1.使用Docker-compose实现Tomcat+Nginx负载均衡
-
理解nginx反向代理原理
- 参考资料:nginx反向代理原理和配置讲解
- 原理:以代理服务器来接受Internet上的连接请求,然后将请求转发给内部网络上的服务器;并将从服务器上得到的结果返回给Internet上请求连接的客户端,此时代理服务器对外就表现为一个服务器。
-
nginx代理tomcat集群,代理2个以上tomcat;
- 参考资料
- Nginx 配置详解
- linux下Nginx反向代理多个tomcat(单独访问或集群配置)
- Docker-Compose部署nginx代理Tomcat集群 - 项目结构

- default.conf
upstream tomcats { server tomcat1:7070; server tomcat2:7071; server tomcat3:7072; } server { listen 2420; server_name localhost; location / { proxy_pass http://tomcats; # 请求转向tomcats } }- index.jsp
<%@ page language="java" contentType="text/html; charset=utf-8" import="java.net.InetAddress" pageEncoding="utf-8"%>Nginx+Tomcat负载均衡 <% InetAddress addr = InetAddress.getLocalHost(); out.println("主机地址:"+addr.getHostAddress()); out.println("主机名:"+addr.getHostName()); %>- docker-compose.yml
version: "3.8" services: nginx: image: nginx container_name: ex4ngx ports: - 80:2420 volumes: - ./nginx/default.conf:/etc/nginx/conf.d/default.conf # 挂载配置文件 depends_on: - tomcat01 - tomcat02 - tomcat03 tomcat01: hostname: tomcat01 image: tomcat container_name: tomcat1 volumes: - ./webapps:/usr/local/tomcat/webapps/ROOT # 挂载web目录 tomcat02: hostname: tomcat2 image: tomcat container_name: tomcat2 volumes: - ./webapps:/usr/local/tomcat/webapps/ROOT # 挂载web目录 tomcat03: hostname: tomcat03 image: tomcat container_name: tomcat3 volumes: - ./webapps:/usr/local/tomcat/webapps/ROOT # 挂载web目录 - 参考资料
-
了解nginx的负载均衡策略,并至少实现nginx的2种负载均衡策略;
- 编写爬虫:
import requests import re url = 'http://localhost/index.jsp' for i in range(0,6): res = requests.get(url) text = re.findall('tomcat[0-9]{2}',res.text,re.S) print(text) - 轮询策略:
默认就是轮询算法
运行爬虫:

- 权重策略:
修改default.conf

运行爬虫:
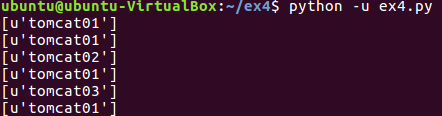
- 编写爬虫:
2.使用Docker-compose部署javaweb运行环境
-
分别构建tomcat、数据库等镜像服务;
- 参考资料:
- SpringBoot项目的创建和jar、war方式的部署
- Host is not allowed to connect to this MySQL server解决方法 - 项目结构:
.
