数据压缩实验6-MPEG1音频编码
一、 实验原理
1. MPEG-1 Audio LayerII编码器原理

输入声音信号经过一个多相滤波器组,变换到32个子带,同时经过“心理声学模型”并计算以频率为自变量的噪声掩蔽阈值。在量化和编码部分用信掩比SMR决定分配给子带信号的量化位数,使量化噪声<掩蔽域值。最后通过数据帧包装将量化的子带样本和其它数据按照规定的帧格式组装成比特数据流。
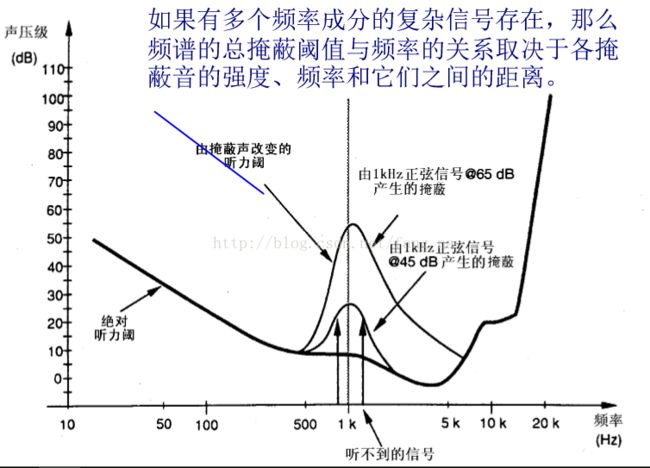
2. 听觉掩蔽特性:即听觉阈值电平是自适应的,会随听到的不同频率声音而发生变化。如下图频域掩蔽域随声压级变化曲线所示,则声音压缩算法可以确立这种特性的模型来取消更多的冗余数据。
3. 人耳听觉系统与临界频带
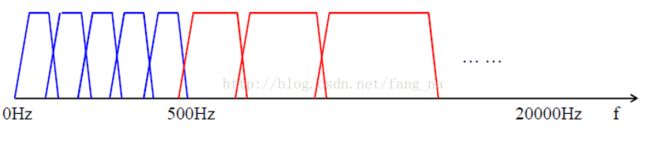
人类听觉系统大致等效于一个在0Hz到20KHz频率范围 内由25个重叠的带通滤波器组成的滤波器组,如下图所示,人耳频带也称为临界频带(critical band),且人耳不能区分同一频带内同时发出的不同声音。
4. 掩蔽与量化原则
将输入信号变换到频域,再将结果分解成一些尽量与临界频带尽可能相似的子带,然后对每个子带进行量化,量化方式应当使得量化噪声听不见。
二、心理声学模型算法分析
1. 将样本变换到频域 :利用多相滤波器将样本32个等分的子带信号并不能精确地反映人耳的听觉特性,则引入FFT补偿频率分辨率不足的问题:采用1024 (Layers II and III)样本窗口,每帧1152个样本点,每帧两次计算,选择两个信号掩蔽比(SMR)中较小的一个。
2. 确定声压级别

