Reactor详解
reactor 是什么
为何要用,能解决什么问题
如何用,更好的方式
其他事件处理模式
一、Reactor 是什么
关于reactor 是什么,我们先从wiki上看下:
The reactor design pattern is an event handling pattern for handling service requests delivered concurrently to a service handler by one or more inputs. The service handler then demultiplexes the incoming requests and dispatches them synchronously to the associated request handlers.
从上述文字中我们可以看出以下关键点 :
事件驱动(event handling)
可以处理一个或多个输入源(one or more inputs)
通过Service Handler同步的将输入事件(Event)采用多路复用分发给相应的Request Handler(多个)处理
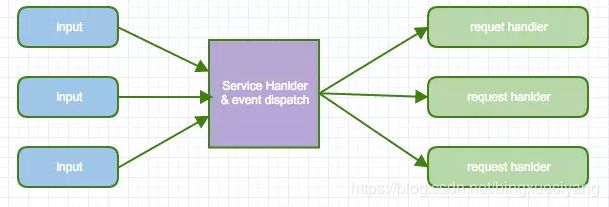
自POSA2 中的关于Reactor Pattern 介绍中,我们了解了Reactor 的处理方式:
同步的等待多个事件源到达(采用select()实现)
将事件多路分解以及分配相应的事件服务进行处理,这个分派采用server集中处理(dispatch)
分解的事件以及对应的事件服务应用从分派服务中分离出去(handler)
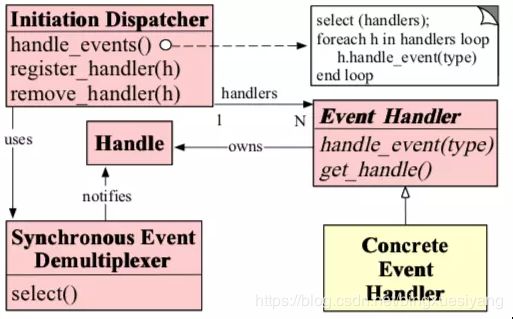
关于Reactor Pattern 的OMT 类图设计:
二、为何要用Reactor
常见的网络服务中,如果每一个客户端都维持一个与登陆服务器的连接。那么服务器将维护多个和客户端的连接以出来和客户端的contnect 、read、write ,特别是对于长链接的服务,有多少个c端,就需要在s端维护同等的IO连接。这对服务器来说是一个很大的开销。
1、BIO
比如我们采用BIO的方式来维护和客户端的连接:
// 主线程维护连接
public void run() {
try {
while (true) {
Socket socket = serverSocket.accept();
//提交线程池处理
executorService.submit(new Handler(socket));
}
} catch (Exception e) {
e.printStackTrace();
}
}
// 处理读写服务
class Handler implements Runnable {
public void run() {
try {
//获取Socket的输入流,接收数据
BufferedReader buf = new BufferedReader(new InputStreamReader(socket.getInputStream()));
String readData = buf.readLine();
while (readData != null) {
readData = buf.readLine();
System.out.println(readData);
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
很明显,为了避免资源耗尽,我们采用线程池的方式来处理读写服务。但是这么做依然有很明显的弊端:
同步阻塞IO,读写阻塞,线程等待时间过长
在制定线程策略的时候,只能根据CPU的数目来限定可用线程资源,不能根据连接并发数目来制定,也就是连接有限制。否则很难保证对客户端请求的高效和公平。
多线程之间的上下文切换,造成线程使用效率并不高,并且不易扩展
状态数据以及其他需要保持一致的数据,需要采用并发同步控制
2、NIO
那么可以有其他方式来更好的处理么,我们可以采用NIO来处理,NIO中支持的基本机制:
非阻塞的IO读写
基于IO事件进行分发任务,同时支持对多个fd的监听
我们看下NIO 中实现相关方式:
public NIOServer(int port) throws Exception {
selector = Selector.open();
serverSocket = ServerSocketChannel.open();
serverSocket.socket().bind(new InetSocketAddress(port));
