R 教程:如何将数据导入 R 中
经出版者许可,本文摘自“大众传播与新闻实践R”。 ©2019 Taylor&Francis Group,LLC版权所有。
在分析和可视化数据之前,您必须将数据放入R中。有多种方法可以执行此操作,具体取决于数据的格式设置方式和位置。
通常,用于导入数据的功能取决于数据的文件格式。 例如,在基本R中,您可以使用read.csv()导入CSV文件。 哈德利·威克汉姆(Hadley Wickham)创建了一个名为readxl的软件包,正如您所期望的那样,它具有读取Excel文件的功能。 还有另一个软件包googlesheets,用于从Google电子表格中提取数据。
但是,如果您不想记住所有这些,那就有力拓。
里约魔术
该项目的GitHub页面说: “ rio的目的是通过以瑞士军刀风格实现三个简单的功能,使R中的数据文件I / O [导入/输出]尽可能简单。” 这些函数是import() , export()和convert() 。
因此,rio包只有一种功能可以读取许多不同类型的文件: import() 。 如果import("myfile.csv") ,它将知道使用函数来读取CSV文件。 import("myspreadsheet.xlsx")工作方式相同。 实际上,rio处理的格式有两种以上,包括制表符分隔的数据(扩展名为.tsv),JSON,Stata和固定宽度的格式数据(.fwf)。
本教程所需的软件包
- 里约
- htmltab
- 读xl
- googlesheets
- 吃豆人
- 看门人
- rmiscutils(pm GitHub)或阅读器
- 小声
分析数据后,如果要将结果另存为CSV,Excel电子表格或其他格式,则rio的export()函数可以处理该结果。
如果您的系统上还没有rio软件包,请立即使用install.packages("rio") 。
我已经用波士顿冬季降雪数据建立了一些样本数据。 您可以转到http://bit.ly/BostonSnowfallCSV,然后右键单击以在当前R项目工作目录中将文件另存为BostonWinterSnowfalls.csv。 但是,脚本编写的目的之一是用易于复制的自动化代替繁琐的或其他的手工工作。 除了单击下载外,您还可以将R的download.file函数与语法download.file("url", "destinationFileName.csv") :
download.file("http://bit.ly/BostonSnowfallCSV",
"BostonWinterSnowfalls.csv")假设您的系统将从该Bit.ly URL快捷方式重定向并成功找到真实文件URL,即https://raw.githubusercontent.com/smach/NICAR15data/master/BostonWinterSnowfalls.csv 。 有时我在访问旧Windows PC上的Web内容时遇到问题。 如果您拥有其中之一,并且此Bit.ly链接不起作用,则可以将实际URL替换为Bit.ly链接。 另一个选择是,如果可能的话,将Windows PC升级到Windows 10,看看是否能解决问题。
如果您希望rio可以直接直接从URL导入数据,实际上可以,我将在下一节中介绍。 本节的重点是练习使用本地文件。
在本地系统上拥有测试文件后,可以使用以下代码将该数据加载到名为snowdata的R对象中:
snowdata <- rio::import("BostonWinterSnowfalls.csv")请注意,rio可能会要求您以二进制格式重新下载文件,在这种情况下,您需要运行
download.file("http://bit.ly/BostonSnowfallCSV",
"BostonWinterSnowfalls.csv", mode='wb')确保使用RStudio的选项卡完成选项。 如果输入rio::并等待,您将获得所有可用功能的列表。 键入snow然后等待,您应该可以看到对象的全名。 使用向上和向下箭头键在自动完成建议之间切换。 突出显示所需选项后,按Tab键(或Enter)将完整的对象或功能名称添加到脚本中。
您应该看到对象snowdata出现在RStudio右上方窗格的环境选项卡中。 (如果右上方的窗格显示的是“命令历史记录”而不是“环境”,请选择“环境”选项卡。)
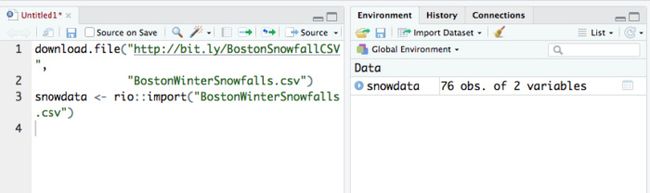
下载并导入积雪数据后的RStudio
