引言:
上一节简单介绍了redis的安装与使用,与redis一样的缓存组件还有memcached,大体接入方式类似,这里就不重复介绍了,大家可以google具体memcached安装以及使用方式。那么这一节将围绕redis以及memcached两大分布式最常用的缓存组件,对它们各自使用的网络IO模型进行分析。
简介:
本篇博客主要针对redis的单线程模型,epoll事件驱动。以及memcached多线程模型,libevent事件驱动进行对比分析,了解他们各自的设计思想与应用层的利弊。
目录:1.redis的单线程模型
2.memcached的多线程模型
正文:
引用一段CSDN博主对于redis架构的描述:
Redis单线程架构
1 单线程模型(linux只有轻量级进程,ps命令也会出线程,由于博主不搞底层开发,就把模拟进程称为线程)
Redis客户端对服务端的每次调用都经历了发送命令,执行命令,返回结果三个过程。其中执行命令阶段,由于Redis是单线程来处理命令的,所有每一条到达服务端的命令不会立刻执行,所有的命令都会进入一个队列中,然后逐个被执行。并且多个客户端发送的命令的执行顺序是不确定的。但是可以确定的是不会有两条命令被同时执行,不会产生并发问题,这就是Redis的单线程基本模型。
2 单线程模型每秒万级别处理能力的原因
(1)纯内存访问。数据存放在内存中,内存的响应时间大约是100纳秒,这是Redis每秒万级别访问的重要基础。
(2)非阻塞I/O,Redis采用epoll做为I/O多路复用技术的实现,再加上Redis自身的事件处理模型将epoll中的连接,读写,关闭都转换为了时间,不在I/O上浪费过多的时间。
(3)单线程避免了线程切换和竞态产生的消耗。
(4)Redis采用单线程模型,每条命令执行如果占用大量时间,会造成其他线程阻塞,对于Redis这种高性能服务是致命的,所以Redis是面向高速执行的数据库。
ok,看完了以上描述,我的总结是:
总体来说:
1)绝大部分请求是纯粹的内存操作(非常快速)
2)采用单线程,避免了不必要的上下文切换和竞争条件
3)非阻塞IO 、epoll event loop。
Redis的单线程的行为主要是对内存的读写,这些操作其实用不了多少时间,因此瓶颈在网络I/O上面,我们一般提供较好的网络环境就可以提升Redis的吞吐量,比如提高网络带宽,除此之外还可以通过合并命令提交批处理请求(pipeline)来代替单条命令一次次请求从而减少网络开销,提高吞吐量。
我们来进一步研究redis的网络模型,redis是封装了下图几种多路复用器实现的EventLoop事件轮训,redis没有采用memcached采用的Libevent,Libevent为了迎合通用性造成代码庞大及牺牲了在特定平台的不少性能。Redis一直坚持设计小巧并去依赖库的思路,提供Socket句柄事件的多路复用器,这部分分别对于不同平台提供了不同的实现,比如epoll和select可以用于linux平台、kqueue可以用于苹果平台、evpoll可以用于Solaris平台,这里并没有看到iocp,也就是Redis对于Windows支持并不是很好。

什么是多路I/O复用?
