---------------------------------------------------------------------------------------------------
1.网络存储主要技术
2.主要协议和相关技术
3.文件系统
4.RAID技术
5.数据复制与容灾
6.备份技术
7.windows相关
8.linux相关
9.存储网络知识
10.存储I/O
11.云存储
12.其他存储
13.资料
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
6. 备份技术
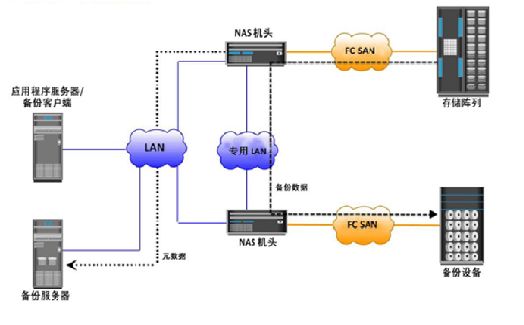
6.1 NAS环境中的备份
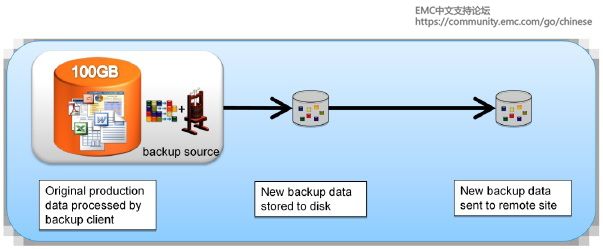
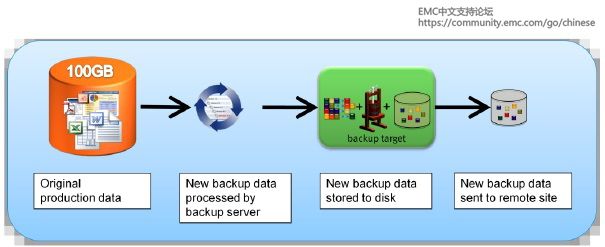
备份是容灾的基础,是指为防止系统出现操作失误或系统故障导致数据丢失,而将全部或部分数据集合从应用主机的硬盘或阵列复制到其它的存储介质的过程。公司还可以利用备份来遵循法规要求。执行备份的目的有三个:灾难恢复、操作恢复和归档。数据备份做为数据高可用的最后一道防线,其重要性不言而喻。本文将介绍NAS环境中的几种常见备份方式。
NAS 是一种采用直接与网络介质相连的特殊设备实现数据存储的机制。由于这些设备都分配有IP 地址,所以客户机通过充当数据网关的服务器可以对其进行存取访问,甚至在某些情况下,不需要任何中间介质客户机也可以直接访问这些设备。该技术能够满足那些希望降低存储成本但又无法承受SAN昂贵价格的中小企业的需求,具有相当好的性能价格比。
NAS机头是做为NAS环境中的备份和恢复应用的核心组件。NAS机头使用支持多种文件共享协议的专用操作系统和文件系统结构。在NAS环境中,可以通过不同方式实施备份:基于服务器的备份、无需服务器的备份或使用网络数据管理协议(NDMP)的备份。通常实施的备份是NDMP2路备份和NDMP3路备份。
基于服务器的备份
在基于应用程序服务器的备份中,NAS机头会通过网络检索存储整列中的数据,并将其传输到应用程序服务器上运行的备份客户端。备份客户端会将该数据发送到存储节点,存储节点继而将该数据写入备份设备。这会导致网络备份数据超载,以及使用应用程序服务器资源来移动备份数据。

无需服务器的备份
在无需服务器的备份中,网络共享直接装载在存储节点上。在此情况下,存储节点(也是备份客户端)会从NAS机头读取数据,并将其写入备份设备,而不会涉及应用程序服务器。如此可避免网络超载,也不需要使用应用程序服务器上的资源。

使用网络数据管理协议(NDMP)的备份
NDMP 是基于TCP/IP的行业标准协议,专为NAS环境中的备份而设计。数据可以通过NDMP备份,不受操作系统或平台限制。由于这种灵活性,它不再需要通过应用程序服务器传输数据,从而减少了应用程序服务器上的负载,并提高了备份速度。在NDMP中,备份数据直接从NAS机头发送到备份设备,而元数据将发送到备份服务器。在NDMP2路方法中,数据移动发生在NAS和本地连接的备份设备之间。在网络上只传输元数据。由于备份设备专用于NAS设备,因此这种方法不支持对该环境中所有备份设备进行集中管理。

需要在NAS机头间共享备份设备时,可以使用NDMP3路备份。采用此方式时,NAS机头可控制备份设备并与其他NAS机头共享该设备。在NDMP3路方法中,必须在所有NAS机头之间建立单独的专用备份网络并将NAS机头连接到备份设备。原数据和NDMP控制数据仍然通过公用网络进行传输。
6.2 备份系统技术设计
重复数据删除技术的选择:
备份的时候进行重复数据的删除的好处是显而易见的,也已成为目前业界的主流技术。这类技术目前的发展方向,最常见的方式,以除重操作发生的位置来划分:
1.在数据源端(基于主机)备份,备份之前就做除重了,然后再备份。这种方式能避免更多重复数据为了消重而通过网络传输到备份服务器,减轻了网络压力,但是缺点是会占用备份客户机的时间和资源来做消重。
2.在备份服务器端来做除重,在线处理(Inline或联机处理),Data Domain就是这一技术的代表,这一方式中,数据在读进来之后,在存到磁盘之前就已经进行了重复数据删除,也就是一边备份,一边除重。In-line的优势是节省了磁盘空间,同时重复数据删除一步到位,特别简单,但缺点是对CPU的损耗非常大,会占用大量CPU资源,导致性能下降。
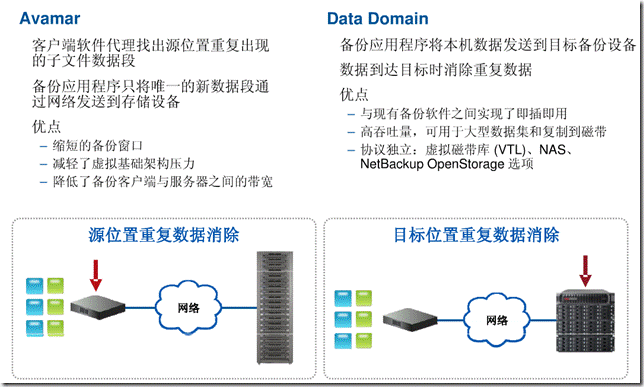
所以我们在选择使用哪种重复数据删除技术的时候应该先弄清楚,自己的重复数据在哪里发生的最多,再决定是不是在那个位置来进行重复数据删除。假如是在一个企业内部,发件人给所有员工发了一封带附件的邮件,这些数据都是存储在主机上,这种情况下可以采用基于主机的重复数据删除。
Avamar软件和Data Domain重复数据删除存储系统是目前EMC重复数据删除解决方案的核心。在EMC的重复数据删除技术蓝图中,Avamar和Data Domain被赋予不同的工作目标,Avamar更侧重于源端,更偏向在VMware虚拟化环境、备份服务器、在线复制等应用领域,其最新的进展是EMC将Avamar推进到了桌面和移动办公领域;Data Domain的工作则更多的侧重在目标端,即业务系统后端所连接的存储、备份和归档、容灾设备。
可扩展性的选择:
企业级的备份系统的架构应当是及其灵活的和可延展的,这样才是对分布式企业环境来说的理想的解决方案。公司的备份策略要从一个中心区域到遍及所有机构,都能够得到技术实现、贯彻执行和集中管理。备份系统要支持本地区域网络和广泛区域网络的连接。