serverSocket.configureBlocking(false);
serverSocket.register(selector, SelectionKey.OP_ACCEPT);
}
@Override
public void run() {
while (!Thread.interrupted()) {
try {
//阻塞等待事件
selector.select();
// 事件列表
Set selected = selector.selectedKeys();
Iterator it = selected.iterator();
while (it.hasNext()) {
it.remove();
//分发事件
dispatch((SelectionKey) (it.next()));
}
} catch (Exception e) {
}
}
}
private void dispatch(SelectionKey key) throws Exception {
if (key.isAcceptable()) {
register(key);//新链接建立,注册
} else if (key.isReadable()) {
read(key);//读事件处理
} else if (key.isWritable()) {
wirete(key);//写事件处理
}
}
private void register(SelectionKey key) throws Exception {
ServerSocketChannel server = (ServerSocketChannel) key
.channel();
// 获得和客户端连接的通道
SocketChannel channel = server.accept();
channel.configureBlocking(false);
//客户端通道注册到selector 上
channel.register(this.selector, SelectionKey.OP_READ);
}
我们可以看到上述的NIO例子已经差不多拥有reactor的影子了
基于事件驱动-> selector(支持对多个socketChannel的监听)
统一的事件分派中心-> dispatch
事件处理服务-> read & write
事实上NIO已经解决了上述BIO暴露的1&2问题了,服务器的并发客户端有了量的提升,不再受限于一个客户端一个线程来处理,而是一个线程可以维护多个客户端(selector 支持对多个socketChannel 监听)。
但这依然不是一个完善的Reactor Pattern ,首先Reactor 是一种设计模式,好的模式应该是支持更好的扩展性,显然以上的并不支持,另外好的Reactor Pattern 必须有以下特点:
更少的资源利用,通常不需要一个客户端一个线程
更少的开销,更少的上下文切换以及locking
能够跟踪服务器状态
能够管理handler 对event的绑定
那么好的Reactor Pattern应该是怎样的?
三、Reactor
在应用Java NIO构建Reactor Pattern中,大神 Doug Lea(让人无限景仰的java 大神)在“Scalable IO in Java”中给了很好的阐述。我们采用大神介绍的3种Reactor 来分别介绍。
首先我们基于Reactor Pattern 处理模式中,定义以下三种角色:
Reactor 将I/O事件分派给对应的Handler
Acceptor 处理客户端新连接,并分派请求到处理器链中
Handlers 执行非阻塞读/写 任务
1、单Reactor单线程模型
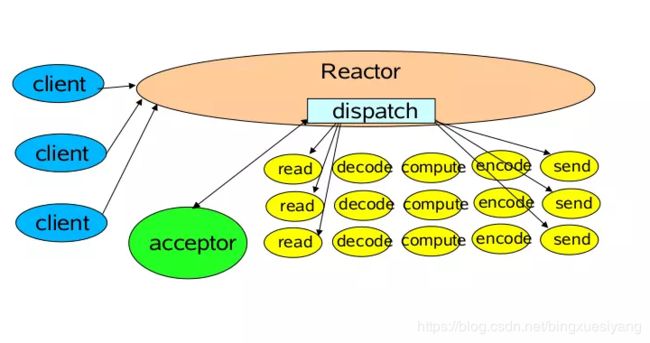
我们看代码的实现方式:
/**
* 等待事件到来,分发事件处理
*/
class Reactor implements Runnable {
private Reactor() throws Exception {
SelectionKey sk =
serverSocket.register(selector,
SelectionKey.OP_ACCEPT);
// attach Acceptor 处理新连接
sk.attach(new Acceptor());
}
public void run() {
try {
while (!Thread.interrupted()) {
selector.select();
