决战大数据之巅:Spark、Dask、Vaex、Pandas的正面交锋
全文共3924字,预计学习时长15分钟

图源:unsplash
新的数据科学问题席卷而来时,首要问题是使用何种技术。广告宣传、标准工具、尖端技术、整个平台和现成的解决方案,都是备选项。
过去的几年里,笔者尝试使用各项技术来构建概念证明和解决方案。笔者注册试用新平台、试用任何大型云平台发布的新功能。当一项新技术出现时,笔者必然会浏览一些教程并在个人数据集上试用。
笔者决定比较各项数据整理技术,以便为下一个项目选择最适合表格式数据探索、清洗和整理的技术。笔者也以此为契机,重新接触了好几年没有使用过的技术。随着时间的推移,这些技术已优化很多。
TL;DR
Vaex作为新型大数据技术正在崛起。如果用户已在使用PySpark平台或已拥有PySpark人才,这仍是一个不错的选择。
是什么
下文中,笔者假设读者对Python API和大数据功能有基本的掌握程度。我选取了Taxi数据集的10亿行数据,容量有100GB。目标是比较这些技术的API、性能和易用性。笔者认为Pandas是API的基准(确实承认该说法存在争议的),因为Pandas是目前最常见的解决方案,但不能处理大数据。
程序员有两种处理大数据集的传统方式/方法:一种是更强大的/分布式计算,使内存与数据大小相匹配;另外一种是核外方法,即只有在必要时才在内存中读取数据。二者成本差异巨大,因此,笔者决定只考虑核外计算的解决方案。

图源:unsplash
竞争产品:
· Koalas —Apache Spark 上的Pandas API。
· Vaex —一个用于延迟外核数据帧的Python库。
· DaskDataFrame —一款用于分析的灵活并行计算库。
· PySpark —一款基于Spark的用于大规模数据处理的统一分析引擎。
· Turicreate —一个相对私密的机器学习包,其数据框架结构为符合标准的SFrame。
· Datatable — H2O无人驾驶AI的支柱。它是一个数据帧包,特别强调单节点速度和大数据支持。
荣誉奖:
· Vaex确实具有GPU和numba支持,但笔者没有进行基准测试。
· Pandas —Pandas具有分块功能,但在探索和动态交互方面,它与其他工具不同。
· cuDF (RapidAI) — GPU数据框软件包是一个刺激的概念。对于大数据,必须使用带有Dask的分布式GPU来匹配数据大小,适合无底洞。
· H2O — 标准的内存数据框架是全面的。尽管如此,根据集群是数据集四倍大小的建议,用户需要有足够的资金利用H2O进行勘探和开发。它另一个GPU版本也有相同的问题。
· Modin —一种在不更改后台使用Dask或 Ray的API情况下缩放Pandas的工具。然而目前它只能读取一个镶木地板文件,而笔者已拥有一个分块的镶木地板数据集。程序员们有望通过Modin获得与Dask数据帧类似的结果,所以此时将所有镶木地板文件合并不是最佳选择。
怎么样
笔者在AWS Sagemaker上使用了一个0.95美元/小时的ml.c5d.4xlige实例,可以轻松复制基准。它有16个vcpu,32GB的RAM加上500个SSD,这与一台固态笔记本电脑有相似之处。
尽管所有竞争产品都可以读取CSV文件,但更优化的方法是使用最适合每种技术的二进制版本。
对于PySpark、Koalas和Dask数据帧,我使用了Parquet,而对于Vaex,笔者使用了HDF5。Turicreates的SFrame具有特定的压缩二进制版本。Datatable是jayformat优化的一种特殊情况。
尽管无法用Datatable读取CSV文件,但Maarten Breddels还是破解了一种使用HDF5的方法,无论实例大小(即使在RAM中的数据大小是原来的两倍多)。当Datatable能够可靠地读取多个CSV、Arrow或Parquet文件时,最好对工具进行更新。
笔者想指出的是,该基准测试的开发成本有点昂贵,技术在运行几个小时后多次崩溃。
结果
编码复杂度:只需关注API,就能了解每种技术的代码量和设计模式。
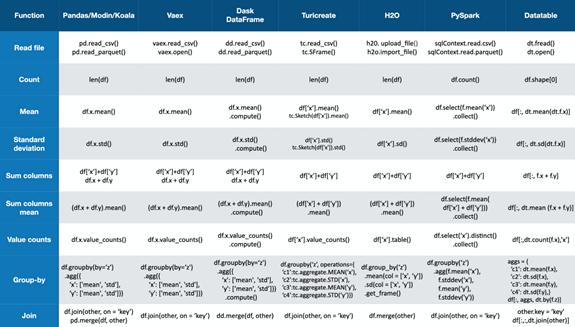
优胜者:Vaex,Dask DataFrame,Turicreate和Koalas的代码非常类似于Pandas代码(Koalas和Pandas代码一样),用户可以轻松完成任何事情。
淘汰者:PySpark和Datatable具有自己的API设计,用户必须学习和调整这些API。这项任务并不艰巨,但如果你习惯使用了Pandas,这是一个限制。
特征
优胜者:PySpark / Koalas和Dask DataFrame提供了各种各样的功能。注意,在某些复杂情况下使用PySpark时,用户可能需要“ map-reduce”知识来编写算法以实现特定需求。
使用Dask DataFrame,用户需要知道何时可以或不能使用sklearn功能,该功能无需占用大量内存即可扩展。虽然Vaex和Turicreate缺少一些特定功能,但它们涵盖了大多数核心功能。
淘汰者:Datatable的功能似乎还不成熟,而且远远落后于其他竞争者。
管道