在系统实施以后,数据在不同的物理站点之间的传递流转产生的网络压力要尽可能地减少。无论本地还是远程的主机上的数据都集中备份到中心区域的服务器上。作为一个集中化的备份系统,它不需要在分支机构的站点部署任何的硬件或者驻留任何的备份管理员就能对这些分支机构的数据提供保护。
对一个拥有众多分支机构的大型企业来说,我们在一个集中化的备份系统里就能够备份所有分支机构的数据并自动复制备份数据到中心站点和专门的灾备站点。此外,我们还能把存储在中心备份服务器上的管理数据和用户数据都复制到一个远程的灾备站点。所有的备份、恢复和复制的活动都在中央数据中心使用亲和的图形化界面的工具统一管理。
灾备技术的选择:
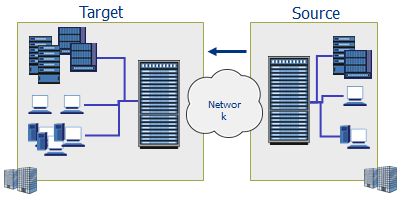
最常见的灾备技术就是异地复制,就是把本地备份系统上的数据通过广域网复制到远程的备份系统上。为了减少网络流量和节约时间,我们应当只把经过重复数据消除技术处理过的备份数据复制到灾备系统上。
理解与复制技术有关的所有硬件和软件,对于设计一套备份和恢复系统是非常重要的。作为设计者,需要考虑到的方方面面包括:
1.一套受支持的存储阵列,例如:EMC Symmetrix 或者CLARiiON,或者其他具备合适级别的固件和API的存储阵列
2.一套受支持的快照软件解决方案,例如:MS VSS,EMC TimeFinder或者SnapView
3.一套受支持的操作系统并安装了备份软件的服务器版,客户机版和任何需要的备份代理程序,例如:EMC Networker,Samentac NetBackup
4.一系列经过授权的备份软件的应用模块,适用于普通电脑终端的备份、数据库的备份、大数据量文件系统的备份,例如:Networker server/client,Networker SnapImage, Networker Module for Oracle
5.一套受支持的物理卷(介质)管理工具,例如:EMC Unisphere
6.一套受支持的备份源端到目标端的数据传递的多路径解决方案,例如:EMC PowerPath
7.一个设计合理的整体基础架构,例如:基于共享存储的SAN,基于主机自用磁盘的LAN
许多用户都会在设计和实施复制方案的时候面对这样一个简单的问题:要不要使用备份软件来管理基于磁盘存储的复制?
实现备份和复制不仅仅要考虑清楚硬件和软件,还要分清业务需求和要求。考量一个复制方案是否经得起推敲,可以从以下方面入手:
1.对于商务应用和业务数据来说,怎样的恢复时间目标(RTO)和恢复时间点目标(RPO)是可以接受的?
2.备份数据和复制数据要分别安排在怎样的时间窗口内才是合理的?
3.谁来执行数据恢复?恢复工具易于操作吗?恢复流程明确周详吗?
4.目前备份系统用到了哪些硬件技术和软件技术?
5.可用于改善备份系统的财务预算和实施周期是怎样定义的?
那么,那种备份解决方案最好呢?这个问题的答案必须基于用户对上述问题的考虑以及最终确定的各个细节。业务系统的类型和使用环境的可用性极大程度地触发了一个又一个实施方案的选择。
镜像和克隆典型地被用在含有重要数据的环境中,尤其是在短时间内会发生大量数据改变的情况,但是他们的使用成本和维护成本会高于仅使用快照技术的备份系统。
在Microsoft Windows的环境中,推荐使用VSS快照技术完成备份作业。
对于含有大数据量的文件系统,推荐使用Server less和NDMP技术。
实现基于任意时间点的恢复能最大限度地达到RTO和RPO,EMC Recoverpoint能提供这方面的解决方案。
虚拟机备份技术的选择:
不同的数据中心环境适用不同的方案。主流的实现方式包括:
Guest-based:基于客户机的方式。这种方式的配置和备份物理机的配置如出一辙,没有任何额外的步骤。在此不表。
vStorage APIs:基于代理服务器的方式。这是目前最高效的方式。

这样的数据保护就能支持LAN-free的备份,并且把所有备份相关的资源开销都集中到一个代理服务器上。备份的时候,系统会创建一个虚拟机的vmdk文件的快照,这个vStorage APIs的代理服务器能够挂载这个快照,并通过备份软件直接备份这个快照,这样的备份就是镜像级别的了。当然为了让备份服务器能识别和管理这个代理服务器,我们需要在他上面安装备份软件的代理程序,由这个代理程序提供备份服务,所有的备份操作都在这个代理服务器上完成。一个代理服务器能为多个ESX主机上的虚拟机提供备份服务。
考虑到效率,我们建议把这些虚拟机都部署在共享存储环境中,例如:SAN,便于代理服务器读写。笔者的经验是,如果把这个代理服务器也存放在同一套共享存储中,备份的效率会更高。
设计一个完整的备份架构:
就以下图作为模拟,整理下构建备份系统的思路。

首先,横向来看,既要有在线备份,也要有离线备份。数据从左至右依次经过客户端、备份服务器、一级存储介质、二级存储介质。在备份系统中,我们要规划好各层之间的网络连接,部署成本和管理平台。如果需要异地长期保存数据的,还要考虑如何转移磁带,如何存放和管理便于恢复的时候支取。对于多级存储介质,磁盘阵列和磁带库,最好能通过统一存储工具进行管理,而且容量、性能和高可用性是最主要的三个方面,需要在成本允许的范围内取得平衡。事先和应用部门就这些方面做一次modeling来明确这些方面的细节。
然后,纵向来看,既要有磁带备份,也要有磁盘备份。至于两者之间的比较,就不再本文赘述了。感兴趣的读者,请自行查找其他资料。值得一提的是,在现在介质成本不断下降的大环境下,磁盘的优势非常明显,建议有条件优先考虑,选择知名厂商的成熟存储阵列产品。
最后,我们推荐结合EMC的三大备份产品搭建这个环境。
利用Avamar和Networker内嵌的DD Boost向Data Domain目标备份Exchange、Oracle、SharePoint、SQL Server和VMware镜像。Avamar自有的Data Store有效容量翻番达到124TB。与之相比,Data Domain目标系统可用容量为285TB。Networker更是能通过添加外部设备直接使用更多更大容量的一级磁盘阵列和二级磁带库。用户能够将DD Boost所支持应用的备份发送至Data Domain目标,而其他应用备份将发送至Avamar Data Store,以此最大化备份整体性能,并加速Avamar和Networker客户端。
Networker备份客户端在备份时,可以选择要除重还是不要除重。如果不要除重,把它备份到Networker后面管理的其他备份设备上,可以是一级磁盘阵列也可以是二级磁带库,甚至Data Domain都是可以的。另一个是带除重的选项,这时选中后,备份设备备份到Avamar或者Data Domain的磁盘里,这个结合的好处:用同一个客户端选择要除重还是不要除重,并且整个备份策略是由Networker统一管理的,也就是说这个数据用了除重或非除重的备份方式,备份的数据存在什么样的备份设备上,还有备份策略、备份周期,是什么样的都是由Networker来管理的,所以有一些客户已经把Avamar,Networker和Data Domain结合起来一起使用了。
备份系统“软”技术的选择:

所谓的“软”技术,包括这些内容:
1.根据业务的需求,我们要制定怎样的备份策略才能在充分利用上述所有系统配置和环境资源来实现日常的备份任务?
2.哪些技术和非技术人员会参与备份系统的日常维护和管理,他们的身份验证和系统权限作出了怎样的定义?
3.当需要进行数据恢复的时候,流程足够清晰吗?恢复数据直接可用吗?
6.3 重复数据删除的实现
重复数据删除指的是备份时找到并消除重复的数据,以提高备份的效率。本文将介绍重复数据删除的级别和种类,让大家了解重复数据删除是如何实现的,以及重复数据删除能够给我们带来些什么好处。
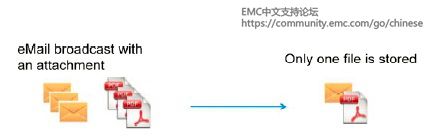
先来看一个考小朋友的问题:“以下一共有几种水果?“

