我相信大家都用过STL中的priority_queue,并且你可能也知道其底层原理是二叉堆(binary heap),但是你真正了解它具体是怎么实现的吗?你能自己写个优先队列模板而不用STL中的吗?刨根问底才是学习的最高境界(当然,这里探讨的只是简单的实现)。
优先队列模型

二叉堆
对于优先队列的实现,二叉堆的使用很常见。与二叉查找树(binary search tree)一样,堆也有两个性质,即结构性质和堆序性质。类似于AVL树,对堆的操作可能破坏其中一个性质,因此,堆的操作必须到堆的所有性质都被满足是才能终止。
结构性质
堆是一棵完全二叉树(complete binary tree)。我们知道,一棵高为 h 的完全二叉树有 2h 到 2h+1-1 个结点。这意味着,完全二叉树的高为O(logN)。
一个重要的观察发现,因为完全二叉树很有规律,所以可以用一个数组表示而不需要使用链。下图2中的数组对应着图1中用二叉树表示的堆。

对于数组中任一位置 i 上的元素,其左儿崽在位置 2i 上,右儿子在位置 2i+1 中,它的父亲则在位置 i /2上。因此,这里不仅不需要链,而且遍历该树所需要的操作也极为简单。这种实现方法的唯一问题在于,最大的堆大小需要事先估计,但一般情况下这并不成问题(而且如果需要我们可以重新调整)。
因此,一个堆数据结构由一个数组(Comparable对象的)和一个代表当前堆大小的整数组成。下面的代码为一个优先队列接口:
template
class BinaryHeap
{
public:
// constructor
explicit BinaryHeap(int capacity = 100);
explicit BinaryHeap(const vector& items);
bool isEmpty() const;
const Comparable& findMin() const;
void insert(const Comparable& x);
void deleteMin();
void deleteMin(const Comparable& minItem);
void makeEmpty();
void printArray();
private:
int currentSize; //Number of elements in heap
vector array; //The heap array
void buildHeap();
void percolateDown(int hole);
};
我们始终把堆画成树,是便于理解,但实际上具体的实现是采用简单的数组。
堆序性质
使操作可以快速执行的性质是堆序性质(heap-order property)。由于想要快速地找出最小元,因此最小元应该在根上。如果考虑任意子树也应该是堆,那么任意结点就应该小于它的所有后裔。
应用这个逻辑,可以得到堆序性质。在堆中,对于每一个结点 X,X 的父亲中的键小于或等于 X 中的键,根节点除外(它没有父亲)。下图左边的树是一个堆,但是,右边的不是。

根据堆序性质,最小元总可以在根处找到。因此,我们可以以 O(1) 时间得到附加操作 findMin。
基本的堆操作
1. insert
为将一个元素 X 插入到堆中,我们在下一个空闲位置创建一个空穴。如果 X 可以放在空穴中而不破坏堆序性质,那么插入完成。否则,按上滤(percolate up)策略进行,该操作如下图所示:


使用下面的代码很容易实现插入:
/**
* Insert item x, allowing duplicates.
*/
template
void BinaryHeap::insert(const Comparable& x)
{
if (currentSize == array.size() - 1)
{
array.resize(array.size() * 2);
}
// percolate up(上滤)
int hole = ++currentSize;
for (; hole > 1 && x < array[hole/2]; hole /= 2) //array[0] don't put heap element
{
array[hole] = array[hole / 2];
}
array[hole] = x;
}
我们本可以通过反复实施交换操作直至建立正确的顺序来实现上滤过程,可是一次交换需要 3 条赋值语句。如果一个元素上滤 d 层,那么由于交换而实施的赋值次数达到 3d,而这里的代码只需要 d+1 次赋值。
显然,insert 操作的最坏时间复杂度为 O(logN)。平均看来,这种上滤终止得要早;业已证明,其平均时间复杂度为 O(1)。
2. deleteMin
findMin操作是简单的,困难的部分在于:删除它。我们的策略是用堆中最后一个元素替换根,然后实行下滤(percolate down)操作。如下图所示:
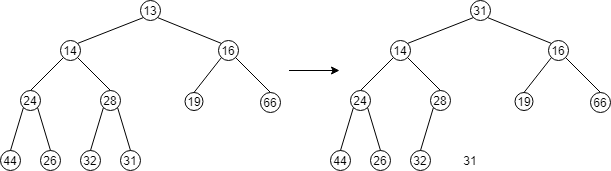

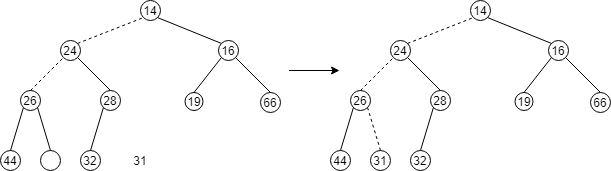
在堆的实现中经常发生的错误为:当堆中存在偶数个元素时,最后一个非叶子结点将只有一个崽崽,我们每次都是取崽崽中小的那个作为下滤的对象,所以这个时候就需要一个附加的测试。下面代码的 if 语句中的 child != currentSize 避免了这个容易发生的错误。
/**
* Remove the minimum item.
* Throws UnderflowException if empty.
*/
template
void BinaryHeap::deleteMin()
{
if (isEmpty())
{
//throw UnderflowException();
cout << "the array is empty!";
}
array[1] = array[currentSize--];
percolateDown(1);
}
/**
* Internal method to percolate down in the heap.
* hole is the index which the percolate down begins.
*/
template
void BinaryHeap::percolateDown(int hole)
{
Comparable temp = array[hole];
int child;
for (; hole * 2 <= currentSize; hole = child)
{
child = hole * 2;
if (child != currentSize && array[child + 1] < array[child])
{
child++;
}
if (array[child] < temp)
{
array[hole] = array[child];
}
else
{
break;
}
}
array[hole] = temp;
}
这种操作的平均运行时间为 O(logN)。
3. buildHeap
初始堆通过项的原始集合来构造。构造函数将 N 项作为输入并把它们放入一个堆中。显然,这可以通过 N 次连续的 insert 来完成。由于每个 insert 操作都花费 O(1) 的平均时间,以及 O(logN) 的最坏情形时间,这个算法的总的运行时间就是 O(logN) 平均时间,其最坏情形时间为 O(NlogN)。
通常的算法是将 N 项以任意顺序放入树中,并保持结构特性。然后从最后一个非叶子结点开始,一直到根,对这些结点执行下滤(percolate down)操作,可以保证能够生成一棵具有堆序性质的树(heap-ordered tree)。
template
BinaryHeap::BinaryHeap(const vector& items):currentSize(items.size()),array(items.size()+10)
{
/*currentSize = items.size();
array(items.size() + 10);*/
for (int i = 0; i < (int)items.size(); ++i)
{
array[i + 1] = items[i];
}
this->buildHeap();
}
/**
* Establish heap order property from an arbitrary arrangement of items.
* Runs in linear time.
*/
template
void BinaryHeap::buildHeap()
{
for (int i = currentSize / 2; i > 0; --i)
{
percolateDown(i);
}
}
可以证明(略):buildHeap 的运行时间的界为:O(N)。
以上,便是优先队列的具体实现。我在文章开头说了,这只是基本的实现,高级实现还远远不够,包括左式堆、斜堆、二项队列等等(这些我也还没看呢嘻嘻)。
PS:
看别人的代码永远只是看看,自己将其实现,以后还可以拿来用的勒,到时候需要另外的功能自己扩充就行了 sha !
有什么error评论指出来啊!!!