snowdata应该表明它有76个“ obs”。即观测值或行,以及两个变量或列。 如果单击snowdata左侧的snowdata以展开列表,您将看到两个列名以及每个列所保存的数据类型。 Winter是字符串, Total列是数字。 您还应该能够在“环境”窗格中看到每列的前几个值。
 泰勒和弗朗西斯集团
泰勒和弗朗西斯集团
单击对象名称旁边的箭头,可以在RStudio的“环境”选项卡中查看有关该对象的详细信息。
在“环境”选项卡中单击单词snowdata本身,以更类似于电子表格的方式查看数据。 您可以使用命令View(snowdata)从R控制台获得相同的视图(这必须是View的大写V, view将不起作用)。 注意: snowdata不在引号中,因为您要引用环境中的R对象的名称。 在rio::import命令之前, BostonWinterSnowfalls.csv 是在引号,因为这不是R对象; 它是R之外的文件的字符串名称。
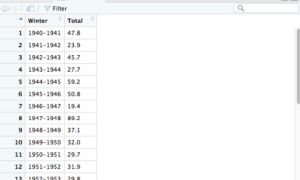
RStudio中数据框的类似于电子表格的视图
该视图具有一些类似于电子表格的行为。 单击列标题,使其按升序按该列的值排序; 再次单击同一列标题,以降序排列。 有一个搜索框来查找与某些字符匹配的行。
如果单击“过滤器”图标,则会为每一列获得一个过滤器。 Winter字符列按预期工作,对包含键入字符的任何行进行过滤。但是,如果单击“ Total值”列的过滤器,则RStudio的较旧版本将显示一个滑块,而较新的RStudio将显示一个直方图和一个框。用于过滤。
从网络导入文件
如果您想从网络上下载和导入文件,只要该文件是公开可用的,并且格式为Excel或CSV即可。 尝试
snowdata <- rio::import("http://bit.ly/BostonSnowfallCSV",
format ="csv")即使您首先向您显示错误消息,只要您将格式指定为"csv"因为此处的文件名不包含.csv许多系统仍可以遵循重定向URL到文件。 如果您的服务器不起作用,请改用URL https://raw.githubusercontent.com/smach/R4JournalismBook/master/data/BostonSnowfall.csv 。
rio还可以从网页导入格式正确的HTML表格,但是表格必须格式非常正确 。 假设您要下载表格,该表格描述了国家气象局对暴风雪的严重等级。 美国国家环境信息中心的“区域降雪指数”页面只有一张表格,精心制作,因此这样的代码应该可以工作:
rsi_description <- rio::import(
"https://www.ncdc.noaa.gov/snow-and-ice/rsi/",
format="html")再次注意,您需要包括格式,在这种情况下为format="html" 。 因为URL本身不提供有关文件类型的任何指示。 如果URL包含扩展名为.html的文件名,rio就会知道。
但是,在现实生活中,Web数据很少以这种整洁,孤立的形式出现。 对于不太精心设计的情况,一个很好的选择通常是htmltab包。 使用install.packages("htmltab")安装它。 该程序包用于读取HTML表的功能也称为htmltab。 但是,如果运行此命令:
library(htmltab)
citytable <- htmltab("https://en.wikipedia.org/wiki/List_of_United_States_cities_by_population")
str(citytable)您会发现您没有正确的表,因为数据框包含一个对象。 因为我没有指定哪个表,所以它提取了页面上的第一个HTML表。 那不是我想要的那个。 在找到正确的表之前,我不希望导入页面上的每个表,但是幸运的是,我有一个名为Table Capture的Chrome扩展程序,可让我查看页面上的表列表。
我上次检查时,具有300行以上的表5是我想要的表。 如果这现在对您不起作用,请尝试在Chrome浏览器上安装Table Capture ,以检查要下载的表。
我将再次尝试,指定表5,然后查看新的citytable中的列名称。 请注意,在以下代码中,我将citytable <- htmltab()命令放在多行上。 这样一来,它就不会超出利润范围,您可以将所有内容保持在一条直线上。 如果表编号自发布以来已更改,请用正确的编号替换which = 5 。
您可以使用我创建的文件副本的URL替换Wikipedia URL,而不是使用Wikipedia上的页面。 该文件位于http://bit.ly/WikiCityList 。 要使用该版本, bit.ly/WikiCityList在浏览器中键入bit.ly/WikiCityList ,然后复制重定向到的冗长网址,并使用该网址代替下面代码中的Wikipedia URL:
library(htmltab)
citytable <- htmltab("https://en.wikipedia.org/wiki/List_of_United_States_cities_by_population",
which = 5)
colnames(citytable)我怎么知道指定表号需要使用which参数? 我使用?htmltab命令阅读了htmltab帮助文件。 这包括所有可用的参数。 我扫描的可能性,和“ which文档中的表格的识别长度为1的矢量”看着右。
还要注意,我使用colnames(citytable)而不是names(citytable)来查看列名。 两者都会起作用。 基数R还具有rownames()函数。
无论如何,这些表的结果要好得多,尽管从运行str(citytable)可以看到,应该以数字形式输入的几列是字符串。 您可以在列名旁边的chr看到它,也可以在值8,550,405周围用引号引起8,550,405 。
这是R的小烦恼之一:R通常不理解8,550是一个数字。 我自己解决了这个问题,方法是在我自己的rmiscutils程序包中编写自己的函数,以将所有实际上是用逗号分隔的“字符串”都转换为数字。 任何人都可以从GitHub下载该软件包并使用它。
从GitHub安装软件包的最流行的方法是使用名为devtools的软件包。 devtools是一个功能非常强大的软件包,主要是为想要编写自己的软件包的人们设计的,它包括几种从CRAN以外的其他位置安装软件包的方法。 但是,与典型的软件包相比,devtools通常需要执行几个额外的步骤才能安装,并且我想把烦人的系统管理员任务留在绝对必要之前。
但是,pacman软件包还会从非CRAN来源(如GitHub)安装软件包。 如果尚未安装,请使用install.packages("pacman").安装pacman install.packages("pacman").
pacman的p_install_gh("username/packagerepo")函数从GitHub存储库安装。
p_load_gh("username/packagerepo")如果系统上已经存在某个软件包,则将其加载到内存中;如果该软件包在本地不存在,则首先安装,然后从GitHub加载该软件包。
我的rmisc实用程序包可以在smach/rmiscutils找到。 运行pacman::p_load_gh("smach/rmiscutils")安装我的rmiscutils软件包。
注意:用于从GitHub安装软件包的替代软件包称为remotes,您可以通过install.packages("remotes") 。 它的主要目的是从GitHub等远程存储库安装软件包。 您可以使用help(package="remotes")查看帮助文件。
而且,可能最精巧的是一个名为githubinstall的软件包。 它旨在猜测软件包所在的存储库。 通过install.packages("githubinstall")安装它; 然后您可以使用githubinstall::gh_install_packages("rmiscutils")安装我的rmiscutils软件包。 系统会询问您是否要在smach/rmisutils安装软件包(您这样做)。
现在,您已经安装了函数集合,可以使用number_with_commas()函数将应为数字的字符串改回数字。 我强烈建议您在数据框中添加新列,而不要修改现有列,无论您使用哪种平台,这都是一种很好的数据分析实践。
在此示例中,我将调用新列PopEst2017 。 (如果此后已更新表,请使用适当的列名。)
library(rmiscutils)
citytable$PopEst2017 <- number_with_commas(citytable$`2017 estimate`)顺便说一句,我的rmiscutils软件包不是处理带有逗号的导入数字的唯一方法。 创建了rmiscutils程序包及其number_with_commas()函数之后,tidyverse读取程序包就诞生了。 readr还包括一个将字符串转换为数字的函数parse_number() 。
安装阅读器后,您可以使用阅读器从2017年估算列生成数字:
citytable$PopEst2017 <- readr::parse_number(citytable$`2017 estimate`)readr::parse_number()优点之一是您可以定义自己的locale()来控制诸如编码和小数点之类的内容,这可能是非美国读者所感兴趣的。 运行?parse_numbe r以获取更多信息。
