openresty 常用Lua开发库Json库、cache 使用、编码转换
location ~ /lua_iconv {
default_type 'text/html';
charset gbk;
lua_code_cache on;
content_by_lua_file /usr/example/lua/test_iconv.lua;
}
lua_code_cache 表示 缓存lua脚本内容
JSON库
在进行数据传输时JSON格式目前应用广泛,因此从Lua对象与JSON字符串之间相互转换是一个非常常见的功能;目前Lua也有几个JSON库,本人用过cjson、dkjson。其中cjson的语法严格(比如unicode \u0020\u7eaf),要求符合规范否则会解析失败(如\u002),而dkjson相对宽松,当然也可以通过修改cjson的源码来完成一些特殊要求。而在使用dkjson时也没有遇到性能问题,目前使用的就是dkjson。使用时要特别注意的是大部分JSON库都仅支持UTF-8编码;因此如果你的字符编码是如GBK则需要先转换为UTF-8然后进行处理。
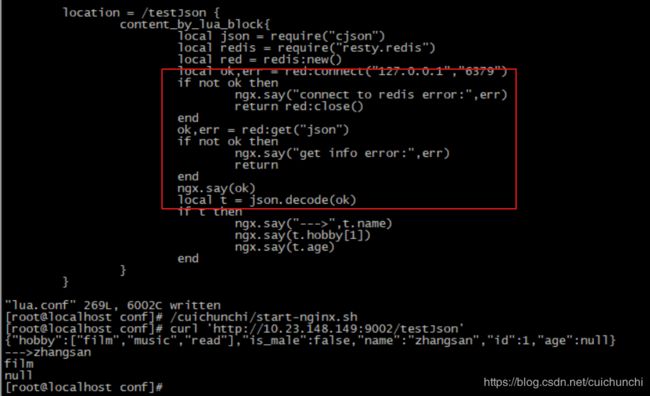
local cjson = require("cjson")
--lua对象到字符串
local obj = {
id = 1,
name = "zhangsan",
age = nil,
is_male = false,
hobby = {"film", "music", "read"}
}
local str = cjson.encode(obj)
ngx.say(str, "
")
--字符串到lua对象
str = '{"hobby":["film","music","read"],"is_male":false,"name":"zhangsan","id":1,"age":null}'
local obj = cjson.decode(str)
ngx.say(obj.age, "
")
ngx.say(obj.age == nil, "
")
ngx.say(obj.age == cjson.null, "
")
ngx.say(obj.hobby[1], "
")
--循环引用
obj = {
id = 1
}
obj.obj = obj
-- Cannot serialise, excessive nesting
--ngx.say(cjson.encode(obj), "
")
local cjson_safe = require("cjson.safe")
--nil
ngx.say(cjson_safe.encode(obj), "
") 
null将会转换为cjson.null;循环引用会抛出异常Cannot serialise, excessive nesting,默认解析嵌套深度是1000,可以通过cjson.encode_max_depth()设置深度提高性能;使用cjson.safe不会抛出异常而是返回nil。
还有一种方式 dkjson
下载类库
- cd /usr/example/lualib/
- wget http://dkolf.de/src/dkjson-lua.fsl/raw/dkjson.lua?name=16cbc26080996d9da827df42cb0844a25518eeb3 -O dkjson.lua
local dkjson = require("dkjson") --lua对象到字符串 local obj = { id = 1, name = "zhangsan", age = nil, is_male = false, hobby = {"film", "music", "read"} } local str = dkjson.encode(obj, {indent = true}) ngx.say(str, "
") --字符串到lua对象 str = '{"hobby":["film","music","read"],"is_male":false,"name":"zhangsan","id":1,"age":null}' local obj, pos, err = dkjson.decode(str, 1, nil) ngx.say(obj.age, "
") ngx.say(obj.age == nil, "
") ngx.say(obj.hobby[1], "
") --循环引用 obj = { id = 1 } obj.obj = obj --reference cycle --ngx.say(dkjson.encode(obj), "
")默认情况下解析的json的字符会有缩排和换行,使用{indent = true}配置将把所有内容放在一行。和cjson不同的是解析json字符串中的null时会得到nil。
编码转换
我们在使用一些类库时会发现大部分库仅支持UTF-8编码,因此如果使用其他编码的话就需要进行编码转换的处理;而Linux上最常见的就是iconv,而lua-iconv就是它的一个Lua API的封装。
安装lua-iconv可以通过如下两种方式:
ubuntu下可以使用如下方式
Java代码
- apt-get install luarocks
- luarocks install lua-iconv
- cp /usr/local/lib/lua/5.1/iconv.so /usr/example/lualib/