图源:unsplash
通常,在为机器学习和后端API构建解决方案时,用户需要对流程进行编程。例如,在对列进行归一化时,需要记住均值和标准差以对新观察值进行归一化。此时,简单性,灵活性和代码简洁性至关重要。对于许多数据科学应用程序来说,该任务可能占据整项工作的80%。
优胜者:Vaex。借助自身表达系统,Vaex对数据集的任何转换都将保存在后台,以便用户可以轻松地将其应用于新数据。这使得学习管道轻松化,管道运行实际上是在进行一项无任务导向的事情。
其次是Dask DataFrame,它具有各种预处理工具。但可能需要运行转换器,并考虑可以有效处理哪些sklearn转换器。
接下来是PySpark。即使构建管道是PySpark的强项之一,用户需要编写很多代码才能实现该任务。不利于PySpark的另一件事是,模型和管道的安装和部署绝非易事。你肯定需要(或倾向于)昂贵的平台(例如Databricks和Domino),或严重依赖Sagemaker,Dataproc或Azure的基础结构。
淘汰者:Koalas,Turicreate和 Datatable
Turicreate and Datatable不具备管道功能。尽管Koalas具有比PySpark更好的API,但对在创建管道方面相当不友好。用户可以轻易将Koalas转换为PySpark数据帧并快速返回,但是对于管道功能而言,这很繁琐,并且会带来各种麻烦。
惰性计算
惰性计算是一项功能,仅在需要时才运行计算。例如,如果我有两列A和B,则创建新的A * B列实际上需要0秒且没有内存。如果我想查看该列的前几个值,则仅计算那些值即可,而无需计算整个列。
惰性计算提速并简化了使特征工程和其勘察过程,并防止了在内存中存储其他庞大的列数据。处理大型数据集时,例如设计新列,连接表或筛选太大而无法放在内存中的数据时,惰性计算的价值功能则相当明显,因为普通计算可能会导致计算机崩溃。
从性能角度来说,你会在下一节看到笔者创建了一个新列,然后计算了平均值。Dask 数据帧花费的时间比其他技术长10到200倍,笔者认为此功能没有得到很好的优化。不幸的是,尽管Koalas支持,但PySpark不支持惰性评估。

图源:unsplash
优胜者:Vaex, Datatable, Koalas和 Turicreate
淘汰者:PySpark和 Dask DataFrame
性能
这里我想误引乔治·博克斯的话:“所有的基准都是错误的,但有些是有用的。”各工具的性能可能会有所不同,笔者受到此博客的启发,将每个基准测试运行两次。考虑到首次运行与成批处理工作更相关(更能指示磁盘读取速度),二次运行更能代表交互工作体验(方法的实际速度)。
在以下所有图表中:
· 蓝色条表示首次运行,橙色条表示二次运行。
· TuricRate具有草图功能,可以同时计算一系列统计和估计;它更适合于统计分析。
· 为了更简洁的名称可视化,我使用别名:“dt”表示Datatable,“tc”表示Turicreate,“spark”表示PySpark,“dask”表示dask DataFrame。
基本统计
此处,笔者测试了一些基础数据:平均值、标准差、值计数、两列乘积的平均值,创建了一个惰性列并计算其平均值:
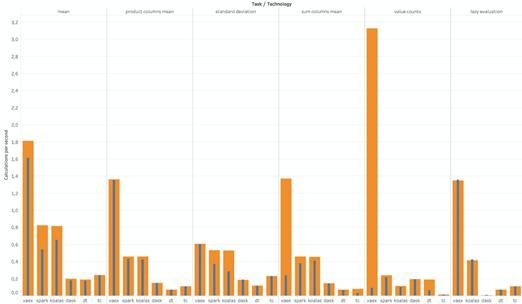
· Vaex处于领先地位。
· Koalas得到了与PySpark相似的结果,这是合理的,因为它在后台使用了PySpark。
· Dask数据帧、Turicreate和Datatable性能相对落后。
繁重计算
笔者在两列上使用均值和标准差进行分组,然后将其加入原始数据集并计算行数,这样就不必处理内存中的整个合并数据集。笔者还运行了一个超级繁琐复杂的数学表达式,以探索冗长特征工程的过程影响。