小朋友最后从一大堆水果中挑出不一样的12种来。这就是最简单的重复数据删除。重复数据删除看似简单,其实在实际生产环境中的实现还挺复杂的。不同重复数据删除的产品最终所能达到的数据消重率和完成的时间效率大相径庭。今天就让我们来看一看实际生产环境中是如何实现重复数据删除的。
重复数据删除的级别:
重复数据删除通过识别重复或冗余数据来降低存储需求。重复数据删除有多种级别,每个级别所对应的文件冗余识别能力有所不同:
文件级别重复数据删除:只要文件有任何修改,整个文件就被认为是一个新的文件,因而会被存储。只有在文件没有任何修改的情况下,该文件才被认为是个冗余文件,从而无需再次存储,但是会创建一个指针从冗余文件指向备份文件,并且保留指针和元数据。需要恢复文件的时候,可以通过唯一文件以及相应的指针或元数据来实现。这种重复数据删除级别效率较低。EMC Avamar包含文件级别重复数据删除功能。
固定长度数据块重复数据删除:常用于快照与复制技术,文件被分割成固定长度的数据块,能够更高效的识别数据的冗余性。但是,因为数据块是固定长度的,所以即使修改文件的一小部分,也有可能导致所有数据块都被修改。例如,如图所示,假如需要添加一个数据块到已有的数据块中,整个数据流都要往后挪以便腾出地方。这种重复数据删除级别效率也不是很高。

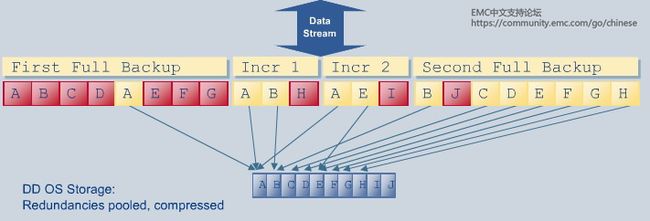
可变长度数据段重复数据删除:在固定长度数据块重复数据删除基础上加以改进,使用一种智能化的方法来确定数据块的大小,着眼于数据本身来确定数据块的分界点。可变长度数据块重复数据删除提供更佳的粒度识别重复数据,消除了文件级别和固定长度数据块重复数据删除的低效率。使用可变长度数据块重复数据删除,当添加数据时,数据可被加入可变长度数据块中,整个数据流无需挪动。因此,更多数据块会被定义为相同数据块,要存储的数据也随之减少。在固定长度数据块重复数据删除和可变长度数据块重复数据删除中,同样也会保留指向唯一数据段的指针和元数据。EMC Avamar和Data Domain使用的都是可变长度数据块重复数据删除。

重复数据删除的种类:
按照重复数据删除操作所执行的对象,重复数据删除可分为两种:
源端重复数据删除:在客户端既数据的源头作重复数据的识别,并将重复数据删除以后的数据通过网络传输并存储到磁盘上进行备份。EMC Avamar提供的就是这种重复数据删除方式。
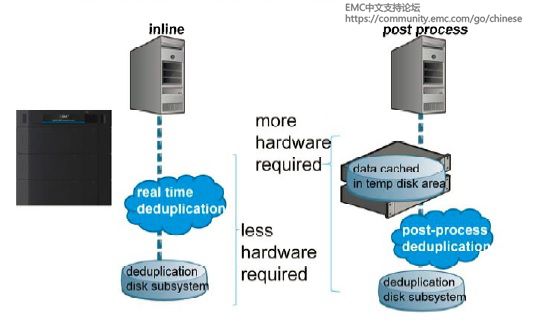
目标端重复数据删除:将数据从客户端发送到目标存储设备上,然后在目标存储设备上进行重复数据删除。此时,不同厂商所提供的目标端重复数据删除产品的差距就体现出来了。很多其他厂商的目标端重复数据删除产品需要将数据先存到磁盘上的一个临时区域,然后再进行重复数据删除,而且无法对重复数据删除之后的数据进行压缩。这样不但需要有额外的磁盘,而且需要额外的人力去管理处于不同状态的数据池中的数据。EMC Data Domain使用的则是一种称为“内联”的重复数据删除方式,在将数据存储到目标存储设备之前,就对数据进行重复数据删除。99%的数据段冗余分析是在内存中完成的,只有一小部分未能在内存中识别的数据会和磁盘中已存储的数据去比较。由于重复数据删除基本是在内存中完成的,很少访问磁盘,所以重复数据删除的速度很快。如果数据块被识别为是旧的,该数据不会被再存储但是会给它创建一个指针。随后,Data Domain会将经过重复数据删除处理以后的数据进行压缩,然后存储到目标存储设备的磁盘上。
使用重复数据删除功能的好处主要有:
- 减少磁盘空间:重复数据删除之后,数据量可以减少几十倍,很大程度上降低了磁盘空间的负担。
- 提高备份速度:重复数据删除极大的减少了所需备份的数据量,缩短了备份窗口。
- 降低网络负载:对于源端重复数据删除而言,由于所要传输的数据量大为减少,网络带宽压力得到减轻。
- 加快数据恢复:由于重复数据删除以后的数据量少了很多,数据长期存于磁盘可成为现实。由于数据是在磁盘而不是磁带中,所以读取数据的数据会大大加快。
- 改进数据保护:不使用重复数据删除的情况下,很多时候因为备份时间段的限制我们也许只能进行每周完整备份和每日增量备份。使用重复数据删除以后,我们很可能将能够采取更积极的备份策略, 如每日完全备份。
应用于
Avamar,Data Domain,重复数据删除
6.4 备份和归档的区别
如今已经进入大数据的时代,每天都有无数的数据在全世界范围内产生。有些企业每年所产生的数据都在成倍增长。如何有效并可靠的保存快速增长的数据已成为很多企业的巨大挑战。备份和归档是现今企业中最流行的两种数据保护方式。本文将介绍下这两种数据保护方式各自的含义和相互间的区别
备份:
备份可以创建数据的副本(文件、数据库等),用于防止因为人为错误、系统崩溃和自然灾害造成的数据丢失。当原始数据丢失时,可以通过获取数据副本来获得想要的数据。备份适合快速恢复大量数据的场景。但是,由于数据的快速增长,备份环境可能需要不断拓展,这对于备份管理员而言是一件头疼的事情。磁带和磁盘提供高可靠性,通常被用作备份的介质。但是,如果一个备份系统没有使用合适的数据管理软件,它就会显得非常低效甚至无效。如果企业决定长期保留数据,那么对备份系统的投资花销、时间成本以及专业人员数量都会有较高的要求。总而言之,备份主要是复制那些经常需要读取或更新的在线数据。
归档:
文件归档是现今另一种数据保护的流行形势。由于归档使用相对较便宜的存储介质(如磁带),并且可以离线存储,所以归档可达到减少开支和方便存放介质的目的。文件归档系统还可以根据文件属性来保存文件。这些属性可以是作者、修改日期或者一些其他的自定义标签。归档系统会保存文件本身以及它们的元数据和属性。此外,归档系统还会提供压缩功能。总而言之,归档主要是将不再需要经常读取或更新的备份数据长期离线保存,并按属性打上归档标签,方便将来的搜索。
备份和归档的区别:
备份和归档系统的目的是不同的。它们应当一起被用来实现数据的保护。备份主要用于保存数据的副本,达到数据保护的目的;归档作为数据管理的一种方式长期组织并保存数据。换句话说,备份可以认为是短期保存副本,而归档则被认为是长期保留文件的方式。在现实生活中,你通常不会在备份之后删除原始副本。但是,一旦文件被归档了,原始文件就可以被删除了,因为我们很可能不再需要去快速获取它了。备份和归档相辅相成,配合一起使用可以更好的保护数据。
EMC Data Domain系统是一款理想的备份和归档数据的保护存储平台。各种各样的数据,如数据库、虚拟机、应用程序、邮件服务器、共享文件、内容管理等,都可以通过Data Domain进行备份和归档,从而得到有效的保护。Data Domain现在可支持16种以上不同的归档软件,包括EMC归档产品DiskXtender、SourceOne、Could Tiering Appliance和Documentum以及第三方厂商归档产品Symantec Enterprise Vault、AXS-One、DataGlobal、Arkivio等。

