、密码如实填写
云服务器 需要设置ssh
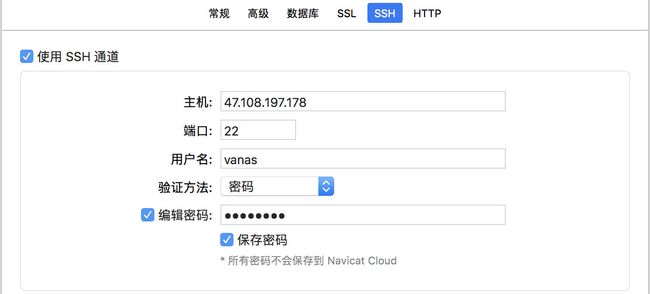
同时安全组添加3306端口访问

创建数据库设置 utf_8 general_ci
运行sql文件
生成业务数据
#在hadoop102的/opt/module/目录下创建db_log文件夹
[vanas@hadoop102 module]$ mkdir db_log/
#把gmall2020-mock-db-2020-04-01.jar和 application.properties上传到hadoop102的/opt/module/db_log路径上
#根据需求修改application.properties相关配置
logging.level.root=info
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
spring.datasource.url=jdbc:mysql://hadoop102:3306/gmall?characterEncoding=utf-8&useSSL=false&serverTimezone=GMT%2B8
spring.datasource.username=root
spring.datasource.password=123456
logging.pattern.console=%m%n
mybatis-plus.global-config.db-config.field-strategy=not_null
#业务日期
mock.date=2020-05-15
#是否重置
mock.clear=1
#生成新用户数量
mock.user.count=1000
#男性比例
mock.user.male-rate=20
#用户数据变化概率
mock.user.update-rate:20
#收藏取消比例
mock.favor.cancel-rate=10
#收藏数量
mock.favor.count=100
#购物车数量
mock.cart.count=30
#每个商品最多购物个数
mock.cart.sku-maxcount-per-cart=3
#购物车来源 用户查询,商品推广,智能推荐, 促销活动
mock.cart.source-type-rate=60:20:10:10
#用户下单比例
mock.order.user-rate=95
#用户从购物中购买商品比例
mock.order.sku-rate=70
#是否参加活动
mock.order.join-activity=1
#是否使用购物券
mock.order.use-coupon=1
#购物券领取人数
mock.coupon.user-count=1000
#支付比例
mock.payment.rate=70
#支付方式 支付宝:微信 :银联
mock.payment.payment-type=30:60:10
#评价比例 好:中:差:自动
mock.comment.appraise-rate=30:10:10:50
#退款原因比例:质量问题 商品描述与实际描述不一致 缺货 号码不合适 拍错 不想买了 其他
mock.refund.reason-rate=30:10:20:5:15:5:5
#并在该目录下执行,如下命令,生成2020-05-15日期数据:
[vanas@hadoop102 db_log]$ java -jar gmall2020-mock-db-2020-04-01.jar
#在配置文件application.properties中修改
mock.date=2020-05-15
mock.clear=0
#再次执行命令,生成2020-05-15日期数据:
[vanas@hadoop102 db_log]$ java -jar gmall2020-mock-db-2020-04-01.jar
sqoop
sqoop使用场景
1.业务数据库(关系型数据库) ——>hdfs 导入
2.需要把hdfs数据——>关系型数据库里 导出
也就是二者相互导的轻量级框架sqoop
Sqoop安装
tar -zxf sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz -C /opt/module/
[vanas@hadoop102 conf]$ mv sqoop-env-template.sh sqoop-env.sh
[vanas@hadoop102 conf]$ vim sqoop-env.sh
export HADOOP_COMMON_HOME=/opt/module/hadoop-3.1.3
export HADOOP_MAPRED_HOME=/opt/module/hadoop-3.1.3
export HIVE_HOME=/opt/module/hive
export ZOOKEEPER_HOME=/opt/module/zookeeper-3.5.7
export ZOOCFGDIR=/opt/module/zookeeper-3.5.7/conf
#把jdbc驱动拷贝到 sqoop/lib 目录下
cp mysql-connector-java-5.1.48.jar /opt/module/sqoop/lib/
#验证swoop与数据库连接是否成功
[vanas@hadoop102 sqoop]$ bin/sqoop list-databases --connect jdbc:mysql://hadoop102:3306 --username root --password 123456
Mysql-hdfs 传输应用
注意必须要有空格
– 和- 没区别
两个列中间没空格就不需要引号 有空格 需要加引号
–delete-target-dir \ 为了让文件实现幂等性
只有map没有reduce (为什么不需要reduce sqoop是用来读数据 再 写数据 所以不需要聚合)
mappers默认4个
split 要求写主键 按行分片
fields-terminated-by 在hdfs 列与列的分隔符是什么
bin/sqoop import \
--connect jdbc:mysql://hadoop102:3306/gmall \
--username root \
--password 123456 \
--table user_info \
--columns id,login_name \
--where 'id>=10 and id<=100' \
--target-dir /test \
--delete-target-dir \
--num-mappers 1 \
--split-by id \
--fields-terminated-by '\t'
改写:Conditions 为了数据分片
bin/sqoop import \
--connect jdbc:mysql://hadoop102:3306/gmall \
--username root \
--password 123456 \
--query "select id,login_name from user_info where id>=10 and id<=100 and \$CONDITIONS" \
--target-dir /test \
--delete-target-dir \
--num-mappers 2 \
--split-by id \
--fields-terminated-by '\t'
sqoop和flume对比
flume 实时监控实时写入
sqoop 批量导入hdfs上写死的路径
那怎么让sqoop自己选择路径?