注意:如果您未在2017年估算值列中使用制表符补全,则在运行此代码时,如果该列名中有空格,则可能会遇到问题。 在上面的代码中,请注意,列名周围有向后的单引号( ` )。 这是因为现有名称中有一个空格,您不应该在R中使用该空格。该列名称还有另一个问题:它以数字开头,通常也可以是R no-no。 RStudio知道这一点,并使用制表符自动完成功能自动在名称周围添加所需的反引号。
温馨提示:有一个名为janitor的R包(当然有!)可以自动修复从非R友好数据源导入的麻烦列名。 使用install.packages("janitor") 。 然后,您可以使用管理员的clean_names()函数创建新的干净列名称。
现在,我将创建一个全新的数据框,而不是更改原始数据框上的列名,然后对原始数据运行janitor的clean_names()。 然后,使用names()检查数据框的列名称:
citytable_cleaned <- janitor::clean_names(citytable)
names(citytable_cleaned)您会看到空格已更改为下划线,下划线在R变量名称中是合法的(句点也是如此)。 并且,所有以数字开头的列名现在都以x开头。
如果不想通过拥有两个基本相同的数据副本来浪费内存,则可以使用rm()函数: rm(citytable)从工作会话中删除R对象。
从包中导入数据
有几种软件包可让您直接从R中访问数据。一个是quantmod,它允许您将一些美国政府和财务数据直接提取到R中。
另一个是在CRAN上恰当命名的weatherdata软件包 。 它可以从Weather Underground API中提取数据,该API具有世界各地许多国家的信息。
ropenSci集团的一个项目rnoaa软件包利用了美国国家海洋和大气管理局的几个不同数据集,包括每日气候,浮标和风暴信息。
如果您对美国或加拿大的州或地方政府数据感兴趣,则可能需要查看RSocrata,以查看对您感兴趣的代理商是否在此发布数据。 我尚未找到所有可用的Socrata数据集的完整列表,但是在https://www.opendatanetwork.com上有一个搜索页面。 不过请注意:有社区上传的数据集以及官方政府数据,因此请在依赖数据集进行R实践之前,先检查数据集的所有者并上传源。 结果中的“ ODN数据集”意味着它是一个由一般公众上传的文件。 官方的政府数据集通常位于https://data.CityOrStateName.gov和https://data.CityOrStateName.us类的URL上。
有关更多数据导入包,请参见http://bit.ly/RDataPkgs上的可搜索图表。 如果您使用美国政府数据,则您可能会对普查和提纯普查特别感兴趣,这两种方法都可以利用美国人口普查局的数据。 其他有用的政府数据包包括来自美国和欧盟政府的eu.us.opendata,以便更轻松地比较两个地区的数据以及加拿大人口普查数据的人口普查。
当数据格式不理想时
在所有这些示例数据案例中,数据不仅格式合理,而且非常理想:一旦找到它,它就完全适合R。这是什么意思? 它是矩形的,每个单元格具有单个值,而不是合并的单元格。 第一行具有列标题,而不是跨多个单元格以大字体显示的标题行,以便看起来很漂亮,或者根本没有列标题。
不幸的是,处理不整洁的数据会变得非常复杂。 但是,有一些常见的问题很容易解决。
不属于数据的开始行。 如果您知道Excel Spreadsheeet的前几行没有所需的数据,则可以告诉rio跳过一行或多行。 语法为rio::import("mySpreadsheet.xlsx", skip=3)以排除前三行。 skip需要一个整数。
电子表格中没有列名。 默认导入假定工作表的第一行是列名。 如果您的数据没有标题,则数据的第一行可能会以列标题结尾。 为了避免这种情况,请使用rio::import("mySpreadsheet.xlsx", col_names = FALSE)以便R将生成默认的标头X0,X1,X2,依此类推。 或者,使用rio::import("mySpreadsheet.xlsx", col_names = c("City", "State", "Population"))这样的语法来设置自己的列名。
如果电子表格中有多个选项卡,则which参数将覆盖第一个工作表中的默认读数。 rio::import("mySpreadsheet.xlsx", which = 2)读取第二个工作表。
什么是数据框? 那你能做什么?
