简介:
kaggle初学者,先抄抄别人的代码
目的是熟悉kaggle分析的流程,并简单熟悉一下各个包的作用。
正文:
Step 1: 检视源数据集
——读入数据
train_df = pd.read_csv('../input/train.csv', index_col=0)
test_df = pd.read_csv('../input/test.csv', index_col=0)
——检视数据源
train_df.head()
看前5行的数据,对数据集字段有个整体了解。
Step 2: 合并数据
目的是为了方便数据预处理,之后再将其分开;当然之前要将因变量取出。
先看看因变量的分布情况。
%matplotlib inline
prices = pd.DataFrame({"price":train_df["SalePrice"],"log(price+1)": np.log1p(train_df["SalePrice"])})
prices.hist()
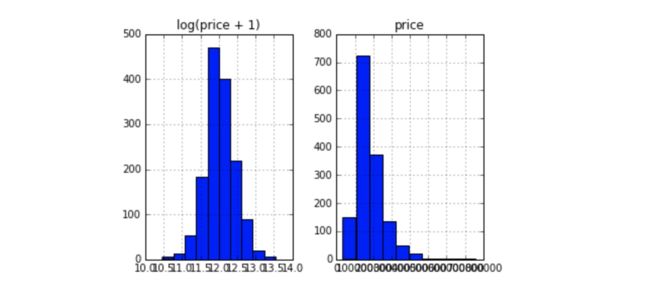
y_train=np.log1p(train_df.pop('SalePrice'))
再把剩下的部分合并起来;
y_train=np.log1p(train_df.pop('SalePrice'))
Step 3: 变量转化
类似『特征工程』。就是把不方便处理或者不unify的数据给统一了
首先,我们注意到,MSSubClass 的值其实应该是一个category,
但是Pandas是不会懂这些事儿的。使用DF的时候,这类数字符号会被默认记成数字。
这种东西就很有误导性,我们需要把它变回成string
all_df['MSSubClass'] = all_df['MSSubClass'].astype(str)
——转换为str
all_df['MSSubClass'].value_counts()
——计数
——把category的变量转变成numerical表达形式
pandas自带的get_dummies方法,可以 一键 One-Hot
all_dummy_df = pd.get_dummies(all_df)
——处理好numerical变量
就算是numerical的变量,也还会有一些小问题。
比如,有一些数据是缺失的,首先查看;
all_dummy_df.isnull().sum().sort_values(ascending=False).head(10)
接下来填补,本次选用平均值,最后检查一下
mean_cols=all_dummy_df.mean()mean_cols.head(10)
all_dummy_df=all_dummy_df.fillna(mean_cols)
all_dummy_df.isnull().sum().sum()
——标准化numerical数据
首先查找numerical数据
numeric_cols=all_df.columns[all_df.dtypes!='object']numeric_cols
计算标准分布:(X-X')/s
让我们的数据点更平滑,更便于计算。
注意:我们这里也是可以继续使用Log的,我只是给大家展示一下多种“使数据平滑”的办法。
numeric_col_means=all_dummy_df.loc[:,numeric_cols].mean()
numeric_col_std = all_dummy_df.loc[:, numeric_cols].std()
all_dummy_df.loc[:, numeric_cols] = (all_dummy_df.loc[:, numeric_cols] - numeric_col_means) / numeric_col_std
Step 4: 建立模型
——把数据集分回 训练/测试集
dummy_train_df=all_dummy_df.loc[train_df.index]
dummy_test_df=all_dummy_df.loc[test_df.index]
——Ridge Regression
用Ridge Regression模型来跑一遍看看。(对于多因子的数据集,这种模型可以方便的把所有的var都无脑的放进去)
from sklearn.linear_mode limport Ridge
from sklearn.model_selection import cross_val_score
这一步不是很必要,只是把DF转化成Numpy Array,这跟Sklearn更加配
X_train=dummy_train_df.values
X_test=dummy_test_df.values
效果如下:

——用Sklearn自带的cross validation方法来测试模型
alphas=np.logspace(-3,2,50) ——正则化参数
test_scores=[]
for alpha in alphas:
clf=Ridge(alpha)
test_score=np.sqrt(- cross_val_score(clf,X_train,y_train,cv=10,scoring='neg_mean_squared_error'))
test_scores.append(np.mean(test_score))
存下所有的CV值,看看哪个alpha值更好(也就是『调参数』)
import matplotlib.pyplotasplt
%matplotlibinline
plt.plot(alphas,test_scores)
plt.title("Alpha vs CV Error");
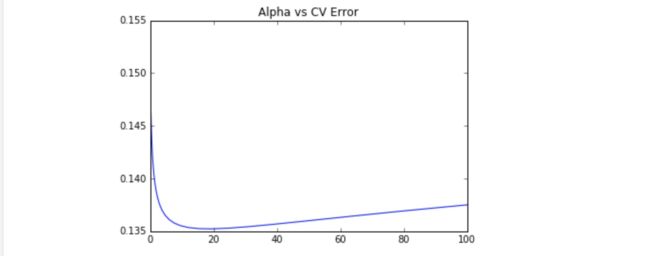
可见,大概alpha=10~20的时候,可以把score达到0.135左右。
——Random Forest
from sklearn.ensemble import RandomForestRegressor
max_features=[.1,.3,.5,.7,.9,.99]
test_scores=[]
for max_feat in max_features: ——每棵树可以使用的最大特征数量
——n_estimators:数的数量(默认10)
clf=RandomForestRegressor(n_estimators=200,max_features=max_feat)
test_score=np.sqrt(- cross_val_score(clf,X_train,y_train,cv=5,scoring='neg_mean_squared_error'))
test_scores.append(np.mean(test_score))
plt.plot(max_features,test_scores)
plt.title("Max Features vs CV Error")

用RF的最优值达到了0.137
Step 5: Ensemble
这里我们用一个Stacking的思维来汲取两种或者多种模型的优点
首先,我们把最好的parameter拿出来,做成我们最终的model
ridge=Ridge(alpha=15)
rf=RandomForestRegressor(n_estimators=500,max_features=.3)
ridge.fit(X_train,y_train)
rf.fit(X_train,y_train)
上面提到了,因为最前面我们给label做了个log(1+x), 于是这里我们需要把predit的值给exp回去,并且减掉那个"1"
所以就是我们的expm1()函数。
y_ridge=np.expm1(ridge.predict(X_test))
y_rf=np.expm1(rf.predict(X_test))
一个正经的Ensemble是把这群model的预测结果作为新的input,再做一次预测。这里我们简单的方法,就是直接『平均化』。
y_final=(y_ridge+y_rf)/2
Step 6: 提交结果
submission_df=pd.DataFrame(data={'Id':test_df.index,'SalePrice':y_final})
参考:July在线