源码安装方式,需要有gcc环境
Java代码
- wget https://github.com/do^Cloads/ittner/lua-iconv/lua-iconv-7.tar.gz
- tar -xvf lua-iconv-7.tar.gz
- cd lua-iconv-7
- gcc -O2 -fPIC -I/usr/include/lua5.1 -c luaiconv.c -o luaiconv.o -I/usr/include
- gcc -shared -o iconv.so -L/usr/local/lib luaiconv.o -L/usr/lib
- cp iconv.so /usr/example/lualib/
1、test_iconv.lua
Java代码
- ngx.say("中文")
此时文件编码必须为UTF-8,即Lua文件编码为什么里边的字符编码就是什么。
2、example.conf配置文件
Java代码
- location ~ /lua_iconv {
- default_type 'text/html';
- charset gbk;
- lua_code_cache on;
- content_by_lua_file /usr/example/lua/test_iconv.lua;
- }
通过charset告诉浏览器我们的字符编码为gbk。
3、访问 http://192.168.1.2/lua_iconv会发现输出乱码;
此时需要我们将test_iconv.lua中的字符进行转码处理:
Java代码
- local iconv = require("iconv")
- local togbk = iconv.new("gbk", "utf-8")
- local str, err = togbk:iconv("中文")
- ngx.say(str)
通过转码我们得到最终输出的内容编码为gbk, 使用方式iconv.new(目标编码, 源编码)。
有如下可能出现的错误:
Java代码
- nil
- 没有错误成功。
- iconv.ERROR_NO_MEMORY
- 内存不足。
- iconv.ERROR_INVALID
- 有非法字符。
- iconv.ERROR_INCOMPLETE
- 有不完整字符。
- iconv.ERROR_FINALIZED
- 使用已经销毁的转换器,比如垃圾回收了。
- iconv.ERROR_UNKNOWN
- 未知错误
iconv在转换时遇到非法字符或不能转换的字符就会失败,此时可以使用如下方式忽略转换失败的字符
Java代码
- local togbk_ignore = iconv.new("GBK//IGNORE", "UTF-8")
另外在实际使用中进行UTF-8到GBK转换过程时,会发现有些字符在GBK编码表但是转换不了,此时可以使用更高的编码GB18030来完成转换。
更多介绍请参考http://ittner.github.io/lua-iconv/。
cache缓存的使用
第一种:ngx_lua模块本身提供了全局共享内存ngx.shared.DICT可以实现全局共享。
第二种:也可以使用如Redis来实现缓存。
第三种:还一个lua-resty-lrucache实现,其和ngx.shared.DICT不一样的是它不是每Worker进程共享,即每个Worker进行会有一份缓存,而且经过实际使用发现其性能不如ngx.shared.DICT。但是其好处就是不需要进行全局配置
如何选择?
shared.dict使用的共享内存,每次操作都是全局锁,如果高并发环境,不同worker之间容易引起竞争。所以单个shared.dict的体积不能过大。
lrucache是worker内使用的,由于nginx是单进程方式存在,所以永远不会出现触发锁,效率上优势,且没有体积限制,内存上有弹性,但是不同的worker之间的数据是不共享的,同一缓存s数据可能被冗余存储。
以下就讲诉下第一种和第三种方式

local lrucache = require("resty.lrucache")
--创建缓存实例,并指定最多缓存多少条目
local cache, err = lrucache.new(200)
if not cache then
ngx.log(ngx.ERR, "create cache error : ", err)
end
local function set(key, value, ttlInSeconds)
cache:set(key, value, ttlInSeconds)
end
local function get(key)
return cache:get(key)
end
local _M = {
set = set,
get = get
}
return _M在lualib下建立自己的缓存lua文件,然后在nginx配置文件引入自己的缓存文件。此处利用了模块的特性实现了每个Worker进行只初始化一次cache实例。lua_code_cache 指令开启lua文件缓存,下次再次使用直接从缓存取脚本,不再编译。
下面使用 全局指令缓存 ngx.shared.my_cache
使用在 nginx.conf 中通过 lua_shared_dict my_cache 128m; 定义的缓存中获取数据
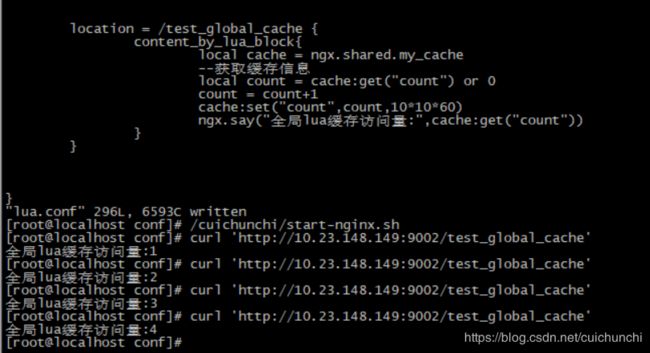
推荐使用定义全局lua缓存,方便