Set selected = selector.selectedKeys();
Iterator it = selected.iterator();
while (it.hasNext()) {
it.remove();
//分发事件处理
dispatch((SelectionKey) (it.next()));
}
}
} catch (IOException ex) {
//do something
}
}
void dispatch(SelectionKey k) {
// 若是连接事件获取是acceptor
// 若是IO读写事件获取是handler
Runnable runnable = (Runnable) (k.attachment());
if (runnable != null) {
runnable.run();
}
}
}
/**
* 连接事件就绪,处理连接事件
*/
class Acceptor implements Runnable {
@Override
public void run() {
try {
SocketChannel c = serverSocket.accept();
if (c != null) {// 注册读写
new Handler(c, selector);
}
} catch (Exception e) {
}
}
}这是最基本的单Reactor单线程模型。其中Reactor线程,负责多路分离套接字,有新连接到来触发connect 事件之后,交由Acceptor进行处理,有IO读写事件之后交给hanlder 处理。
Acceptor主要任务就是构建handler ,在获取到和client相关的SocketChannel之后 ,绑定到相应的hanlder上,对应的SocketChannel有读写事件之后,基于racotor 分发,hanlder就可以处理了(所有的IO事件都绑定到selector上,有Reactor分发)。
该模型 适用于处理器链中业务处理组件能快速完成的场景。不过,这种单线程模型不能充分利用多核资源,所以实际使用的不多。
2、单Reactor多线程模型
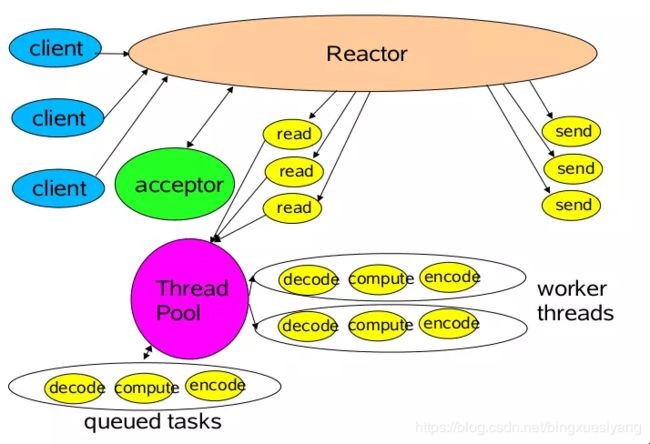
相对于第一种单线程的模式来说,在处理业务逻辑,也就是获取到IO的读写事件之后,交由线程池来处理,这样可以减小主reactor的性能开销,从而更专注的做事件分发工作了,从而提升整个应用的吞吐。
我们看下实现方式:
/**
* 多线程处理读写业务逻辑
*/
class MultiThreadHandler implements Runnable {
public static final int READING = 0, WRITING = 1;
int state;
final SocketChannel socket;
final SelectionKey sk;
//多线程处理业务逻辑
ExecutorService executorService = Executors.newFixedThreadPool(Runtime.getRuntime().availableProcessors());
public MultiThreadHandler(SocketChannel socket, Selector sl) throws Exception {
this.state = READING;
this.socket = socket;
sk = socket.register(selector, SelectionKey.OP_READ);
sk.attach(this);
socket.configureBlocking(false);
}
@Override
public void run() {
if (state == READING) {
read();
} else if (state == WRITING) {
write();
}
}
private void read() {
//任务异步处理
executorService.submit(() -> process());
//下一步处理写事件
sk.interestOps(SelectionKey.OP_WRITE);
this.state = WRITING;
}
private void write() {
//任务异步处理
executorService.submit(() -> process());
//下一步处理读事件
sk.interestOps(SelectionKey.OP_READ);
this.state = READING;