rio导入电子表格或CSV文件作为R 数据框 。 您如何知道是否有数据框? 在snowdata的情况下, class(snowdata)返回其所属对象的类或类型。 str(snowdata)还会告诉您该类并添加更多信息。 您在str()看到的许多信息与在RStudio环境窗格中的示例所看到的信息相似: snowdata具有76个观察值(行)和两个变量(列)。
数据框有点像电子表格,因为它们具有列和行。 但是,数据帧更加结构化。 数据帧中的每个列都是R 向量 ,这意味着列中的每个项目都必须具有相同的数据类型 。 一列可以是所有数字,另一列可以是所有字符串,但是在一列中,数据必须一致。
如果您有一个数据框列,其值分别为5、7、4和“值即将出现”,那么R不仅会感到不满意,还会给您带来错误。 相反,它将强制您的所有值成为同一数据类型。 因为无法将“即将产生的值”转换为数字,所以5、7和4最终将转换为字符串"5" , "7"和"4" 。 通常这不是您想要的,因此了解每一列中的数据类型非常重要。 一千个数字列中的一个杂散字符串值可以将整个内容转换为字符。 如果您想要数字,请确保有数字!
R确实有一种方法可以引用丢失的数据,而这些数据不会破坏其余的列: NA表示“不可用”。
数据框是矩形的:每行必须具有相同数量的条目(尽管有些条目可以为空白),每列必须具有相同数量的条目。
Excel电子表格列通常以字母表示:列A,列B等。您可以使用语法dataFrameName$columnName来引用具有名称的数据框列。 因此,如果键入snowdata$Total并按Enter,您将在“ Total列中看到所有值,如下图所示。 (这就是为什么在运行str(snowdata)命令时,每列名称前都有一个美元符号。)
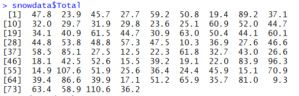
snowdata数据框中的“ Total列。
提醒您,列表左侧的括号中的数字不是数据的一部分; 他们只是在告诉您每行数据的起始位置。 [1]表示行以向量中的第一个项目开始, [10]第十个,依此类推。
RStudio选项卡补全可与数据框列名以及对象和函数名一起使用。 这对于确保您不会拼写错误的列名并破坏脚本非常有用,并且如果您的列名很长,也可以节省输入内容。
snowdata$并等待,然后您将看到snowdata中所有列名称的列表。
在数据框中添加一列很容易。 当前,“ Total列显示以英寸为单位的冬季降雪量。 要添加以米为单位显示总计的列,可以使用以下格式:
snowdata$Meters <- snowdata$Total * 0.0254新列的名称在左侧,右侧有一个公式。 在Excel中,您可能使用了=A2 * 0.0254 ,然后将公式向下复制到该列中。 使用脚本,您不必担心是否已将公式正确应用于列中的所有值。
现在,在“环境”选项卡中查看您的snowdata对象。 它应该有第三个变量, Meters 。
由于snowdata是数据帧,因此它具有某些数据帧属性,您可以从命令行访问它们。 nrow(snowdata)给你的行数和数量ncol(snowdata)列数。 是的,您可以在RStudio环境中查看它,以查看有多少观察值和变量,但是有时您可能想将其作为脚本的一部分来了解。 colnames(snowdata)或names(snowdata)为您提供snowdata列的名称。 rownames(snowdata)为您提供任何行名(如果未设置任何行名,则默认为行号的字符串,例如"1", "2", "3",等)。
其中一些特殊的数据框功能(也称为方法 )不仅为您提供信息,还使您可以更改数据框的特征。 因此, names(snowdata)告诉您数据框中的列名称,但是
names(snowdata) <- c("Winter", "SnowInches", "SnowMeters")更改数据框中的列名。
您可能不需要了解数据框对象的所有可用方法,但是如果您好奇,可以使用methods(class=class(snowdata))显示它们。 要查找有关任何方法的更多信息,请运行带有问号的常规帮助查询,例如?merge或?subset 。
当数字不是真的数字时
邮政编码是“数字”的一个很好的例子,实际上不应这样对待。 尽管从技术上讲是数字的,但是进行诸如将两个邮政编码加在一起或在一个社区中取平均邮政编码的事情是没有意义的。 如果导入邮政编码列,R可能会将其转换为数字列。 如果您要处理的是新英格兰地区,邮政编码以0开头的区域,则0将会消失。
我从马萨诸塞州政府机构( https://raw.githubusercontent.com/smach/R4JournalismBook/master/data/bostonzips.txt)上下载了按区域划分的波士顿邮政编码标签文件,该文件是从附近的麻省政府机构下载的。 如果尝试使用zips <- rio::import("bostonzips.txt") zip zips <- rio::import("bostonzips.txt") ,则邮政编码将输入为2118、2119等,而不是02118、02119,依此类推。