应用:
数据恢复,Data Domain
6.5 备份架构—三种基本备份拓扑
最常见的基本备份拓扑有三种:直连备份、基于LAN的备份和基于SAN的备份。我们来简单介绍下它们各自的概念和优缺点。
在直连备份模式中,备份数据直接从主机备份到磁带中,不经过LAN。备份任务由备份客户端发起,直接将数据备份到与客户端相连的磁带设备中。在这种模式中,我们无法进行集中管理,也很难拓展现有的环境。这种备份拓扑的主要优点是速度快,磁带设备可以最大化的发挥自己的I/O速度。由于磁带设备与数据源紧密相连并且提供给主机专用,所以备份和恢复数据的速度能够得到优化。直连备份的缺点是由于备份需要消耗主机I/O的带宽、内存和CPU资源,所以它们会影响到主机以其应用程序的性能。此外,直连备份还有距离上的限制,尤其是当使用如SCSI这类短距离连接的时候。
在下图中,客户端同时也是存储节点,承担将数据写入备份设备的责任。

在基于LAN的备份模式中,备份数据从主机通过LAN备份到磁带中。备份服务器作为控制中心控制所有的备份任务。在这种模式中,我们可以进行集中管理但是LAN的高负载率可能会是一个问题,因为所有数据都会经过LAN。这种备份拓扑的主要优点是能够集中化管理备份和磁带资源,从而提高操作的效率。缺点是备份流程可能会对生产系统、客户端网络和应用程序造成影响,因为它会消耗CPU、I/O带宽、LAN带宽和内存。
下图列出了最简单的传统基于LAN的备份拓扑。所有系统都由LAN相连并且所有存储设备都是直连的(磁带本地直连在备份服务器上)。数据备份应当找到一条从源端(备份客户端)到目标端(备份设备)的最佳路径,从而最小化对网络可能造成的影响。减少影响的方式可能有多种,比如:给不同的备份任务专门配置不同的网络以及在应用服务器上配置专用存储节点等。

在基于SAN的备份模式(LAN-Free)中,备份数据通过SAN来传输,LAN只用于传输元数据。备份元数据包含被备份的文件的信息,如文件名、备份时间、文件大小和权限、文件所有人以及用于快速定位和恢复数据的跟踪信息等。基于SAN的备份优化了备份的整个过程,包括提供光纤性能、高可靠性、长距离、无需LAN来传输备份数据、无需专用备份服务器以及高性能备份恢复等特性。这种模式可以提供更好的备份性能和更简化的管理,但是需要额外的设施建设投资开销。
如下图所示,磁带库和客户端都被连接到SAN,所有客户端都可以共享一个单独的磁带库。客户端从SAN中读取数据并将数据写入与SAN相连的磁带中。数据总在SAN环境中传输,唯一通过LAN传输的只有元数据。

应用于
备份和恢复, NetWorker
6.6 虚拟磁带库(VTL)
虚拟磁带库(VTL)是一种常用于备份和恢复目的的数据存储虚拟化技术。
目前,大多数虚拟磁带库使用SAS或SATA磁盘阵列作为主要的存储组件。阵列盘柜的使用可以提高解决方案的可拓展性。通过增加更多的磁盘驱动器和盘柜,可以增加存储容量。
对于备份软件而言,物理磁带库和虚拟磁带库没有什么不同。虚拟磁带库提供虚拟磁带库模拟功能将VTL中的物理磁盘呈现为磁带备份设备。由于虚拟磁带库看起来就好像是物理磁带库,此功能使得企业能够轻松集成虚拟磁带库到现有的备份环境中,而无需对备份软件作任何更改。
相较于物理磁带库,虚拟磁带库能够提供更好的单数据流性能、更高的可靠性和随机磁盘访问等特点。由于磁盘总是在线并保持随时可用,所以备份和恢复的效率得到了很大的提升。虚拟磁带不需要像对待物理磁带机那样进行常规维护操作,如定期清洗和驱动器校准。此外,使用虚拟磁带库并不需要在备份软件上安装额外的模块或做出特别的改变。
虚拟磁带库和物理磁带库具有相同的组件,除了虚拟磁带库中的大部分组件是以虚拟资源呈现的。虚拟磁带库使用磁盘作为备份媒介来模拟磁带的行为。模拟引擎是一个具有定制化操作系统的专门服务器,将虚拟磁带库中的物理磁盘呈现为磁带备份设备。模拟软件中包含一个含有虚拟磁带库列表的数据库,每个虚拟磁带被分配磁盘上的一部分LUN。如果需要的话,虚拟磁带可以跨多个LUN。虽然使用的是备份到磁盘技术,但是文件系统的识别不是必须的,因为虚拟磁带库可以使用裸设备。不像物理磁带库会有机械延迟,虚拟磁带库的访问几乎是瞬间完成的。

传统的虚拟磁带库面临一些挑战比如:磁盘相对较贵,长期存放数据成本较高,最后可能仍需要将数据存放到物理磁带上;数据量较大不利于跨广域网复制到远程站点实现灾难恢复等。EMC Data Domain既能够提供虚拟磁带库功能,又由于自身强大的重复数据删除机制,使得这些难题都迎刃而解。
应用于
VTL,Data Domain
6.7 面向大数据的归档解决方案
EMC Isilon大数据归档解决方案瞄准了日益增长的信息和数据保留需求。特别适合大型企业、媒体和娱乐公司以及需要处理大数据的公司。高扩展性、易于管理的特性使得它可以轻松减少您的投资,简化存储管理并遵循企业及各种合规要求。
同时为在线和归档数据服务:
通过Isilon 系列节点的集群使用,单个Isilon NAS群集可以同时被多种工作负载使用,包括目录、虚拟化文件存储和归档库,而不用担心对性能的影响以及对长期数据保存的特殊处理。除此之外它还有以下关键优势:
- 提供在线存储级性能的归档服务:对大数据归档,Isilon瞬时访问速度可以扩展到超过每秒100 GB的吞吐量。
- 自动管理和自我修复功能:单个Isilon群集可以方便地扩展至超过20 PB的容量。系统的自我管理和分配功能可以监控系统并自我修复系统内的任何故障。
- 消除数据迁移风险:当新的存储节点、更新或更有性价比(存储效率)的硬盘被加入到系统中时,可以提供自动迁移功能。它不会有磁带介质退化的问题,使得长期归档服务成为了可能。
高可用和数据保护:
Isilon OneFS操作环境通过FlexProtect技术提供横向扩展的数据保护。区别于传统的RAID技术,FlexProtect采用特定于文件的方法来实现数据保护,为每个文件单独存储保护信息。这种独立保护允许将保护数据连同文件数据一起散布在整个群集中,从而在需要时大幅提高数据访问和重建的潜在并行度。在Isilon存储系统中存在节点或驱动器故障时,FlexProtect能够确定文件的哪些部分受故障的影响,并让多个节点仅参与受影响的文件的重新构建。
Isilon SmartLock技术添加了一个安全层,保护归档数据不会因为意外、提前或恶意的变更而被删除。SmartLock企业版(Enterprise Edition)符合最严格的SEC-17a4法规,它能和Isilon OneFS操作系统完整结合并无缝地与其它的OneFS应用整合,比如SmartPools自动存储分层、SnapshotIQ和SyncIQ本地和远程数据复制和灾难恢复技术。
减少大数据归档的存储成本:
Isilon横向扩展NAS为非结构化数据提供了最有效的空间使用效率,提供显著的资本和运营支出结余。它提供开放的、标准的NAS和基于RESTful对象接口协议。为您企业内部应用选择合适的归档方案提供了便利。一旦数据从主存储归档,Isilon会使用一系列功能确保归档文件尽可能有效率地存放:
- 单文件系统和单存储卷的简化使得其存储利率用超过80%。和传统的归档系统不同,Isilon群集的存储效率、可用性和性能会在容量提升时同步提升。
- SmartPools技术提供自动化的、基于策略的分层策略。根据相关性和权值,数据会被放入高性能的存储池或高容量的存储池中。
- 简单的、横向扩展的架构可以整合文件数据,减少整个组织内文件的存放位置。从而减少管理成本和归档的操作流程。