(1) 网络IO都是通过Socket实现,Server在某一个端口持续监听,客户端通过Socket(IP+Port)与服务器建立连接(ServerSocket.accept),成功建立连接之后,就可以使用Socket中封装的InputStream和OutputStream进行IO交互了。针对每个客户端,Server都会创建一个新线程专门用于处理
(2) 默认情况下,网络IO是阻塞模式,即服务器线程在数据到来之前处于【阻塞】状态,等到数据到达,会自动唤醒服务器线程,着手进行处理。阻塞模式下,一个线程只能处理一个流的IO事件
(3) 为了提升服务器线程处理效率,有以下三种思路
(1)非阻塞【忙轮询】:采用死循环方式轮询每一个流,如果有IO事件就处理,这样可以使得一个线程可以处理多个流,但是效率不高,容易导致CPU空转
(2)Select代理(无差别轮询):可以观察多个流的IO事件,如果所有流都没有IO事件,则将线程进入阻塞状态,如果有一个或多个发生了IO事件,则唤醒线程去处理。但是还是得遍历所有的流,才能找出哪些流需要处理。
(3)Epoll代理:Select代理有一个缺点,线程在被唤醒后轮询所有的Stream,还是存在无效操作。 Epoll会哪个流发生了怎样的I/O事件通知处理线程,因此对这些流的操作都是有意义的。
Linux下epoll属于IO多路复用,但他实际应用必须搭配no-blocking io ,执行epoll和具体业务都是在同个主进程中执行。虽然纯内存的业务操作很快,但在执行业务时,有新的请求到来那么kernel中发现readylist正在被使用时,会把就绪事件放在ovflist中当处理完readylist后,会检查ovflist是否有事件。
首先,Redis服务器中有两类事件,文件事件和时间事件。
文件事件(file event):Redis客户端通过socket与Redis服务器连接,而文件事件就是服务器对套接字操作的抽象。例如,客户端发了一个GET命令请求,对于Redis服务器来说就是一个文件事件。
时间事件(time event):服务器定时或周期性执行的事件。例如,定期执行RDB持久化。
在这里我们主要关注Redis处理文件事件的模型:Reactor模型
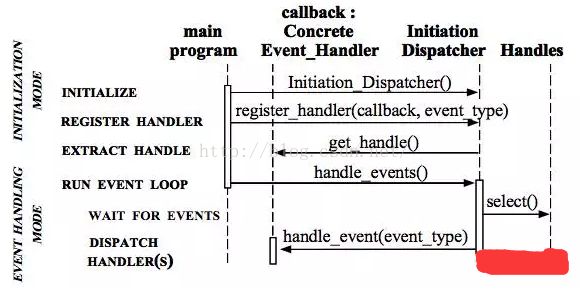
Handles :表示操作系统管理的资源,我们可以理解为fd。
Synchronous Event Demultiplexer :同步事件分离器,阻塞等待Handles中的事件发生。
Initiation Dispatcher :初始分派器,作用为添加Event handler(事件处理器)、删除Event handler以及分派事件给Event handler。也就是说,Synchronous Event Demultiplexer负责等待新事件发生,事件发生时通知Initiation Dispatcher,然后Initiation Dispatcher调用event handler处理事件。
Event Handler :事件处理器的接口
Concrete Event Handler :事件处理器的实际实现,而且绑定了一个Handle。因为在实际情况中,我们往往不止一种事件处理器,因此这里将事件处理器接口和实现分开,与C++、Java这些高级语言中的多态类似。
2.memcached网络IO模型
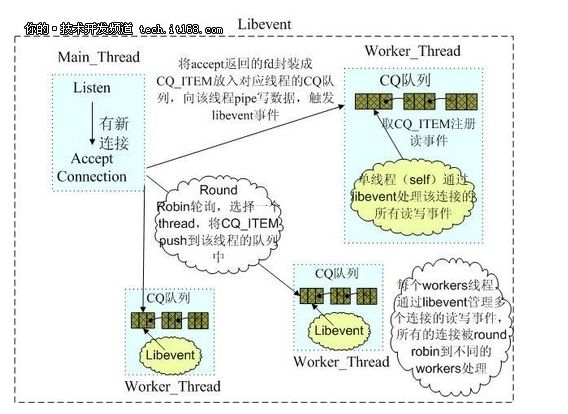
Memcached是多线程,非阻塞IO复用的网络模型,分为监听主线程和worker子线程,监听线程监听网络连接,接受请求后,将连接描述字pipe 传递给worker线程,进行读写IO, 网络层使用libevent封装的事件库,多线程模型可以发挥多核作用,但是引入了cache coherency和锁的问题,比如,Memcached最常用的stats 命令,实际Memcached所有操作都要对这个全局变量加锁,进行计数等工作,带来了性能损耗。
Libevent应该算是包含了上述一些功能,总体来说也是走事件驱动+no blocking io。会有一个fd和event的mapping关系,至于linux内核对于唤醒的细节就没有多研究了,那总体对比下来,io层面的话,redis有单线程的优势、批量pipeline的优势,memcached有多核优势,但是多了一些同步的损耗,但是在内存管理方面以及集群方面,redis是动态分配,memcached是分配比较固定的chunk,那对于某些字节比chunk小的情况,就有浪费的空间,集群方面memcached服务端是没有分布式的,redis在3.0提供了cluster,这个后续讨论,具体性能对比还需要区分数据量 数据格式 集群方案等,下篇文章主要分析两者在内存管理上的区别。