虢国飞:饿了么异地双活数据库实战
【IT168 专稿】本文根据虢国飞老师在2018年5月12日【第九届中国数据库技术大会】现场演讲内容整理而成。
讲师简介: 虢国飞,饿了么 DBA负责人。从事数据库行业10+年,专注于MySQL、PgSQL、MSSQL等数据库领域的管理、研究和平台的研发等工作,目前负责饿了么数据库团队的管理和数据库维护方面的工作。

摘要: 异地多活(双活)技术一直是行业内一个比较大的技术挑战,当中要突破诸多的技术难点,很多公司都做过类似的尝试,但是往往止步于灾备阶段难以向前;饿了么双活项目通过前期丰富的调研,真正启动改造实施只有短短三个月就完成了上线,并且一次性上线成功,当中也遇到了不少的问题踩过很多坑,尤其是在数据库这一块的问题会比较多,因为在多活设计中大家最担心的点是怎么保证数据在多个机房实时同步、如何才能保障数据不被写坏和怎么兜底保障数据的一致性,这些点对数据库方面的挑战很大(极容易出现重大事故),所以本次分享会对这些难点做一个全面介绍,内容包括饿了么多活中数据库的架构、改造、难点、收益与展望等,重点会介绍数据库为多活所做的改造、多活过程中和上线后DBA所面临的挑战和我们是怎么克服这些困难的,期望能为大家揭开多活技术的在数据库这层面纱,为大家进行类似技术方面的改造提供参考。
分享大纲:
1、多活难点&设计原则
2、多活架构&切换
3、数据库改造&挑战
4、收益&展望
正文:
1、多活难点&设计原则
从多活落地后回过头来看,多活的难点还是有很多的。
首先,同城Or异地的问题。如果是做同城多活,和异地比成本投入会少很多,起码光纤距离和带宽费用就会少很多。另外,异地多活实现起来会更复杂,涉及跨网络的延时,需要有更周密的方案,而同城访问一般不需要做太多的改造,相当于是同机房的调用。异地多活的劣势是改造大、成本高,但是与同城相比,存在天然优势,最直观直观来看我们的扩容就不会受地域的限制,而同城机房就不能解决这个问题。
异地多活除了成本高外,异常情况下的数据处理方案,如数据出现错乱,冲突,环路,或者一致性问题等,都需要重点考虑。
总的来看,异地多活的难点其实主要有三个,第一,如何做好分流和控制;第二,如何解决跨机房延时带来的问题(访问&数据);第三, 如何解决数据安全性。
基于上述这些问题,我们抽取了一些设计原则:
1)、业务内聚。跨机房自然会存在延时,但我们希望一笔交易能在同一个机房完成,减少跨机房的调用; 即一个订单的生命周期在一个机房中完成,这样可以避免跨机房延迟带来的影响。
2)、可用性优先。绝大部分互联网公司都是基于这个原则(base),优先保证系统可用,对饿了么来讲就是先让用户可以下单吃饭,容忍暂时数据不一致,事后修复。
3)、保证正确性。在确保可用的情况下,需要对数据做保护以避免错误。
4)、业务可感。业务团队修改逻辑,能够识别出业务单元的边界,只处理本单元的数据,打造强大的业务状态机,在出现异常时能发现和纠正错误。
除此外,还有设计分区原则。我们在云端部署了一个智能DNS,并且是在多个云端,根据用户所在的POI位置,来完成用户的分流。相当于是对机房的一个映射,把全国分成很多区,机房和分区是一对多的关系,如果用户从某个位置进来,就会对应到某个逻辑分区,分区最终会路由到对应的物理机房,完成基于用户位置的分流。
2、多活架构&切换
那么,多活的实际架构是怎样的呢?