应用于
大数据、Isilon
--------------------------------------------------------------------------------------------------------------------------------------------------------------
7. Windows 相关
7.1 磁盘分区对齐详解与配置
许多系统管理员可能不曾听过”磁盘分区对齐“之说,甚至一些有经验的存储管理员对分区对齐也不甚了解。磁盘分区不对齐现象是什么,为什么会造成比较严重的性能下降?相反,配置正确的分区起始位置(Offset)设置会使存储系统发挥更大的性能潜力。文章就磁盘分区对齐进行的介绍,并且给出了在Windows平台上如何配置的方法。
磁盘分区对齐(Disk Alignment、Partition Alignment):
Windows的磁盘有一种结构叫做Master Boot Record(MBR), 它的默认大小为63个Block(每个大小为512字节)。它的存在使得磁盘的初始位置和的磁盘上第一个分区的初始位置有63个Block的错位。如果磁盘的单个Track大于63个Block的话。这就会导致默认的初始的位置是从第64个开始。使文件系统的中的Track和位于磁盘中的两个Track之上。这种不对齐现象会导致存储系统的性能下降,原因是单个I/O请求会跨越多个磁盘上的Track,从而导致存储系统的额外性能开销。特别是对于一些随机I/O比较较大的应用程序,影响将更大。
而对于Windows 2003以后支持的GPT Disk,也会存在磁盘分区不对齐的现象,但是结构有所不同。如图1所示(图中单位为Block,512字节),所有的分区由1MB大小(2048 Block)构成,第一个分区从LBA 34开始,即17KB大小位置。这也就意味着所有的分区会有17KB的不对齐的情况发生。同样会导致I/O读写性能影响。
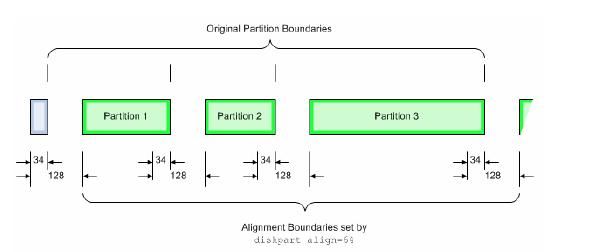
Windows磁盘分区对齐配置:
配置磁盘分区对齐后,如下图所示四个分区的例子中,对比图1中不对称的情况,图2中这些Windows的分区结束地址与图1中的地址位置一致了。

磁盘分区对齐操作,只针对Windows的Basic Disk。对于Windows 2008和Windows 2008 R2,无需对磁盘进行对齐操作,因为这个过程已经在操作系统划分分区的时候自动进行了,软件的升级还是给管理员们带来了不少便利的。对于Windows 2003和 2003 R2,以及Windows 2000,建议设置开始偏移量(starting offset)为64KB(128 block)。另外,对于Dynamic Disk类型,不能进行磁盘分区对齐操作。不过,如果原来的Basic Disk上已经进行了对齐操作的分区,会在转换后保留原来的对齐。
查看Windows磁盘分区对齐方法:
1. 查看Basic Disk的分区对齐信息:
方法1:
在Windows的命令行下输入Diskpart命令。
C:\>diskpart
选择对应的Disk
DISKPART> list disk (显示本机所有磁盘)
DISKPART> Select Disk X (x代表上面显示的从0开始的磁盘编号)
DISKPART> list partition (显示从1开始的所有的分区信息,在最右边有一个Offset/偏移量的值,如果它是8的倍数,说明你的硬盘分区是对齐的,如果不是,说明你的磁盘分区没有对齐
方法2:
使用WMIC命令,在Windows命令行下输入下列命令,命令输出的列StartingOffset为该分区的偏移量,该数值除以512则为扇区数目:
wmic partition get BlockSize, StartingOffset, Name, Index
2.查看Dynamic Disk的对齐信息:
使用dmdiag工具,下载地址;
执行从命令行执行dmdiag.exe –v
在命令行输出中,LDM Volume区域的RelSec列,该列显示的就是Dynamic Disk的起始扇区。
磁盘分区对齐配置方法:
对于Windows 2003 sp1以下版本,使用dispar命令来设置偏移量和分区对齐。步骤如下:
1. 安装在Windows Resource Kit后,在Performance Tools目录下,通过命令行运行diskpar命令:
2. 使用diskpar –s N命令,下面的例子中定义了配置一个20GB的磁盘的错位64KB的配置
对于Windows 2003 sp1以上版本,dispar命令被dispart命令所替换。
1. 在CMD命令行运行Diskpart命令
C:\>diskpar
2. 选择对应的Disk
DISKPART> Select Disk X
3. 创建分区设置偏移量为64KB(128 Block),下面的例子为创建一个1GB的分区。
DISKPART> create partition primary size=1024 align=64
最后,进行分区对齐操作的时候需要注意:对齐操作需要在磁盘上写入数据之前完成,最好在磁盘刚刚映射到主机时进行。磁盘对齐操作必然损坏磁盘上的数据,所以如果有数据需先备份,操作的时候注意数据安全。
7.2 MBR结构
Windows Basic Disk中的MBR:
Master Boot Record作为磁盘中最重要的数据结构,在磁盘分区的时候会被创建。MBR中包括几个部分,一段可执行的代码叫做Master Boot Code,Disk Signature以及磁盘的分区表。在MBR的末端还有一直为0x55AA值大小为两个字节的Sector Marker的签名字段。这个字通常还标注了extend boot record(EBR)和启动扇区(boot sector)的结束。
Master Boot Code代码主要完成下列几项活动。
- 扫描活动分区的分区表
- 找到活动分区的起始扇区位置
- 将一个启动扇区的拷贝从活动分区载入到内存
- 将控制权转移到启动扇区上的执行代码
如果Master Boot Code不能完成这些功能,Windows系统就会抛出一些错误,比如“Invalid partition table”、“Error loading operating system”、“Missing operating system”从而提示相应的步骤中发生了错误。
Basic Disk中的分区表:
在Basic Disk中的Partition Table是一个64个字节的数据结构用来定义物理磁盘上的分区类型与位置的,独立于操作系统。每个分区表的记录是16个直接长度,最大包括四条记录,每条记录从预先定义的起始位置。下面的例子显示一段MBR的记录,其中包括显示了一个三个分区记录,起始位置分别是0x01BE、0x01CE、0x01DE。图中还显示了,分区记录中几个关键的字段。0x01C2是System ID,用来定义逻辑卷的类型,图中07就是表示Installable File System(NTFS)。0x01C6开始的四个字节是Relative Sectore,表示了逻辑卷的起始位置。0x01CA开始的四个字节显示了整个逻辑卷的扇区总数。Boot Indictor显示了是否分区为活动分区。