├── docker-compose.yml
├── mysql
│ ├── dockerfile
│ ├── schema.sql
│ └── setup.sh
├── nginx
│ ├── default.conf
│ └── Dockerfile
└── tomcat
├── Dockerfile
├── ROOT [error opening dir]
├── ROOT.war
在上一个实验的基础上,nginx的配置无需改动 - mysql
-
dockerfile:
from mysql:5.7 #基础镜像 maintainer lyh<[email protected]> #维护者信息 ENV MYSQL_ALLOW_EMPTY_PASSWORD no #不允许空密码登录 ENV MYSQL_ROOT_PASSWORD=123456 #root密码 COPY setup.sh /mysql/setup.sh COPY schema.sql /mysql/schema.sql #所需文件 CMD ["sh", "/mysql/setup.sh"] #启动命令 -
setup.sh
#!/bin/bash set -e #查看mysql服务的状态,方便调试,这条语句可以删除 echo `service mysql status` echo '1.启动mysql....' #启动mysql service mysql start sleep 3 echo `service mysql status` echo '2.开始导入数据....' #导入数据 mysql < /mysql/schema.sql echo '3.导入数据完毕....' sleep 3 echo `service mysql status` #sleep 3 echo `service mysql status` echo `mysql容器启动完毕,且数据导入成功` tail -f /dev/null -
schema.sql
-- 远程操作数据库必须,否则会报项目汇报错 grant all privileges on *.* to 'root'@'%' identified by '123456' with grant option; flush privileges; -- 创建数据库 create database ex4_db default character set utf8 collate utf8_general_ci; use ex4_db; -- 建表 DROP TABLE IF EXISTS myuser; CREATE TABLE myuser ( username varchar(20), phone varchar(255) DEFAULT "", PRIMARY KEY (username) )
-
- docker-compose.yml
version: "3.8" services: mysql: image: mysql:5.7 container_name: ex4_mysql restart: always build: context: ./mysql dockerfile: Dockerfile ports: - "3306:3306" nginx: image: nginx container_name: ex4_ngx ports: - "80:2020" build: context: ./nginx dockerfile: Dockerfile #指定dockerfile文件 volumes: - ./nginx/default.conf:/etc/nginx/conf.d/default.conf # 挂载配置文件 depends_on: - tomcat01 - tomcat02 - tomcat03 tomcat01: hostname: tomcat01 image: tomcat container_name: tomcat1 build: context: ./tomcat dockerfile: Dockerfile #指定dockerfile文件 depends_on: - mysql restart: always volumes: - ./tomcat:/usr/local/tomcat/webapps # 挂载web目录 tomcat02: hostname: tomcat02 image: tomcat container_name: tomcat2 build: context: ./tomcat dockerfile: Dockerfile #指定dockerfile文件 depends_on: - mysql restart: always volumes: - ./tomcat:/usr/local/tomcat/webapps # 挂载web目录 tomcat03: hostname: tomcat03 image: tomcat container_name: tomcat3 build: context: ./tomcat dockerfile: Dockerfile #指定dockerfile文件 depends_on: - mysql restart: always volumes: - ./tomcat:/usr/local/tomcat/webapps # 挂载web目录
- 参考资料:
-
javaweb项目:
刚好最近在竞赛有用springboot构建项目,就用上了-
需要排除springboot自带的tomcat,教程:SpringBoot去除内嵌tomcat
-
还有可能出现
 这种报错,不用管它,在pojo添加注解@Mapper即可
这种报错,不用管它,在pojo添加注解@Mapper即可 -
一定一定一定要用plugin自动生成Mapper.xml代码!自己手写既繁琐又容易错,吃大亏了我,为啥知道了能自动生成我还要自己写
-
记得修改application.yml文件
url: jdbc:mysql://ex4_mysql:3306/ex4_db主机名修改为容器名 -
功能大概如下