· Vaex在连接方面做得很好,它使图形失真。
· Datatable在连接方面表现出色。此结果可能与我用HDF5包装数据表的方式有关。我没有加入所有的字符串列,这导致数据帧的占用空间更少。因此它是黑马,第二名!
· Dask DataFrame和Turicreate再次落后。
注意,当我在一个新创建的列上运行连接时,除了Vaex之外的所有技术都崩溃了,在规划特征工程时要考虑到这一点。
可以看到,Dask DataFrame和Turicreate性能落后,Vaex赢得了绝对的胜利。
过滤
此处,笔者首先过滤数据并重复上述操作。此时Koalas,Datatable和Turicreate崩溃了。这些结果很好地体现了数据清洗性能。
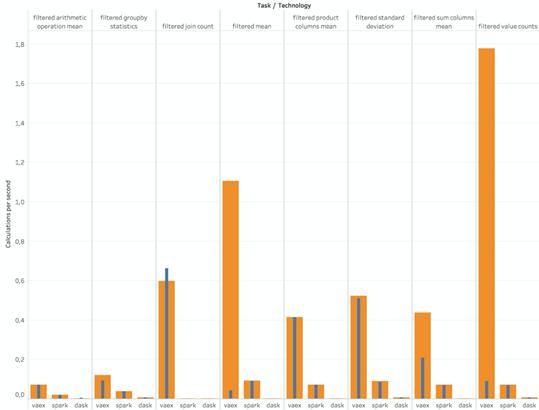
· 在大多数情况下,尤其是在第二轮比较中,Vaex似乎占了上风。
· Dask数据帧并未崩溃,因此获得了荣誉称号,但结果比Vaex和PySpark慢5到100倍。
数量
下面是列表结果:
· 结果以秒为单位。
· 缺少结果的地方,技术崩溃了。
· 小于一秒的值表示惰性计算。
· 交互式表格。
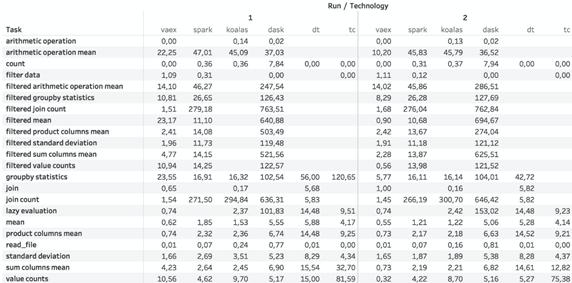
优胜者:Vaex明显胜利,亚军是PySpark和Koalas
淘汰者:Dask DataFrame,Turicreate和Datatable
最后一点
此代码允许用户比较API并自己运行基准测试。所有数据集都可以以正确的二进制格式下载。我在使用Dask 数据帧时遇到了种种问题,为了获得最佳性能,我竭尽全力重新启动内核,并在进行一些计算之前重新读取了数据。
尽管过程很不愉快,但我还是尽了最大努力来获得最佳性能。如果仅按原样运行笔记本,则可能要等待几个小时,不然可能会崩溃。正如预期的那样,Koalas和PySpark的结果非常相似,因为它们都在后台使用Spark。
如前所述,我无法对文件中未保留的新创建列应用测试,因为这会使Dask 数据帧和PySpark崩溃。为了解决这个问题,我进一步计算了结果的平均值或计数,以强制使用单个值。我没有使用任何字符串列,这是因为破解Datatable对字符串列不起作用。
(免责声明:我本人认识Turicreate的创建者之一,Spark的撰稿人和Vaex的主要开发人员,但我尽可能地保持公正去发表看法。)

图源:unsplash
自从Turicreate开源以来,笔者一直在使用Turicreate作为它的首选软件包,而在此之前,笔者一直使用PySpark,现在已改成Vaex。尽管状态还处于起步阶段,还有些粗糙,但是表达式和状态转移减少了因不常用功能而形成的代码浪费,提升了编码速度。
笔者对PySpark和Koalas的出色表现感到惊讶,但设置问题、使用非现有平台部署解决方案、管道问题、开发过程中无法解释的错误(以及常见的PySpark API问题)等麻烦依然存在。
Dask 数据帧是一个高难度挑战。它崩溃了无数次,笔者经历了多次考验,以使其在性能上更具竞争力。
概言之,在基准测试开发过程中,PySpark和Dask DataFrame是时间成本最高、价格成本最大的。

一起分享AI学习与发展的干货
欢迎关注全平台AI垂类自媒体 “读芯术”
(添加小编微信:dxsxbb,加入读者圈,一起讨论最新鲜的人工智能科技哦~)