7.3 Windows磁盘结构详解
Windows磁盘结构:
Windows的主流磁盘结构分为MBR和GPT两种。MBR是早期Windows的唯一选择,但是随着物理磁盘的容量不断增大。GPT结构成为目前的主流,最大支持超过2TB的容量,提供容错,多分区支持,比MBR来的更加强大。
MBR (Master Boot Record )磁盘结构:
在Basic MBR Disk中的MBR中包含了几种信息。
- Bootstrap Code – 也叫Master boot code,它是一段可执行的代码,主要作用是,扫描活动分区的分区表,寻找活动分区的开始扇区,加载启动扇区到内存等功能。
- Disk Signature - Windows的所有物理磁盘都有一个磁盘签名的机制,如果没有签名windows则不能访问该磁盘的数据。当Windows新扫描到一个物理磁盘,尝试写入一些磁盘签名,用来标识这个磁盘。签名的长度为8个字节。然后会写入到第一个扇区,位置为0x01B8 - 0x01BB。签名存储在注册表的HKLM\SYSTEM\MountedDevices位置。
- Partition Table – 分区表,一个64字节的数据结构用来定义每个分区的起始位置。每个分区定义去大小为16个字节。因为这个设计,所以MBR的的扩展主分区最多只能支持4个。

一个简单的Basic (MBR)的磁盘结构如下图所示,我可以看到最外层的是物理磁盘(Disk),在物理磁盘的最前端包含MBR(Master Boot Record),这个例子中,定义了一个分区和NTFS逻辑卷。
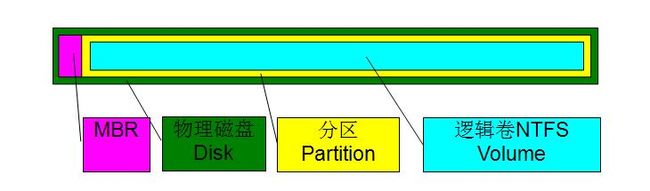
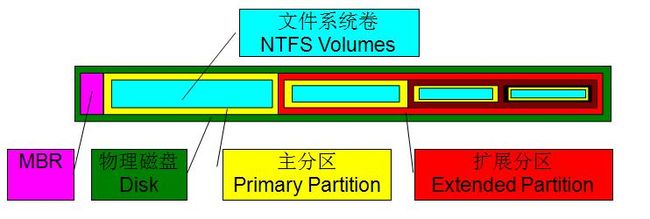
MBR Disk支持最大四个主分区(Primary Patition),如果创建多个主分区的,则结构如下。一个物理磁盘中包含四个主分区,每个主分区包含一个文件卷。

如果启用了扩展分区,则在扩展分区中可以包含多个逻辑卷。
GPT (GUID - Globally Unique Identifer)磁盘结构:
截止201年,大多数操作系统都支持GPT GPT Disk在主的MBR中包含几个内容,GPT Disk的分区表包括以下几个内容。在MBR硬盘中,分区信息直接存储于主引导记录(MBR)中(主引导记录中还存储着系统的引导程序)。但在GPT硬盘中,分区表的位置信息储存在GPT头中。但出于兼容性考虑,硬盘的第一个扇区仍然用作MBR,之后才是GPT头。
- Protective MBR - 和MBR在Partition Table中包含主分区信息不同的是,GPT Disk在磁盘的第一个扇区(Sector)为“Protective MBR”,它位于LBA0(通用的存储寻址方式大小为512每单位)这个位置上。它包含的内容为磁盘的分区信息和初始的BIO启动器。这是为了兼容性的考虑,保证一些遗留的MBR磁盘工具可以识别到GPT Disk。
- Partition Table Header – 分区表头定义了一些磁盘上可使用的块,同时还定义了组成分区表的Partition Entries数目和大小(大小通常为128个字节)。GPT支持的64位版本的Windows Server 2003以上版本,支持创建最大128个分区,每个分区记录大小为128个字节。在分区表头中还记录了磁盘的GUID,用来记录自身的大小与位置以及备用GPT表头的位置(位于磁盘的最后一个扇区)。同时还包括CRC32的校验值。
- Partition entries – GPT Disk用简单直接的条目来描述分区。最初的16个字节用来标识分区类型。第二个16直接用来记录改分区唯一的GUID。接下来三个8字节的记录分别描述的初始LBA地址,结束LBA地址和分区属性。最后72个字节为分区名。单个分区记录大小为128个字节。通常Partition entries会从LBA2地址开始。
- 最后,为了为了减少分区表损坏的风险,GPT在硬盘最后保存了一份分区表的副本。