3. 考虑安静时阈值,也即绝对阈值:在标准中有根据输入PCM信号的采样率编制的“频率、临界频带率和绝对阈值”表。
4. 将音频信号分解成“乐音(tones)” 和“非乐音/噪声” 部分:两种信号的掩蔽能力不同。如下图所示:
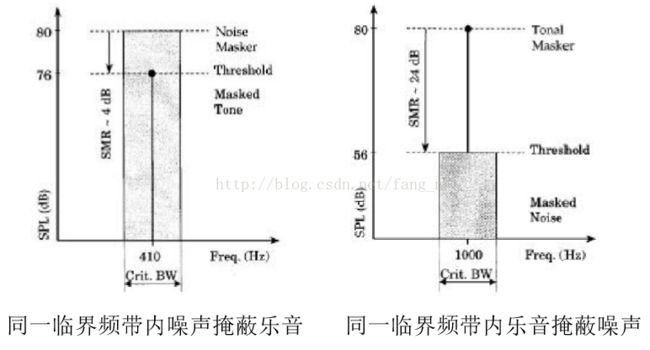
5. 根据音频频谱的局部功率最大值确定乐音成分:局部峰值为乐音,然后将本临界频带内的剩余频谱合在一起,组成一个代表噪声频率(无调成份)
6. 音调和非音调掩蔽成分的消除:利用标准中给出的绝对阈值消除被掩蔽成分; 考虑在每个临界频带内,小于0.5Bark的距离中只保留最高功率的成分
7. 单个掩蔽阈值的计算:音调成分和非音调成分单个掩蔽阈值根据标准中给出的算法求得。
8. 全局掩蔽阈值的计算:
注意:还要考虑别的临界频带的影响,一个掩蔽信号会对其它频带上的信号产生掩蔽效应,这种掩蔽效应称为掩蔽扩散。
9. 每个子带的掩蔽阈值:选择出本子带中最小的阈值作为子带阈值
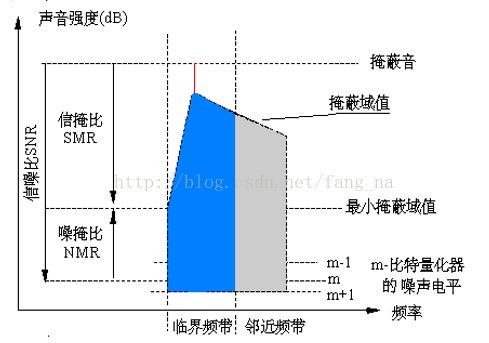
10.计算每个子带信号掩蔽比(signal-to-mask ratio, SMR) ,并将SMR传递给编码单元:
SMR = 信号能量 / 掩蔽阈值
11.比特分配及编码
在调整到固定的码率之前,先确定可用于样值编码的有效比特数,这个数值取决于比例因子、比例因子选择信息、比特分配信息以及辅助数据所需比特数。
比特分配的过程:
对每个子带计算掩蔽-噪声比MNR,是信噪比SNR – 信掩比SMR,即:MNR = SNR – SMR。
使整个一帧和每个子带的总噪声-掩蔽比最小。这是一个循环过程,每一次循环使获益最大的子带的量化级别增加一级,当然所用比特数不能超过一帧所能提供的最大数目。
第1层一帧用4比特给每个子带的比特分配信息编码;而第2层只在低频段用4比特,高频 段则用2比特。
12.子带样值的量化和编码
输入以12个样本为一组,每组包含32个子带样本,样本经过时间-频率变换之后进行一次比特分配并记录一个比例因子(scale factor) ,比特分配信息告诉解码器每个样本由几位表示,比例因子用6比特表示,解码器使用这个6比特的比例因子乘逆量化器的每个输出样本值,以恢复被量化的子带值。比例因子的作用是充分利用量化器的量化范围, 通过比特分配和比例因子相配合,可以表示动态范围 超过120dB的样本。
第2层中,量化级别的数目随子带的不同而不同,但量化等级仍然覆盖了3~65535的范围,同时子带不被分 配给比特的概率增加了,没有分配给比特的子带就不被量化。低频段的量化等级有15级,中频段7级,高频段只有3级。
13.数据帧包装

层II每帧包含1152个样本,为层1的三倍数量。低、中、高频段对比特分配不同,分别用4、3、2比特。比特流中增加了一个比特因子选择信息域,解码器根据这个域的信息可知道 是否需要以及如何共享比例因子。
三、实验要求
1. 输出音频的采样率和目标码率
2. 选择某个数据帧,输出该帧所分配的比特数,该帧的比例因子,该帧的比特分配结果。
四、关键代码及实验结果
m2aenc.c
FILE *info;
char name[100]="musicinfo.txt";
………..
adb = available_bits(&header, &glopts);
//fn add start
if(frameNum==3)
{
fprintf (info, "采样频率: %.1fkHz\n",s_freq[header.version][header.sampling_frequency]);
fprintf (info, "目标码率:%d kbps\n",bitrate[header.version][header.bitrate_index]);
fprintf (info, "输出第3帧信号信息\n");
fprintf (info, "该帧分配的总比特数:%d bits\n",adb);
}
//fn add end
……..
CRC_calcDAB (&frame,bit_alloc, scfsi, scalar, &crc, i);//比例因子选择函数
………..
//fn add start
if(frameNum==3)
{
fprintf(info,"比例因子选择\n");
for ( sd = 0; sd < nch; sd++ )//声道
{
fprintf(info,"声道%d\n",sd);
for ( zd = 0; zd < frame.sblimit; zd++ )//30个子带
{
fprintf(info,"子带%d:\t",zd);
fprintf(info,"%3d\t",scfsi[sd][zd]);
fprintf(info,"\n");
}
} fprintf(info, "输出比例因子:\n");
for ( sd = 0; sd < nch; sd++ )//声道
{
fprintf(info,"声道%d\n",sd);
for (zd = 0; zd {
fprintf(info,"子带%d:\t",zd);
fprintf(info, "子带%d:\t %d\t %d:\t %d:\t\n",zd, scalar[sd][0][zd], scalar[sd][1][zd], scalar[sd][2][zd]);
}
}
fprintf(info,"比特分配:\n");
for ( sd = 0; sd < nch; sd++ )//声道
{
fprintf(info,"声道%d\n",sd);
for ( zd = 0; zd < frame.sblimit;zd++ )//各子带
{
fprintf(info,"子带%d:\t",zd);
fprintf(info,"%d\n",bit_alloc[sd][zd]);
}
}
if(info)
fclose(info);
}
//fn add end实验结果如下图所示