sqoop每天导一次 写脚本找日期
同步策略(mysql—数据仓库 导数据)
hive中才有这些表的策略
数据同步策略的类型包括:全量表、增量表、新增及变化表、特殊表
全量表:存储完整的数据。
增量表:存储新增加的数据。
新增及变化表:存储新增加的数据和变化的数据。
特殊表:只需要存储一次。
全量同步策略
hive的分区表 每一个分区存的都是当天对应的mydql全量数据
保留历史状态 多一个时间维度 就会有多个分析角度
表数量不大 每天有增加和修改的表
增量同步策略
数据量大 每天有新增 无变化
例如交易
新增及变化策略
怎么获取每天的新增和变化?
createtime 和 operate_time
如果没有以上两列 则用canal能拿到变化 实时监控
特殊策略
不会变化的数据 例如地区
时间宽表
业务数据导入HDFS
分析表同步策略
在生产环境,个别小公司,为了简单处理,所有表全量导入。
中大型公司,由于数据量比较大,还是严格按照同步策略导入数据。
两个判断基准:
1.数据量大不大
2.有没有新增或变化
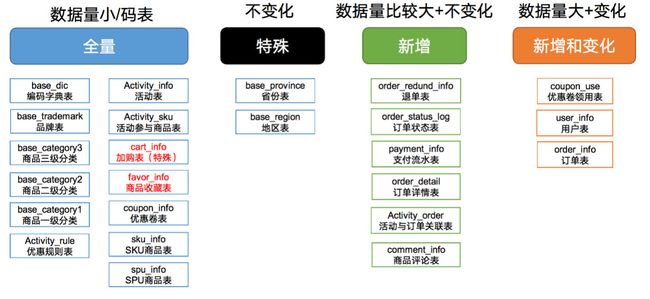
cart_info 、favor_info 后期会做快照 根据具体需求做的
全量 sqoop只拿一天中最后一个状态 要监控的话用canal
一般在00:30之后导数据
脚本编写
写脚本的目的 批量调度 交给azkaban 路径变动
vim mysql_to_hdfs.sh
gg或g1 跳到最前面
$1 $2都指的是函数的变量
hive中 null值是\N 所以把null值都进行转义
传参 1 表名 2 sql
表策略 体现where
do_data是昨天的数据
where 1=1 是为了满足sql的语法 因为$CONDITIONS
date -help
date -d '-1 day' +%F
do_date=`date -d '-1 day' +%F`
#飘号的作用是把结果 赋予变量 或者用 $()二者等同
#! /bin/bash
sqoop=/opt/module/sqoop/bin/sqoop
if [ -n "$2" ] ;then
do_date=$2
else
do_date=`date -d '-1 day' +%F`
fi
import_data(){
$sqoop import \
--connect jdbc:mysql://hadoop102:3306/gmall \
--username root \
--password 123456 \
--target-dir /origin_data/gmall/db/$1/$do_date \
--delete-target-dir \
--query "$2 and \$CONDITIONS" \
--num-mappers 1 \
--fields-terminated-by '\t' \
--compress \
--compression-codec lzop \
--null-string '\\N' \
--null-non-string '\\N'
hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/common/hadoop-lzo-0.4.20.jar com.hadoop.compression.lzo.DistributedLzoIndexer /origin_data/gmall/db/$1/$do_date
}
import_order_info(){
import_data order_info "select
id,
final_total_amount,
order_status,
user_id,
out_trade_no,
create_time,
operate_time,
province_id,
benefit_reduce_amount,
original_total_amount,
feight_fee
from order_info
where (date_format(create_time,'%Y-%m-%d')='$do_date'
or date_format(operate_time,'%Y-%m-%d')='$do_date')"
}
import_coupon_use(){
import_data coupon_use "select
id,
coupon_id,
user_id,
order_id,
coupon_status,
get_time,
using_time,
used_time
from coupon_use
where (date_format(get_time,'%Y-%m-%d')='$do_date'
or date_format(using_time,'%Y-%m-%d')='$do_date'
or date_format(used_time,'%Y-%m-%d')='$do_date')"
}
import_order_status_log(){
import_data order_status_log "select
id,
order_id,
order_status,
operate_time
from order_status_log
where date_format(operate_time,'%Y-%m-%d')='$do_date'"
}
import_activity_order(){
import_data activity_order "select
id,
activity_id,
order_id,
create_time
from activity_order
where date_format(create_time,'%Y-%m-%d')='$do_date'"
}
import_user_info(){
import_data "user_info" "select
id,
name,
birthday,
gender,
email,
user_level,
create_time,
operate_time
from user_info
where (DATE_FORMAT(create_time,'%Y-%m-%d')='$do_date'
or DATE_FORMAT(operate_time,'%Y-%m-%d')='$do_date')"
}
import_order_detail(){
import_data order_detail "select
od.id,
order_id,
user_id,
sku_id,
sku_name,
order_price,
sku_num,
od.create_time,
source_type,
source_id
from order_detail od
join order_info oi
on od.order_id=oi.id
where DATE_FORMAT(od.create_time,'%Y-%m-%d')='$do_date'"
}
import_payment_info(){
import_data "payment_info" "select
id,
out_trade_no,
order_id,
user_id,
alipay_trade_no,
total_amount,
subject,
payment_type,
payment_time
from payment_info
where DATE_FORMAT(payment_time,'%Y-%m-%d')='$do_date'"