8 Linux相关
8.1 理解I/O
通常定义的I/O(或Input/Output)是指在电脑和设备之间执行一次输入和/或输出操作的能力。输入设备可以是键盘或鼠标,基于输入设备,更新光标坐标的监视器可作为输出设备。在数据存储方面,I/O通常表示输入和输出磁盘设备的数据流(如:块设备)。
块设备是指能够处理文件系统和/或存储非易失性数据的设备(即:硬盘驱动,CD-ROM,软盘等)。在现代计算机系统里,块设备只能处理一次传输整个或多个块(或扇区)的I/O操作,通常为512字节长度(或2的指数倍)。块设备可以通过本地、网络或通过物理设备接口共享挂载的文件系统节点来访问。使用文件系统的优点是增加数据存储的组织结构特性使其可以同时被用户和操作系统(及其应用程序)访问。文件系统因众多的功能模块而日趋先进,用户能够管理冗余并在高性能环境下进行操作。没有文件系统,物理设备也只是一系列无意义的字节值。也将不会出现识别文件位置的源数据,包括文件相关信息如:文件大小、权限等。
回到I/O处理。有多种方式用于初始化存储设备的I/O处理。在操作系统的应用层和存储设备终端生成I/O的基本步骤包括:
- 打开设备或文件
- 设置读取或写入地址
- 执行读或写操作
- 重复执行步骤2和步骤3
- 关闭设备或文件
尽管这些步骤看起来较为简单,但仍需采用很多变量以定义I/O处理的行为。这些变量通常称为I/O属性。配置I/O属性的其中一部分参数包括:
- 传送大小 —— 需传送字节数或块数。
- 寻址方式 —— 顺序、随机或混合。
- 范围 —— 执行并维护I/O操作及其大小的区域。例如:磁盘设备的前100个块或创建长度小于1GB的文件。
- 进程数量 —— 产生同时运行在磁盘设备之上的I/O的进程总数。包括最大主机数及对中断存储设备进行I/O操作的进程数。
- 数据模式 —— 载入读写缓存并写入/读出磁盘设备的数据模式。
- 时序 —— I/O生成的速率包括读写操作的不同耗时差异。
以上列出了构成I/O属性的大部分参数,I/O属性也包括了主机总线适配器HBA的类型及配置,SCSI层队列深度,SCSI磁盘的超时限制,如果磁盘设备位于阵列中,用户还需考虑磁盘设备的stripe/chunk大小甚至RAID类型等其他因素。理解I/O属性的构成在研发,设计和故障定位中显得尤为重要。
当用户空间发起一个需要读出/写入磁盘设备时,需进入内核空间以恢复该进程。Linux系统I/O分为以下两类:
1.文件I/O
对于内核而言,所有打开的文件都通过文件描述符引用。文件描述符通常是一个小的非负整数,内核用它标识一个特定进程正在访问的文件。当内核打开一个已有文件或创建一个新文件时,它返回一个文件描述符。
可用的文件I/O函数——打开文件,读文件,写文件等。UNIX系统中的大多数文件I/O只需用到5个函数:open、read、write、lseek以及close。它们是不带缓冲的I/O,都使用文件描述符。在使用read和write函数时,选定不同大小的缓冲区(保存读和写的数据),效率是不同的。存在一个最佳效率的缓冲区大小,就是缓冲区大小等于文件系统的块长。
2.标准I/O
对于标准I/O库,它们的操作则是围绕流进行的。当用标准I/O库打开或创建一个文件时,使用一个流与一个文件相关联。当打开一个流时,标准I/O函数fopen返回一个指向FILE对象的指针。该对象通常是一个结构,它包含了标准I/O库为管理该流所需要的所有信息,包括:用于实际I/O的文件描述符,指向用于该缓冲区的指针、缓冲区的长度、当前在缓冲区中的字符数以及出错标志等。
预定义了三个标准I/O流,分别为三个文件指针stdin,stdout和stderr。
标准I/O库提供缓冲的目的是尽可能减少使用read和write调用的次数。它对每个I/O流自动地进行缓冲管理,从而避免了应用程序需要考虑这一点所带来的麻烦。标准I/O提供三种类型的缓冲:全缓冲、行缓冲和不带缓冲。
1)全缓冲:直到缓冲区填满,才调用系统I/O函数。
2)行缓冲:直到遇到换行符\n才调用系统I/O函数。
3)无缓冲:灭有缓冲区,数据会立即读入或者输出到外存文件和设备上。
8.2 Linux系统设备驱动
Linux版本概述:
Linux是与Unix类似的操作系统,与传统操作系统和花费较高的Unix系统相比,为个人电脑用户提供了一个免费或价格相对低廉的操作系统。Linux以快速高效著称,与其他服务器操作系统一样,它具有多重应用。
Linux厂商发行版本有Red Hat,Debian,Fedora,Gentoo,SuSE,TurboLinux等,其中一部分可以下载。FTP发行商如:Sunsinte.org.uk, Sunsinte.unc.edu, www.isoimages.org。
可通过以下URL找到Linux相关信息:www. linux.com 和 www.linix.com, www.xfree86.com
Redhat企业版是一种常见的版本。它支持如Intel X86, Intel Itanium, AMD AMD64 and IBM z系列, POWER 系列, and S/390。Redhat使用最新版本稳定的2.5/2.6 Linux内核。
Redhat发展历程:
1991年,Linux内核发布。同年Bob Yong(加拿大人,多伦多大学毕业)在纽约UNIX用户组引入系统管理自由软件。
1993年,Bob Yang 建立了ACC公司,营销Linux和UNIX的支持软件和书籍杂志。
1994年,Marc Ewing(美国人,卡内基梅隆大学毕业)建立了自己的Linux分销业务,发布了Red Hat Linux 1.0。
1995年,Bob Yang 收购了Marc Ewing的业务,合并后的ACC公司成为新的Red Hat 软件公司,发布了Red Hat Linux 2.0。
1997年12月,Red Hat Linux 5.0发布,它支持Intel、alpha和Sparc平台和大多数的应用软件。极其简单易用的RPM模块化的安装、配置和卸载工具,使程序的安装可在15分钟内完成。软件升级也很方便,这对刚开始使用Linux的用户来说是一大福音。
2003年4月,Red Hat Linux 9.0发布。重点放在改善桌面应用方面,包括改进安装过程、更好的字体浏览、更好的打印服务等。统计表明,2003年,Red Hat的 Linux市场份额为86% 。
2004年4月30日,Red Hat公司正式停止对Red Hat 9.0版本的支持,标志著Red Hat Linux的正式完结。原本的桌面版Red Hat Linux发行包则与来自民间的Fedora计划合并,成为Fedora Core发行版本。Red Hat公司不再开发桌面版的Linux发行包,而将全部力量集中在服务器版的开发上,也就是Red Hat EnterpriseLinux版。 2005年10月RHEL4发布。
2007年3月,现行主流版本RHEL5发布(最新版本5.5)
2010年4月RHEL6 BETA测试版发布。
2011年04月12日 Oracle发布的Linux系统6.0(基于RedHat Enterprise Linux 6.0)
本文中,将采用Redhat企业版作为示例操作系统。
Linux内核模块及启动:
Linux内核采用模块化设计。系统启动时,只有最近贮存的内核会加载到内存中。此后,每当用户请求一个当前内核中不具备的功能,将动态加载一个内核模块(有时称为驱动)到内存中。
在安装过程中,对系统硬件进行探测。基于本次探测及用户提供的信息,安装程序决定在启动时加载哪一种模块。安装程序建立了动态加载机制以实现透明操作。
如果安装结束后新添加了硬件,并且该硬件需要一个内核模块,则系统必须为新硬件配置并加载合适的内核模块。
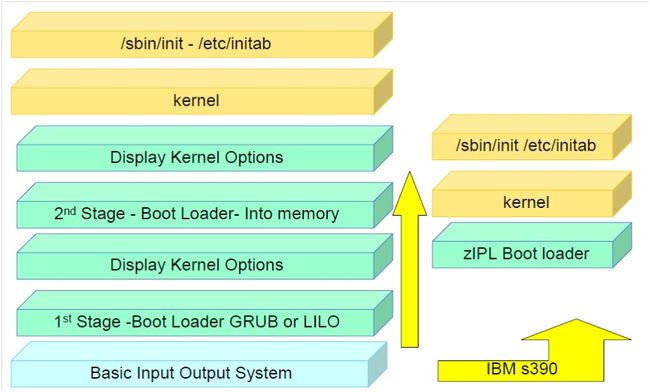
BIOS(Basic Input and Output System)的启动过程
不同类型的服务器使用了不同的引导装载程序。以上图例中,如果服务器是基于Intel的则引导装载程序可能是GRUB或LILO。如果是mainframe大型机则有可能使用IBM s390引导加载程序。
BIOS发起第一阶段主引导加载程序。BIOS将位于引导介质第一扇区中的程序加载入内存,我们称之为主引导记录(Master Boot Record或MBR)。主引导记录只有512字节大小,包含启动设备所需的机器代码,也称为引导加载程序(boot loader)。一旦BIOS将引导加载程序找到并将其加载入内存后,它就将启动程序的控制权交给二级引导加载程序。在第一阶段,主引导加载程序通过BIOS从主引导记录被读入内存。它的主要工作是加载位于不同介质上任意位置的数据,通过这步操作来定位第二阶段引导加载程序。
第二阶段引导装载程序由第一阶段的引导装载程序发起,它包含有加载程序更需要磁盘空间的部分,如用户界面和内核引导程序。该阶段允许用户选择启动的操作系统或Linux内核。可用的两个启动加载程序是GRUB或LILO。GRUB是较新的启动加载程序,能够阅读ext2和ext3类型文件分区并在启动时加载它的配置文件——/boot/grub/grub.conf。LILO是较老的版本,它使用主引导记录中的信息以确定用户可用的启动选项。这意味着无论何时配置发生更改或内核被手动升级,必须通过命令来讲合适的信息写入MBR。命令为:/sbin/lilo -v -v。