}
/**
* task 业务处理
*/
public void process() {
//do IO ,task,queue something
}
}
3、多Reactor多线程模型
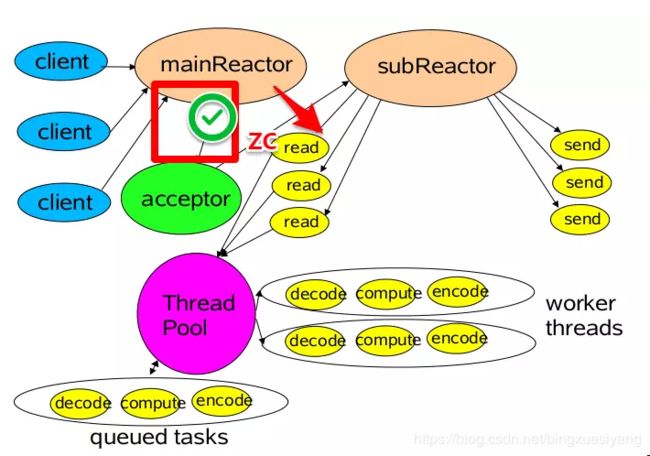
第三种模型比起第二种模型,是将Reactor分成两部分,
mainReactor负责监听server socket,用来处理新连接的建立,将建立的socketChannel指定注册给subReactor。
subReactor维护自己的selector, 基于mainReactor 注册的socketChannel多路分离IO读写事件,读写网 络数据,对业务处理的功能,另其扔给worker线程池来完成。
我们看下实现方式:
/**
* 多work 连接事件Acceptor,处理连接事件
*/
class MultiWorkThreadAcceptor implements Runnable {
// cpu线程数相同多work线程
int workCount =Runtime.getRuntime().availableProcessors();
SubReactor[] workThreadHandlers = new SubReactor[workCount];
volatile int nextHandler = 0;
public MultiWorkThreadAcceptor() {
this.init();
}
public void init() {
nextHandler = 0;
for (int i = 0; i < workThreadHandlers.length; i++) {
try {
workThreadHandlers[i] = new SubReactor();
} catch (Exception e) {
}
}
}
@Override
public void run() {
try {
SocketChannel c = serverSocket.accept();
if (c != null) {// 注册读写
synchronized (c) {
// 顺序获取SubReactor,然后注册channel
SubReactor work = workThreadHandlers[nextHandler];
work.registerChannel(c);
nextHandler++;
if (nextHandler >= workThreadHandlers.length) {
nextHandler = 0;
}
}
}
} catch (Exception e) {
}
}
}
/**
* 多work线程处理读写业务逻辑
*/
class SubReactor implements Runnable {
final Selector mySelector;
//多线程处理业务逻辑
int workCount =Runtime.getRuntime().availableProcessors();
ExecutorService executorService = Executors.newFixedThreadPool(workCount);
public SubReactor() throws Exception {
// 每个SubReactor 一个selector
this.mySelector = SelectorProvider.provider().openSelector();
}
/**
* 注册chanel
*
* @param sc
* @throws Exception
*/
public void registerChannel(SocketChannel sc) throws Exception {
sc.register(mySelector, SelectionKey.OP_READ | SelectionKey.OP_CONNECT);
}
@Override
public void run() {
while (true) {
try {
//每个SubReactor 自己做事件分派处理读写事件
selector.select();
Set keys = selector.selectedKeys();
Iterator iterator = keys.iterator();
while (iterator.hasNext()) {
SelectionKey key = iterator.next();