在这里可以帮助您了解rio的import()函数使用的基础函数。 您可以通过阅读?import的import帮助文件找到那些基础功能。 为了拉入制表符分隔的文件, import使用data.table包中的fread()或基R的read.table()函数。 ?read.table帮助说,您可以使用colClasses参数指定列类。
在当前项目目录中创建一个数据子目录,然后使用以下命令下载bostonzips.txt文件:
download.file("https://raw.githubusercontent.com/smach/R4JournalismBook/master/data/bostonzips.txt", "data/bostonzips.txt")如果您导入此文件并将两列都指定为字符串,则邮政编码将采用正确的格式:
zips <- rio::import("data/bostonzips.txt", colClasses =
c("character”", "character"))
str(zips)请注意,必须使用c()函数c("character", "character")设置列类。 如果尝试使用colClasses ="character", "character" ,则会收到错误消息。 对于R初学者来说,这是一个典型的错误,但是很快就可以养成c()习惯。
一个自己动手的提示:写出c("character", "character")并不那么费劲; 但是,如果您有一个包含16列的电子表格,其中前14列必须是字符串,那么这会很烦人。 R的rep()函数可以提供帮助。 正如您可能已经猜到的那样, rep()会使用rep(myitem, numtimes)格式重复您提供的任何内容,无论您告诉了多少次。 rep("character", 2)与c("character", "character") ,因此colClasses = rep("character", 2)等同于colClasses = c("character", "character") 。 并且, colClasses = c(rep("character", 14), rep("numeric", 2))将前14列设置为字符串,将后两列设置为数字。 此处所有列类的名称都必须用引号引起来,因为名称是字符串。
我建议您在rep()稍作rep()以使您习惯这种格式,因为它也是其他R函数使用的语法。
简单的样本数据
R附带了一些内置数据集,如果您想使用新功能或其他编程技术,这些数据集很容易使用。 讲授R的人也经常使用它们,因为讲师可以确保所有学生都从完全相同格式的相同数据开始。
键入data()以查看base R中可用的内置数据集以及当前正在加载的所有已安装软件包。 base R中的data(package = .packages(all.available = TRUE))显示来自系统中已安装软件包的所有可能数据集,无论它们是否已加载到当前工作会话的内存中。
您可以通过获得函数帮助的相同方式获取有关数据集的更多信息: ?datasetname或help("datasetname") 。 mtcar和虹膜是我经常看到的那些。
如果键入mtcars ,则整个mtcars数据集都会在控制台中打印出来。 您可以使用head()函数使用head(mtcars)查看前几行。
您可以根据需要将该数据集存储在另一个变量中,格式为cardata <- mtcars 。
或者,使用数据集名称(例如data(mtcars)运行数据功能,将数据集加载到您的工作环境中。
针对记者的最有趣的带有示例数据集的软件包之一是Fivethirtyeight软件包,该软件包包含在FiveThirtyEight.com网站上发布的故事中的数据。 该软件包是由多位学者与FiveThirtyEight编辑协商后创建的; 它被设计为教学本科统计学的资源。
预先打包的数据可能有用,并且在某些情况下很有趣。 但是,在现实世界中,您可能不会使用打包得非常方便的数据。
在R中手动创建数据框
通常,您经常会处理以R开头的数据,并且是从电子表格,CSV文件,API或其他来源导入的。 但是有时您可能只想在R中直接输入少量数据,或者手动创建一个数据框。 因此,让我们快速看一下它是如何工作的。
R数据帧通过柱默认一次组装列,而不是一行 。 如果要组装城镇选举结果的快速数据框,则可以创建候选人姓名的向量,具有其党派隶属关系的第二向量,然后是其投票总数的向量:
candidates <- c("Smith", "Jones", "Write-ins", "Blanks")
party <- c("Democrat", "Republican", "", "")