}
import_comment_info(){
import_data comment_info "select
id,
user_id,
sku_id,
spu_id,
order_id,
appraise,
comment_txt,
create_time
from comment_info
where date_format(create_time,'%Y-%m-%d')='$do_date'"
}
import_order_refund_info(){
import_data order_refund_info "select
id,
user_id,
order_id,
sku_id,
refund_type,
refund_num,
refund_amount,
refund_reason_type,
create_time
from order_refund_info
where date_format(create_time,'%Y-%m-%d')='$do_date'"
}
import_sku_info(){
import_data sku_info "select
id,
spu_id,
price,
sku_name,
sku_desc,
weight,
tm_id,
category3_id,
create_time
from sku_info where 1=1"
}
import_base_category1(){
import_data "base_category1" "select
id,
name
from base_category1 where 1=1"
}
import_base_category2(){
import_data "base_category2" "select
id,
name,
category1_id
from base_category2 where 1=1"
}
import_base_category3(){
import_data "base_category3" "select
id,
name,
category2_id
from base_category3 where 1=1"
}
import_base_province(){
import_data base_province "select
id,
name,
region_id,
area_code,
iso_code
from base_province
where 1=1"
}
import_base_region(){
import_data base_region "select
id,
region_name
from base_region
where 1=1"
}
import_base_trademark(){
import_data base_trademark "select
tm_id,
tm_name
from base_trademark
where 1=1"
}
import_spu_info(){
import_data spu_info "select
id,
spu_name,
category3_id,
tm_id
from spu_info
where 1=1"
}
import_favor_info(){
import_data favor_info "select
id,
user_id,
sku_id,
spu_id,
is_cancel,
create_time,
cancel_time
from favor_info
where 1=1"
}
import_cart_info(){
import_data cart_info "select
id,
user_id,
sku_id,
cart_price,
sku_num,
sku_name,
create_time,
operate_time,
is_ordered,
order_time,
source_type,
source_id
from cart_info
where 1=1"
}
import_coupon_info(){
import_data coupon_info "select
id,
coupon_name,
coupon_type,
condition_amount,
condition_num,
activity_id,
benefit_amount,
benefit_discount,
create_time,
range_type,
spu_id,
tm_id,
category3_id,
limit_num,
operate_time,
expire_time
from coupon_info
where 1=1"
}
import_activity_info(){
import_data activity_info "select
id,
activity_name,
activity_type,
start_time,
end_time,
create_time
from activity_info
where 1=1"
}
import_activity_rule(){
import_data activity_rule "select
id,
activity_id,
condition_amount,
condition_num,
benefit_amount,
benefit_discount,
benefit_level
from activity_rule
where 1=1"
}
import_base_dic(){
import_data base_dic "select
dic_code,
dic_name,
parent_code,
create_time,
operate_time
from base_dic
where 1=1"
}
case $1 in
"order_info")
import_order_info
;;
"base_category1")
import_base_category1
;;
"base_category2")
import_base_category2
;;
"base_category3")
import_base_category3
;;
"order_detail")
import_order_detail
;;
"sku_info")
import_sku_info
;;
"user_info")
import_user_info
;;
"payment_info")
import_payment_info
;;
"base_province")
import_base_province
;;
"base_region")
import_base_region
;;
"base_trademark")
import_base_trademark
;;
"activity_info")
import_activity_info
;;
"activity_order")
import_activity_order
;;
"cart_info")
import_cart_info
;;
"comment_info")
import_comment_info
;;
"coupon_info")
import_coupon_info
;;
"coupon_use")
import_coupon_use
;;
"favor_info")
import_favor_info
;;
