转载:http://www.itpub.net/thread-1801066-1-1.html
https://blog.csdn.net/cymm_liu/article/details/7968537
注:buffer pin有队列,x$bh的US_*是bh pin的owner队列,WA*是waiter队列,但是队列机制并非先进先出
buffer busy waits 的由来。
当n个进程想以不兼容的模式持有内存块上的buffer pin的时候,就会产生buffer busy waits等待。
什么?
内存块上有buffer pin ?
不是说内存块的锁都是靠latch实现的吗?什么时候还冒出一个buffer pin?从来没听说过!!
好,既然你这么问,那我们可以先假设没有buffer pin这东东,看看ORACLE怎么去访问/修改一个数据块。(下面的过程尽可能的我做了简化)
1)依据数据块的地址计算出数据块所在的bucket
2)获得保护这个bucket的cbc latch
3)在这个链表上找寻我们需要的数据块
4)读取/修改数据块的内容
5)释放cbc latch
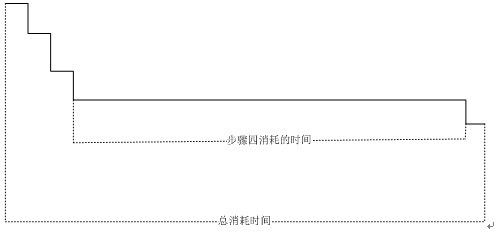
我们知道latch的获得和释放时间一般都是极短的(cpu的原子操作),上面5个步骤里1,2,3,5的时间我们都可以认为是极快的操作。
但是步骤四消耗的时间相对于这几个就大了去了。我粗糙的画了一个图,可以参展一下。
这样就导致了一个问题,在大并发环境下,由于cbc latch的持有时间过长,会导致大量的latch争用,latch的大量争用非常容易导致系统的cpu资源出现瓶颈。需要特别说明的是,即使你所有的操作都是查询非修改,也会导致大量的cbc latch争用:cbc latch的持有到cbc latch的释放这段时间过长了。
如何解决这个问题呢,说一下ORACLE的做法。
ORACLE通过让每次访问buffer block的会话获取两次cbc latch,再配合在内存块上加buffer pin来解决这个问题。
看如下的步骤。
1)依据数据块的地址计算出数据块所在的bucket
2)获得保护这个bucket的cbc latch
3)在这个链表上找寻我们需要的数据块,找到后,pin这个buffer(读取s,修改x)
4)释放cbc latch
5)读取/修改数据块的内容
6)获取cbc latch
7)unpin这个buffer
8)释放cbc latch
通过这种实现方式,我们看到cbc latch的持有时间大大降低了,因为cbc latch的持有,只做了很少的事情,这样就大大降低了cbc latch的争用。
你可能会挑战说,虽然cbc latch的争用会大大减轻,可是ORACLE只不过是转移了竞争点,现在变成了buffer lock之间的竞争。
你说的对,但是也不对!!