votes <- c(15248, 16723, 230, 5234)请记住,不要像在Excel中那样在数字中使用逗号 。
要从这些列创建数据帧,请使用data.frame()函数和synatx data.frame(column1, column2, column3) 。
myresults <- data.frame(candidates, party, votes)用str()检查其结构:
str(myresults)
当候选者和参与方向量是字符时,候选者和参与方数据帧列已变成一类称为因子的R对象。 在这一点上有点杂草丛生,无法研究因素与角色的不同之处,只是说
- 如果您想以某种非字母顺序的方式订购商品以进行绘图和其他用途,那么因素可能会很有用,例如
Poor小于Fair小于Good小于Excellent。 - 有时因素的行为可能与您预期的有所不同。 我建议您坚持使用字符串,除非您有充分的理由特别要考虑因素。
通过添加参数stringsAsFactors = FALSE可以在创建数据帧时保持字符串的完整性:
myresults <- data.frame(candidates, party, votes,
stringsAsFactors = FALSE)
str(myresults)现在,这些值就是您所期望的。
当以这种方式创建数据帧时,我还需要警告您:如果一列短于另一列,R有时会重复来自较短列的数据- 无论您是否希望发生这种情况。
例如,假设您为候选人和政党创建了选举结果列,但仅输入了史密斯和琼斯的选票结果,而不是写入和空白的选票结果。 您可能希望数据框将其他两个条目显示为空白, 但是您会错了 。 通过创建仅包含两个数字的新投票向量,并使用该新投票向量创建另一个数据框,来进行尝试并查看:
votes <- c(15248, 16723)
myresults2 <- data.frame(candidates, party, votes)
str(myresults2)没错,R重用了前两个数字,这绝对不是您想要的。 如果使用投票向量中的三个数字而不是两个或四个来尝试此操作,则R会引发错误。 这是因为每个条目不能被回收相同的次数。
如果现在您在想,“为什么我不能创建不会自动将字符串变成因子的数据框? 如果忘记填写所有数据,为什么还要担心数据帧会重用一列数据?” 哈德利·威克姆(Hadley Wickham)也有同样的想法。 他的tibble包创建了一个R类,也称为tibble,他说这是“对数据帧的现代理解”。 他们保留了经受住时间考验的功能,并放弃了曾经很方便但现在令人沮丧的功能。”
如果这对您有吸引力,请在系统上未安装tibble软件包的情况下,然后尝试使用创建一个tibble
myresults3 <- tibble::tibble(candidates, party, votes)并且您将收到一条错误消息,即votes列的长度必须为4four或1个项目( tibble()将根据需要重复单个项目多次,但仅重复一个项目)。
如果要使用此数据创建小标题,请将“投票”列放回四个条目:
library(tibble)
votes <- c(15248, 16723, 230, 5234)
myresults3 <- tibble(candidates, party, votes)
str(myresults3)它看起来类似于数据框-实际上,它是一个数据框,但是具有某些特殊行为,例如打印方式。 还要注意,候选人列是字符串,不是因素。
如果您喜欢这种行为,请继续进行小动作。 但是,考虑到R中仍然保留着流行的常规数据帧,了解它们的默认行为仍然很重要。
汇出资料
通常,在R中对数据进行整理之后,您想要保存结果。 以下是一些我最常使用的导出数据的方法:
保存到一个CSV文件 rio::export(myObjectName, file="myFileName.csv")并与Excel文件rio::export(myObjectName, file="myFileName.xlsx") rio根据文件名的扩展名了解所需的文件格式。 还有其他几种可用格式,包括用于制表符分隔数据的.tsv ,用于JSON的.json和用于XML的.xml 。
保存到R二进制对象 ,以便在以后的会话中轻松加载回R。 有两种选择。
通用save()将一个或多个对象保存到文件中,例如save(objectName1, objectName2, file="myfilename.RData") 。 要将数据读回R,只需使用命令load("myfilename.RData") ,所有对象都以相同的名称返回,且状态与以前相同。
您还可以使用saveRDS(myobject, file="filename.rds")将单个对象保存到文件中。 合理的假设是loadRDS会读回文件,但命令是readRDS ,在这种情况下,仅存储了数据, 而不存储对象名 。 因此,您需要将数据读入一个新的对象名称,例如mydata <- readRDS("filename.rds")。