我们会在云端部署智能DNS,完成用户的分流,用户通过DNS进来就决定它的流量会落到哪个机房,他的整笔交易基本上是在同一个机房来完成的。所以,用户的使用不会受到跨机房的影响。另外,我们在底层也有相应兜底的架构应对方案,防止因前段路由异常情况下造成数据的错乱。

这是我们在做数据同步时很重要的一个组件,叫做DRC。主要任务是在底层完成两个机房之间的数据同步。设计原则是在每个机房部署相应的通道,一端接受的是数据变更,然后把变更同步到另一端机房,完成数据双向同步。
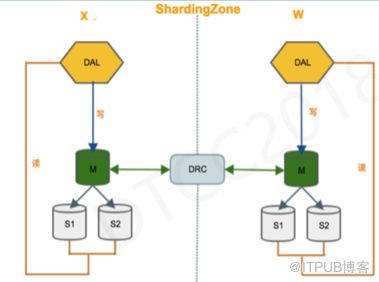

在DB这端,我们看到最前面的架构图有两个。一个是ShardingZone,另外一个是GlobalZone。ShardingZone的主要特点是,适用于业务能按区域维度进行切分的应用,实现真正的多活, 而且读写都在本地机房进行;这个架构正常情况下,只需要本地机房的数据,对其他机房数据无依赖,所以跨机房数据延时是无影响的,我们设计时只需要考虑避免数据同步冲突(DRC冲突处理、自增值DB控制)。GlobalZone架构适用于特殊场景,比如需要对数据有强一致性的要求或者没有分区标签,它的写是在同一个机房,但读是在本地机房完成,这样在读的时候会有数据延时,所以我们要按照业务分,有些业务能接受一定程度的延时,他才会选用这种数据完全一致的架构。
具体DB的切换动作是怎么操作的呢?

其实绝大部分情况DB都是不需要做切换动作的,因为只有GlobalZone的写入需要变动的时候才是需要DB切换的,其他情况的流量调整和切换只需要GZS控制前端做路由调整就行(DB不需要跟着切)。DB在切换的时候,会有锁、等待动作,是为了保障数据完成同步。当然,等待也有时间限制,如果超时也会强切。
看下大概过程,比如我们把1机房的DB访问切换到2机房,会先发出一个BLOCK的操作,把1机房的DB写入先锁住,等后面的数据同步和验证操作完成后,GZS会控制其他组件把1机房的访问流量改到到机房2,DAL会完成DB写入的机房间切换。
3、数据库改造&挑战
在做多机房最先要做的就是要全量同步数据,包括测试环境、生产环境数据全量同步等问题。第二DRC为了解决数据冲突问题,需要增加毫秒级别的时间戳,但是我们在数据库设计阶段,并不会有这样的字段,所以要做很多更新。第三做多活后很多自增列也会调整,防止溢出。第四多活有不同的架构类型,所以不同类型的DB需要迁移,将同类型的DB拆分到对应的架构里,不同类型的拆开。还有原生复制改成DRC复制、账号网段调整、各个集群参数一致性调整、按集群类型调整HA配置等等动作。总的来说,首先要做数据搬移,然后适配多活的体系改造,还有个各种数据库的配置也需要调整。做完多活以后,实例、集群、Proxy、HA、数据量、DDL、机器故障等几乎都是翻倍状态。
为了应对数据库改造问题,DBA做了哪些基础工作呢?
首先,要有检测数据是不是一致性的最终方案。当然,我们在前端、后端有一些相应的保护。比如在路由这层,会有几个路由来判断订单是不是正确地进入了对应的机房,DAL这层也会判断这笔交易是不是符合路由规则,不正确的话会直接拒绝。但是还是会出现一些问题,比如:软件上的BUG,或者是没考虑到的问题和设计之外的异常场景,会导致数据穿透到底层,造成多个机房数据不一致,所以我们要做兜底的最终数据是否一致的校验。我们开发了DCP数据校验平台,能完成分钟级别的数据校验, DCP不只完成全量、增量、延时校验、手动校验,还有数据结构、多维校验,还要考虑各种延迟、并发、校验时长等情况;最重要的是要有一套比较方便的修复数据的方式或者配套工具,因为你找到不一致数据后,工具如果不能直观告诉你怎么去修复,又会是一个大问题,而且数据还会一直在变,可能会造成其他的影响。
其次,会涉及到数据的迁移、会有大表拆小表这种动作。所以我们研发了D-Bus这套工具,它可以完成DB&Table迁移 、增量和实时同步(包括暂停、断点续传)、单表和Sharding表数据互转、数据校验等工作。
第三,在系统切换的时候,HA如何与其他系统完成对接,这也是一个重要问题。我们做了一套自动化系统,叫做EMHA 。在HA切换的时候,可以和其他组件完成互动,进行配置、切换、联动(DAL、DRC)。