``` @RestController @RequestMapping(value = "/ex4/") public class UserController { @Autowired UserMapper userMapper; @RequestMapping(value = "add") public String add(User user){ int result = userMapper.insert(user); if (result == 0){ return "add error"; } String str = user.getUsername() + " " + user.getPhone(); return "add successfully! User:[" + str + "]"; } @RequestMapping(value = "update") public String update(User user){ int result = userMapper.updateByPrimaryKey(user); if (result == 0){ return "update error"; } String str = user.getUsername() + " " + user.getPhone(); return "update success fully! User:[" + str + "]"; } @RequestMapping(value = "delete") public String delete(String username){ User user = userMapper.selectByPrimaryKey(username); int result = userMapper.deleteByPrimaryKey(username); if (result == 0){ return "delete error"; } String str = user.getUsername() + " " + user.getPhone(); return "delete success fully! User:[" + str + "]"; } @RequestMapping(value = "search") public String search(String username){ User user = userMapper.selectByPrimaryKey(username); if (user == null){ return "user not exists"; } String str = user.getUsername() + " " + user.getPhone(); return "search success fully! User:[" + str + "]"; } @RequestMapping(value = "addr") String getPort(HttpServletRequest request) { return "hello from " + request.getLocalAddr(); } } ```- 部署项目
- 将项目打包成.war,并修改文件名问ROOT.war,放置在tomcat挂载目录下
-sudo docker-compose up -d --build构建

- 部署项目
-
测试接口:
- 增:

- 查:
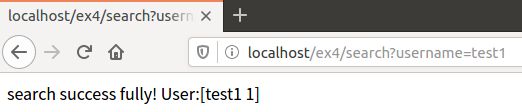
- 改:

验证

- 删:

验证

- 增:
-
-
负载均衡
- 爬虫:
import requests url = 'http://localhost/ex4/addr' num = {} for i in range(0,100): res = requests.get(url) if res.text in num: num[res.text] += 1 else: num[res.text] = 0 print(num) - 运行爬虫:
此时根据nginx配置,是权重策略
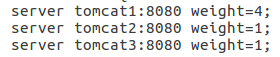

负载均衡成功
- 爬虫:
3.使用Docker搭建大数据集群环境
参考资料:
- [使用Docker搭建Hadoop分布式集群](http://dblab.xmu.edu.cn/blog/1233/)
项目结构:
- dockerfile:
```
FROM ubuntu
#基础镜像
maintainer lyh<[email protected]>
#维护者信息
```
环境搭建:
- ubuntu
-
创建容器:
使用sudo docker pull ubuntu拉取ubuntu镜像
使用如下命令创建并进入ubuntu容器docker build -t ubuntu . docker run -it --name ubuntu ubuntu -
ubuntu环境的初始化:
apt-get update # 更新系统源 apt-get install vim # 用于修改配置文件 apt-get install ssh # 安装sshd,因为在开启分布式Hadoop时,需要用到ssh连接slave: /etc/init.d/ssh start # 运行脚本即可开启sshd服务器每次在开启镜像时,都需要手动开启sshd服务,因此我们把这启动命令写进~/.bashrc文件,这样我们每次登录Ubuntu系统时,都能自动启动sshd服务
vim ~/.bashrc并在最后一行添加/etc/init.d/ssh start安装好sshd之后,我们需要配置ssh无密码连接本地sshd服务,如下命令:
cd ~/.ssh sh-keygen -t rsa #一直按回车键即可 cat id_rsa.pub >> authorized_keys #参考文档好像拼写错了即可无密码访问本地sshd服务;
-
为容器安装SDK
由于版本依赖问题不能用默认的apt安装,否则会导致很多错误,根据官方文档,最好下载java8
apt install openjdk-8-jdk安装好后需要配置环境变量
vim ~/.bashrc打开配置文件
在最后添加export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64/ export PATH=$PATH:$JAVA_HOME/binsource ~/.bashrc使~/.bashrc生效 -
保存配置好的镜像文件
docker ps # 查看当前容器id docker commit 容器ID ubuntu/ex4.3 # 存为镜像
-
安装Hadoop
docker run -it -v /home/hadoop/build:/root/build --name ubuntu-ex4.3 ubuntu/ex4.3开启保存的那份镜像ubuntu/ex4.3Hadoop下载选择清华源
下载完成后,用cp命令将文件复制入共享文件夹
/home/hadoop/build