"order_refund_info")
import_order_refund_info
;;
"order_status_log")
import_order_status_log
;;
"spu_info")
import_spu_info
;;
"activity_rule")
import_activity_rule
;;
"base_dic")
import_base_dic
;;
"first")
import_base_category1
import_base_category2
import_base_category3
import_order_info
import_order_detail
import_sku_info
import_user_info
import_payment_info
import_base_province
import_base_region
import_base_trademark
import_activity_info
import_activity_order
import_cart_info
import_comment_info
import_coupon_use
import_coupon_info
import_favor_info
import_order_refund_info
import_order_status_log
import_spu_info
import_activity_rule
import_base_dic
;;
"all")
import_base_category1
import_base_category2
import_base_category3
import_order_info
import_order_detail
import_sku_info
import_user_info
import_payment_info
import_base_trademark
import_activity_info
import_activity_order
import_cart_info
import_comment_info
import_coupon_use
import_coupon_info
import_favor_info
import_order_refund_info
import_order_status_log
import_spu_info
import_activity_rule
import_base_dic
;;
esac
第一次用first 全导(比如说特殊的地区)
之后 用all(没有变化的数据就不需要了)
mysql_to_hdfs.sh first
mysql_to_hdfs.sh all
项目经验
Hive中的Null在底层是以“\N”来存储,而MySQL中的Null在底层就是Null,为了保证数据两端的一致性。在导出数据时采用–input-null-string和–input-null-non-string两个参数。导入数据时采用–null-string和–null-non-string。
Hive
Hive安装部署
lib中的 log4j 与hadoop中的冲突 记得要删除
tar -zxvf /opt/software/apache-hive-3.1.2-bin.tar.gz -C /opt/module/
mv /opt/module/apache-hive-3.1.2-bin/ /opt/module/hive
sudo vim /etc/profile.d/my_env.sh
#HIVE_HOME
export HIVE_HOME=/opt/module/hive
export PATH=$PATH:$HIVE_HOME/bin
source /etc/profile.d/my_env.sh
mv log4j-slf4j-impl-2.10.0.jar log4j-slf4j-impl-2.10.0.jar.bak
拷贝JDBC驱动
cp /opt/software/mysql-connector-java-5.1.48.jar /opt/module/hive/lib/
Hive元数据配置到MySQL
vim hive-site.xml
hive.metastore.warehouse.dir 数据存储路径
hive.metastore.schema.verification 是否检查表结构
<configuration>
<property>
<name>javax.jdo.option.ConnectionURLname>
<value>jdbc:mysql://hadoop102:3306/metastore?useSSL=falsevalue>
property>
<property>
<name>javax.jdo.option.ConnectionDriverNamename>
<value>com.mysql.jdbc.Drivervalue>
property>
<property>
<name>javax.jdo.option.ConnectionUserNamename>
<value>rootvalue>
property>
<property>
<name>javax.jdo.option.ConnectionPasswordname>
<value>123456value>
property>
<property>
<name>hive.metastore.warehouse.dirname>
<value>/user/hive/warehousevalue>
property>
<property>
<name>hive.metastore.schema.verificationname>
<value>falsevalue>
property>
<property>
<name>hive.server2.thrift.portname>
<value>10000value>
property>
<property>
<name>hive.server2.thrift.bind.hostname>
<value>hadoop102value>
property>
<property>
<name>hive.metastore.event.db.notification.api.authname>
<value>falsevalue>
property>
<property>
<name>hive.cli.print.headername>
<value>truevalue>
property>
<property>
<name>hive.cli.print.current.dbname>
<value>truevalue>
property>
configuration>
启动Hive
初始化元数据库
mysql -uroot -p123456
mysql> create database metastore;
mysql> quit;
--初始化Hive元数据库
schematool -initSchema -dbType mysql -verbose
启动hive客户端
bin/hive
hive2个服务分别干什么的?
2种方法读取数据 1直接从mysql获取 2 访问metastore 然后metastore访问mysql
metastore:如果设置中配置了metastore 服务地址 必须启动
hiveserver2:只有jdbc访问需要启动hivesercer2