第四,DDL翻倍的问题。比如100G的一个表,我们如果通过DRC把变更数据传递到另外一个机房,而且是在跨地域网络的情况下,网络可能会爆掉。所以,在DRC这层实际上是不方便来做DDL操作的传递的,DRC要把这个动作滤掉。我们DDL操作类型比较多,有原生能支持Online的DDL直接分发,还有PT的工具,还有自己研发的mm-ost的工具等。
多活场景下DDL具体要考虑什么问题呢?首先是控制,DDL的时候空间&延时&锁&定时&低峰期&风险&预估时长等要得到有效的控制;另外,我们的类型比较复杂,包括:非多活 、ShardingZone、GlobalZone、多推、 Sharding(分开分表)等业务,要控制好DDL的同步,同时要保障所有的表都达到一致的状态;还有多机房的问题,我们通过Mm-ost,保证多机房一致性问题,同时保证跨机房延时在3-5s之间。
之前DDL很大一部分工作是由DBA来做(研发提供单DBA负责处理),现在已经不需要DBA做太多的事情了,由研发自助发布,自助发布的比例超过90%以上,极少数情况下才需要DBA来干预,还有一部分是系统自动执行(不要研发,也不需要DBA来做)。
4、收益&展望
很多人可能会有疑问,多活花费这么大的成本,是否值得?
首先,看下多活的收益。第一,打破了单机房(地域)容量瓶颈,当主机房不能再放机器,而且系统容量已经到上线时,你可以把流量引流到其他机房,让多个机房能承载容量。第二,你的故障不受单机房(地域)故障影响,在做多活之前,其实我们有主力机房核心交换机出现故障的情况,当时没有多活的只能厂商来解决,核心的交换机宕机了三个小时,影响非常大,但是我们却束手无策,而且我们的业务特点有两个尖峰,尤其在中午尖峰的时候挂了,损失会很大。第三,动态调整各机房流量,如果有机房资源紧张,可做动态调配,或者哪个地方访问不均衡,也可以做动态调整。第四,Online维护(通过GZS、DAL、DRC、D-Bus、DCP这些组件的配合),有多活之后如果你想做哪些升级,可以先把流量切到一个机房,在没有流量的机房完成各种动作,都没问题,所以我们现在主要业务基本没有停机维护之说。
针对企业未来发展,我们也有一些相应的计划。首先是,想做多个机房 。现在很多企业都在计划上云,我们也希望在云上做一个多活的Zone,去分担一部分流量,而且云上还可以动态调整资源。其次是,Data-Sharding,现在做的还是全量数据,上层流量访问是分流量的,底层我们也在考虑对数据分流。其三是, 自动动态扩缩容,这也是我们想上云的原因,考虑在业务高峰的时候多添加一些资源,低峰的时候释放掉这些资源,合理控制成本。其四是,多机房强一致,我们也在做相应方案调研,希望对一致性要求高的部分也能做到多活。
来自 “ ITPUB博客 ” ,链接:http://blog.itpub.net/31545808/viewspace-2222212/,如需转载,请注明出处,否则将追究法律责任。
转载于:http://blog.itpub.net/31545808/viewspace-2222212/