GRUB 与 LILO 的比较
所有引导加载程序都以类似的方式工作,满足共同的目的。不过,LILO 和 GRUB 之间有很多不同之处:
- LILO 没有交互式命令界面,而GRUB 拥有。
- LILO 不支持网络引导,而GRUB 支持。
- LILO 将关于可以引导的操作系统位置的信息物理上存储在MBR 中。如果修改了LILO 配置文件,必须将LILO第一阶段引导加载程序重写到MBR。相对于 GRUB,这是一个更为危险的选择,因为错误配置的MBR 可能会让系统无法引导。使用GRUB,如果配置文件配置错误,则只是默认转到GRUB 命令行界面。
接下来,系统将操作系统加载入内存并将设备的控制权转交给该操作系统。操作系统将会处理/etc/inittab文件,并依据/etc/inittab设定的内容,依序启动相关进程。首先启动的程序为/etc/rc.sysinit。rc.sysinit设置环境变量,启动置换空间,检查文件系统,并执行所有系统初始化所需的其他步骤。例如,绝大多数系统使用时钟,因此rc.sysinit读取/etc/sysconfig/clock配置文件以初始化硬件时钟。另一个例子是如果要初始化串口,rc.sysinit将会执行/etc/rc.serial文件。
Linux磁盘设备驱动基础:
Linux内核中采用可加载的模块化设计,常见的驱动程序是作为内核模块动态加载的。
模块的相关命令:
- lsmod——列出当前系统加载的模块
- rmmod——将当前模块卸载
- insmod——加载当前模块
- mknod——创建相关模块
Linux将设备看作文件,每个设备对应一个文件名,内核中对应一个索引节点,对文件操作的系统调用大都适用于设备文件。对某个具体设备而言,文件操作和设备驱动是同一事物的不同层次。Linux将设备分为两大类,一类是像磁盘那样的以块或扇区为单位、成块进行输入/输出的设备,称为块设备;另一类是像键盘那样以字符(字节)为单位,逐个字符进行输入/输出的设备,称为字符设备;文件系统通常建立在块设备上。
本文将以SCSI磁盘为例来介绍磁盘设备驱动的基础知识。
SCSI(小型计算机系统接口)总线是一种高效的点对点数据总线,它最多可以支持8个设备,其中包括多个主设备。在总线上的两个设备间数据可以以同步或异步方式,在32位数据宽度下传输率为40M字节来交换数据。SCSI总线上可以在设备间同时传输数据与状态信息。
Linux SCSI子系统由两个基本部分组成,每个由一个数据结构来表示。
Host
一个SCSI host即一个硬件设备:SCSI控制权。在Linux系统中可以存在相同类型的多个SCSI控制权,每个由一个单独的SCSI host来表示。这意味着一个SCSI设备驱动可以控制多个控制权实例。SCSI host总是SCSI命令的initiator设备。
Device
虽然SCSI支持多种类型设备如磁带机、CD-ROM等等,但最常见的SCSI设备是SCSI磁盘。SCSI设备总是SCSI命令的target。这些设备必须区别对待,例如象CD-ROM或者磁带机这种可移动设备,Linux必须检测介质是否已经移动。不同的磁盘类型有不同的主设备号,这样Linux可以将块设备请求发送到正确的SCSI设备。
SCSI子系统的初始化非常复杂,它必须反映出SCSI总线及其设备的动态性。Linux在启动时初始化SCSI子系统。 如果它找到一个SCSI控制器(即SCSI hosts)则会扫描此SCSI总线来找出总线上的所有设备。然后初始化这些设备并通过普通文件和buffer cache块设备操作使Linux内核的其它部分能使用这些设备。一旦SCSI子系统初始化完成这些SCSI设备就可以使用了。每个活动的SCSI设备类型将其自身登记到内核以便Linux正确定向块设备请求。
如前所述,一个设备文件(即设备节点)可以通过mknod命令来创建,其中指定了主设备号和次设备号。主设备号表明某一类设备,一般对应着确定的驱动程序;次设备号一般是用于区分标明不同属性,例如不同的使用方法,不同的位置,不同的操作等,它标志着某个具体的物理设备。高字节为主设备号和底字节为次设备号。例如,在系统中的块设备SCSI 磁盘的主设备号是3,而多个SCSI 磁盘及其各个分区分别赋予次设备号1、2、3……
SCSI系统中磁盘设备驱动层级如下:sd——直接访问磁盘,sg——SCSI通用接口,sr——Data CD-ROMs,st——磁带。sg驱动是基于字符的设备而其他三个驱动都是块设备驱动。sg驱动主要用于扫描仪,刻录机,以及打印机。从第一个SCSI控制器开始,sg设备文件动态映射到SCSI总线上的SCSI IDs/LUNs。
块设备的本地文件名具有以下格式:/dev/sdln,l表示物理设备而n表示该物理设备上的分区号。当主机总线适配器发现附加连接的存储后Linux会在设备文件/dev/sd[l][n]中定义这些设备。当主机总线适配器监测到随机附带存储后Linux将会定义设备文件/dev/sd[l][n]。
按照以上定义,以文件/dev/sda1为例,物理设备是“a”而分区是“1”。Linux内核为SCSI设备保留了16个主设备编号,各主设备编号可拥有0-255个从设备编号。这些从设备编号包括SCSI设备的分区。对于每个磁盘设备Linux支持0到15个分区。其中,1至4为主分区,分区5以上为逻辑分区或扩展分区;以上限制只适用于Intel平台。默认情况下,Linux并不使用slice这一概念。因此,16个主设备编号和16个从设备编号意味着256个SCSI磁盘设备,内核能够扫描范围从1至255的磁盘设备。Red Hat Linux和SuSE SLES 7最大支持128个SCSI设备,而SuSE SLES 8版本支持256个SCSI设备。
动态设备配置步骤:
在Linux内核中,与其他类型的UNIX系统(如:Sun,SGI,HP-UX,BSD)不同,设备名中并没有使用SCSI地址。如前文所述,块设备名格式为/dev/sdln,l是表示物理设备驱动的字符而数字n代表该物理设备驱动的分区号。设备名在启动时或设备加载时按发现顺序动态指定。
如果添加了硬件设备之后系统重新启动,设备编号将会更改从而造成主机的挂载列表不准确。为了保持设备编号的准确性并减少挂在列表出现偏差的可能性,应当把新的设备附加在当前设备列表中。例如,如果主机包含多个HBA,最好将新设备附加在最后一个HBA的磁盘设备列表的末端,这样就无需更改挂载列表中的现有记录。如果新设备添加到第一个HBA中,那么在系统重启之后,所有设备编号都会在原有数字加一同时挂在列表记录也需随着该设备发生偏移。如果只有一个HBA,则新设备可方便地添加到原有设备列表中并相应地改变挂载列表。
目前Linux系统缺乏植入到内核中的、如同drvconfig或ioscan这样能够动态配置SCSI通道的命令。
重新配置Linux主机的三种方式有:
- 重启系统
- 卸载并重新加载HBA驱动模块
- echo /proc文件系统
重启主机:
重启主机是检测新添加磁盘设备的可靠方式。在所有I/O停止之后方可重启主机,同时静态或以模块方式连接磁盘驱动。系统初始化时会扫描PCI总线,因此挂载其上的SCSI host adapter会被扫描到,并生成一个PCI device。之后扫描软件会为该PCI device加载相应的驱动程序。加载SCSI host驱动时,其探测函数会初始化SCSI host,注册中断处理函数,最后调用scsi_scan_host函数扫描scsi host adapter所管理的所有scsi总线。
卸载并重新加载HBA驱动模块:
通常情况下,HBA驱动在系统中以模块形式加载。从而允许模块被卸载并重新加载,在该过程中SCSI扫描函数得以调用。通常,在卸载HBA驱动之前,SCSI设备的所有I/O都应该停止,卸载文件系统,多路径服务应用也需停止。如果有代理或HBA应用帮助模块,也应当中止。
例如,rac节点上某台服务器执行fdisk –l命令看不到共享磁盘,可尝试执行如下命令:
# modprobe -r lpfc(卸载驱动)
# modprobe lpfc(加载驱动)
/proc下SCSI扫描:
2.4内核中,/proc文件系统提供了可用SCSI设备的列表。如果系统中SCSI设备重新配置,那么所有这些改变通过echo /proc接口反映到SCSI设备中。添加一个设备,主机,channel,target ID,以及磁盘设备的LUN编号会被添加到/proc/scsi/,需指定scsi编号。
# echo "scsi add-single-device 0 1 2 3" > /proc/scsi/scsi
0:主机ID
1:channel ID
2:target ID
3:LUN编号
该命令会将新磁盘设备添加到/proc/scsi/scsi文件中。如果没有找到相应文件,需为/dev路径下新增磁盘设备创建设备文件名。
如果要删除一个磁盘设备,使用适当的主机,channel,target ID及LUN编号运行如下格式命令:
# echo "scsi remove-single-device 0 1 2 3" > /proc/scsi/scsi
0:主机ID
1:channel ID
2:target ID
3:LUN编号