sudo cp /home/ubuntu/Desktop/hadoop-3.2.1.tar.gz /home/hadoop/build
此时,能在ubuntu镜像的/root/build下看见文件

解压文件
tar -zxvf hadoop-3.2.1.tar.gz -C /usr/local./bin/hadoop version # 验证安装```  -
配置Hadoop集群
-
先进入配置文件存放目录:
cd /usr/local/hadoop-3.2.1/etc/hadoop -
修改环境变量
vim hadoop-env.shexport JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64/ # 找不到教程说的export JAVA_HOME=${JAVA_HOME},好像直接加就行了 -
修改core-site.xml
vim core-site.xml
添加:hadoop.tmp.dir file:/usr/local/hadoop/tmp Abase for other temporary directories. fs.defaultFS hdfs://master:9000 -
修改hdfs-site.xml
vim hdfs-site.xml
添加:dfs.namenode.name.dir file:/usr/local/hadoop/namenode_dir dfs.datanode.data.dir file:/usr/local/hadoop/datanode_dir dfs.replication 3 -
修改mapred-site.xml
vim mapred-site.xml
添加:mapreduce.framework.name yarn yarn.app.mapreduce.am.env HADOOP_MAPRED_HOME=/usr/local/hadoop-3.2.1 mapreduce.map.env HADOOP_MAPRED_HOME=/usr/local/hadoop-3.2.1 mapreduce.reduce.env HADOOP_MAPRED_HOME=/usr/local/hadoop-3.2.1 -
修改yarn-site.xml
vim yarn-site.xml
添加:yarn.nodemanager.aux-services mapreduce_shuffle yarn.resourcemanager.hostname master
-
-
存档
sudo docker commit 8ff ubuntu/hadoopinstalled

-
运行Hadoop集群
-
在三个终端上开启三个容器运行ubuntu/hadoopinstalled镜像,分别表示Hadoop集群中的master,slave01和slave02;
# 第一个终端 sudo docker run -it -h master --name master ubuntu/hadoopinstalled # 第二个终端 sudo docker run -it -h slave01 --name slave01 ubuntu/hadoopinstalled # 第三个终端 sudo docker run -it -h slave02 --name slave02 ubuntu/hadoopinstalled -
配置master,slave01和slave02的地址信息
分别打开/etc/hosts可以查看本机的ip和主机名信息,最后得到三个ip和主机地址信息如下:172.17.0.2 master 172.17.0.3 slave01 172.17.0.4 slave02最后把上述三个地址信息分别复制到master,slave01和slave02的/etc/hosts即可
-
-
测试ssh
检测下是否master是否可以连上slave01和slave02ssh slave01 ssh slave02
-
修改slaves(worker
参考资料为什么hadoop没有slaves配置文件?(搞了半天人家改名了,我真是吐血
vim /usr/local/hadoop-3.2.1/etc/hadoop/workers# 将localhost替换成两个slave的主机名 slave01 slave02 -
配置完成,启动集群
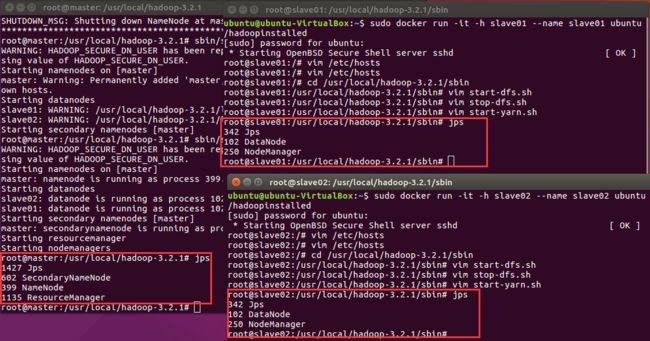
master终端上,首先进入/usr/local/hadoop-3.2.1cd /usr/local/hadoop-3.2.1 bin/hdfs namenode -format # 格式化文件系统 sbin/start-dfs.sh # 开启NameNode和DataNode服务执行sbin/start-dfs.sh报错,
- ERROR: Attempting to operate on hdfs namenode as root
参考使用root配置的hadoop并启动会出现报错
本来还有其他报错的,结果这个解决了其他的错误就不见了
用jsp命令测试结果:成功
- ERROR: Attempting to operate on hdfs namenode as root
-
运行Hadoop实例程序grep
运行的实例是hadoop自带的grep
要用到hdfs,所以我们先在hdfs上创建一个目录:./bin/hdfs dfs -mkdir -p /user/hadoop/input将/usr/local/hadoop/etc/hadoop/目录下的所有文件拷贝到hdfs上的目录:
bin/hdfs dfs -put ./etc/hadoop/*.xml /user/hadoop/input

已经正确将文件上传到hdfs下执行实例程序:
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar grep /user/hadoop/input output 'dfs[a-z.]+'可以在hdfs上的output目录下查看到运行结果:
./bin/hdfs dfs -cat output/*
输出为: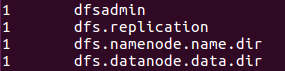
成功!
-
4.用时&心得
时间统计
- 查资料4小时
- 动手6小时
- 写博客3小时
- 合计13小时左右
心得
这次作业也太花时间了,实验三做的是最舒服的,基本上照着教程打就行了,不过自己花时间慢慢琢磨确实也能学到很多东西(但是好容易暴毙啊,我其他课怎么办,我的竞赛怎么办,我还想当个无忧无虑的考研党