iterator.remove();
if (key.isReadable()) {
read();
} else if (key.isWritable()) {
write();
}
}
} catch (Exception e) {
}
}
}
private void read() {
//任务异步处理
executorService.submit(() -> process());
}
private void write() {
//任务异步处理
executorService.submit(() -> process());
}
/**
* task 业务处理
*/
public void process() {
//do IO ,task,queue something
}
}
第三种模型中,我们可以看到,mainReactor 主要是用来处理网络IO 连接建立操作,通常一个线程就可以处理,而subReactor主要做和建立起来的socket做数据交互和事件业务处理操作,它的个数上一般是和CPU个数等同,每个subReactor一个县城来处理。
此种模型中,每个模块的工作更加专一,耦合度更低,性能和稳定性也大量的提升,支持的可并发客户端数量可达到上百万级别。
关于此种模型的应用,目前有很多优秀的矿建已经在应用了,比如mina 和netty 等。上述中去掉线程池的第三种形式的变种,也 是Netty NIO的默认模式。下一节我们将着重讲解netty的架构模式。
四、事件处理模式
在 Douglas Schmidt 的大作《POSA2》中有关于事件处理模式的介绍,其中有四种事件处理模式:
Reactor
Proactor
Asynchronous Completion Token
Acceptor-Connector
1. Proactor
本文介绍的Reactor就是其中一种,而Proactor的整体结构和reacotor的处理方式大同小异,不同的是Proactor采用的是异步非阻塞IO的方式实现,对数据的读写由异步处理,无需用户线程来处理,服务程序更专注于业务事件的处理,而非IO阻塞。
2. Asynchronous Completion Token
简单来说,ACT就是应对应用程序异步调用服务操作,并处理相应的服务完成事件。从token这个字面意思,我们大概就能了解到,它是一种状态的保持和传递。
比如,通常应用程序会有调用第三方服务的需求,一般是业务线程请求都到,需要第三方资源的时候,去同步的发起第三方请求,而为了提升应用性能,需要异步的方式发起请求,但异步请求的话,等数据到达之后,此时的我方应用程序的语境以及上下文信息已经发生了变化,你没办法去处理。
ACT 解决的就是这个问题,采用了一个token的方式记录异步发送前的信息,发送给接受方,接受方回复的时候再带上这个token,此时就能恢复业务的调用场景。
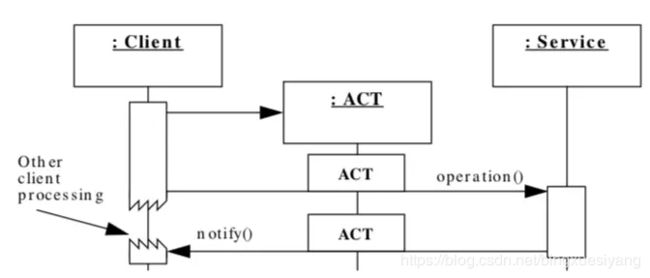
上图中我们可以看到在client processing 这个阶段,客户端是可以继续处理其他业务逻辑的,不是阻塞状态。service 返回期间会带上token信息。
3. Acceptor-Connector
Acceptor-Connector是于Reactor的结合,也可以看成是一种变种,它看起来很像上面介绍的Reactor第三种实现方式,但又有本质的不同。
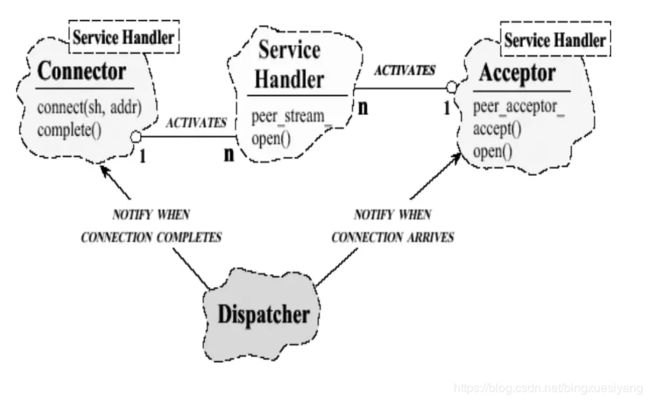
Acceptor-Connector模式是将网络中对等服务的连接和初始化分开处理,使系统中的连接建立及服务一旦服务初始化后就分开解除耦合。连接器主动地建立到远地接受器组件的连接,并初始化服务处理器来处理在连接上交换的数据。同样地,接受器被动地等待来自远地连接器的连接请求,在这样的请求到达时建立连接,并初始化服务处理器来处理在连接上交换的数据。随后已初始化的服务处理器执行应用特有的处理,并通过连接器和接受器组件建立的连接来进行通信。
这么处理的好处是:
一般而言,用于连接建立和服务初始化的策略变动的频度要远小于应用服务实现和通信协议。
容易增加新类型的服务、新的服务实现和新的通信协议,而又不影响现有的连接建立和服务初始化软件。比如采用IPX/SPX通信协议或者TCP协议。
连接角色和通信角色的去耦合,连接角色只管发起连接 vs. 接受连接。通信角色只管数据交互。
将程序员与低级网络编程API(像socket或TLI)类型安全性的缺乏屏蔽开来。业务开发关系底层通信
转载:https://my.oschina.net/u/1859679/blog/1844109