如果你的数据库里读极多,写极少,由于各个读之间的buffer pin是兼容的,都是s模式,因此不会产生任何的争用。
如果你的数据库里写极多,读极小,就会产生buffer busy waits等待,但是这种等待的代价比cbc latch的等待代价要小的多,latch的spin机制是非常耗cpu的,而buffer pin的管理本质上
类似于enq 锁的机制
,没有spin机制,不需要自旋耗费大量的cpu。
如果你的数据库是读写混合的场景,那么写会阻塞读,产生buffer busy waits,但是读不会阻塞写,不会产生这个等待。这个我们后面会重点讨论。
我们可以来简单的看一下,产生buffer busy waits的几个场景。如下代码找到了在同一个块上的两条记录。
create table wxh_tbd as select * from dba_objects;
create index t on wxh_tbd(object_id);
select dbms_rowid.ROWID_RELATIVE_FNO(rowid) fn, dbms_rowid.rowid_block_number(rowid) bl, wxh_tbd.object_id,rowid from wxh_tbd where rownum<3;
FN BL OBJECT_ID ROWID
---------- ---------- ---------- ------------------
8 404107 20 AAAF04AAIAABiqLAAA
8 404107 46 AAAF04AAIAABiqLAAB
1)场景1,读读。为了不影响实验的完整性,我们还是来简单的测试下读读的场景,虽然你可能已经知道这种场景肯定不会有buffer busy waits的等待。
SESSION 1运行:
declare
c number;
begin
for i in 1 ..6000000 loop
select count(*) into c from wxh_tbd where rowid='AAAF04AAIAABiqLAAB';
end loop;
end;
/
session 2运行:
declare
c number;
begin
for i in 1 ..6000000 loop
select count(*) into c from wxh_tbd where rowid='AAAF04AAIAABiqLAAA';
end loop;
end;
/
查看后台等待,无任何的buffer busy waits等待。这个结果是我们预料之内的。
2)场景2,写写:
session 1,运行:
begin
for i in 1 ..40000000 loop
UPDATE wxh_tbd SET object_name=20 where rowid='AAAF04AAIAABiqLAAA';
commit;
end loop;
end;
/
session 2,运行:
begin
for i in 1 ..40000000 loop
UPDATE wxh_tbd SET object_name=46 where rowid='AAAF04AAIAABiqLAAB';
commit;
end loop;
end;
/
两个session的等待里,我们都观察到了大量的buffer busy waits等待,由于会话1,2会在buffer 上加x排他的buffer pin,两种锁模式的不兼容性导致了争用。
3)读写混合测试:
session 1:
begin
for i in 1 ..40000000 loop
UPDATE wxh_tbd SET object_name=20 where rowid='AAAF04AAIAABiqLAAA';
commit;
end loop;
end;
/
session 2:
declare
c number;
begin
for i in 1 ..6000000 loop
select count(*) into c from wxh_tbd where rowid='AAAF04AAIAABiqLAAB';
end loop;
end;
/
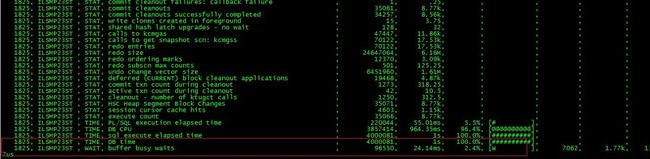
session 1的等待:
1825, WAIT, latch: cache buffers chains , 3531, 882.75us
session 2的等待:
1768, WAIT, buffer busy waits , 145246, 36.31ms
我们看到发生写的会话session 1,没有任何的buffer busy waits等待,而发生读的会话session 2,产生了大量的buffer busy waits等待。