还有第三种保存R对象的方法:生成R命令来重新创建对象,而不是生成具有最终结果的对象。用于生成R文件以重新创建对象的基本R函数是dput()或dump()。但是,我发现里约热内卢::export(myobject,“mysavedfile.R”)更容易记住。
最后,还有一些保存文件的其他方法可以优化文件的可读性、速度或压缩,我在本文末尾的附加参考资料一节中提到了这些方法。
你也可以用里约热内卢:里约热内卢::export(myObjectName, format ="clipboard")将一个R对象导出到你的Windows或Mac剪贴板中。并且,您可以通过相同的方式将数据从您的剪贴板导入到R中:里约热内卢::import(file ="clipboard")。
额外的好处:里约热内卢的convert()函数允许您—您猜对了—将一种文件类型转换为另一种文件类型,而不需要手动地将数据从r中提取出来。
最后一点:RStudio允许您单击以导入文件,而完全不需要编写代码。在您熟悉从命令行导入之前,我不建议这样做,因为我认为理解导入背后的代码非常重要。但是,我承认这是一个便捷的捷径。
在RStudio右下窗格的Files选项卡中,导航到要导入的文件并单击它。您将看到一个查看文件或导入数据集的选项。选择Import Dataset查看一个预览数据的对话框,允许您修改数据的导入方式,并预览将要生成的代码。
做任何你想做的改变,然后点击导入,你的数据就会被拉入R中。
额外资源
力拓的替代品。而力拓是一个伟大的瑞士军刀的文件处理,有时可能你想要更多的控制你的数据是如何拖入或保存r .此外,有些时候我有一个具有挑战性的数据文件,力拓被呛,但另一个包可以处理它。一些其他的功能和包,你可能想要探索:
- 基本R的read.csv()和read.table()来导入文本文件(使用?read.csv和?read)。表格以取得更多资料)。如果要将字符串保留为字符串,则需要stringsAsFactors = FALSE。CSV()保存到CSV。
- 里约热内卢使用Hadley Wickham的readxl软件包来读取Excel文件。Excel的另一个替代方案是openxlsx,它可以写入Excel文件,也可以读取Excel文件。查看openxlsx包小插曲,了解有关在导出时格式化电子表格的信息。
- 威克汉姆的readr包也值得一看,作为“tidyverse”的一部分。readr包含读取CSV、制表符分隔、固定宽度、web日志和其他类型文件的函数。readr打印出它为每个列确定的数据类型——整数、字符、双精度数(非整数),等等。它创造了宠物猫。
直接从一个谷歌电子表格导入。通过验证您的谷歌帐户,googlesheets包允许您从谷歌Sheets电子表格导入数据,即使它是私有的。该软件包可在CRAN上获得;通过install.packages(“googlesheets”)安装它。在加载库(“googlesheets”)之后,阅读优秀的介绍性短文。在写这篇文章的时候,在vignette(“基本用法”,package=“googlesheets”)的R中可以找到简介vignette。
如果您没有看到它,请尝试帮助(package="googlesheets")并单击用户指南、package Vignettes和其他文档链接以获得可用的Vignettes,或者查看GitHub上的包信息,https://github.com/jennybc/googlesheets。
用rvest包和SelectorGadget浏览器扩展或JavaScript bookmarklet从Web页面中获取数据。SelectorGadget帮助您发现您想要复制的HTML页面上的数据的CSS元素;然后rvest使用R查找并保存数据。这不是一个适合初学者的技巧,但是一旦你有了一些R经验,你可能会想要回来重新学习它。我有一些说明和一段关于如何做到这一点的视频在http://bit。ly / Rscraping。RStudio也提供了一个网络研讨会。
基本R的保存和读取函数的替代方法。如果您使用的是大型数据集,那么在保存和加载文件时,速度可能会变得非常重要。数据。表包有一个快速的fread()函数,但是要注意结果对象是数据。表而不是普通的数据帧;有些行为是不同的。如果希望使用传统的数据框架,可以使用as.data.frame(mydatatable)语法。数据.table package的fwrite()函数旨在以比基本R的write.csv()快得多的速度写入CSV文件。
另外两个包可能用于存储和检索数据。feather包以二进制格式保存,可以读到R或Python中。而且,fst包的read.fst()和write.fst()提供了R数据帧对象的快速保存和加载——以及文件压缩选项。
From: https://www.infoworld.com/article/3313111/r-tutorial-how-to-import-data-into-r.html