网上对这一块的争论是比较激烈的。
道理其实非常简单
1)当读取的进程发现内存块正在被修改的时候(如果有x模式的buffer pin,就说明正在被修改),它只能等待,它不能clone块,因为这个时候内存块正在变化过程中ing,这个时候clone是不安全的。很多人说,oracle里读写是互相不阻塞的,oracle可以clone内存块,把读写的竞争分开。其实要看情况,在读的时候发现内存块正在被写,是不能够clone的,因为是不安全的。这个时候读的进程只能等待buffer busy waits。
2)当写的进程发现内存块正在被读,这个时候,读是不阻塞写的,因为ORACLE可以很容易的clone出一个xcur的数据块,然后在clone的块上进行写,这个时候clone是安全的,因为读内存块的进程不会去修改数据块,保证了clone的安全性。
说到这里,基本上可以来一个简单的总结了,但是总结前,还是有必要给大家简单介绍一下,buffer header上的两个列表。
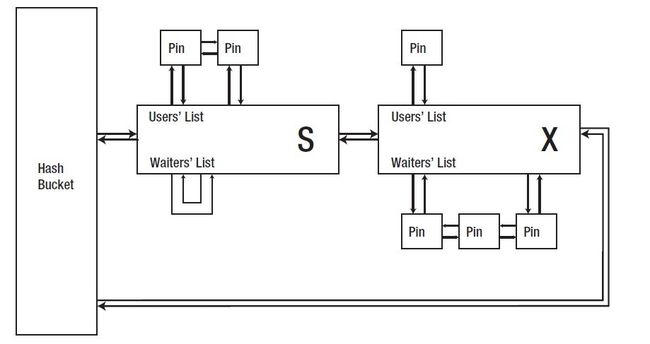
每个buffer header上都有2个列表:users list和waiter list。
users list用来记录,当前有哪些会话获得了此buffer block上的buffer pin,并记录下buffer pin的模式。
waiter list用来记录,当前有哪些会话在等待buffer block 上的buffer pin,并记录下申请buffer pin的模式。
看到这两个列表,是不是觉得似曾相识?对了,enq锁的管理也是类似的这个方式,不过多了一个列表,锁转换列表。
给大家举个例子,会更清晰一些:
session 1(sid 123):修改数据块block 1
此block的buffer headler上的users list如下:
sid hold mode
123 x
session 2(sid 134):也想修改数据块block 1,但是由于于session 1的锁模式不兼容,只能等待buffer busy waits,此时的user list不变,waiter list如下:
sid req mode
134 x
session 3(sid 156):也想修改数据块block 1,但是由于于session 1的锁模式不兼容,只能等待buffer busy waits,如果这个时候我们去观察后台的等待,会发现2个会话在等待buffer busy waits了(134,156)。此时的user list不变,waiter list如下:
sid req mode
134 x
156 x
如果这个时候sid为123的会话修改完成,那么会通知sid为134的会话获得buffer pin,此时的user list,waiter list 如下:
user list
sid hold mode
134 x
waiter list
sid req mode
156 x
可要看到,buffer lock的这种机制非常类似于enq锁的机制,先进先出,然后通过n个列表来记录锁的拥有者和等待着。等待buffer busy waits的进程在进入队列后,会设置一个1秒(_buffer_busy_wait_timeout)的超时时间,等待超时后,会“出队”检查锁有没有释放,然后重新入队。
最后我们可以来一个总结了:
1)buffer busy waits是产生在buffer block上的等待,由于n个进程想以不兼容的模式获得buffer block的buffer pin,进而引起buffer busy waits等待。
2)buffer lock的管理模式非常类似enq锁的管理模式,先进先出,有队列去记录锁的拥有者和等待着。
3)写写,读写都会产生buffer busy wiats等待。写写的两个会话,都会产生buffer busy wiaits等待,而读写的两个会话,只有读的session会产生,因为它不能去简单的clone一个内存块,正在发生写的内存块发生克隆是不安全的
4)oracle为了解决cbc latch持有时间过长的问题,以每次访问buffer block的会话获取两次cbc latch,再配合在内存块上加buffer pin来解决这个问题。
说明:oracle并不是针对所有的内存块都采取两次获取cbc latch的机制,比如针对索引root,索引branch,唯一索引的叶子节点,都是采取的一次获取机制。
1)一旦你PIN住了一个数据块,不需要立即去UNPIN(移除PIN)它。ORACLE认为你的本次调用后还有可能去访问这个数据块,因此保留了PIN,直到本次调用结束再UNPIN。
2)Oracle在对唯一索引/undo块/唯一索引的回表/索引root、branch块的设计上,在访问(读取)的时候,获取的是共享的CBC LATCH,不需要去PIN数据块,在持有共享CBC LATCH的情况下读取数据块。可能的原因是这些块修改的可能性比较小,因此Oracle单独的采用这种机制。因此对于普通数据块的读取都是需要获取2次CBC LACTH,而对于这种特殊的数据块,只获取一次共享CBC LATCH就OK 了。
3)我们上面所说的情况都是在数据块已经存在在内存里的情况。如果数据块不在内存,有可能会产生READ BY OTHER SESSION争用等待。有时间我们再看这个等待的原因。
4)上面描述只符合10G后的版本。在10G前读读也会产生BUFFER BUSY WAITS,10G后把这方面的BUFFER BUSY WAITS归到了READ BY OTHER SESSION等待里。
5)上面的描述基本都采用了数据块这个词,更准确的表达应该是buffer block。
带有原因码(9i)/类(10g后)(v$session P3字段)130的数据块(类#1)争用
1) 等待集中在数据块上,并且原因码是130,则意味着多个会话并发请求相同的数据块,但该数据块并不在缓冲存储器中,并且必须从磁盘读取。
2) 当多个会话请求不在缓冲存储器中的相同数据块时,ORACLE可以聪明地防止每个会话进行相同的操作系统I/O调用。否则,这可能严重地增加系统I/O的数量,所以,ORACLE只允许一个会话执行实际的I/O,而其他的会话在buffer busy waits上等待块,执行I/O的会话在db file sequential read或db file scattered read等待事件上等待。
3) 可在v$session视图中检查SESSION的注册时间,并且等待事件db file sequential(scattered) read和buffer busy waits等待相同的文件号和块号。
4) 解决方法:优化SQL语句,尽可能地减少逻辑读和物理读;
带有原因码220的数据块(类#1)争用
1) 等待集中在数据块上,并且原因码是220,则意味着多个会话同时在相同的对象上执行DML(相同块中的不同行)。
2) 如果数据块的尺寸较大(>=16K),则可能强化这种现象,因为较大的块一般在每个块中包含更多的行。
3) 减少这种情况的等待的方法:减少并发;减少块中行的数量;在另一个具有较小块尺寸的表空间中重新构建对象。
4) 具体方法说明:使用较大的PCTFREE重新构建表或索引;使用alter table minimize records_pre_block命令改变表以最小化每个块的最小行数
从ORACLE9i开始,可以在另一个具有较小块尺寸的表空间中移动或重新构建对象。
注:虽然这些方法可以最小化buffer busy waits问题,但它们无疑会增加全表扫描时间和磁盘空间利用率。
数据段头(类#4)的争用
1) 如果buffer busy waits的等待事件主要集中在数据段头(即表或索引段头,并且不是UNDO段头)上,这意味着数据库中一些表或索引有高段头活动。
注:进程出于两个主要原因访问段头,一是,获得或修改FREELISTS信息;二是,为了扩展高水位标记(HWM)。
2) 减少这种情况的等待的方法:
>> 对使用自由表进行段管理的表,增加确认对象的FREELISTS和FREELIST GROUPS(注:FREELIST GROUPS的增加也是必须的);
>> 确保FCTFREE和PCTUSED之间的间隙不是太小,从而可以最小化FREELIST的块循环。
>> 下一区的尺寸不能太小,当区高速扩张时,建立的新区需要修改在段头中区映射表。可以考虑将对象移动到合理的、统一尺寸的本地管理的表空间中。
撤销段头(类#17)的争用
1) 如果buffer busy waits等待事件主要集中在撤销段头,这表明数据库中的回滚段过少或者是它们的区尺寸太小,从而造成对段头的频繁更新。如果使用ORACLE9I的由数据库系统管理UNDO段,就不需要处理这种问题,因为ORACLE会根据需要增加额外的的UNDO段。
2) 可以创建并启用私有回滚段,以减少每个回滚段的事务数量。需要修改init.ora文件中的ROLLBACK_SEGMENTS参数。
3) 如果使用公用回滚段可以减少初始化参数transactions_per_rollback_segment的值,ORACLE通过transactions/transactions_per_rollback_segment来获取公有回滚段的最小数量。
撤销块的争用(类#18)
1) 如果buffer busy waits等待事件主要集中在撤销块上,这表明有多个并发会话为保证一致性读同时查询更新的数据。
2) 这是应用程序存在问题,当应用程序在不同时间内运行查询和DML时,这种问题不会存在。